RAG 深度解析:从架构原理到模型选型,打造可靠的企业知识库
大模型很强大,但它不知道你家产品的退换货政策,也不知道上个月新出的技术文档。
RAG(检索增强生成)让模型“外挂”知识库,成为企业落地的关键技术。
本文不讲空话,从架构到选型,带你理清 RAG 的每个关键环节。
一、RAG 整体架构
1.1RAG 的两条管道
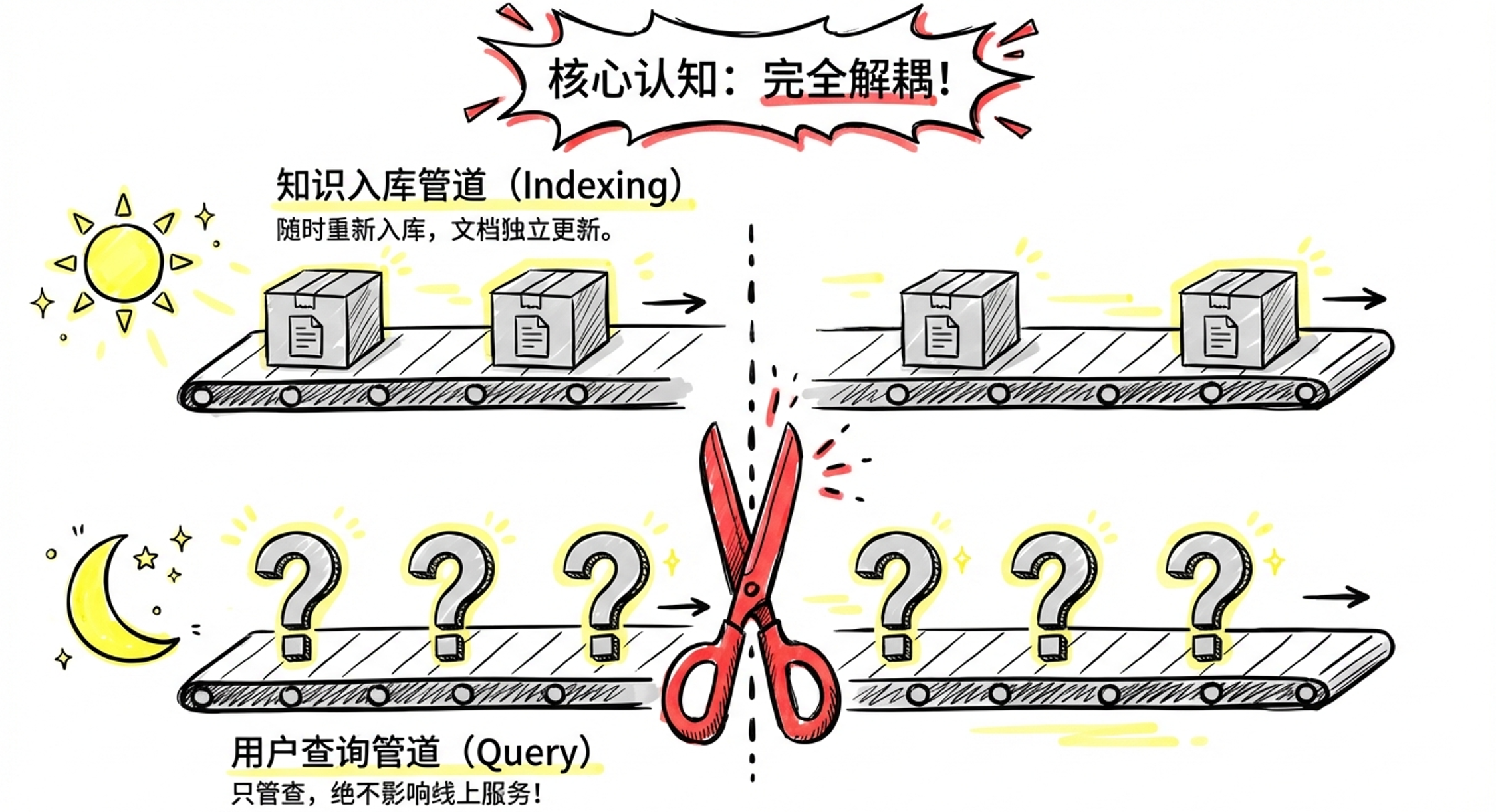
RAG 由两条独立的管道组成,执行时机不同,但完全解耦。
1.1.1📥 Indexing Pipeline(索引管道)—— 离线执行
原始文档 → 文档加载 → 分块 → 向量化 → 存入向量库-
文档加载:读取 PDF、Word、TXT 等,提取文字(扫描件必须 OCR)
-
分块(Chunking):将长文档切成小片段 —— 最关键环节之一
-
向量化(Embedding):文本 → 高维向量
-
向量存储:保存“向量 + 原文 + Metadata”
1.1.2📤 Query Pipeline(查询管道)—— 在线执行
用户问题 → [查询处理] → 检索 → [后处理] → 生成答案-
查询处理(可选):改写口语化问题、扩展查询、识别意图
-
检索:向量相似度搜索,取回 TopK 个最相关片段
-
后处理(可选):重排序(Reranker)、上下文压缩、去重
-
生成:将检索内容注入 Prompt,模型基于上下文回答
两条管道完全解耦意味着:知识更新只需重跑索引管道,线上查询服务完全不受影响。
1.2 Naive RAG vs Advanced RAG
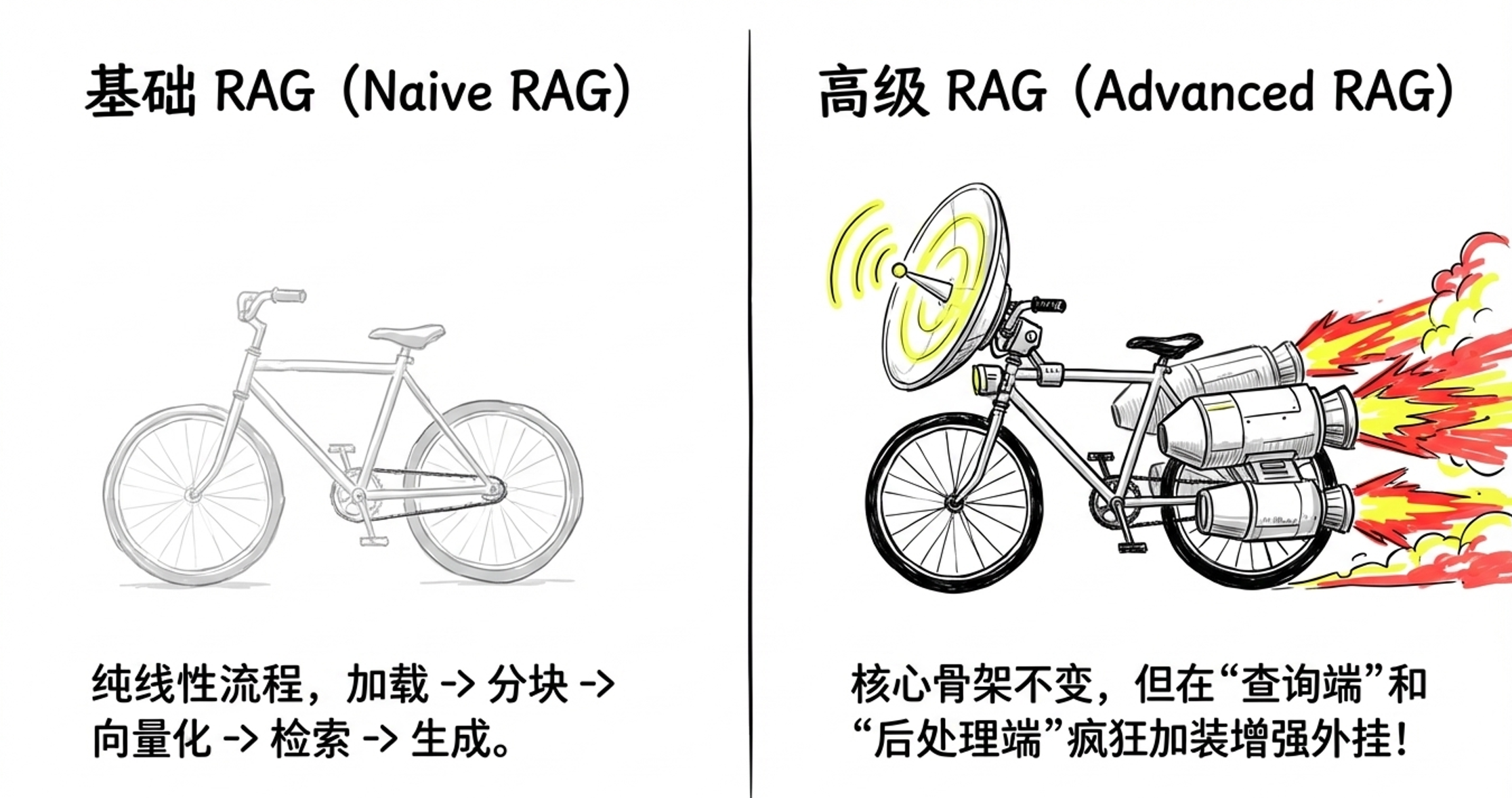
上面描述的是基础 RAG(Naive RAG),流程线性:加载 → 分块 → 向量化 → 检索 → 生成。
实际生产中,基础 RAG 的常见问题:
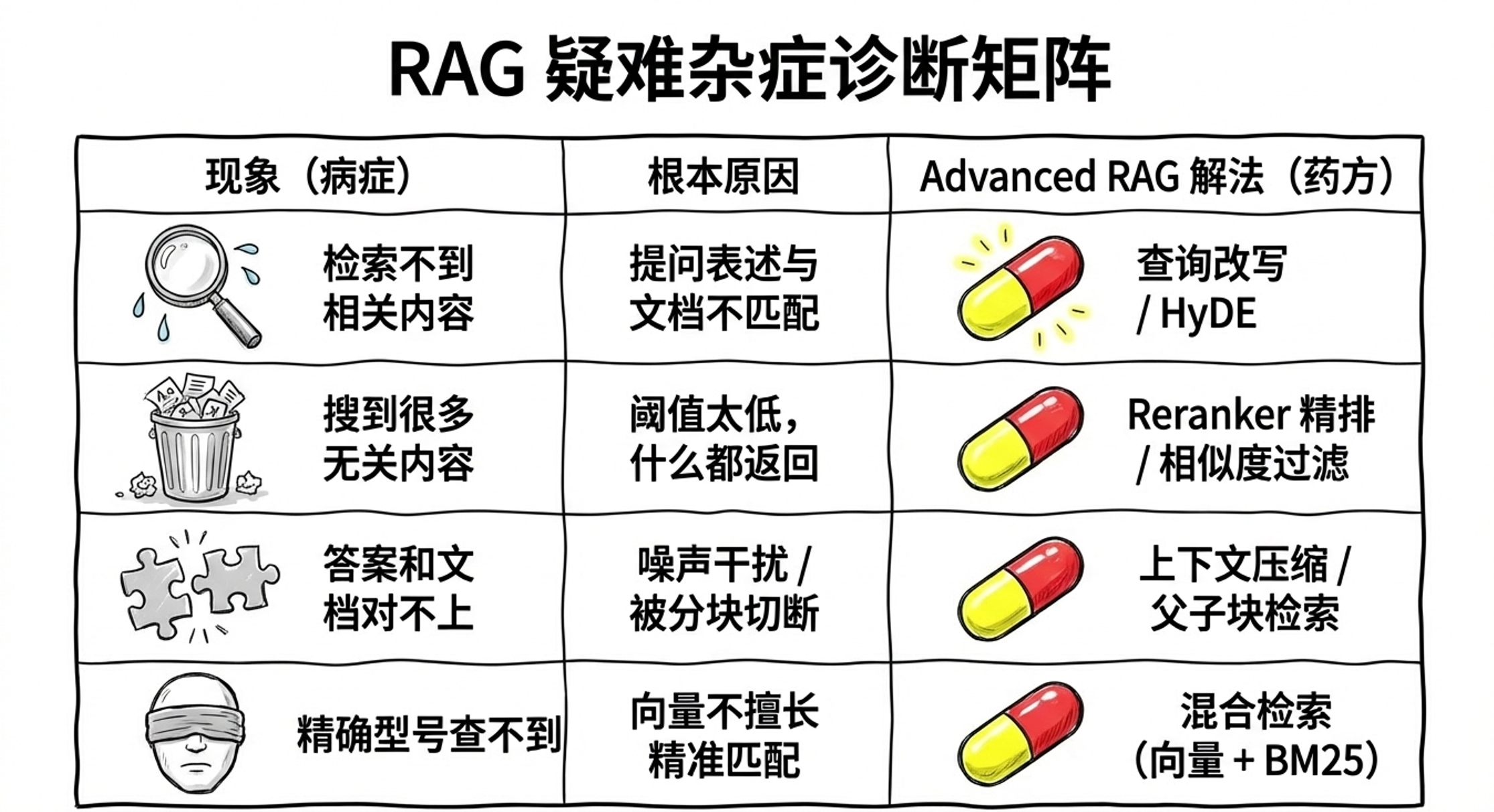
| 问题现象 | 根本原因 | Advanced RAG 解法 |
|---|---|---|
| 检索不到相关内容 | 查询表述与文档不匹配 | 查询改写、HyDE |
| 检索到大量无关内容 | 相似度阈值太低 | Reranker、相似度过滤 |
| 答案不准确 | 内容被分块切断 | 更好的分块策略、父子块检索 |
| 答案与文档对不上 | 噪声内容干扰 | 上下文压缩 |
| 精确值查不到 | 向量检索不擅长精确匹配 | 混合检索(向量 + BM25) |
| 跨文档推理做不到 | 局部语义匹配 | Graph RAG |
1.3完整的 RAG 架构图

Indexing Pipeline(离线)
────────────────────────────────────────────────────────────────
原始文档(PDF / Word / HTML / DB / 代码...)
↓ Document Loader(格式解析)
Document(原始文字 + Metadata)
↓ Document Transformer(清洗 + 分块)
List<TextSegment>(切块后的片段)
↓ Embedding Model(语义向量化)
List<Embedding>(高维浮点向量)
↓ Vector Store(持久化存储)
向量库(PGVector / Qdrant / Milvus)
Query Pipeline(在线,每次提问)
────────────────────────────────────────────────────────────────
用户问题(自然语言)
↓ [可选] Query Transformer(改写 / 扩展 / 路由)
优化后的查询
↓ Embedding Model(问题向量化)
↓ Vector Store.search(TopK 相似度搜索)
List<TextSegment>(候选结果,通常 10-20 条)
↓ [可选] Reranker(Cross-Encoder 精排)
↓ [可选] Context Compressor(块内噪声过滤)
最终上下文(通常 3-8 条高质量片段)
↓ Prompt 构建(System + 检索结果 + 用户问题)
↓ Chat Model(大模型推理)
最终答案(含来源引用)二、写代码前先想清楚这 4 个问题,否则你的 RAG 只会“跑起来”却“答不准”
我见过太多人上来就找教程、复制代码、跑起来——然后三天后发现检索效果很差,不知道从哪里改起。
RAG 系统不是“跑起来”就算成了,而是“回答得准”才算成了。跑起来很容易,准起来很难。
在此,我们先把关键的选型和配置问题想清楚,不然代码写完反而要推翻重来。
2.1我要用哪个 Embedding 模型?
这个决定影响你整个 RAG 系统的天花板。一旦入库完成,中途换模型意味着所有数据必须重新入库。所以开始前想清楚。
核心判断:文档主要是什么语言?
-
纯中文或中英混合:我的第一推荐是通义千问的
text-embedding-v3。
原因:阿里自己训练的,中文语义理解比 OpenAI 强;国内网络直接访问,不用翻墙;API 价格便宜。 -
纯英文:
text-embedding-3-small(OpenAI)是主流选择,效果稳定,价格也不贵。 -
对数据安全有要求,不能调外部 API:本地部署 BGE 系列(
bge-m3或bge-large-zh)。效果和商业 API 差距不大,但需要自己维护服务。
另一个不能忽视的指标:向量维度
不同模型的输出维度不同,这个数字必须记住,后面配向量数据库时需要填对:
| 模型 | 维度 | 适用场景 |
|---|---|---|
text-embedding-v3(通义) |
1024 或 2048(可配) | 中文首选 |
text-embedding-3-small(OpenAI) |
1536 | 英文 / 通用 |
text-embedding-3-large(OpenAI) |
3072 | 高精度场景,贵 |
bge-m3(本地) |
1024 | 离线部署 |
bge-small-zh(本地) |
512 | 资源受限场景 |
维度填错是最常见的报错来源。向量数据库配置里的
dimensions必须和你选的模型完全一致,差一个数字就报vector dimension mismatch。我当年查了半小时才发现是这个原因。
2.2我要用哪个向量数据库?
这个决定主要看你处于什么阶段、数据量多大。
| 数据库 | 适用阶段 | 特点 |
|---|---|---|
| SimpleVectorStore | 开发/快速验证 | Spring AI 内置内存库,不用装任何东西,启动就能用。程序重启数据就没了,生产环境绝对不能用它。 |
| PGVector | 正式项目 / 中小规模 | PostgreSQL 的向量扩展。如果项目本来就在用 PostgreSQL,加一个扩展就变成了向量数据库。大多数企业内部 RAG 项目用 PGVector 就够了,千万级文档块都没问题。 |
| Qdrant / Milvus | 大规模 / 高并发 | 专门为向量搜索设计的数据库,检索速度更快,但引入了新的运维复杂度。 |
决策树
需要快速跑通 Demo?
→ 是 → SimpleVectorStore
→ 否 ↓
项目已有 PostgreSQL?
→ 是 → PGVector(最省事)
→ 否 ↓
数据量超过千万向量,或并发 QPS 很高?
→ 是 → Qdrant 或 Milvus
→ 否 → PGVector(依然推荐)建议:先用 PGVector 跑通,有明确的性能瓶颈再迁移。过早引入专业向量库反而增加复杂度,大多数项目到退休都用不到 Qdrant。
2.3 TopK 和相似度阈值怎么设?
这两个参数直接决定检索质量,但大多数教程只给了默认值,没解释为什么。
2.3.1 TopK:检索多少个文档块
检索时从向量库里取出最相似的 K 个块,全部塞进 Prompt。
-
K 太小(比如 1-2):容易漏掉关键信息,尤其是问题横跨多个文档时
-
K 太大(比如 20+):Prompt 被大量不相关内容填满,模型“注意力”被分散,回答更差;而且 Token 消耗暴增
起点:从 K=5 开始。跑一批测试问题,看召回率是不是够,再往上或往下调。
2.3.2 相似度阈值:过滤低质量的检索结果
即使设了 TopK=5,如果向量库里没有真正相关的内容,搜出来的 5 条可能都是不相关的垃圾。相似度阈值就是兜底过滤——低于这个分数的结果直接丢弃,不塞进 Prompt。
-
阈值太高(比如 0.9):稍微改一下措辞,语义相同的问题就搜不到了
-
阈值太低(比如 0.2):什么都进来,模型拿着一堆无关内容乱推理
起点:0.5~0.6。先把阈值设低,确认入库的内容能被检索到,再逐步提高到合理区间。
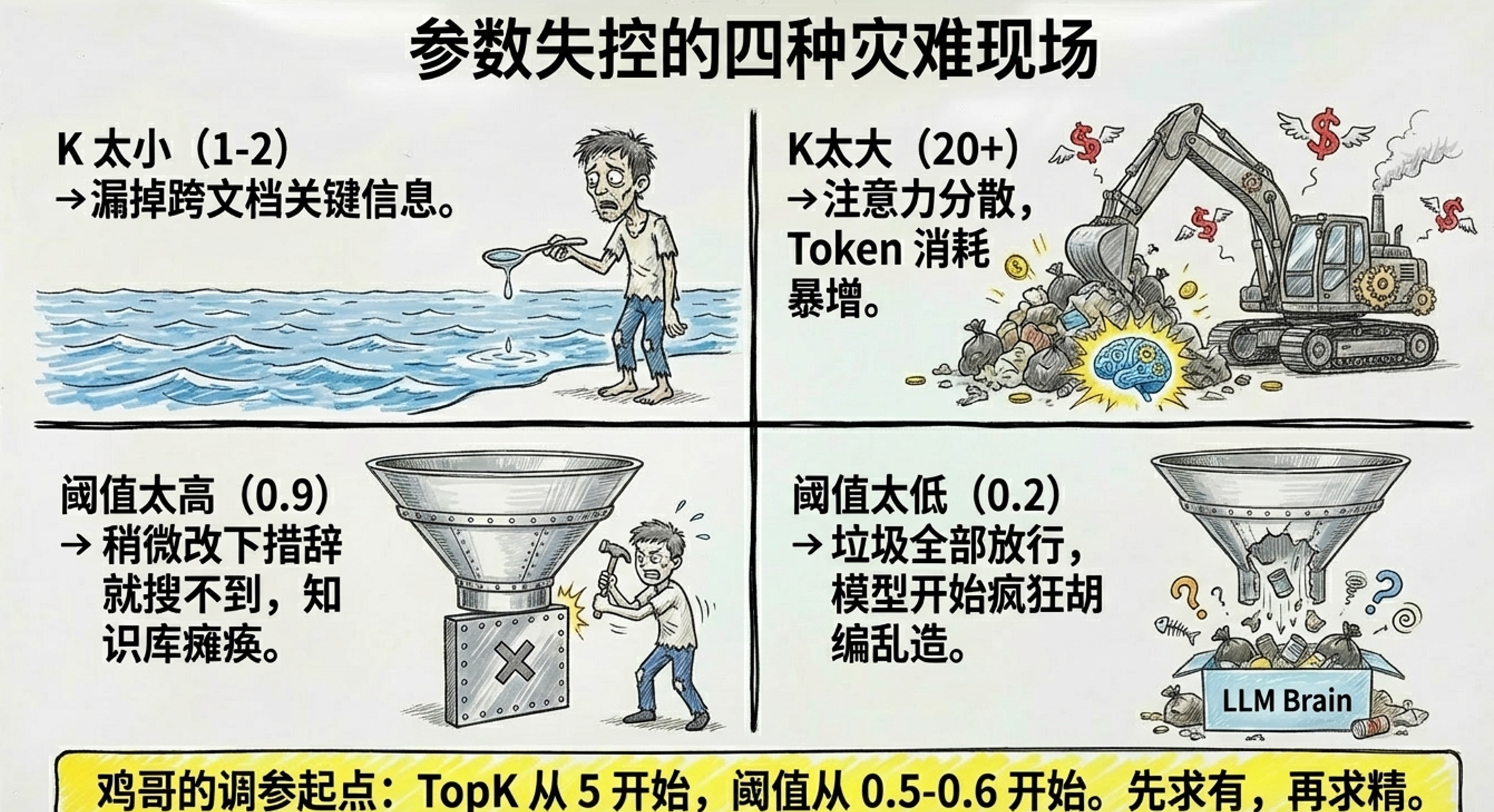
2.3.3两个参数要一起调
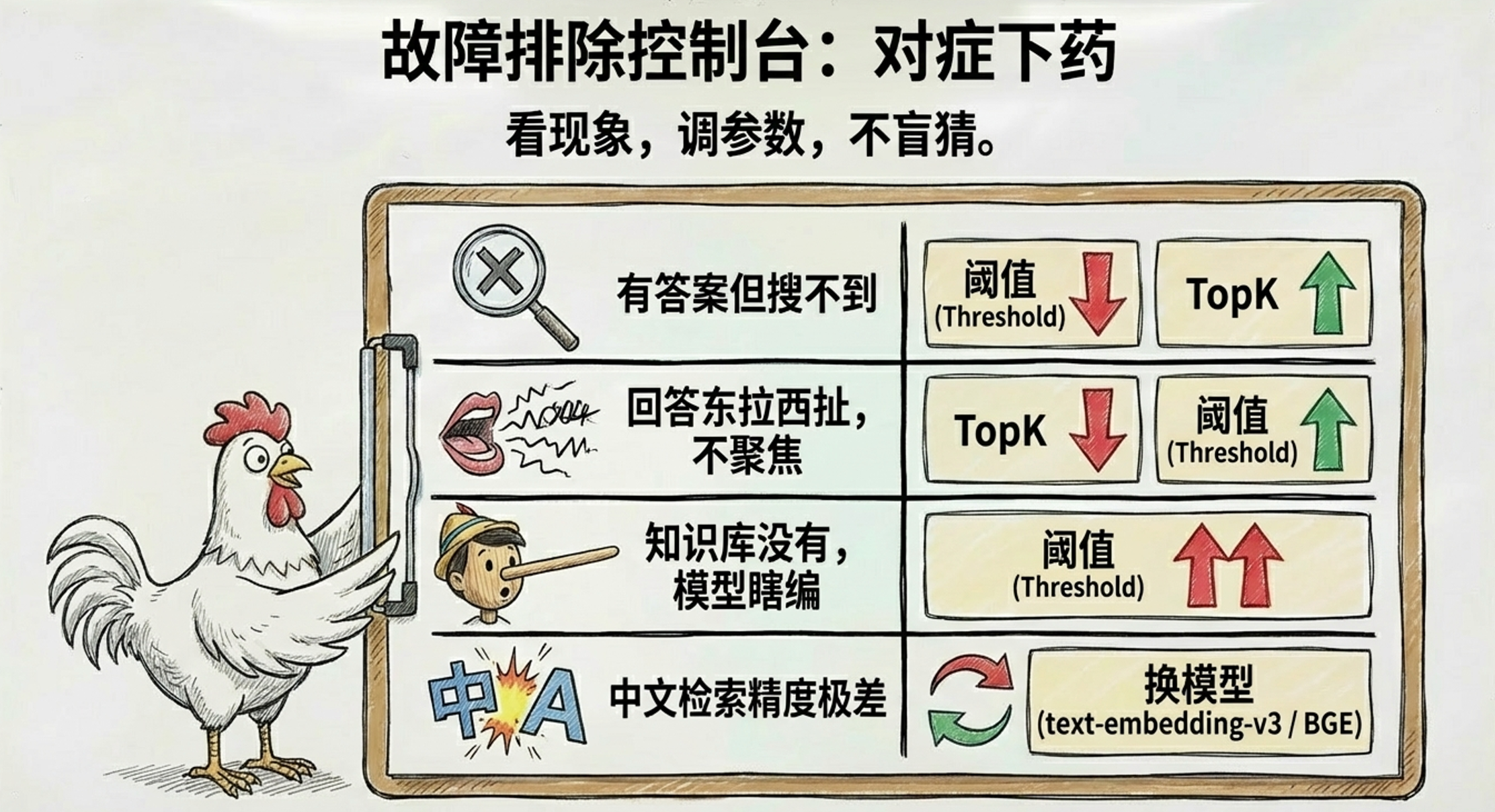
| 现象 | 可能原因 | 调整方向 |
|---|---|---|
| 有答案但搜不到 | 阈值太高 或 K 太小 | 降阈值 / 加大 K |
| 回答东拉西扯、信息不聚焦 | K 太大,引入噪音 | 减小 K / 提高阈值 |
| 知识库没有的内容模型在瞎编 | 阈值太低,垃圾内容进了 Prompt | 提高阈值 |
| 中文问题检索精度差 | Embedding 模型不适合中文 | 换 text-embedding-v3 或 BGE |
三、Embedding 模型选型
3.1 Embedding 是什么(直觉理解)
Embedding 模型做的事情很简单:把“文字”变成“空间中的一个点”。
语义相近的文字,会被映射到相邻的位置;语义差异大的文字,映射出来的点距离很远。
语义空间示意图(二维简化)
·退款政策
·退款流程
·如何申请退款 ← 这一簇都关于“退款”
·猫喜欢吃什么
·宠物饮食建议 ← 这一簇关于“宠物”
·产品保修期
·售后服务说明 ← 这一簇关于“售后”当用户输入“我想退款”,系统把这句话也映射到语义空间,然后找“附近的点”——找到的就是最相关的文档块。
向量的每个维度没有明确的人类可理解含义,整体方向代表了语义位置。模型的维度越高,空间越精细,细微的语义差别越能被区分出来——当然,存储和计算成本也更高。
3.2选 Embedding 模型看什么指标
在看具体模型之前,先把评估框架确立清楚:
| 指标 | 含义 | 中文项目重点关注 |
|---|---|---|
| MTEB 排行 | 业界标准评测基准,覆盖检索、分类、聚类等任务 | 看中文子榜(C-MTEB)而非总榜 |
| 中文语料覆盖 | 训练数据中中文比例 | 主要用中文必看 |
| 最大 Token 长度 | 单次能处理多长文本 | 影响分块策略的上限 |
| 输出维度 | 向量的维度数 | 影响存储和计算成本 |
| 调用方式 | API 还是本地部署 | 影响成本、延迟、数据安全 |
| 数据是否出境 | 文本是否发送到境外服务器 | 企业合规必看 |
3.3主流 Embedding 模型横向对比
先看全局,再深入每个方向。
| 模型 | 提供方 | 维度 | 中文效果 | 调用方式 | 成本 | 数据出境 |
|---|---|---|---|---|---|---|
| text-embedding-3-small | OpenAI | 1536 | 良好 | API | 低(约 $0.02/M tokens) | 是 |
| text-embedding-3-large | OpenAI | 3072 | 优秀 | API | 中(约 $0.13/M tokens) | 是 |
| text-embedding-v3 | 通义千问 | 1024/2048 | 优秀(专项优化) | API | 极低 | 否(国内) |
| bge-m3 | 北京智源(BAAI) | 1024 | 顶尖 | 本地 | 免费 | 否 |
| bge-large-zh | 北京智源(BAAI) | 1024 | 顶尖(专中文) | 本地 | 免费 | 否 |
| bge-small-zh | 北京智源(BAAI) | 512 | 良好 | 本地 | 免费 | 否 |
3.4维度不匹配——最高频的坑
向量数据库在建表时需要指定向量维度。这个维度必须和你的 Embedding 模型输出的维度完全一致。哪怕差一个数字,入库时就报错。
报错信息通常是 vector dimension mismatch 或类似描述,一看到这个,第一反应就是检查维度配置。
换了 Embedding 模型之后,如果维度变化了,已入库的所有数据都要重新入库。老数据的向量是在旧坐标系里算的,新模型的坐标系不一样,直接失效。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 14
14 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)