BERT基础模型架构的初识
前言
该文章是本人学习过程中的笔记内容,如有错误请指正。
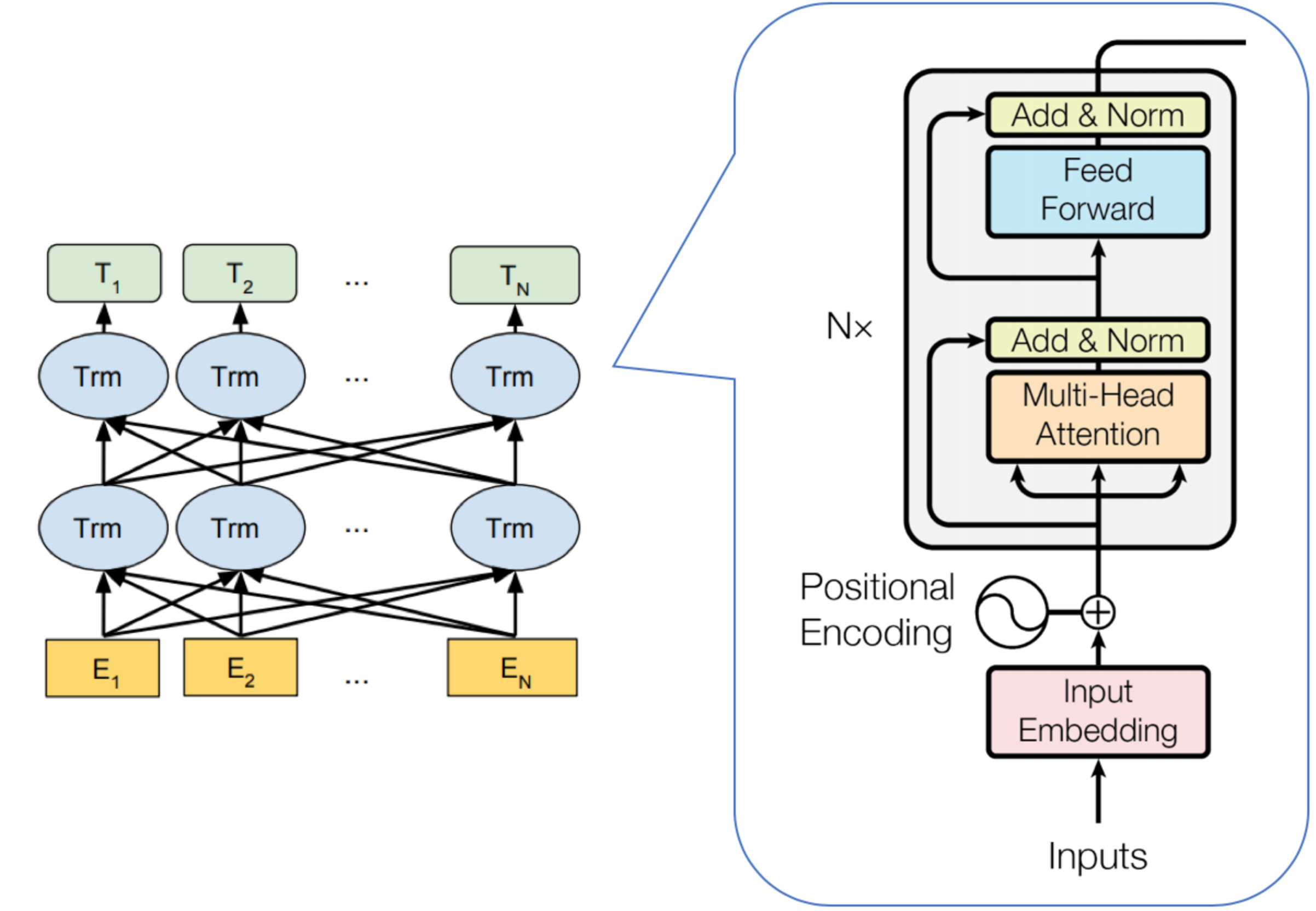
BERT模型基础架构由三个模块组成:词嵌入模块(Embedding),transformer的Encoding模块,预微调模块。
BERT有两大预训练任务:Masked LM(language model)掩码语言模型、NSP(Next Sentence Prediction)下一句话预测任务
一、词嵌入模块
1.1 组成
由词嵌入张量、句子分段嵌入张量、位置编码张量 组成。
词嵌入张量(Token Embeddings)
将句子中的每个词转为计算机可以处理的数字张量,第一个词是任务类型的标记(例如:[CLS],分类标记),每段句子之间由 [SEP] 来分割。
句子分段嵌入张量(Segment Embeddings)
将两个句子进行区分标记,服务于BERT的NSP预训练任务。
位置编码张量(position)
给句子中的每个词给予一个位置编码信息。
1.2 输出
由以上三个模块直接加和而成。
1.3 与transformer模型中的Embedding模块的区别
transformer模型的Embedding模块中只有 词嵌入张量 和 位置编码张量 的直接加和,
而BERT中,多了一个 句子分段嵌入张量 的加和。
二、transformer模块
只使用transformer模块中的encoding编码器部分。
由12层编码器层组成
输入:512维
输出:768维
头数:12头
参数:110M
如果输入的长度超过了512该怎么办?
可以取开头、取结尾、或取开头的部分和结尾的部分拼凑起来。
但要留出任务类型标识(例如:[CLS])和分割标识([SEP]),还剩下的510给输入文本。
如果是取开头和结尾:
输入维度是800以内,则开头取128,结尾取382;
输入维度是800以上,则开头取256,结尾取254。
三、预微调模块
只需要对这个模块作一些改动就可以实现多种下游任务的处理。
例如:句子对分类任务、单句分类任务
四、BERT的两大预训练任务
4.1 Masked LM
一般的语言模型都是从左到右,或者从左到右和从右到左的拼接 来训练模型的,这样模型训练提取到的特征有限,BERT就使用一个深度双向表达模型(MLM)来更好的提取特征。
任务是随机选取15%的Token(即每个词)来做掩码任务。
其中被选择的Token中,
80%的Token用 [MASK] 来替换,
10%的Token用 随机错误的Token 来替换,
10%的Token保持原Token不变。
4.1.1 任务这样设计的好处
只使用15%的Token来做任务,保留了原本文章句子的语言能力和表达规则。
模型不知道哪些词需要被预测,哪些词被MASK,哪些词是正确的,这样就逼着模型要真正理解句子中的语义,才能完成任务。
4.1.2 为什么要用80%、10%、10%这样的比例来替换
用 [MASK] 替换80%的Token,是为了训练模型 同时双向 理解文本的能力。
用 随机错误的Token 来替换10%的Token,是为了强制让模型从句子的上下文来理解语义,真正理解词的含义,不会让模型通过出现的频率去猜。
保持10%Token不变,是为了不让模型学傻。
4.2 NSP
在QA(Question-Answer)问答之类的任务中,模型需要正确理解两个句子之间的关系和含义,就需要Next Sentence Prediction任务来训练模型。
所有参与任务的句子对(A-B)中,所有的句子A不变,
50%的句子B保持不变,标记为isNext(正样本)
50%的句子B被随机的原始句子替换,标记为notNext(负样本)。
五、BERT模型的优缺点
5.1 优点
1.模型理解能力因为双向理解而更强
2.有预微调模块,可以适应不同的下游任务。
3.在公开的数据集上的效果好。
5.2 缺点
1.模型的参数量相对于RNN之类的算法而言比较大。
2.因为MLM任务中选择了15%的Token做双向理解训练,导致模型训练收敛的速度相对慢。
3.中文处理有局限性,例如一些生僻字。
4.MLM训练任务中的[MASK]标记只在训练阶段出现,在预测阶段不会出现,就造成了一定的信息偏差,过多使用[MASK]会让模型的性能下降。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)