GPUStack部署实战与功能图解
一、概述
GPUStack 是一个开源的 GPU 集群管理器,专为高效的 AI 模型部署而设计。它配置和编排推理引擎(vLLM、SGLang、TensorRT-LLM 或您自定义的引擎),以优化跨 GPU 集群的性能。其核心功能包括:
- 多集群 GPU 管理。 跨多个环境管理 GPU 集群。这包括本地服务器、Kubernetes 集群和云提供商。
- 可插拔推理引擎。 自动配置高性能推理引擎,如 vLLM、SGLang 和 TensorRT-LLM。您也可以根据需要添加自定义推理引擎。
- Day 0 模型支持。 GPUStack 的可插拔引擎架构使您能够在新模型发布当天即可部署。
- 性能优化配置。 提供预调优模式,用于低延迟或高吞吐量。GPUStack 支持扩展的 KV 缓存系统,如 LMCache 和 HiCache,以减少 TTFT。它还包括对推测性解码方法(如 EAGLE3、MTP 和 N-grams)的内置支持。
- 企业级运维能力。 支持自动故障恢复、负载均衡、监控、认证和访问控制。
二、 架构
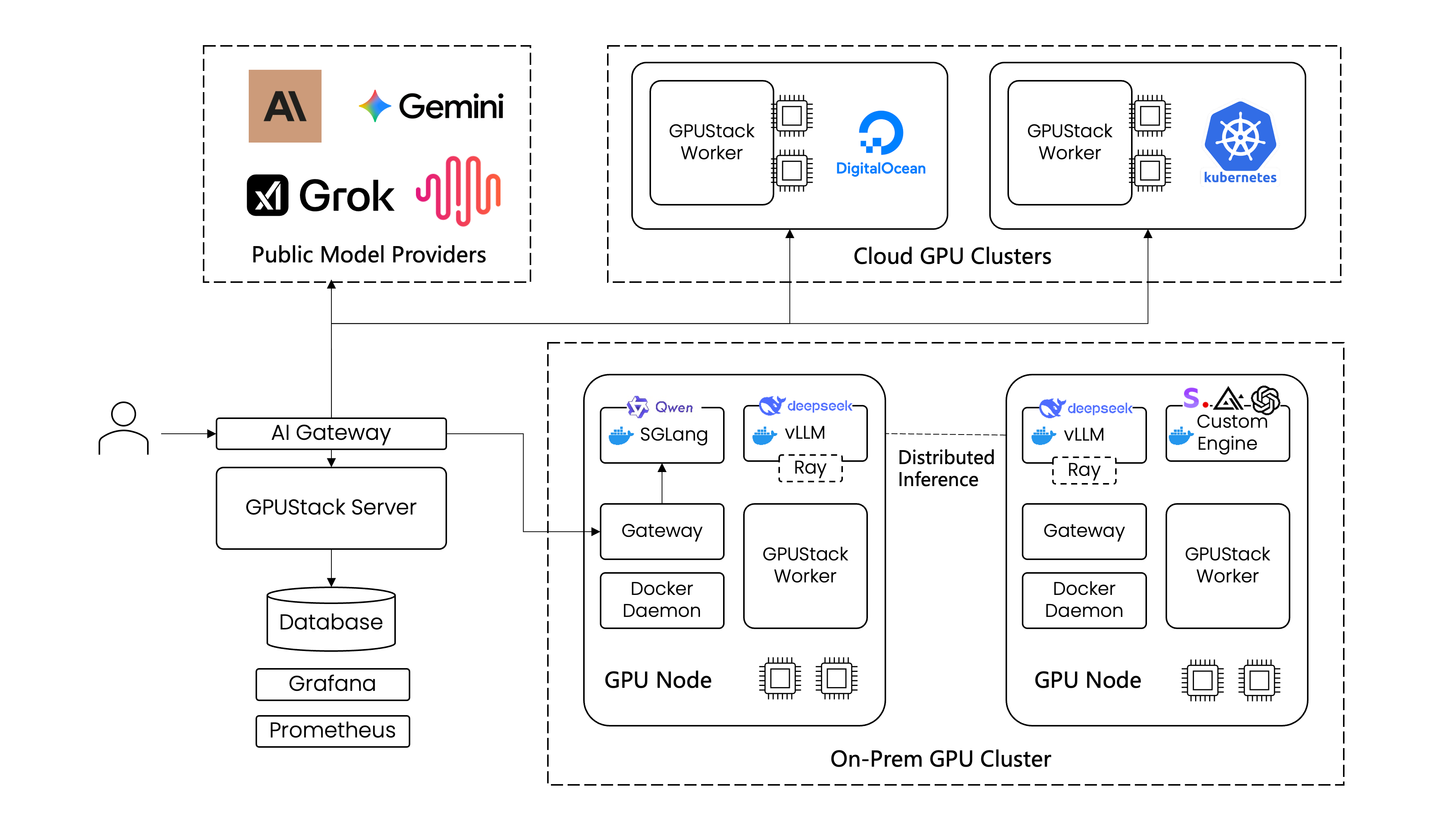
GPUStack 使开发团队、IT 组织和服务提供商能够大规模地提供模型即服务。它支持用于 LLM、语音、图像和视频模型的行业标准 API。该平台内置用户认证和访问控制、GPU 性能和利用率的实时监控,以及令牌使用量和 API 请求率的详细计量。
下图展示了单个 GPUStack 服务器如何管理跨本地和云环境的多个 GPU 集群。GPUStack 调度器分配 GPU 以最大化资源利用率,并选择合适的推理引擎以实现最佳性能。管理员还可以通过集成的 Grafana 和 Prometheus 仪表板全面了解系统运行状况和指标。
三、部署要求
3.1 前提条件
- GPUStack 分为 Server(控制平面,无需 GPU)和 Worker(计算节点,挂载 GPU)。Server 可以与 Worker 共机部署,也可以分离部署。生产环境建议分离。
- 一个至少配备一块 NVIDIA 或其他 GPU 的 Worker 节点。GPU卡支持列表见3.2小节。
- 确保 worker 节点上已安装 已安装所有必需的驱动程序和工具包。其他GPU类型类似。
- (可选)一个用于托管 GPUStack server 的 CPU 节点。GPUStack server 不需要 GPU,可以在仅有 CPU 的机器上运行。必须安装 Docker。同时支持 Docker Desktop(适用于 Windows 和 macOS)。如果没有专用的 CPU 节点,可以将 GPUStack server 安装在 GPU worker 节点所在的同一台机器上。
- GPUStack worker 节点仅支持 Linux。如果你使用 Windows,可考虑使用 WSL2 并避免使用 Docker Desktop。macOS 不支持作为 GPUStack worker 节点。
3.2 GPU卡支持列表
3.3 推理后端框架支持列表
|
GPU卡 |
vLLM | SGLang | MindIE | VoxBox | Custom |
|---|---|---|---|---|---|
| NVIDIA GPU | ✅ | ✅ | ❌ | ✅ | ✅ |
| AMD GPU | ✅ | ⚠️ gfx9 系列 | ❌ | ❌ | ✅ |
| 昇腾 NPU(Ascend) | ✅ | ✅ | ✅ | ❌ | ✅ |
| 海光 DCU(Hygon) | ✅ | ❌ | ❌ | ❌ | ✅ |
| 沐曦 GPU(MetaX) | ✅ | ✅ | ❌ | ❌ | ✅ |
| 摩尔线程(MThreads) | ✅ | ✅ | ❌ | ❌ | ✅ |
| 天数智芯(Iluvatar) | ✅ | ❌ | ❌ | ❌ | ✅ |
| 寒武纪 MLU(Cambricon) | ❌ | ❌ | ❌ | ❌ | ✅ |
| 平头哥 PPU(T-Head) | ✅ | ✅ | ❌ | ❌ | ✅ |
四、GPUStack部署实战
4.1 部署Server
使用Docker安装并启动GPUStack Server:
sudo docker run -d --name gpustack \
--restart unless-stopped \
-p 80:80 \
--volume gpustack-data:/var/lib/gpustack \
gpustack/gpustack查看GPUStack容器日志:
sudo docker logs -f gpustack如果一切正常,可在浏览器中打开 http://localhost:80 以访问GPUStack界面。
使用用户名登录,密码为默认值。可通过以下方式获取初始密码:
sudo docker exec -it gpustack \
cat /var/lib/gpustack/initial_admin_password4.2 添加GPU集群和工作节点
登录GPUStack系统后,可按照Clusters和Workers页面上的UI说明,添加GPU集群和工作节点。
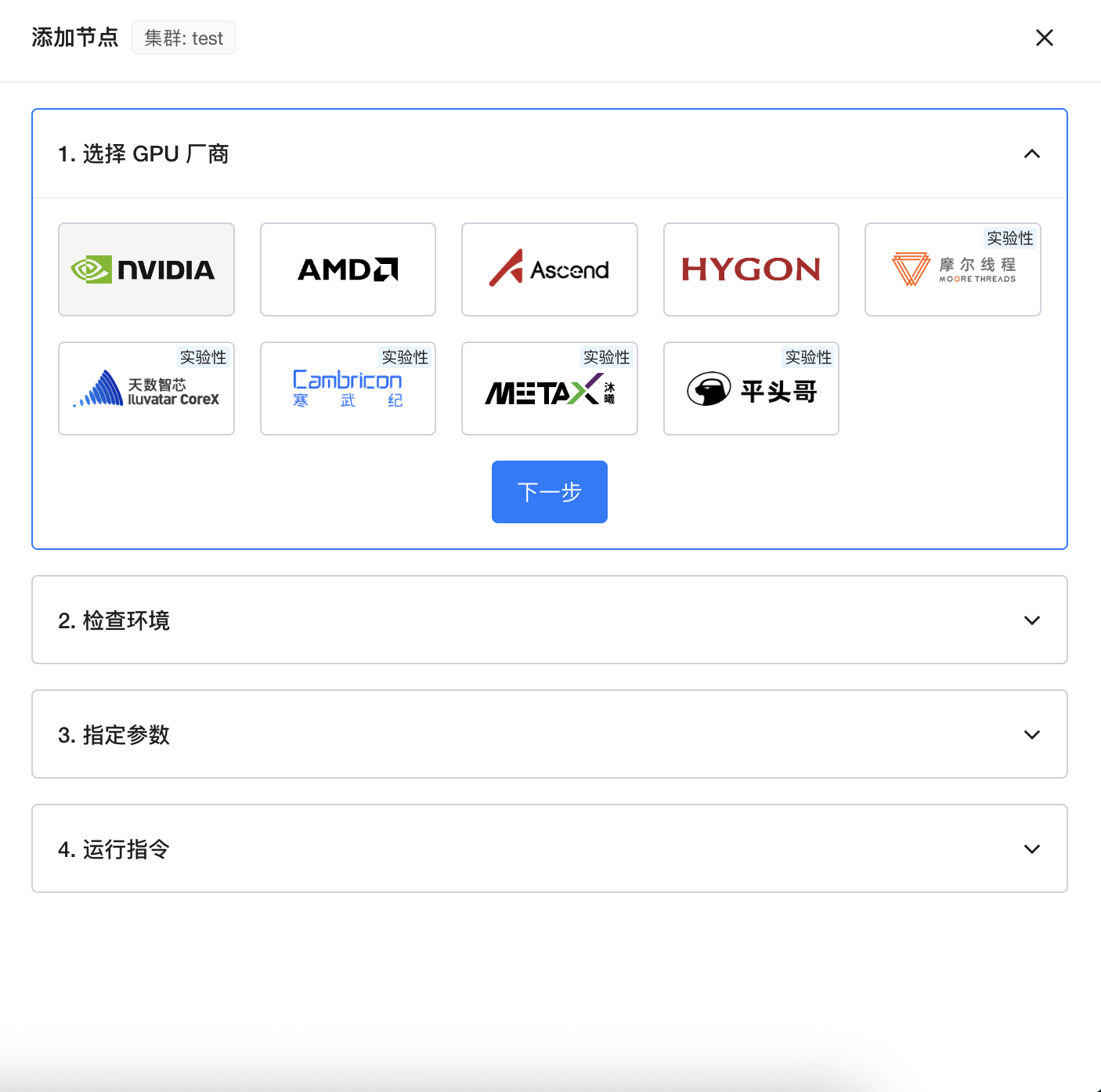
选择准备好的GPU节点,并执行命令检查环境是否准备妥当。
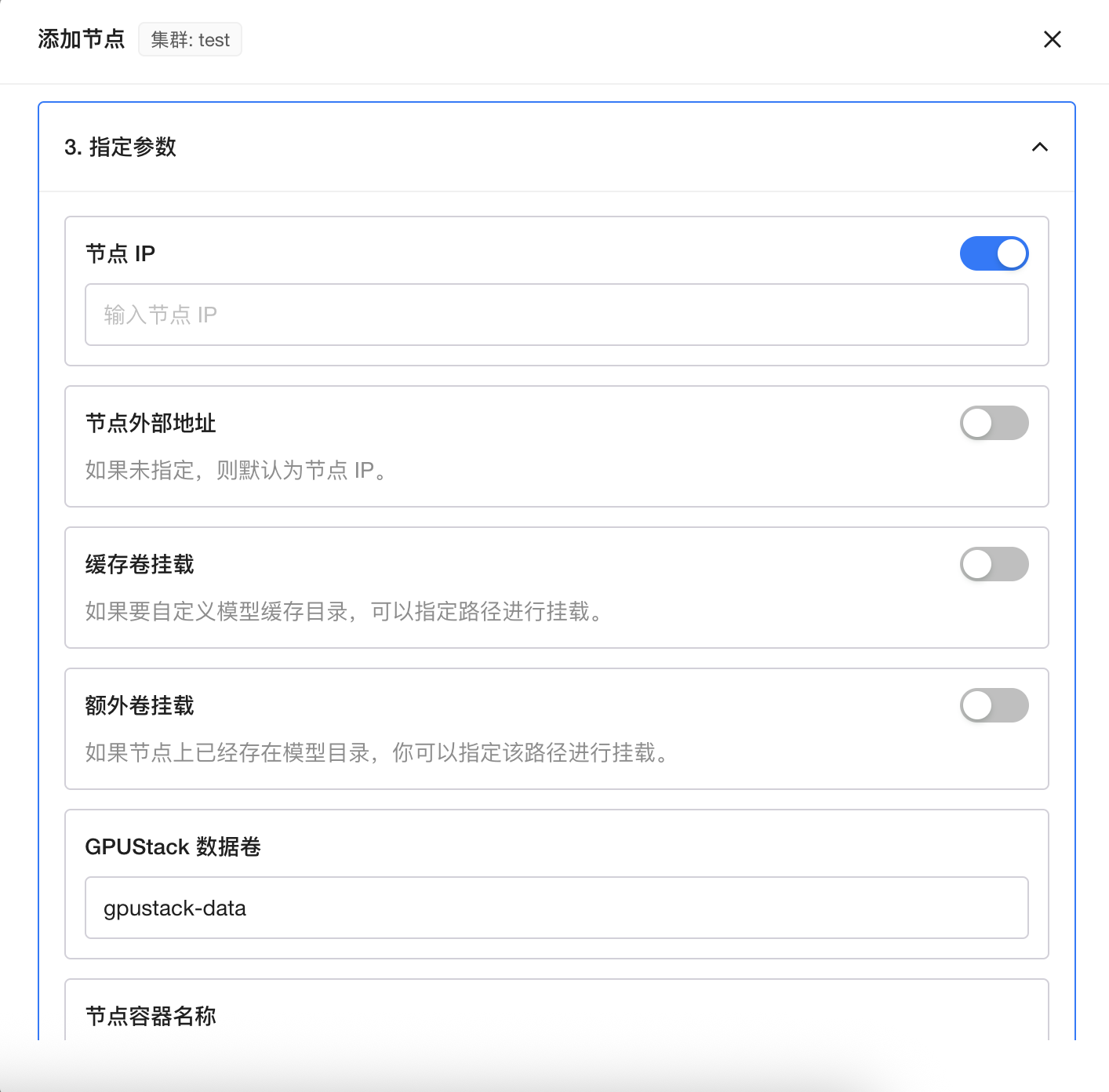
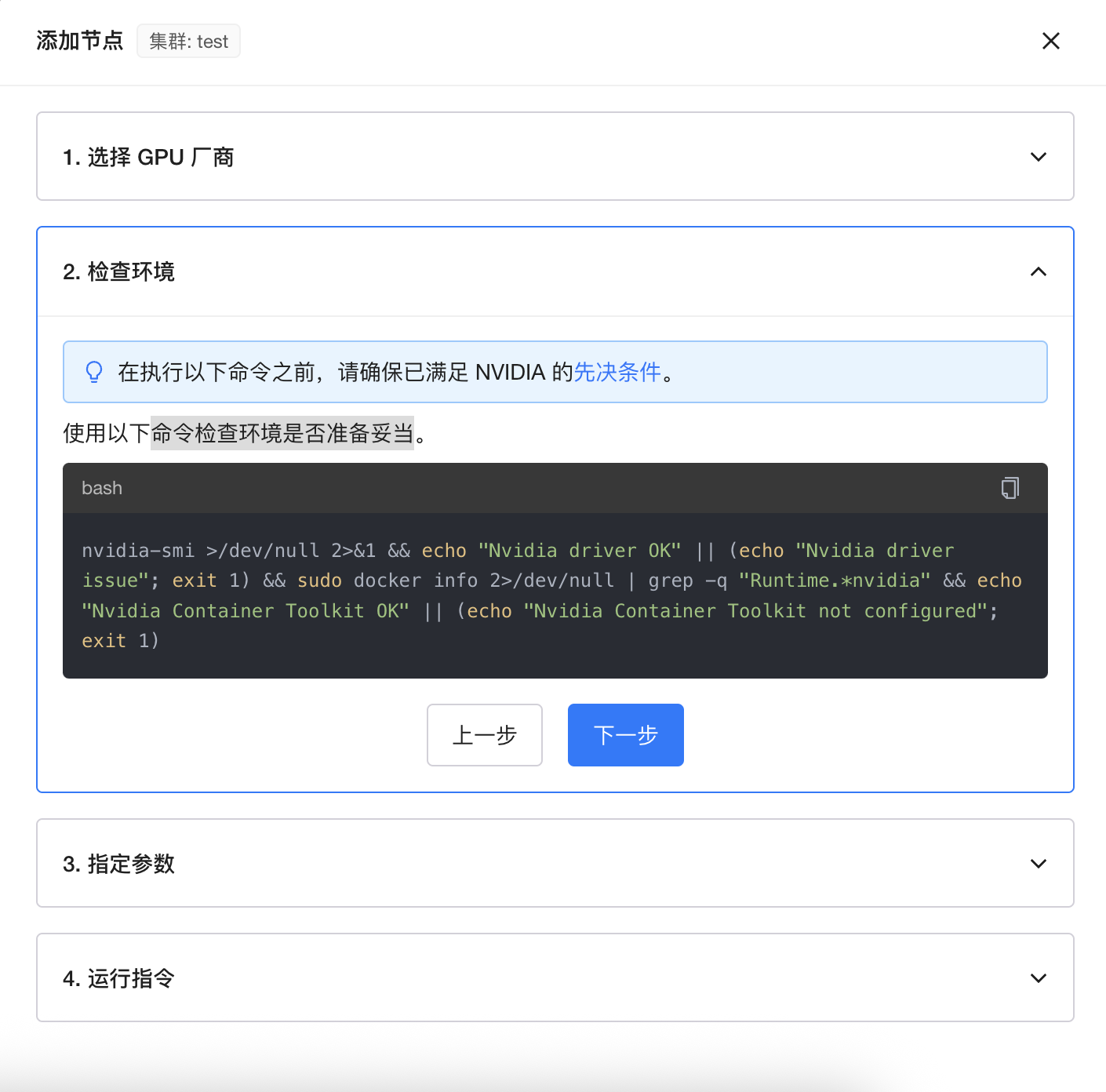 环境检查通过后将节点IP、数据卷、容器名称等配置对应信息:
环境检查通过后将节点IP、数据卷、容器名称等配置对应信息:
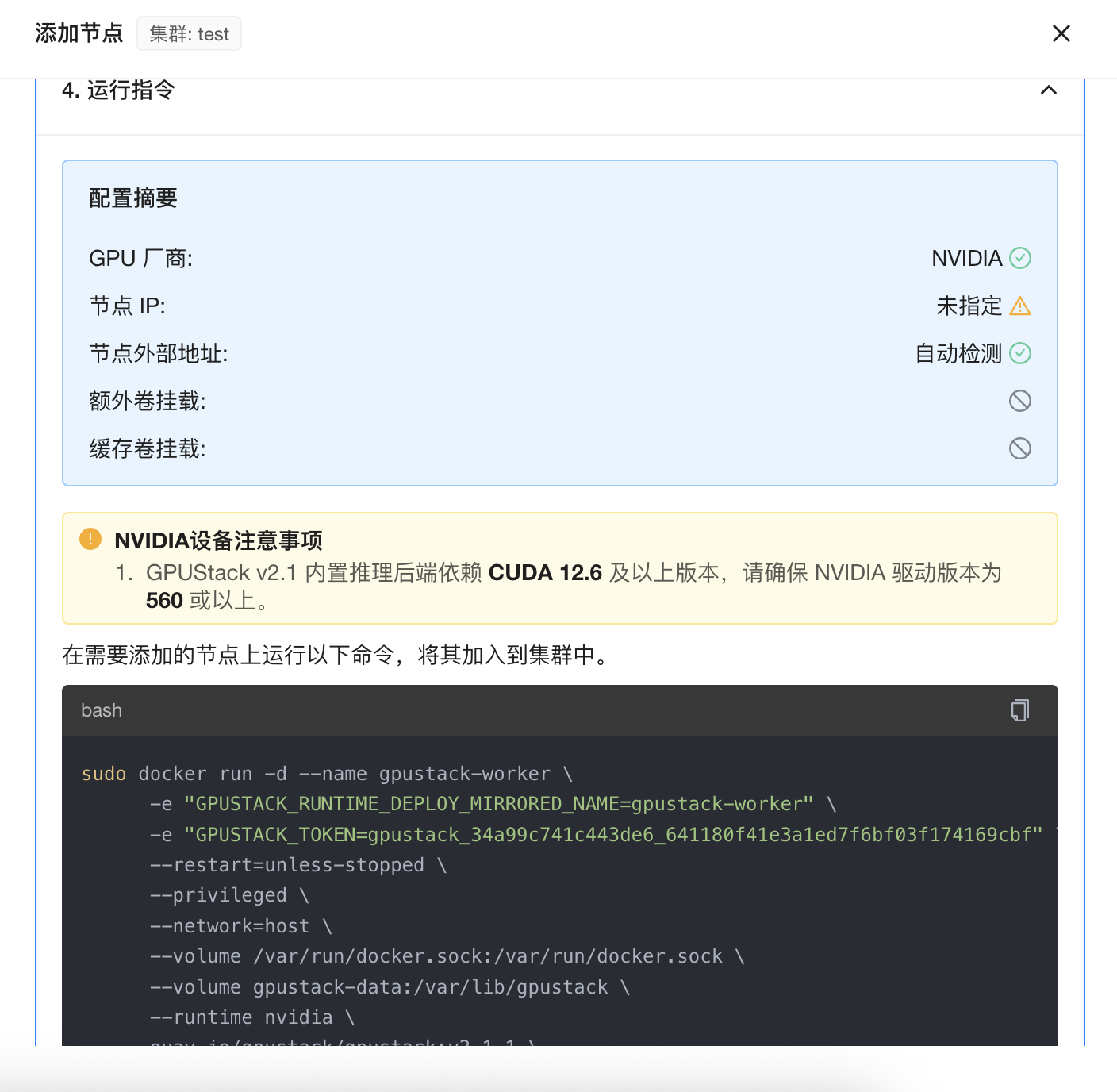
配置完成后,执行work部署命令将节点加入到集群中:
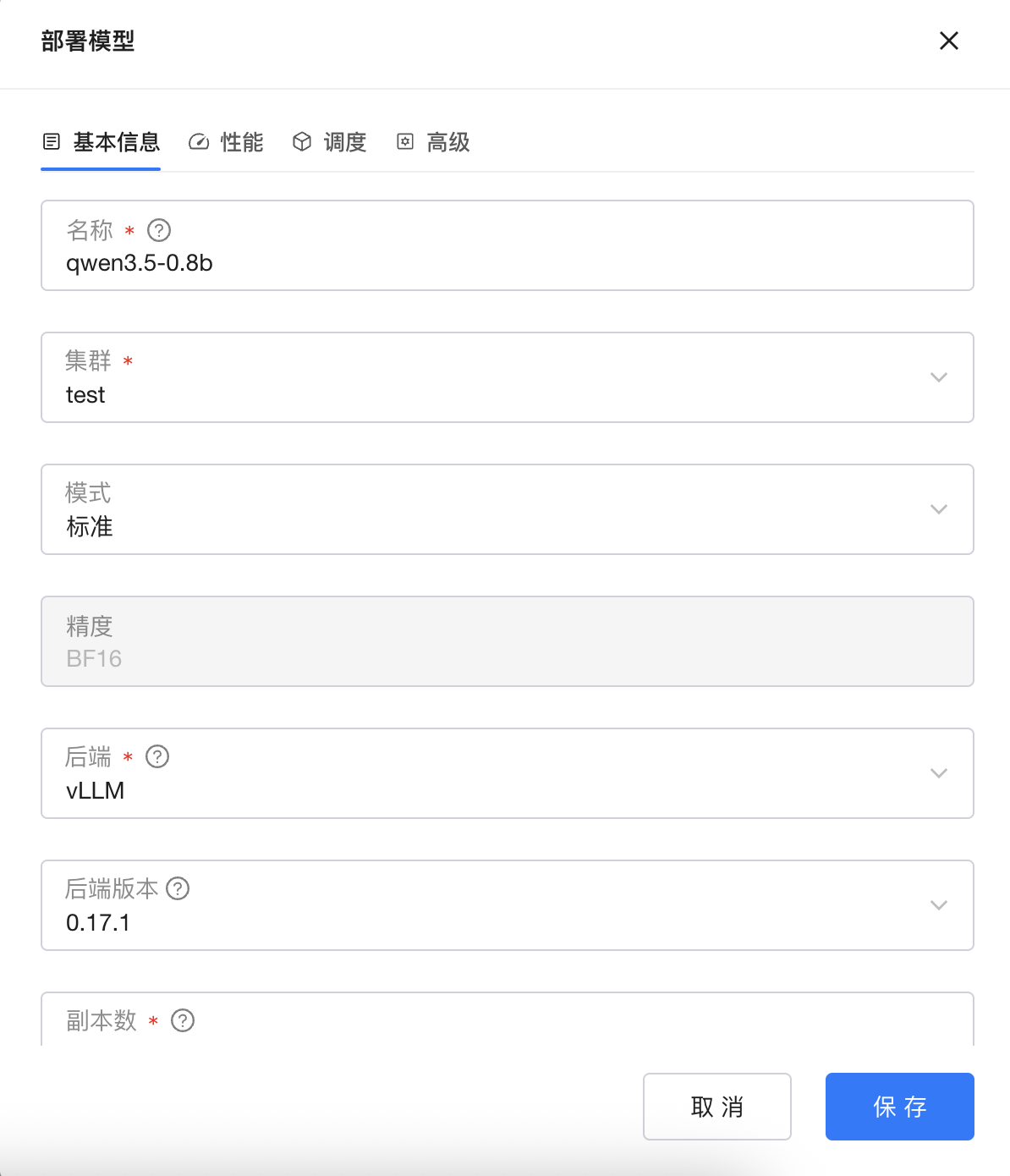
4.3 模型部署
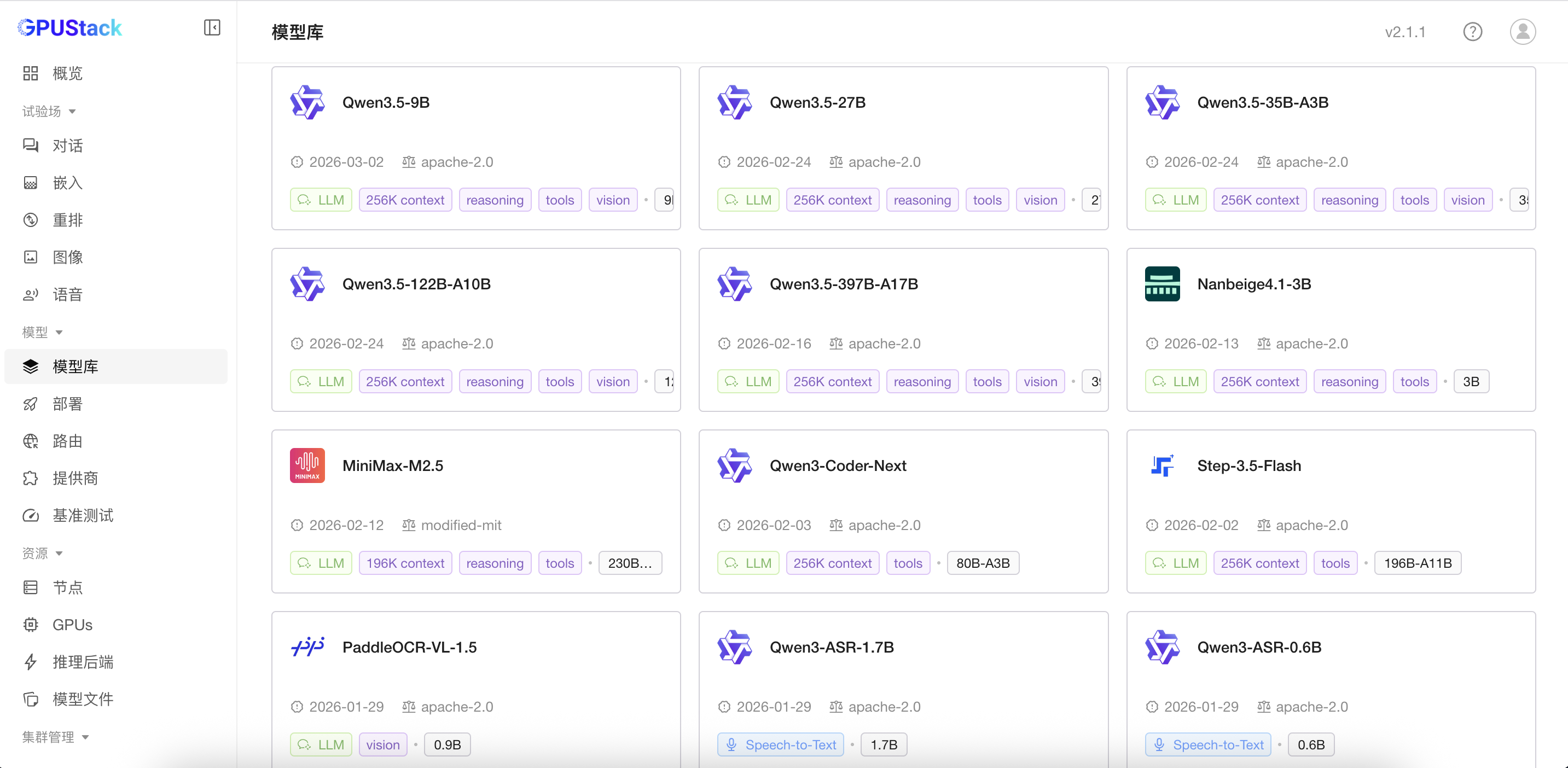
GPUStack内置模型库,可以方便从HuggingFace或ModelScope下载所需模型文件,并一键部署。
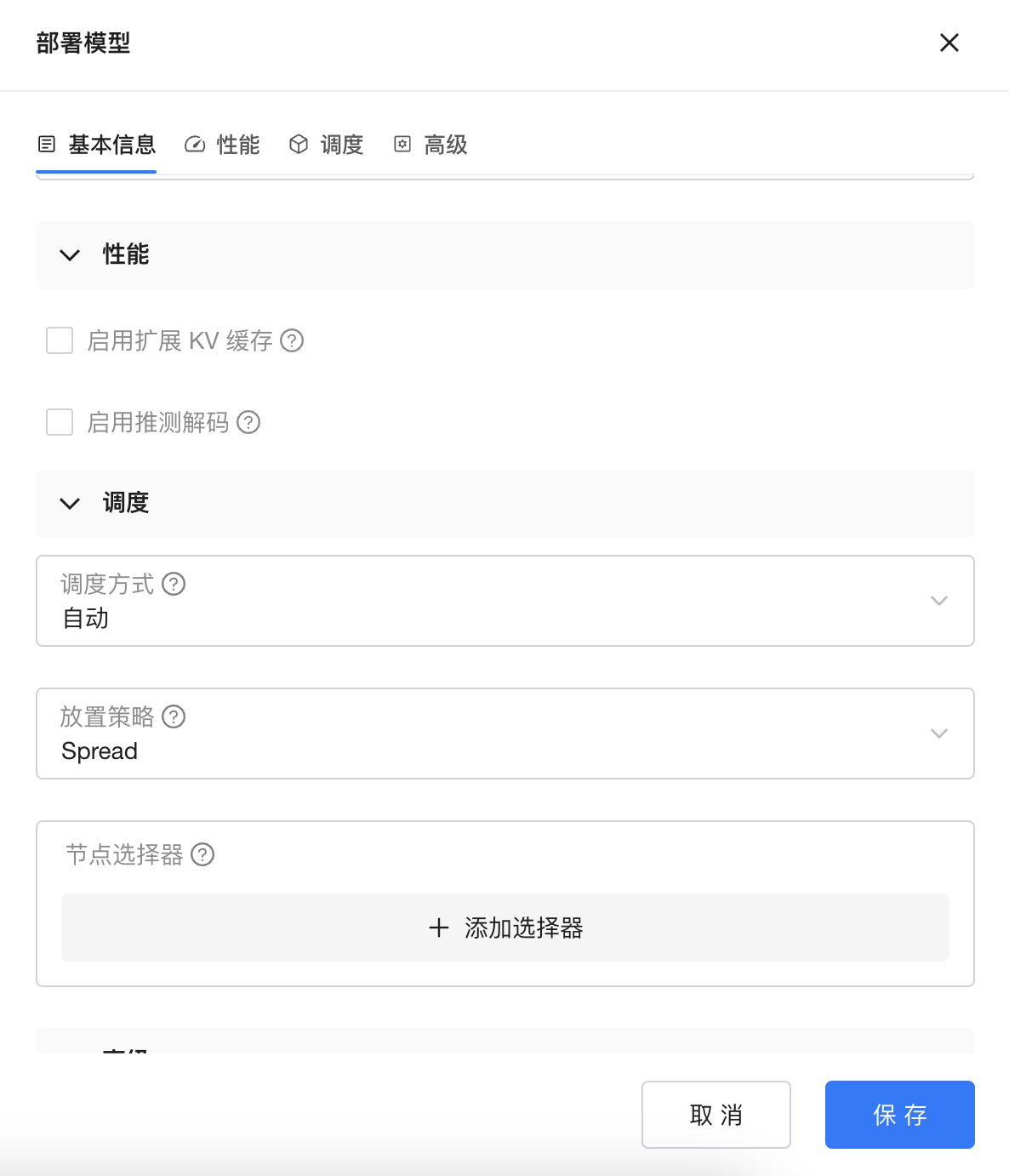
模型部署支持选择后端推理镜像,以及推理副本,也可以配置kvCache、推测解码等高级性能选项,调度支持自动选择和手动选择,自动调度可选SPread和BinPack调度模式。
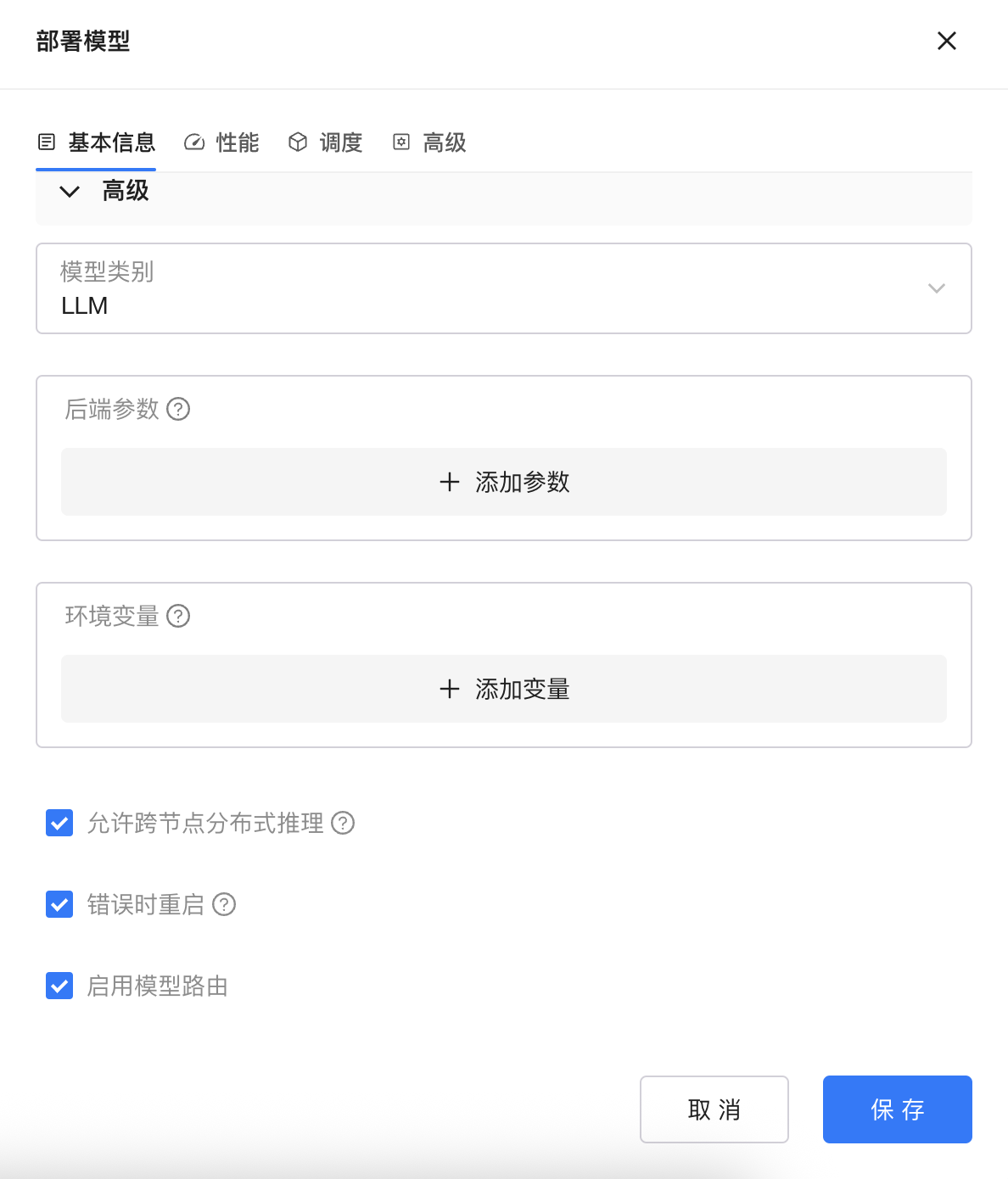
高级配置中还可以配置超参、环境变量,开启分布式推理、模型路由等高阶能力。
4.4 模型试验场及推理服务网关
模型试验场可以通过 UI 跟大模型进行交互
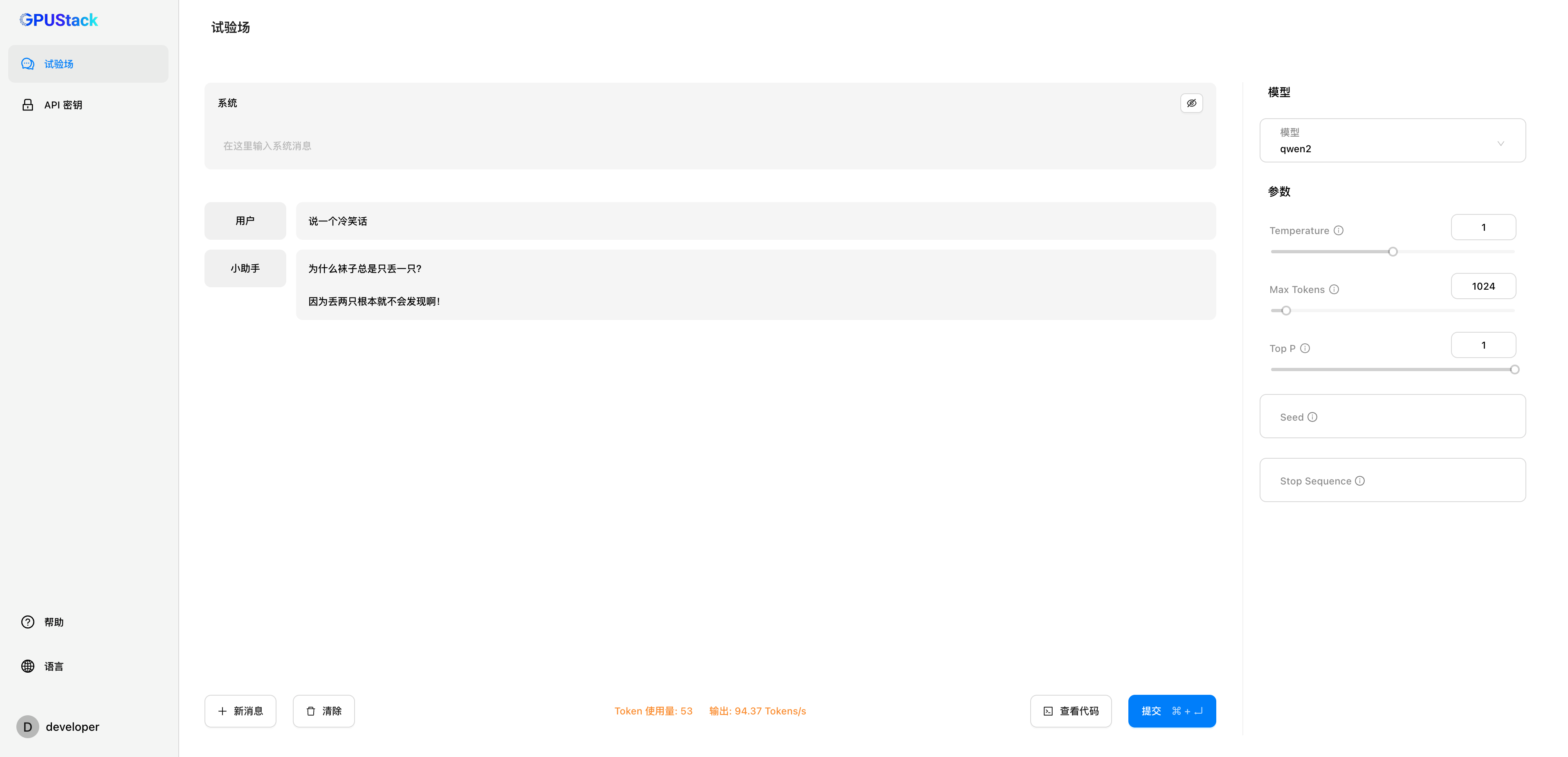
下一步,你可以访问到 API 秘钥生成并保存你的 API 秘钥。然后回到试验场,在这里自定义你的大模型,例如调整系统 prompt,添加小样本学习样例,或调整 prompt 参数。
当你完成了自定义设置,点击查看代码选择你期望的调用代码格式(curl, Python, Node.js),并加入之前的 API 秘钥,然后在你的应用中使用这段调用代码来让应用与你的私有大模型通信。
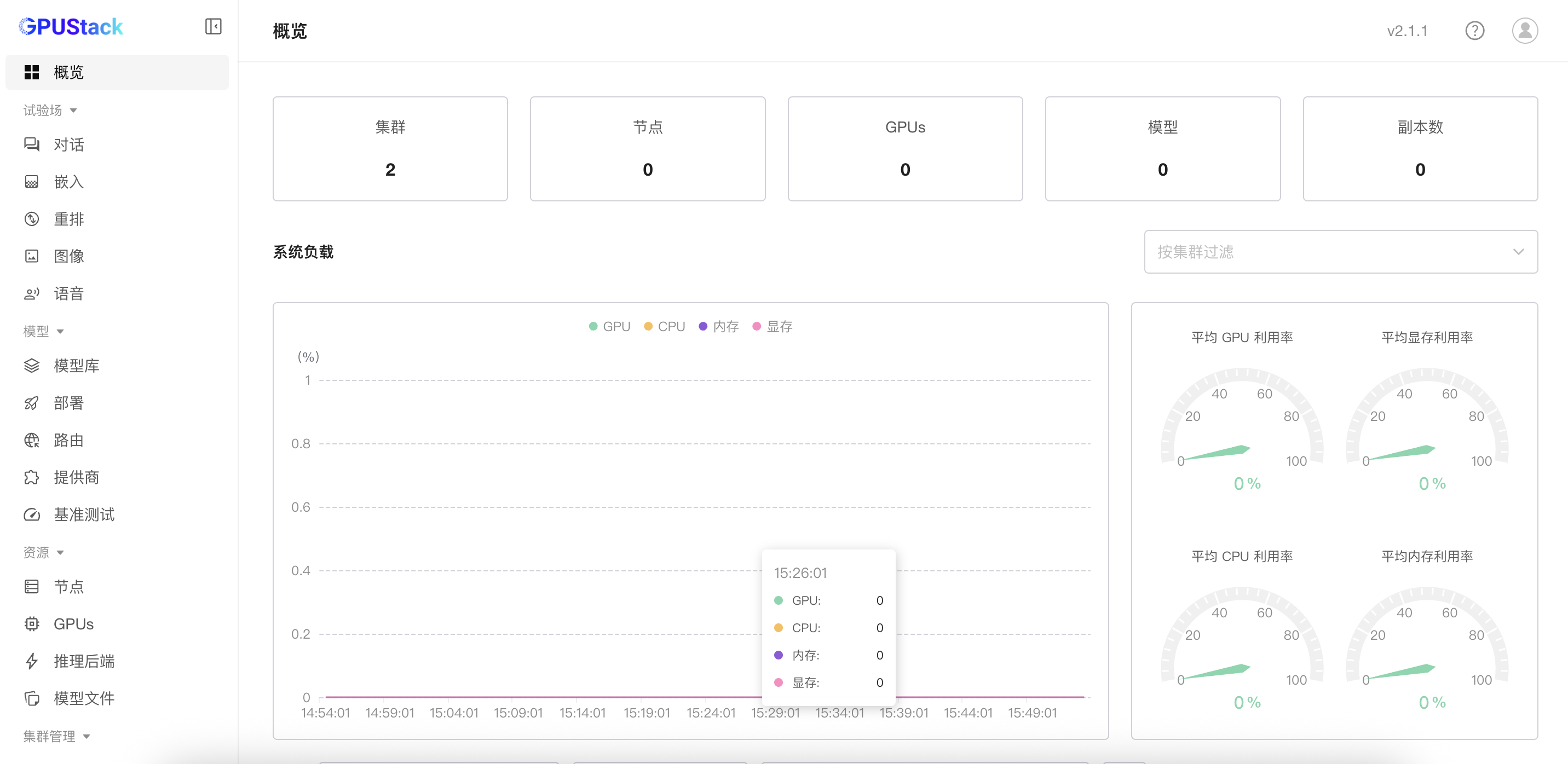
4.5 监控信息
GPUStack集成 Grafana 面板,无需额外部署即可监控 GPU / NPU 与系统资源利用率、模型实例运行状态、 推理指标(TTFT / TPOT / ITL、延迟分布、缓存命中率等,推理服务运行状态更加直观,同时可与企业监控体系集成。
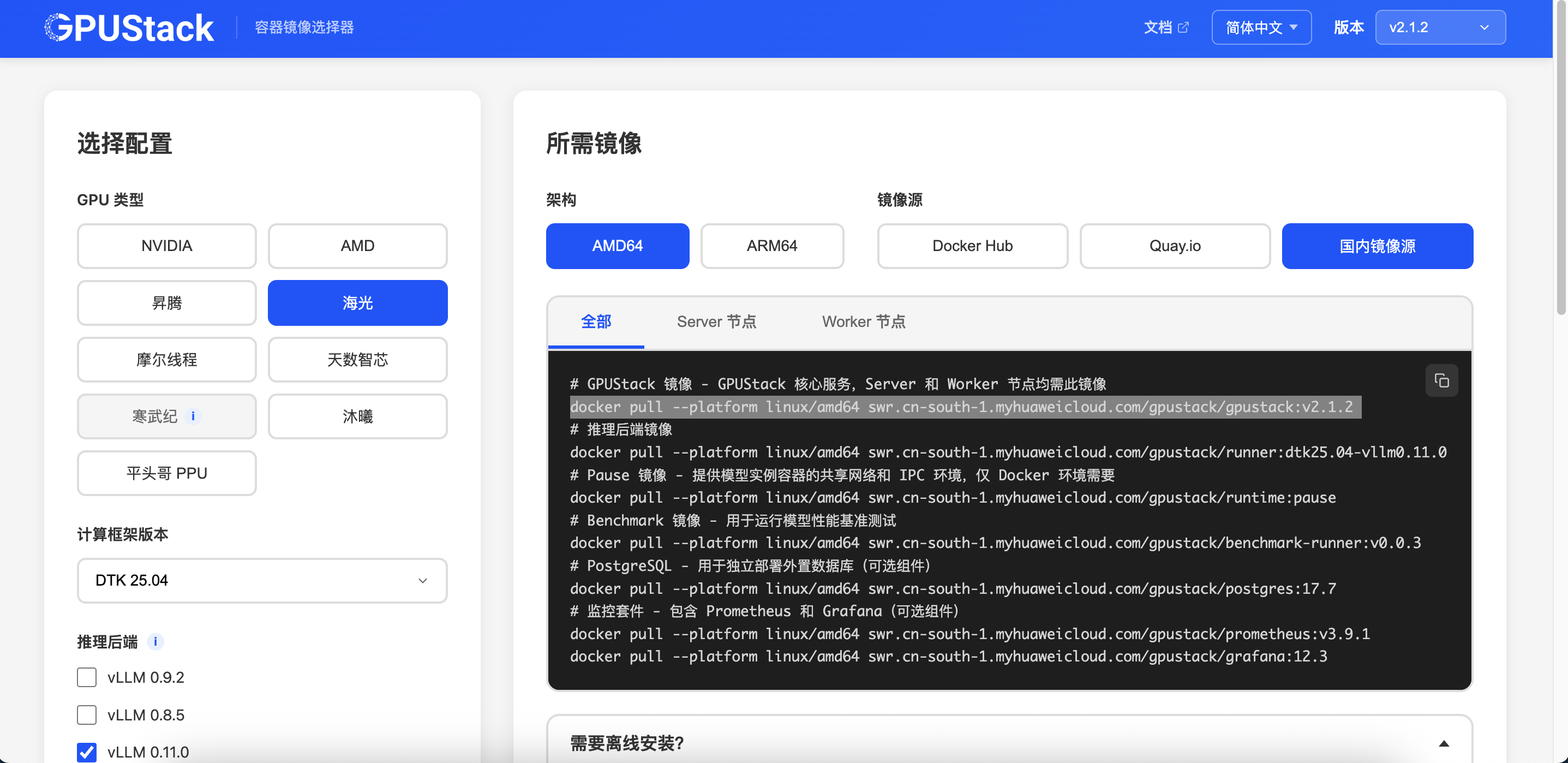
4.6 离线部署
增强离线环境支持,GPUStack支持容器镜像选择器,在内网或离线环境部署 GPUStack 时,不同硬件环境的容器镜像准备往往较为复杂。为此,GPUStack 官方提供了离线镜像选择器:
https://docs.gpustack.ai/latest/image-selector
用户只需选择对应的硬件环境,即可生成所需镜像及下载命令。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)