零基础学AI人工智能:6.2 python进阶之闭包和装饰器
大家好,上一篇我们学习了 Python 面向对象编程的核心思想与三大特征,掌握了封装、继承、多态等高级编程思维。而在 Python 进阶语法中,闭包、装饰器与深浅拷贝是三类极具特色的高级特性,它们在 AI 开发中有着广泛的应用:装饰器可用于日志记录、性能统计、权限校验,闭包可用于状态保持与函数增强,深浅拷贝则是处理复杂数据结构时的必备工具。今天我们就来系统学习这三大进阶特性,帮大家掌握 Python 的高级语法技巧,写出更优雅、更高效的代码。
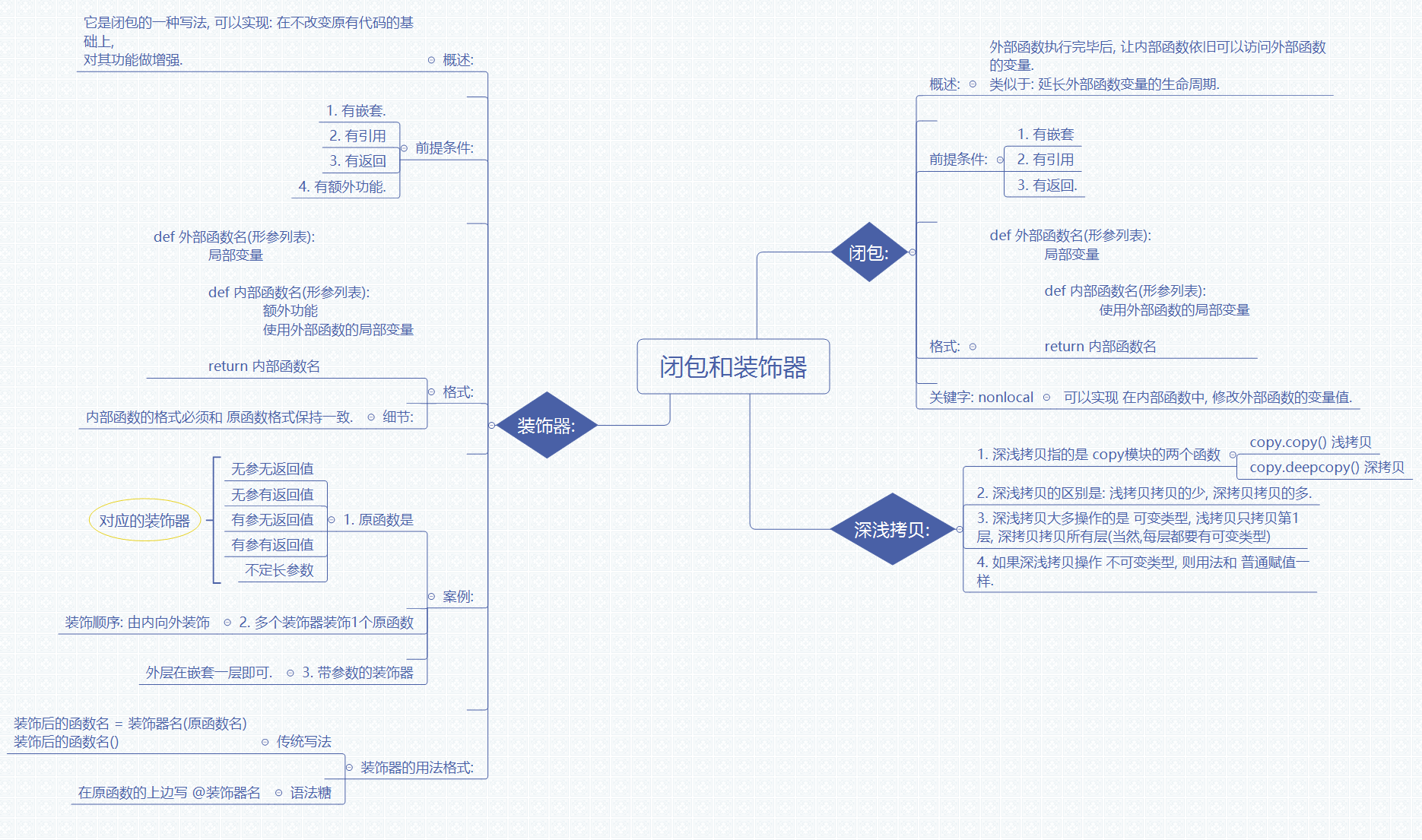
一、闭包的核心概念与底层逻辑
1.1 什么是闭包?
闭包是一种基于嵌套函数实现的高级特性,它的核心作用是在不修改原有代码的基础上,对原有函数的功能进行增强,同时延长外部函数局部变量的生命周期。我们可以把它理解为一个 “带状态的函数”,内部函数可以持续访问外部函数的局部变量,即使外部函数已经执行完毕。
1.2 闭包的核心前提条件
要实现一个标准的闭包,必须同时满足以下四个前提条件:
- 存在函数嵌套结构,即外部函数内部定义了内部函数;
- 内部函数引用了外部函数的局部变量;
- 外部函数将内部函数作为返回值返回;
- 内部函数包含额外的功能逻辑,实现对原有逻辑的增强。
1.3 闭包的核心价值与作用
闭包的核心价值主要体现在以下两点:
- 实现功能增强:无需修改原有函数的代码,即可为函数添加额外的逻辑,比如日志记录、参数校验等;
- 延长变量生命周期:外部函数执行完毕后,其局部变量不会被销毁,内部函数依然可以访问和使用这些变量,实现状态的保持。
1.4 闭包的关键细节:nonlocal 关键字
在闭包中,内部函数默认只能读取外部函数的局部变量,无法直接修改。如果需要在内部函数中修改外部函数的局部变量值,就需要使用nonlocal关键字,它可以声明变量属于外部函数的作用域,从而实现对外部变量的修改。
二、装饰器的核心概念与实现逻辑
2.1 什么是装饰器?
装饰器是基于闭包实现的一种语法糖,它的核心作用是在不修改原有函数代码、不改变原有函数调用方式的前提下,为函数添加额外的功能,比如日志记录、性能统计、权限校验、缓存等,是 Python 中实现面向切面编程的核心工具。
2.2 装饰器的核心实现前提
装饰器的实现依赖于闭包的特性,因此它的核心前提条件和闭包一致,需要同时满足嵌套、引用、返回的条件,同时内部函数的格式必须和原函数保持一致,才能保证原函数的调用不受影响。
2.3 装饰器的分类与对应场景
根据原函数的参数和返回值情况,装饰器可以分为以下五类,分别对应不同的使用场景:
- 无参数无返回值的装饰器:适用于原函数不需要参数、也没有返回值的场景;
- 无参数有返回值的装饰器:适用于原函数不需要参数,但有返回值的场景;
- 有参数无返回值的装饰器:适用于原函数需要参数,但没有返回值的场景;
- 有参数有返回值的装饰器:适用于原函数既需要参数,也有返回值的场景;
- 不定长参数的装饰器:适用于原函数的参数数量不确定的场景,通用性最强,可适配所有函数。
2.4 装饰器的两种用法格式
装饰器有两种常用的用法格式,分别适用于不同的场景:
- 传统写法:通过赋值的方式,将装饰器处理后的函数赋值给原函数名,后续直接调用新的函数名即可;
- 语法糖写法:在原函数的上方添加装饰器标记,简化装饰器的使用方式,代码更简洁直观,是实际开发中最常用的方式。
2.5 多装饰器与带参数装饰器的细节
在使用装饰器时,有两个高频使用的场景需要注意:
- 多个装饰器装饰同一个原函数:装饰的顺序是由内向外的,即离原函数最近的装饰器先执行,离原函数最远的装饰器最后执行;
- 带参数的装饰器:需要在原有装饰器的外层再嵌套一层函数,用于接收装饰器的参数,实现更灵活的装饰逻辑。
三、深浅拷贝的核心概念与区别
3.1 什么是深浅拷贝?
深浅拷贝是 Python 中用于复制数据结构的两种方式,它们是 copy 模块提供的核心功能,分别对应不同的复制逻辑:
- 浅拷贝:仅复制数据结构的第一层,不会递归复制内部的嵌套数据;
- 深拷贝:会递归复制数据结构的所有层级,包括所有嵌套的数据。
3.2 深浅拷贝的核心区别
深浅拷贝的核心区别主要体现在以下四个方面:
- 复制的层级不同:浅拷贝仅复制数据的第一层,深拷贝会复制数据的所有层级;
- 对可变类型的处理不同:浅拷贝操作可变类型时,原数据和拷贝后的数据会共享内部的嵌套数据;深拷贝会递归复制所有层级,原数据和拷贝后的数据完全独立,互不影响;
- 对不可变类型的处理不同:如果操作的是不可变类型,深浅拷贝的用法和普通赋值完全一样,没有区别;
- 内存占用不同:深拷贝会创建完全独立的副本,内存占用更高;浅拷贝仅复制第一层,内存占用更低。
3.3 深浅拷贝的使用场景与注意事项
在实际开发中,需要根据数据结构的复杂度选择合适的拷贝方式:
- 浅拷贝适用于数据结构简单、没有嵌套可变类型的场景,效率更高;
- 深拷贝适用于数据结构复杂、存在多层嵌套可变类型的场景,需要保证原数据和拷贝数据完全独立,互不干扰;
- 注意:如果数据中存在循环引用,深拷贝可能会出现性能问题,需要特殊处理。
四、逻辑图

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 16
16 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)