深度学习篇---强化学习
通俗易懂地介绍强化学习:
强化学习其实就像训练一只小狗。
你想让狗学会“坐下”这个动作,但狗根本听不懂人话。怎么办?你只能用奖励和惩罚来和它沟通:
-
它偶然坐下,你立刻喂它零食(奖励)。
-
它乱叫扑人,你就不理它或批评它(惩罚)。
慢慢地,狗就会在脑子里形成一个规律:在这个环境下,做什么动作能得到最大的好处。最终,它为了多吃零食,会主动把“坐下”这个动作做到完美。
这就是强化学习的核心,把它翻译成机器术语就是:
-
智能体 (Agent) = 小狗
-
环境 (Environment) = 你的客厅和指令
-
状态 (State) = 狗当前是站着、坐着,以及它听到的命令
-
动作 (Action) = 狗做出的行为:趴下、转圈、坐下
-
奖励 (Reward) = 你做对了(+1分零食),做错了(-1分被批评)
智能体的唯一目标,就是通过不断试错,找到一套策略,让最终累计的奖励最大化。 它不需要你告诉它“先迈哪条腿”,它自己会去探索和发现。
接下来是强化学习最经典的马尔可夫决策过程 (MDP) 的运转流程图。
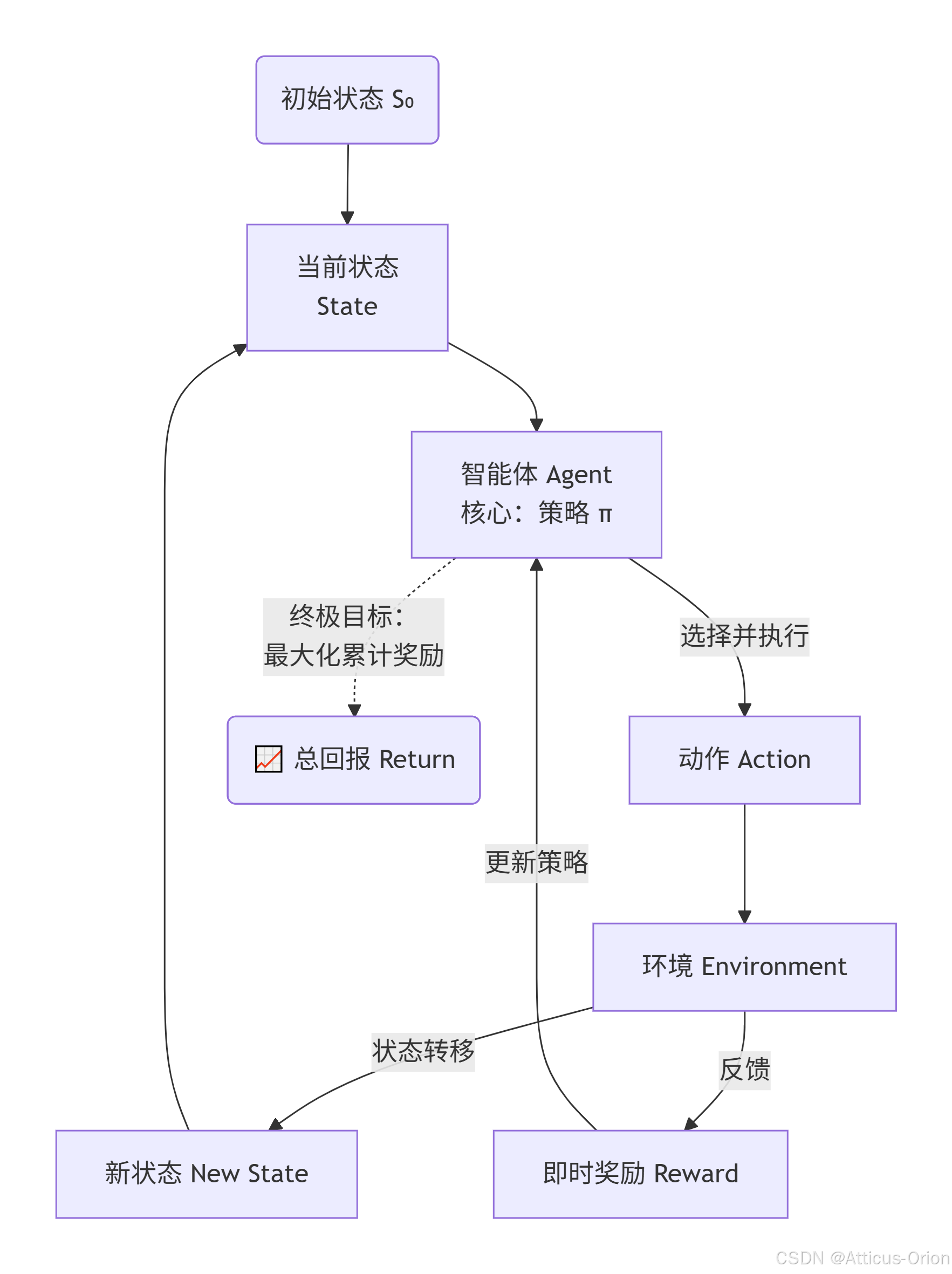
这个图展示的是“智能体-环境”这个循环圈里,一个时间步内发生了什么:智能体看到当前状态,凭策略选一个动作,环境接收动作后状态变了,同时返回一个奖励信号,智能体再根据新奖励去更新自己的策略。
流程解读:
-
观察:智能体看到环境给出的“当前状态”。
-
决策:智能体根据它的“策略”(可以理解为当时的脑子),选出一个“动作”来执行。
-
反馈:环境接收动作后发生变化,进入“新状态”,并吐出一个“奖励分”。
-
学习:智能体用这个奖励分来评判刚才动作的好坏,并优化自己的“策略”,让下次能得更高分。
-
循环:新状态又变成起点,周而复始。
这个循环一直跑,智能体就会越来越“聪明”。最后,你可以拿着它训练好的策略去解决各种实际问题,比如让机器人走路、让AI下围棋,甚至用来优化股票交易决策。
优化策略:
简单来说,优化策略,就是不停地修改那个动作“打分表”,让好动作以后更可能被选,坏动作更少被选。
具体实现上,主要分两大流派:先算分再行动和直接改脑子。再加快捷的第三种方式。
流派一:值函数法——先当“评论家”,算出每个动作的潜在价值
这个方法的核心是不直接优化策略,而是先去完善一张Q表。
1. 经典方法:Q-Learning + 表格
这就是一张超级表格,横轴是所有状态(比如围棋盘面),竖轴是所有动作(落子位置)。格子里的数字 Q值,代表“在当前状态下做这个动作,未来总共大概能得多少分”。
-
初始:表是空白的,智能体纯瞎试。
-
更新公式(通俗拆解):
新Q值 = 旧Q值 + 学习率 × (实际总得分 - 旧Q值)这里面
实际总得分是关键,它等于 即时奖励 + 折扣因子 × 新状态下所有动作里的最高Q值。这叫时序差分学习,用下一步的最好估计来修正当前的估计,就像用明天的预期来修正今天的判断。 -
策略体现:训练时,大部分时间直接选当前状态下的最高Q值动作(利用),小部分时间随机乱选(探索),这就是 ε-贪心策略。
2. 升级版:深度Q网络(DQN)
现实问题(如自动驾驶的图像)状态近乎无限,画不出表格。于是用神经网络来当Q表,输入状态画面,直接输出每个动作的Q值。
但它有三个核心技巧来保持稳定:
-
经验回放:建一个记忆库,存好之前的经历。训练时随机抽一批来学,像学生反复看错题本,打破经历的强相关性。
-
双网络:用两个结构一样的网络。一个当前网络实时更新,负责选动作;另一个目标网络隔段时间才更新,负责算“实际总得分”里的那个最高Q值,防止目标值跟着当前网络一起剧烈波动。
流派二:策略梯度法——直接“动脑子”,不评分离谱分
值函数法要精确算每个动作的分数,有时很浪费。比如机器人走路,稍微往左或往右一点分都差不多,并不需要一个精确的“最优”值。
这个方法就直接把策略当作一个神经网络,输入状态,直接输出每个动作的概率。
-
核心思想:如果一个动作序列最终拿到了高回报,那构成它的所有动作的概率都要被提高;反之,拿了低回报,概率就降低。这就是“蒙地卡罗策略梯度(REINFORCE)”算法。
-
如何优化:算法像录播,把一个回合完整走完,算出总回报。然后直接修改神经网络参数,让回报高的动作序列下次出现概率更高。
流派三:演员-评论家法——融合两大流派精华
这是目前最主流的,结合了前两者的优点。
-
演员:相当于策略网络,负责行动。
-
评论家:相当于Q网络,负责评判刚才那个行动实际上比预期好多少。
优化流程(如A2C算法):
-
演员选个动作,环境给出奖励和新状态。
-
评论家根据奖励和新状态,给出一个优势函数值。大于0就是说“干得好,比预想的好”,小于0就是“干砸了”。
-
演员用这个优势值去更新自己的网络参数,优势大的动作概率大幅提升,优势小的就少提或下降。
这就像学员(演员)边练车,教练(评论家)边坐在副驾给你实时打分纠错,比录完一局再复盘(流派二),或只打分没策略(流派一),学得都更快更稳。
快速总结一下:
-
Q-Learning/DQN:先学好坏标准,再按标准选最好的动作。
-
策略梯度:直接形成行为习惯,好习惯多重复,坏习惯少做。
-
演员-评论家:边行动边听实时评价来修正习惯,是目前效果最好的方法。
PPO(近端策略优化):
PPO,全称近端策略优化,是目前最主流的强化学习算法之一,ChatGPT就是用类似它的方法训练的。
你可以把它理解为:在演员-评论家模式上,加了一道安全锁。这道锁保证演员每次更新步子不要太大,防止“脑子一下学傻了,突然摔个狗吃屎”。
PPO实现这个安全更新的做法,核心是把新老策略的差异当作一种约束。
关键在于:用“剪切”锁死步子
PPO的核心目标函数里有一个非常巧妙的 clip 操作,我们来拆解一下:
-
概率比:你变心了没?
首先,它会计算一个概率比:概率比 = 新策略下做该动作的概率 / 旧策略下做该动作的概率-
如果比例 > 1,说明新策略更偏爱这个动作了。
-
如果比例 < 1,说明新策略打算少做这个动作。
-
-
剪切:画个安全区
PPO设定一个超参数ε(比如0.2),表示允许的最大变动幅度。然后它用clip函数把概率比强行限制在[1-ε, 1+ε]的区间内。这意味着无论你怎么学,新策略和旧策略的相似度必须在80%-120%之间,不能突变。
最终目标的通俗解释
PPO的最终目标,是选择剪切后和目标里更保守、更悲观的那个值来更新。
-
如果这个动作是好的(优势函数为正):
我们想提高它的概率,但最多只能提高到原来的1+ε倍,防止它被一下子学过头。 -
如果这个动作是坏的(优势函数为负):
我们想降低它的概率,但最多只能降到原来的1-ε倍,避免这个动作被完全消灭,万一以后又需要了呢。
一图看懂 PPO 的“安全更新”逻辑
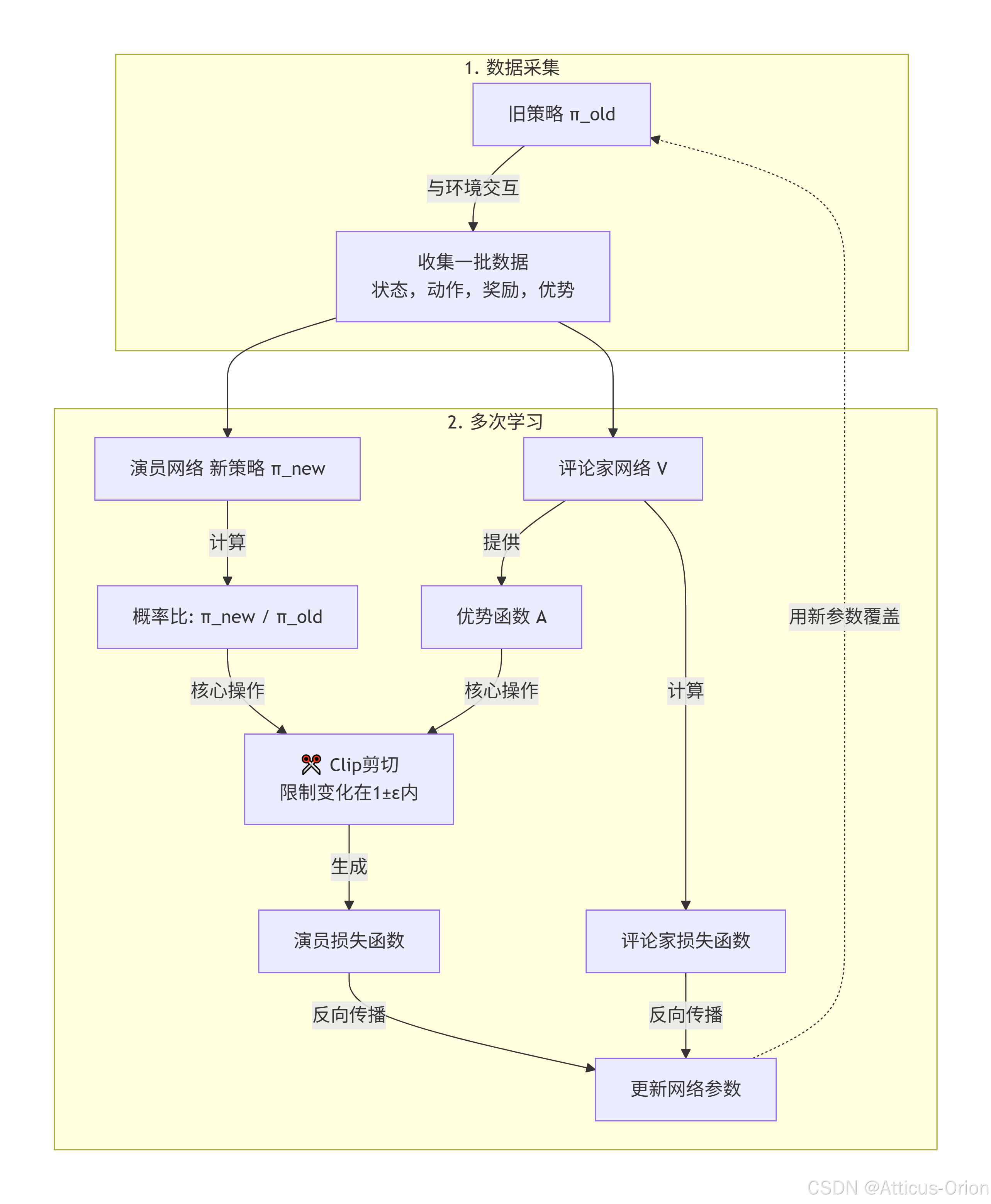
流程解读:
-
收集数据:先用当前的旧策略跟环境互动,攒一批经验数据。
-
利用旧数据,多次学习:这是PPO高效的关键。同一批数据,它可以重复学习好几个回合。
-
核心约束
Clip:在学习更新演员网络时,核心就是计算那个概率比,然后用Clip操作把它限制在 [1−ε,1+ε][1−ε,1+ε] 的安全区里,算出最终的损失。 -
同步更新:演员和评论家一起用这批数据更新自己。
-
覆盖:学完后,新策略变成了旧策略,再用它去收集下一批数据,周而复始。
这样,PPO就在“利用老知识”和“探索新知识”之间找到了一个很稳的平衡点。它既像策略梯度那样直接优化策略,又用类似TRPO(信任区域策略优化)的思想,但仅用简单的剪切操作就保证了训练的稳定,比复杂的TRPO容易实现得多。
所以,PPO方法现在成了很多研究者的默认首选,应用很广。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献65条内容
已为社区贡献65条内容

所有评论(0)