HelloAgents学习:PartⅠChapterⅡ语言模型&架构
语言模型&Transformer架构
从N-gram到RNN
语言模型Language Model是自然余元处理的核心,根本任务是计算一个词序列(也就是句子)出现的概率。一个好的语言模型能够告诉我们什么样的句子是通顺的、自然的。在多智能体系统中,语言模型是智能体理解人类指令、生成回应的基础。
统计语言模型&N-gram思想
深度学习兴起之前,统计方法是语言模型的主流。
核心思想:一个句子出现概率=该句子中每个词出现的条件概率的连乘。
对于由词w1,w2,⋯,wm构成的句子S,出现的概率P(S)可以表示为:
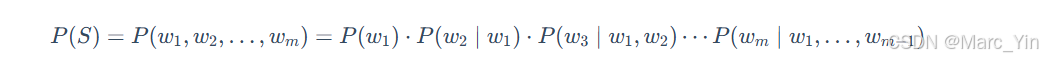
该公式被称为概率的链式法则。然而,直接计算这个公式几乎是不可能的,因为像:
![]()
这样的条件概率难以从语料库中及进行估计
为了解决上述计算难题,研究者引入了马尔可夫假设。
核心思想:不必回溯一个词的全部历史。我们可以近似认为一个词出现的概率只和前面的有限的n-1个词相关。
基于上述假设建立的语言模型称为N-gram模型。
这里的N代表我们考虑的上下文窗口大小。
-
Bigram(N=2):最简单情况,认为当前词出现只和前面的一个词有关。链式法则中复杂的条件概率变为更容易计算形式:
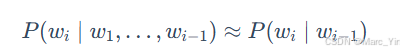
-
Trigram(N=3):假设一个词出现只和前面两个词相关:
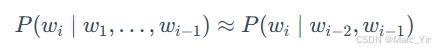
那么这些概率本身该如何计算呢?
通过在大型语料库中进行 最大似然估计Maximum Likelihood Estimation 进行计算。
本质思想:最可能出现的就是我们在数据中看到最多的。
N-gram模型虽然简单有效,但是存在两个致命缺陷:
-
数据稀疏性:若一个词序本身没有在语料库中出现的话,概率估计就是0,这显然是不合理的。
-
泛化能力差:模型无法理解词与词之间的语义相似性。即使语料库中出现了很多次的
agent learns但是它也无法将其泛化到类似的词上。当我们计算robot learns若robot这个词本身没有出现过,或者这个组合没有出现过,模型计算的概率也会是0。模型无法理解agent和robot之间语义的相似性。
神经网络语言模型&词嵌入
N-gram模型根本缺陷在于它将词视为孤立、离散的符号。新思想:使用连续的向量表示词。
前馈神经网络语言模型Feedforward Neural Network Language Model是这领域的里程碑。
核心思想分为两步:
-
构建一个语义空间:创建一个高维的连续向量空间,然后将词汇表中的每个词都映射为该空间的一个点。这个点——即向量,被称为词嵌入(Word Embedding)/词向量。这个空间上,语义相近的词,空间中位置也相近。
-
学习从上下文到下一个词的映射:利用神经网络强大的拟合能力,学习一个函数。这个函数的输入是前n-1个词的词向量,输出是词汇表中每个词在当前上下文后出现的概率分布。
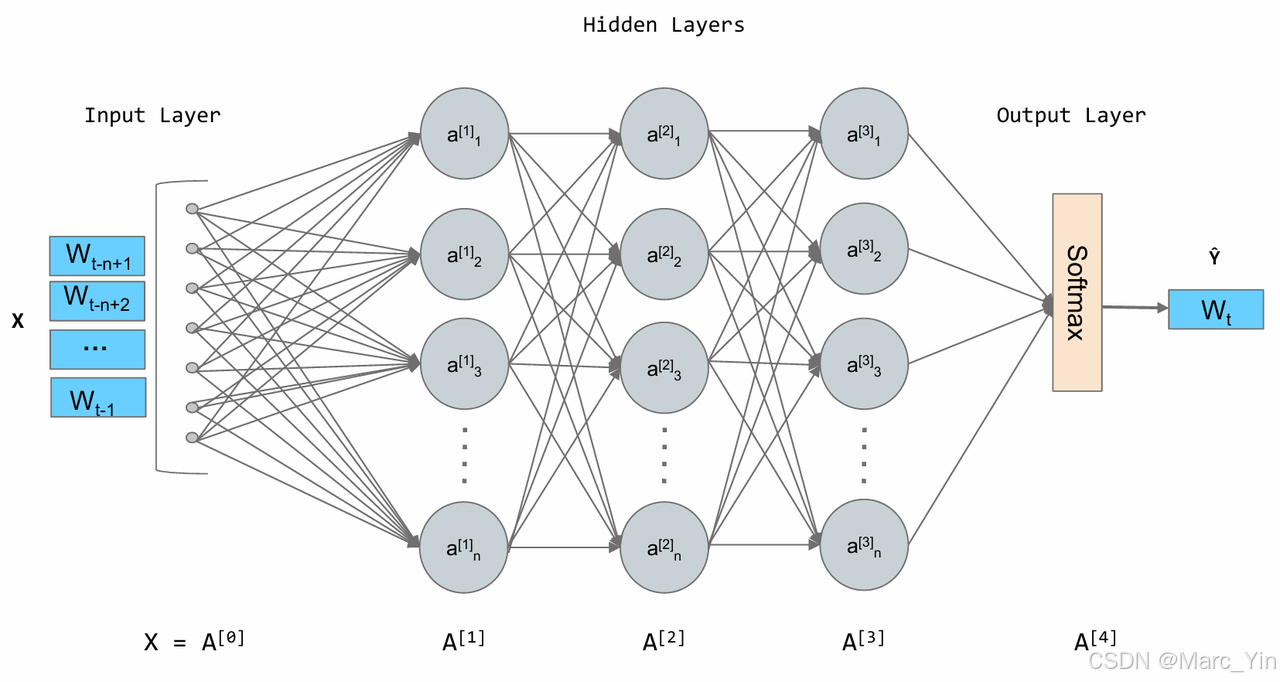
如上图所示,在这个架构中,词嵌入是在模型想你连过程中自动学习到的。模型为了完成“预测下一个词”这个任务,会不断调整每个词的向量位置,最终让这些向量能够蕴含丰富的语义信息。一旦我们将词转换为想i昂,我们就可以用数学工具度量他们之间的关系。
最常用方法:余弦相似度Cosine Similarity
通过计算两向量间夹角的余弦值衡量他们的相似性。
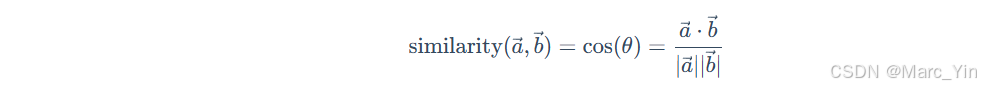
公式含义:
-
如果两个向量方向完全相同,夹角为0°,余弦值为1,表示完全相关。
-
如果两个向量方向正交,夹角为90°,余弦值为0,表示毫无关系。
-
如果两个向量方向完全相反,夹角为180°,余弦值为-1,表示完全负相关。
通过上述计算,不仅能够捕捉到“同义词”这类简单关系,还能捕捉到更加复杂的相似关系、反义关系。
甚至:
vector('King') - vector('Man') + vector('Woman')
和
vector('Queen')
两者在向量空间中的位置惊人的接近。
证明词向量学习到了“性别”“皇室”等概念。
神经网络语言模型通过词嵌入,成功解决了N-gram模型泛化能力差的问题。然而,它仍然有一个类似N-gram的限制:上下文窗口固定。只能考虑固定数量的上下文,这为能处理任意长序列的循环神经网络埋下伏笔。
循环神经网络RNN&长短时记忆网络LSTM
神经网络语言虽然解决了泛化问题,但是和N-gram模型一样,上下文窗口大小是固定的。为了预测下一个词,只能看到n-1个词,再早期的历史就被丢弃了,显然不符合人类理解语言的方式。
为了打破固定窗口限制,循环神经网络Recurrent Nerual Network出现了
核心思想:为网络增加记忆能力
RNN引入了一个隐藏状态hidden state 向量,我们可以将其理解为网络的短期记忆。处理序列的每一步,网络都会读取当前的书如此,并集合上一刻的短期记忆(上一个时间的隐藏状态)生成一个新的记忆(当前时刻隐藏状态)传递给下一时刻。这个循环往复的过程是的信息可以在序列中不断向后传递。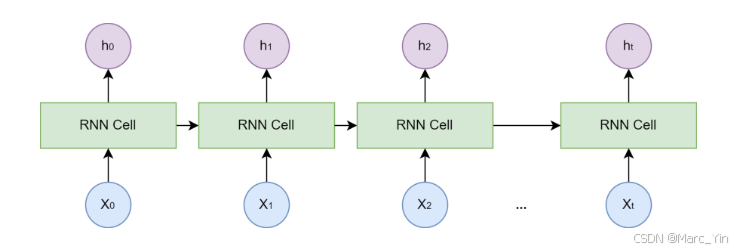
然而,标准的RNN在时间过程当中存在严重的一个问题——长期依赖问题 Long-term Dependency Problem。
训练过程中,模型需要使用反向传播算法根据输出端误差调整网络深处权重。
可以理解为:
最后一步预测出错了
错误一层层往回传递
使用梯度指导调整前面的的参数
存在的问题:
每往前传递一层,梯度(反向传播用)都会被乘一次
进而导致两种极端情况:
-
梯度消失:每次乘的数都小于1,梯度越来越接近0,前面的层几乎收不到训练信号,导致模型学习不到早期信息
-
梯度爆炸:每次乘的数都大于1,梯度越来越大,参数更新失控,训练不稳定甚至崩溃
最终导致模型难以学习序列中远距离信息依赖。信息传递越远,越容易导致信息被淡化失真,表现为“忘记前面的重要信息”
为了解决长期依赖问题,长短时记忆网络 Long Short Term Memory / LSTM 被设计出来。LSTM是一种特殊的RNN,核心在于引入细胞状态 Cell State和一套精密的门控机制Gating Mechanism
细胞状态:
一条贯穿整个序列的“主干信息通道”,专门负责保存长期记忆。
门控机制:
信息开关系统,通过“门”控制信息流入、保留、流出
-
遗忘门:决定旧信息保留多少
-
输入门:决定新信息写入多少
-
输出门:决定当前信息输出多少
Tranformer架构解析
RNN&LSTM通过循环结构处理序列数据。这种循环的计算方式带有瓶颈:
必须按照顺序处理数据。意味着RNN无法进行大规模的并行计算,处理长序列时效率低下,限制了模型的规模以及训练速度的提升。
Transformer架构使用注意力机制,完全抛弃循环结构,来捕捉序列内的依赖关系并实现了并行计算。
Encoder-Decoder整体结构
宏观上遵循了经典的编码器-解码器架构(因为最初Transformer模型是为了端到端机器翻译设计的)
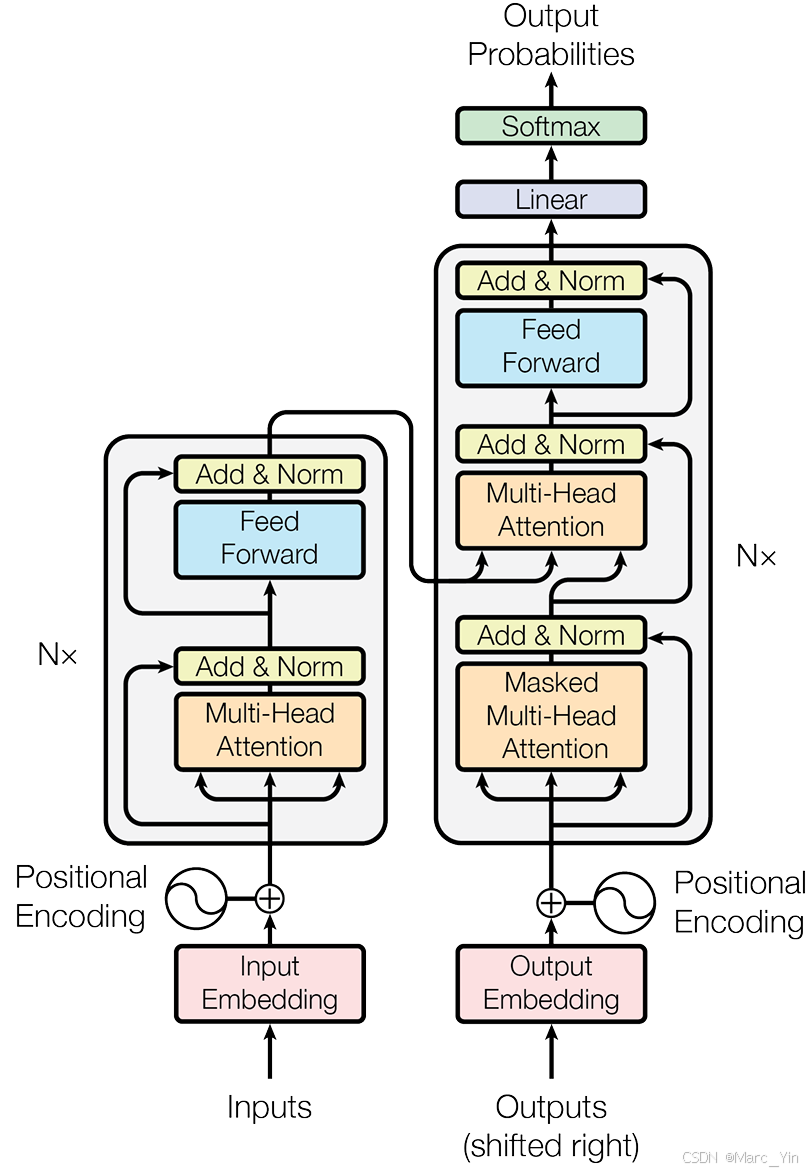
我们可以将整个架构理解为一个分工明确的团队:
-
编码器Encoder:
-
任务:理解输入的整个句子
-
读取所有输入的词元(token),最终为每个词元生成一个富含上下文的向量表示
-
-
解码器Decoder:
-
任务:生成目标句子
-
参考自己已经生成的前文,并咨询编码器的理解结局,生成下一个词
-
自注意力到多注意力
当人类理解“The agent learns because it is intelligent”。当我们读到it时候,我们会想“it是谁?”,之后我们大脑将更多注意力集中到agent这个词上。自注意力机制就是对这种现象的数学建模,允许模型在处理序列中某个词时,都能兼顾句子中其他词,并为每个词分配不同的注意力权重。权重越高的词,代表其与当前词关联性越强,信息也在当前词的表示中占据更大比重。
但是仅进行一次注意力计算(单头),模型可能只会学会关注一种类型的关联。EX:
处理it时,可能只学习到了关注主语。但是我们都知道,语言是复杂的,我们希望模型同时能够关注多种关系。多头注意力机制应运而生,思想:一次做完变成分成几组、分开执做之后合并。
类似让n个不同的的专家从其领域审视一句句子,每个专家从其领域捕捉到一种不同的特征关系,最后将这n个专家的意见(输出向量)拼接起来并进行整合,得到最终输出。
这种设计让模型能够管制来自不同位置、不同表示的自空间的信息,极大增强了模型的表达能力。
前馈神经网络Feed-Forward Network
每个Encoder/Decoder层中,多头注意力子层之后都跟着一个逐位置前馈神经网络。
意味着这个前馈神经网络会独立作用于序列中每个词元向量
注意力层负责“找信息”,而FFN负责“加工信息”
FNN是对每个词的单独处理,但是使用同一套参数。
可以这样理解:
输入是一个序列,每个词都有一个向量表示,FFN会一个词一个词的处理但是使用同一个“小网络”;——使用统一的加工机器对每个词轮流进行精加工。
FNN对词进行加工较为特殊,会先将数据维度放大(通常为4倍)之后缩小为原来大小。
为什么“先放大再缩小”?
👉理解:
放大(升维)
-
将信息投影到更高维空间
-
当于“打开更多表达空间”
👉类似:将简单的话展开为更加丰富的表达
缩小(降维)
-
提取重要信息
-
压缩回原来的表示空间
👉类似:复杂表达中提炼精华
FFN解决“每个词内部如何变成更强的表达”
残差连接&归一化
Transformer每个encoder/decoder中,所有子模块(EX:多头注意力/前馈神经网络)都被一个Add&Norm操作包裹。这个组合是为了保障Transformer能够稳定训练。
操作由两部分组成:
-
残差连接Add:该操作及那个子模块的输入
x直接加到该子模块的输出Sublayer(x)上。这个结构解决了深度神经网络的梯度消失问题。反向传播时,梯度可以绕过子模块直接向前传播,从而保障即使网络层数很深,模型也能够得到有效训练。 -
层归一化Norm:该操作对单个样本的所有特征进行归一化。这解决了模型训练过程中的内部协变量偏移问题,使每层输入分布保持稳定,从而加速模型收敛并提高训练稳定性。
内部协变量偏移
定义:训练过程当中,由于参数不断更新,导致后续曾输入数据的分布持续发生变化。
加速模型收敛
模型训练过程中,更快达到较低损失或者较优解
本质含义:
需要的训练步数更少
参数更快接近最优值
优化过程更稳定
位置编码
Transformer的核心是自注意力机制,通过计算序列中的任意两个词元间关系捕捉依赖。然而,这种计算方式有个固有问题:
计算方式本身并不包含任何关于词元顺序或者位置信息。
对于自注意力而言:“agent learns”和“learns agent”这两个序列是完全等价的,即使语义上相差十万八千里。
为了解决这个问题,Transformer架构引入的位置编码Postional Coding。
核心思想:为输入序列中的每个词元嵌入向量都额外加上一个能够代表其绝对位置和相对位置信息的“位置向量”。这个位置向量并不是通过学习得到的,而是通过固定公式直接计算。
这样,即使两个词元(EX:都是“agent”的词元)自身的向量相同,但是由于位置不同,最终输入到Transformer中的向量因为位置编码而不同。
Decoder-Only架构
Transformer架构用于构建一个与人对话、创作、作为智能体大脑的通用模型的话过于复杂。
Tranformer设计哲学:“先理解,再生成”
编码器负责深入理解输入的整个句子,形成一个包含全局信息的上下文记忆,然后解码器基于这份记忆生成翻译。
OpenAI在开发GPT时,提出更加简单思想:预测下一个最有可能出现的词。
无论是回答问题、编写故事还是生成代码,本质上都是在一个已有的文本序列后面一个词一个词地添加最为合理的内容。
基于这个思想,GPT进行了一个大胆的简化:抛弃编码器,仅保留解码器部分。
Decoder-Only工作模式被称为“自回归”,整体过程:
-
给模型一个起始文本
-
模型预测下一个最有可能出现的此
-
模型将自己生成的词添加到输入文本的末尾,形成新的输入
-
模型基于新输入,再次预测下一个词
-
不断重复这个过程直到生成完整句子或者达到停止条件。
掩码自注意力
而上述架构存在一定问题:“偷看未来的词”
训练时,Decoder-Only架构的模型通常采用Teach-Forcing:一次性输入整句
而自注意力默认是全连接的。每个位置都可以关注序列中的所有位置。
如果不进行限制,预测第t个的时候会直接看到t+1、t+2……的真实词。这就造成了信息泄漏,污染了训练。
-
训练阶段:能够看到未来词
-
推理阶段:仅能够看到已经生成的文本,一个一个词生成
👉问题就在于:训练时需要人为限制信息流,否则训练&推理并不一致
Decoder-Only架构中通过掩码自注意力机制进行解决:
本质:计算注意力分数时,对未来位置进行屏蔽(通过对未来位置加上极大的负数,使其权重接近0)强制模型只能关注已有信息,实现自回归。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)