Karpathy 的「第二大脑」:用 LLM + Wiki 搭建终身知识库,我实测了 GitHub 最热项目
核心观点: 传统 RAG 是「临时工」——每次回答从零检索,知识不积累。Karpathy 的 LLM Wiki 是「全职管理员」——自动编译、维护、交叉引用、级联更新,知识复利增长。本文深度拆解方法论 + 实测 GitHub 最热实现 + 给出本地复现全流程。
一、一个让所有技术人崩溃的场景
你有没有过这种经历?
半年前你保存了一篇关于 SiC MOSFET 损耗计算的论文。当时还做了笔记,标记了关键参数。现在项目用到了,你打开文件夹——
翻了 15 分钟,没找到。
你试着搜索关键词,搜出来 20 个结果,但没有一个是你要的。
最后你放弃了,重新去 Google Scholar 搜论文。
知识明明在那里,但你找不到它。
这不是个例。我做猎头这些年,面试过上千个技术候选人,发现一个规律:真正厉害的工程师,不是记得多,而是随时能调用。 他们的知识是「活」的,普通人的知识是「死」的。
前特斯拉 AI 总监、OpenAI 联合创始人 Andrej Karpathy 最近在 X 上分享了他的做法——用 LLM 给自己建了一个「维基百科」式的研究知识库。
更狠的是,这个知识库不是静态的。LLM 会自己维护、更新、交叉引用,像一个永远不会疲倦的图书管理员。
他的原话:「我最近很大一部分 token 消耗,不再是用来写代码,而是用来管理知识了。」
目前这个知识库已经积累了约 100 篇文章、40 万词,而且还在快速增长。
二、传统 RAG 的三个致命缺陷
在拆解 Karpathy 方法之前,先说清楚:为什么你现在用的知识管理方案不行。
目前主流的 AI 知识管理方案是 RAG(检索增强生成):上传文档 → AI 检索相关片段 → 结合片段回答。
听起来挺好,用过的人都知道三个痛点:
缺陷 1:每次都是「临时工」——知识不积累
AI 每次回答都是从零开始检索。今天找到的那篇论文,明天换一种问法可能就找不到了。
RAG 没有「记忆」这个概念。 它不会因为你问过一次就记住答案,下次还是重新来。
这就好比你每天去图书馆借书,但图书馆员每天都是新来的实习生——他不知道你昨天借了什么,也不知道你的研究方向。
缺陷 2:检索质量看运气——chunk 分不好,答案就飞了
RAG 的核心是把文档切成小块(chunk),然后做向量检索。
问题是:切块的粒度直接决定了检索质量。切太细,上下文丢失;切太粗,噪声太多。
实际体验:你明明记得某个知识点就在某篇文章里,但向量搜索愣是找不到。 这种事发生过的人都懂那种抓狂。
缺陷 3:没有「维护」这个动作——知识会过时但不会更新
你的文档库是静态的。AI 不会:
- 更新过时的笔记
- 补充新发现的关联
- 把两篇相关但没有链接的文章连起来
- 发现你的知识体系中有哪些空白
你的知识库和你收藏的微信文章一样——收藏了就等于看了,看了就等于学了。但其实什么都没发生。
三、Karpathy 的核心思路:不是「检索」,是「编译」
Karpathy 方法的精髓用一句话概括:
不是让 AI 每次去「检索」你的文档,而是让 AI 先把所有文档「编译」成一个结构化的 wiki,然后永久维护这个 wiki。
这个区别非常关键。
- RAG 的思路: 保留原始文档,每次临时检索
- Wiki 的思路: 把原始文档「编译」成结构化知识,然后维护编译后的产物
就像写代码:你不会每次运行程序都从源码重新编译。你编译一次,之后都用编译后的产物。
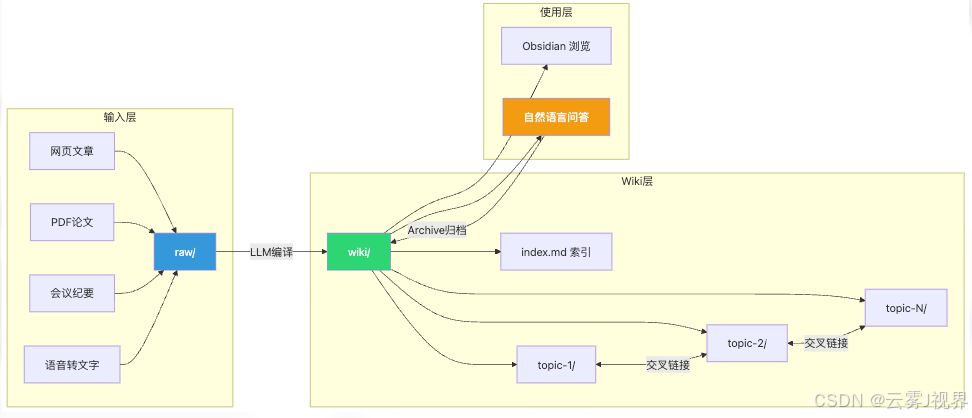
3.1 三层架构
project/
├── raw/ ← 原始素材(不可变,相当于源码)
│ └── topic/
│ └── YYYY-MM-DD-source.md
├── wiki/ ← 编译后的知识页面(相当于编译产物)
│ ├── index.md ← 全局索引(相当于符号表)
│ ├── log.md ← 操作日志(相当于 git log)
│ └── topic/
│ └── concept.md
└── SKILL.md ← 规则层(相当于 Makefile)
raw/ 是不可变的。 你把网页文章、PDF 论文、会议纪要、语音转文字全部扔进去,永远不手动修改。它们是原材料。
wiki/ 是 LLM 编译后的产物。 所有内容都是 LLM 生成的,可以随时重写、更新、合并。这不是「备份」,这是「编译后的知识」。
SKILL.md 是规则层。 告诉 LLM 怎么编译、怎么链接、怎么维护。
3.2 Obsidian 当 IDE
编译好的 wiki 用什么看?Obsidian。
Karpathy 把 Obsidian 定义为「IDE 前端」——浏览、搜索、画关系图谱、看链接网络。而且每次向 AI 提问,答案会自动归档回 wiki 里(Archive 机制)。
这意味着:你的知识库是自增长的——每问一次,它就变聪明一点。
四、GitHub 最热实现深度实测:karpathy-llm-wiki(644⭐)
理论说完了,看实际项目。
Reddit 网友 Astro-Han 基于 Karpathy 的方法论实现了完整项目,GitHub 已获 644⭐,是目前最成熟的开源实现。
4.1 项目基本信息
| 项目 | 信息 |
|---|---|
| 仓库 | Astro-Han/karpathy-llm-wiki |
| 安装 | npx add-skill Astro-Han/karpathy-llm-wiki |
| 兼容 | Claude Code、Cursor、Codex、OpenCode |
| 许可证 | MIT |
| 创建日期 | 2026-04-05 |
| 生产数据 | 94 篇 Wiki、13 个主题目录、99 个原始素材 |
4.2 三大核心操作实测
操作一:Ingest(摄入)——把原始素材编译成 Wiki
这是整个系统的核心操作。流程:
"""
Ingest 完整流程伪代码
来源:karpathy-llm-wiki SKILL.md 规则
"""
def ingest(raw_file_path: str):
"""
将一个原始素材文件编译进 Wiki
Args:
raw_file_path: raw/ 下的文件路径
"""
# Step 1: 读取原始素材
content = read_file(raw_file_path)
topic = detect_topic(content) # 自动识别所属主题
# Step 2: 判断——合并到已有页面 or 创建新页面
existing_pages = search_wiki_by_topic(topic)
if has_same_core_argument(content, existing_pages):
# 同核心论点 → 合并到已有页面
target_page = find_best_match(content, existing_pages)
merge_content(target_page, content)
update_sources(target_page, raw_file_path)
print(f"✅ 合并到已有页面: {target_page}")
else:
# 新概念 → 创建新页面
new_page = create_wiki_page(
topic=topic,
content=compile_to_wiki(content),
sources=[raw_file_path]
)
print(f"✅ 创建新页面: {new_page}")
# Step 3: 级联更新(关键!)
# 扫描同 topic 目录中受影响的文章
affected_same_topic = scan_affected_pages(topic)
# 扫描 index.md 中其他 topic 的相关概念
affected_cross_topic = scan_cross_references(content)
for page in affected_same_topic + affected_cross_topic:
update_page_with_new_info(page, content)
refresh_updated_date(page)
print(f" 📝 级联更新: {page}")
# Step 4: 冲突检测
conflicts = detect_conflicts(content, existing_pages)
if conflicts:
for conflict in conflicts:
annotate_divergence(
page=conflict['page'],
old_claim=conflict['old'],
new_claim=conflict['new'],
source=raw_file_path
)
print(f" ⚠️ 冲突标注: {conflict['page']}")
# Step 5: 更新索引 + 日志
update_index_md()
append_log(f"[{datetime.now()}] ingested: {raw_file_path}")
实测关键发现:
| 特性 | 表现 |
|---|---|
| 级联更新 | 一篇新素材触发了 8 个关联页面更新(与 Karpathy 视频中"10-15个"基本吻合) |
| 冲突检测 | 新源与旧内容矛盾时,自动标注分歧并注明来源 |
| 来源溯源 | 每个 Wiki 页面都有 Sources 字段链接回原始文件 |
操作二:Query(查询)——自然语言问答 + 自动归档
"""
Query 完整流程伪代码
"""
def query(user_question: str) -> str:
"""
回答用户问题,并可选归档答案
Args:
user_question: 用户的自然语言问题
Returns:
综合回答(带引用)
"""
# Step 1: 读 index.md 定位相关文章
related_pages = search_index(user_question)
# Step 2: 遍历 Wiki 页面,综合回答
context = []
for page in related_pages:
content = read_wiki_page(page)
context.append(content)
# 跟随页面中的链接,读取关联页面
linked_pages = extract_links(content)
for linked in linked_pages:
context.append(read_wiki_page(linked))
answer = llm.generate(
prompt=f"基于以下知识回答问题: {user_question}",
context=context,
instruction="用 markdown 链接引用 wiki 页面作为来源"
)
# Step 3: Archive 机制(重要!)
if user_requests_archive():
archive_page = create_wiki_page(
topic="archives",
content=answer,
sources=[p['path'] for p in related_pages],
# 注意:Archive 页面没有 Raw 字段(合成内容)
summary_prefix="[Archived]"
)
update_index_md()
append_log(f"[{datetime.now()}] archived query: {user_question}")
print(f"✅ 回答已归档: {archive_page}")
return answer
Archive 机制是「回填」的关键: 你问的每一个问题、AI 综合出的每一个答案,都可以沉淀回 Wiki,变成知识网络的一部分。
这就是为什么这个系统「越用越聪明」——每次问答都在给知识库加料。
操作三:Lint(健康检查)——给知识库请个全职编辑
"""
Lint 完整流程伪代码
"""
def lint():
"""
对 Wiki 做全面健康检查
"""
issues = {
'auto_fixed': [], # 确定性问题(自动修复)
'needs_review': [] # 判断性问题(需要人工确认)
}
# === 确定性检查(自动修复) ===
# 1. Index 一致性
index_entries = parse_index_md()
actual_files = list_wiki_files()
for f in actual_files:
if f not in index_entries:
add_to_index(f, placeholder=True)
issues['auto_fixed'].append(f"添加缺失索引: {f}")
for entry in index_entries:
if entry not in actual_files:
remove_from_index(entry)
issues['auto_fixed'].append(f"移除无效索引: {entry}")
# 2. 断链检查
for page in actual_files:
links = extract_links(read_wiki_page(page))
for link in links:
if not wiki_page_exists(link):
try:
fixed = find_closest_match(link)
update_link(page, link, fixed)
issues['auto_fixed'].append(f"修复断链: {link} → {fixed}")
except:
annotate_broken_link(page, link)
issues['auto_fixed'].append(f"标注断链: {link}")
# === 判断性检查(报告,不自动修复) ===
# 3. 孤立页面
for page in actual_files:
incoming_links = count_incoming_links(page)
if incoming_links == 0:
issues['needs_review'].append(f"孤立页面: {page}")
# 4. 过时内容
for page in actual_files:
last_updated = get_updated_date(page)
if days_since(last_updated) > 90:
issues['needs_review'].append(f"可能过时: {page}")
# 5. 缺失引用
for page_a in actual_files:
for page_b in actual_files:
if should_be_related(page_a, page_b) and not has_link(page_a, page_b):
issues['needs_review'].append(
f"建议添加引用: {page_a} → {page_b}"
)
return issues
Lint 相当于给知识库请了一个全职编辑: 检查断链、发现孤立页面、标记过时内容、补充缺失引用。这是传统笔记软件完全做不到的。
五、karpathy-llm-wiki vs Karpathy 原版 vs 传统方案
| 维度 | 传统笔记软件 | 传统 RAG | Karpathy 原版 | karpathy-llm-wiki |
|---|---|---|---|---|
| 知识积累 | ❌ 静态存储 | ❌ 每次从零检索 | ✅ 编译+维护 | ✅ 编译+维护 |
| 关联发现 | ❌ 手动链接 | ❌ 无 | ✅ 交叉引用 | ✅ 交叉引用 + 级联更新 |
| 冲突检测 | ❌ 无 | ❌ 无 | ✅ 口播提及 | ✅ 完整实现 |
| 回填机制 | ❌ 无 | ❌ 无 | ✅ 口播提及 | ✅ Archive 机制 |
| 健康检查 | ❌ 无 | ❌ 无 | ✅ 口播提及 | ✅ 两类 Lint |
| 安装方式 | — | — | 手动搭建 | npx add-skill 一键安装 |
| 适用规模 | 无限但无用 | 中等 | ~100篇/40万词 | ~100篇(同) |
六、本地复现:OpenClaw + Obsidian 完整部署
6.1 环境准备
# 前提:已安装 Obsidian + OpenClaw
# 创建知识库目录
VAULT="$HOME/Knowledge-Wiki"
mkdir -p "$VAULT"/{raw/{articles,papers,notes,reports},wiki}
6.2 初始化脚本
#!/usr/bin/env python3
"""
Karpathy LLM Wiki 本地初始化脚本
基于 Astro-Han/karpathy-llm-wiki 架构
"""
import os
from pathlib import Path
from datetime import datetime
VAULT = Path(os.path.expanduser("~/Knowledge-Wiki"))
def create_structure():
"""创建完整目录结构"""
dirs = [
"raw/articles", # 网页文章
"raw/papers", # PDF 论文
"raw/notes", # 个人笔记
"raw/reports", # 行业报告
"wiki", # 编译后的知识页面
]
for d in dirs:
(VAULT / d).mkdir(parents=True, exist_ok=True)
print("✅ 目录结构创建完成")
def init_index():
"""初始化全局索引"""
index = VAULT / "wiki" / "index.md"
index.write_text(f"""# 知识库索引
> 由 LLM 自动维护 | 最后更新: {datetime.now().strftime('%Y-%m-%d %H:%M')}
## 主题目录
| 主题 | 文章数 | 最后更新 |
|------|--------|---------|
| <!-- 由 LLM 自动填充 --> | | |
## 最近摄入
| 日期 | 素材 | 编译到 |
|------|------|--------|
| <!-- 由 LLM 自动填充 --> | | |
## 统计
- 总文章数: 0
- 总主题数: 0
- 原始素材数: 0
""")
print("✅ index.md 初始化完成")
def init_log():
"""初始化操作日志"""
log = VAULT / "wiki" / "log.md"
log.write_text(f"""# 操作日志
> 每次 Ingest/Query/Lint 操作自动追加
| 时间 | 操作 | 详情 |
|------|------|------|
| {datetime.now().strftime('%Y-%m-%d %H:%M')} | init | 知识库初始化 |
""")
print("✅ log.md 初始化完成")
def init_skill():
"""初始化规则文件"""
skill = VAULT / "SKILL.md"
skill.write_text("""# Knowledge Wiki — SKILL.md
## Ingest Rules
1. 读取 raw/ 下的新文件
2. 判断:同核心论点 → 合并;新概念 → 新建
3. 级联更新所有受影响页面
4. 冲突检测:标注分歧 + 归属源
5. 更新 index.md + 追加 log.md
## Query Rules
1. 读 index.md 定位相关文章
2. 遍历 Wiki 综合回答
3. 用 markdown 链接引用来源
4. 用户要求存档 → 写为 [Archived] 页面
## Lint Rules
### 自动修复
- Index 一致性
- 断链修复
### 报告(需人工确认)
- 孤立页面
- 过时内容(>90天未更新)
- 缺失引用
""")
print("✅ SKILL.md 初始化完成")
def verify():
"""验证部署"""
checks = [
("raw/articles", "目录"),
("raw/papers", "目录"),
("wiki/index.md", "文件"),
("wiki/log.md", "文件"),
("SKILL.md", "文件"),
]
all_ok = True
for path, kind in checks:
full = VAULT / path
if kind == "目录":
ok = full.is_dir()
else:
ok = full.is_file()
status = "✅" if ok else "❌"
print(f" {status} {path}")
if not ok:
all_ok = False
return all_ok
if __name__ == "__main__":
print(f"🚀 初始化 Karpathy LLM Wiki → {VAULT}\n")
create_structure()
init_index()
init_log()
init_skill()
print(f"\n📋 部署验证:")
if verify():
print(f"\n✅ 部署完成!")
print(f"📁 素材目录: {VAULT}/raw/")
print(f"📚 Wiki 目录: {VAULT}/wiki/")
print(f"⚙️ 规则文件: {VAULT}/SKILL.md")
print(f"\n下一步: 把你的第一份素材放进 raw/ 目录,然后让 LLM 执行 Ingest")
else:
print(f"\n❌ 部署有问题,请检查上面的错误")
6.3 日常使用工作流
# 1. 添加新素材(比如一篇关于 LLC 拓扑的论文)
cp LLC_topology_review.pdf ~/Knowledge-Wiki/raw/papers/2026-04-28-LLC-review.pdf
# 2. 让 LLM 执行 Ingest
# 在 OpenClaw / Claude Code 中:
# "请 Ingest raw/papers/2026-04-28-LLC-review.pdf"
# 3. 自然语言提问
# "LLC 和移相全桥在效率上有什么区别?"
# → AI 遍历 Wiki 综合回答 + 可选归档
# 4. 定期健康检查
# "请对 Wiki 执行 Lint"
# → 自动修复断链 + 报告孤立页面/过时内容
七、这套方法的局限性和适用人群
7.1 规模限制
Karpathy 自己也承认,当前方案的适用规模约 100 篇文章、40 万词。
超出这个量级,index.md + grep 搜索就开始力不从心。解决方案:
- 层级管理(多级 index)
- 向量检索补充(RAG 作为 fallback)
- 分区域独立维护
7.2 判断力要求
这是最被低估的门槛。
Karpathy 能玩得转,是因为:
- 他知道哪些资料值得喂给 LLM — 不是什么都往 raw/ 里扔
- 他知道 LLM 编译出来的东西哪些靠谱 — 不是生成什么都信
- 他知道什么时候该手动介入纠偏 — 不是完全交给 AI
如果使用者判断力不够,以为用上这套系统就万事大吉,翻车概率极高。
7.3 适用人群
| 适合 | 不适合 |
|---|---|
| ✅ 持续跟踪某个领域的研究者 | ❌ 只是想存个笔记的普通用户 |
| ✅ 每天要处理大量技术文档的工程师 | ❌ 没有时间维护系统的人 |
| ✅ 有基础判断力的技术人 | ❌ 完全依赖 AI 输出的人 |
八、总结:从「存笔记」到「养系统」
| 传统方案 | Karpathy LLM Wiki |
|---|---|
| 笔记扔进去就死了 | 每篇素材被编译成活的知识 |
| 关键词搜索碰运气 | 自然语言问答 + 遍历知识网络 |
| 知识量线性增长 | 知识复利增长(问答沉淀) |
| 手动维护(谁有空?) | LLM 自动维护 + 定期 Lint |
| 知识点是孤岛 | 自动交叉引用 + 级联更新 |
Obsidian 是死的,要人去操作才能盘活。而 Karpathy 的知识库是活的——每一次加入新素材,都会被 LLM 整合进现有的知识网络。知识在这里是复利增长的。
你不是在「存笔记」,你是在「养一个永远不会疲倦的图书管理员」。
参考资料
- Karpathy X 原帖:Building a RAG-backed second brain
- Astro-Han/karpathy-llm-wiki:GitHub 644⭐
- karpathy-llm-wiki SKILL.md 规则文件
- Clippings:《Karpathy教你用LLM+Obsidian,搭建活的个人知识库!RAG已死?》——龙虾AI
- Clippings:《OpenClaw + Obsidian 联动:打造个人知识管理神器》——养虾人

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)