Java AI 框架,让 YOLO 在 JVM 里原生跑 GPU
Java AI 框架,让 YOLO 在 JVM 里原生跑 GPU
一个 Maven 依赖。六行代码。在 Java 里直接调用 PyTorch CUDA,零 Python 配置。
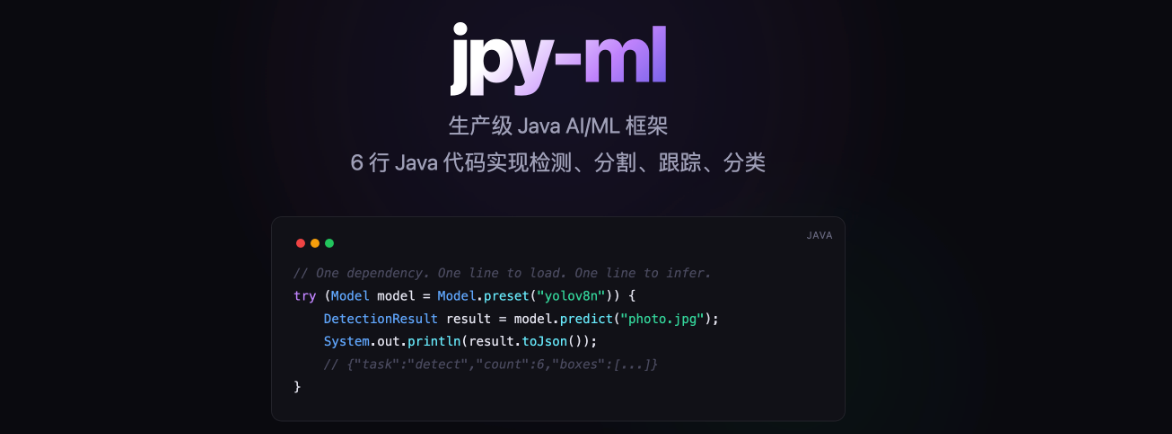
先问一个问题
你团队的技术栈是 Java,老板突然说:“加个 AI 检测功能,识别产线上的缺陷。”
你怎么办?
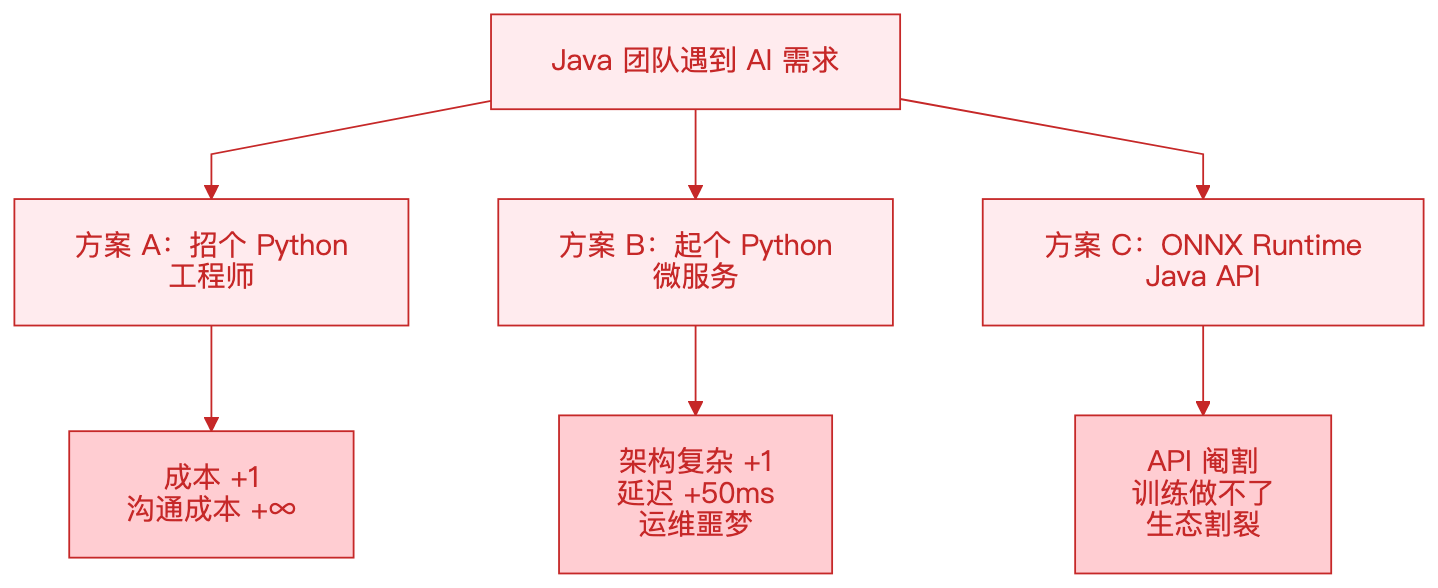
三个方案,三种妥协。
我选了第四条路:让 Java 直接跑 Python 的 AI 生态,进程内,GPU 加速,强类型 API,训练推理一条龙。
六行代码,能做什么?
检测
try (Model model = Model.preset("yolov8n")) {
DetectionResult result = model.predict("photo.jpg");
System.out.println(result.toJson());
}
// {"task":"detect","count":6,"boxes":[...]}
分割
SegmentationResult result = model.predict("photo.jpg");
Mask mask = result.getMasks().get(0);
// 像素级掩码,不是框
姿态
PoseResult result = model.predict("dance.jpg");
Keypoint nose = result.getKeypoints().get(0).getNose();
// 17 个关键点坐标
SAM 2:点一下,分割出来
SAM2Result result = sam.predict("cat.jpg",
new PointPrompt(100, 200, POSITIVE));
// 点哪里,分哪里
SAM 3:说句话,分割出来
SAM3Result result = sam.predict("street.jpg", "red car");
// 自然语言概念级分割
MediaPipe:手部 21 关键点
HandResult result = mp.detectHands("hand.jpg");
// 478 面部关键点 / 33 姿态关键点 同样一行
注意:
Model.preset("yolov8n")自动下载模型。你不用翻 HuggingFace,不用手动拷贝权重文件。
和传统方案的区别
| REST 调 Python | ONNX Runtime Java | jpy-ml | |
|---|---|---|---|
| 调用方式 | HTTP 往返 | 本地推理 | JNI 进程内 |
| 类型安全 | Map<String, Object> 强转地狱 |
依赖 ONNX Java API | DetectionResult 强类型 |
| GPU 支持 | ✅(Python 端) | ✅ CUDA/TensorRT | ✅ 完整 PyTorch 生态 |
| 训练能力 | ❌ | ❌ | ✅ 训练 + 验证 + 导出 |
| 模型管理 | 手动 | 手动 | ✅ 自动下载缓存 |
| 部署形态 | Java + Python 两个服务 | 单服务 | 单 JVM,一个 Jar 包 |
| SAM/MediaPipe | 再搭一个服务 | 不支持 | ✅ 内置 |
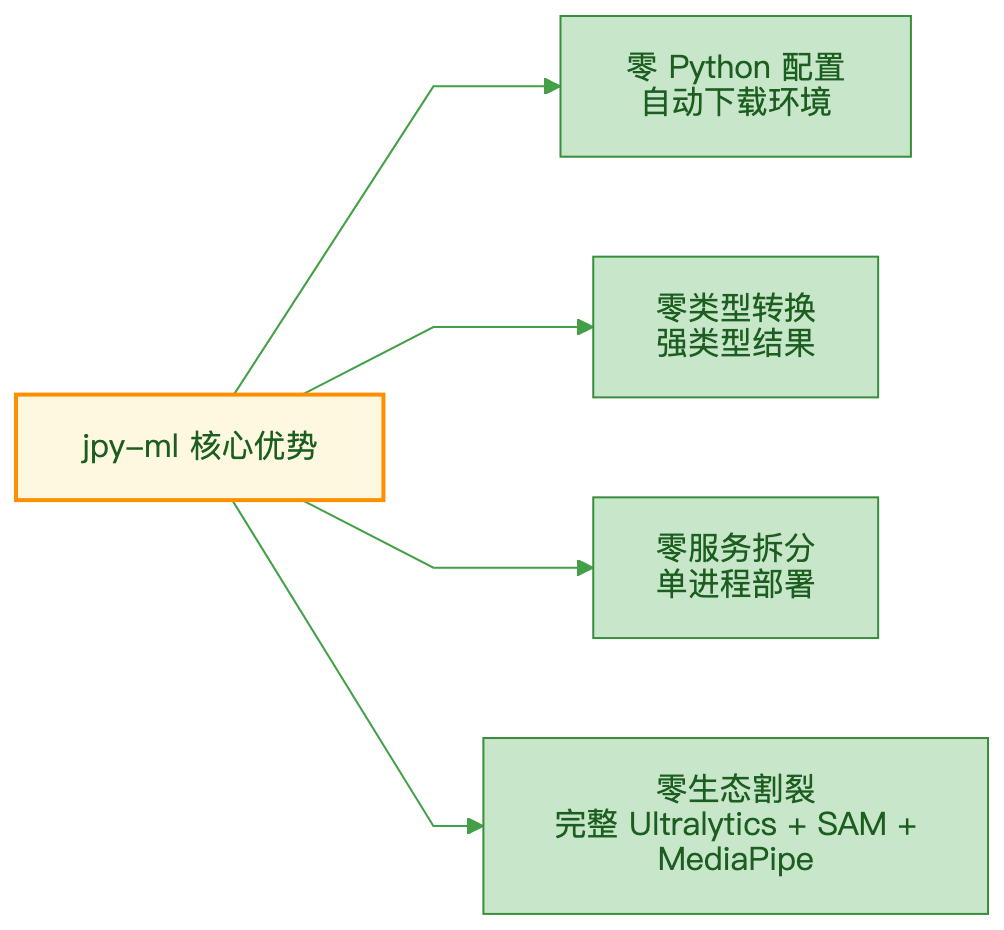
关键差异:ONNX Runtime Java 是"推理工具",jpy-ml 是"完整 ML 平台"——训练、验证、导出、推理、SAM、MediaPipe,全在 JVM 里。
架构:怎么做到的?
不是 Python 子进程。不是 HTTP 调用。是 JNI 共享内存桥接。
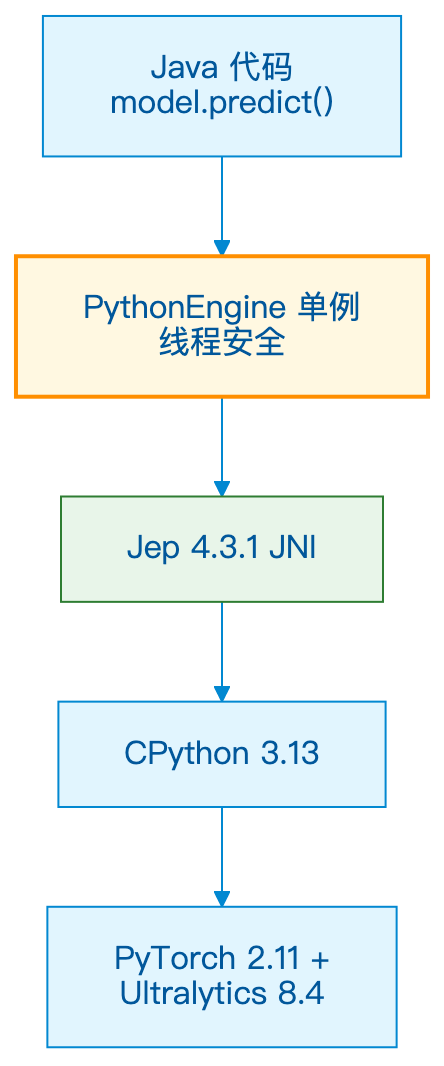
关键设计:
- 单例 PythonEngine:Jep 限制每 JVM 一个解释器,通过变量名前缀隔离多模型
- sys.path 过滤:自动解决 Homebrew 系统包冲突
- 零拷贝桥接:
TensorBufferPool避免 Java-Python 数据拷贝 - AutoCloseable:模型关闭时 Python 变量置 None,GC 友好
覆盖模型全生命周期
不是只能推理。是完整 MLOps。

// 训练
TrainingResult result = model.train(config, (epoch, log) -> {
System.out.println("Epoch " + epoch + ": " + log);
});
// 验证
ValidationResult val = model.validate("coco128.yaml");
// 导出 TensorRT FP16
model.export(ExportFormat.ENGINE, new ExportConfig().half(true));
质量:106 个测试,0 失败
| 测试 | 覆盖 |
|---|---|
| YOLO 检测/分割/分类/姿态/OBB | ✅ |
| SAM 2 点/框/视频跟踪 | ✅ |
| SAM 3 文本/图像提示 | ✅ |
| MediaPipe 手部/面部/姿态 | ✅ |
| OpenCV 图像处理 | ✅ |
| 训练 + 验证 + 导出 | ✅ |
| 异步推理 + 视频流 | ✅ |
| 零拷贝 + GPU 内存管理 | ✅ |
不是 Demo。是生产级框架。
怎么用?
<dependency>
<groupId>io.github.javpower</groupId>
<artifactId>jpy-ml</artifactId>
<version>1.0.0</version>
</dependency>
// 六行代码,开始检测
try (Model model = Model.preset("yolov8n")) {
DetectionResult result = model.predict("photo.jpg");
System.out.println(result.toJson());
}
要求:JDK 17 Temurin(不要用 GraalVM,JNI 会崩),Python 3.13 venv。
路线图:不止 YOLO
已完成:YOLO / SAM 2/3 / MediaPipe / OpenCV
计划中:
- HuggingFace Transformers(NLP、嵌入)
- Whisper(语音)
- Stable Diffusion(图像生成)
- DeepSeek / LLM 推理
- Spring Boot Starter
一句话总结
Java 程序员做 AI,不需要 Python 工程师,不需要双服务架构,不需要阉割版 API。
一个 Maven 依赖,六行代码,在 JVM 里跑完整的 PyTorch 生态——训练、推理、SAM、MediaPipe,全搞定。
Gitee: gitee.com/javpower/jpy-ml
GitHub:github.com/javpower/jpy-ml
如果你也是 Java 技术栈,被 AI 需求折磨过,这个项目可能省你三个月。
一个依赖,一行加载,一行推理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)