你以为你在训练大模型,其实你在烧钱打水漂——分布式训练的四个致命陷阱
一辆法拉利只用倒车档上高速,能跑多快?
这听起来像个笑话,但在很多 AI 团队的机房里,它每天都在真实上演。
写在前面
H100 一张卡的售价能买一辆轿车,一个千卡集群的电费一天就够普通人吃几年。可即便砸下这么多钱,绝大多数团队真正用上的算力,可能还不到硬件理论巅峰的 30%。
更尴尬的是:程序还在跑,损失还在降,监控里 GPU 利用率显示 100%——所有指标都告诉你一切正常,但你其实是在原地烧钱。
这篇博客把分布式训练里最常见、也最隐蔽的四个坑摊开来讲清楚。每一个我都会用两层语言来解释:先是工程师视角的硬核原理,再用一个生活化的比喻让它"秒懂"。如果你正在搭训练流水线,这篇文章可能值你几千美金的电费。
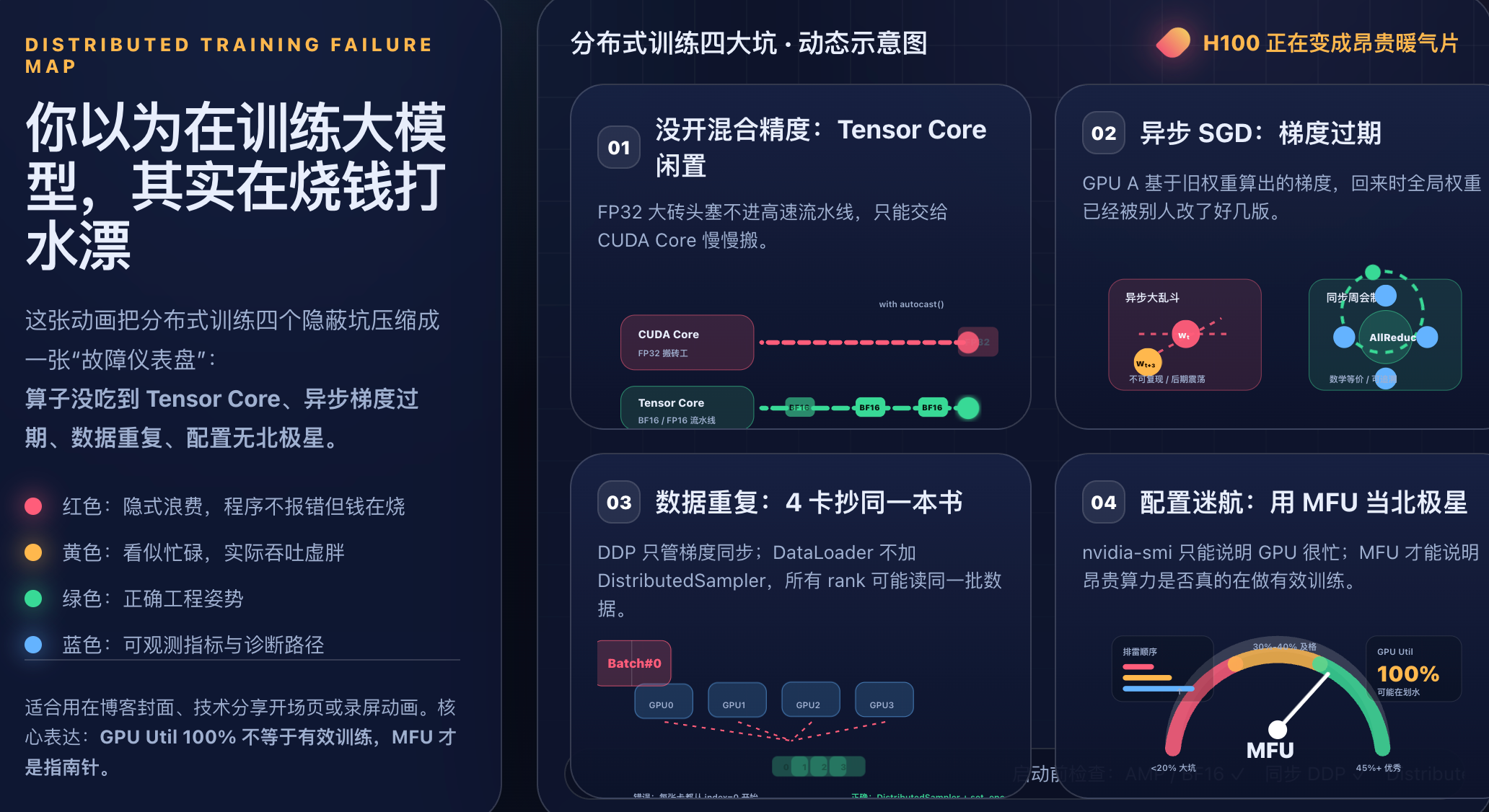
陷阱一:忘了开混合精度,等于把法拉利当人力车推
现象
代码里你写了下面这种 PyTorch 标准操作:
model = MyModel().cuda()
output = model(input_data)模型跑起来了,loss 在下降,看起来没毛病。但实际上,你的 H100 正在以实际能力的 1/20 速度慢悠悠地工作。
硬件原理:两种"工人"的根本差异
现代 GPU 里其实住着两类计算单元:
普通 CUDA 核心:通用计算单元,标量级别地处理 a × b + c。它什么都能干,但每个时钟周期只处理一对数。
Tensor Cores(张量核心):矩阵级别的专用加速器。每个时钟周期能一次性把一整块 4×4 或 8×8 的小矩阵乘加掉。
这个差距有多夸张?H100 在 FP32 下大约几十 TFLOPS,但开了 Tensor Core 跑 BF16/FP16,性能瞬间飙到接近 1000 TFLOPS。
关键约束:Tensor Cores 只吃 16 位精度的输入。如果你给它喂 FP32 的"大砖头",它直接罢工,活儿全甩给普通 CUDA 核心。
大白话比喻:自动化流水线 vs. 搬砖工
把 GPU 想成一家工厂:
- CUDA 核心像搬砖工,再小的砖头也是两手各拿一块往上叠,一秒处理几十块。
- Tensor Cores像自动化流水线,一秒能压几千块砖——但只能压"小砖头"(FP16/BF16)。
PyTorch 默认所有变量是 FP32,相当于你只搬运又大又沉的实心大理石。流水线塞不下,只能停摆,活儿全压给搬砖工慢慢叠。这就是 H100 为什么会"退化"成 4090 的真实原因。
为什么不能纯 16 位?
你可能想:那我全用 FP16 不就最快?
不行。深度模型训练涉及成千上万次梯度累加,FP16 的尾数位太短,累加一次就丢一点精度,最后梯度爆炸或不收敛——好比盖楼时砖头不够结实,叠到几千层就塌。
工业界的解法叫混合精度(Mixed Precision):
D=A×B+C
- A,B用 FP16/BF16:输入轻便,Tensor Core 压得爽
- C,D用 FP32 累加:保留数值稳定性
一句话:乘法用小砖头追求吞吐量,累加用大账本保证不出错。
正确姿势
不要手动 .half(),那容易溢出。用 PyTorch 自带的 AMP:
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for data, target in dataset:
optimizer.zero_grad()
with autocast(): # 自动决定哪些层用 Tensor Cores
output = model(data)
loss = loss_func(output, target)
scaler.scale(loss).backward() # 梯度缩放,防止 FP16 下溢
scaler.step(optimizer)
scaler.update()H100 时代更推荐 BF16——它和 FP32 拥有相同的指数范围,几乎不需要 GradScaler 就能稳定训练。
教训:在 H100 上写下
with autocast():这一行代码的价值,可能等同于你几十万美金的硬件投资。
陷阱二:异步 SGD 看起来很美,实则是调试地狱
现象
新手设计分布式架构时,常常有一个直觉:让每个 GPU 独立计算梯度并立即更新,不需要等待,效率最高。这就是异步 SGD。
听起来完美,对吧?所有 GPU 利用率永远 100%,谁也不拖后腿。
致命缺陷:梯度过期(Stale Gradient)
问题出在更新时序上:
- GPU A 拿到当前权重
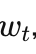 ,开始算梯度
,开始算梯度 - GPU B、C、D 算得快,已经把全局权重更新到了
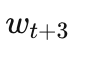
- GPU A 终于算完了,把基于的梯度推上去更新
GPU A 手里的梯度,是基于三个版本之前的权重算出来的。
数学上这叫陈旧梯度(Stale Gradient)。它指向的方向已经不再是当前权重的下降方向。模型会在训练后期出现极其诡异的行为:明明前 80% 收敛得好好的,最后 20% 突然震荡甚至发散,而且完全无法复现——因为时序本身就是随机的。
大白话比喻:小组论文的两种写法
8 个人合写一篇论文。
异步模式(大乱斗):每人写完一段就直接贴到云文档。张三写到第三页时参考的是李四的第一页内容,但等张三贴上去时,李四的第一页已经被改得面目全非。论文逻辑支离破碎,更糟的是——你根本找不出谁的问题,因为时间点是随机的,没法回放。
同步模式(周会制):约定每周五下午 5 点开会,所有人把这周的进度拿出来统一讨论合并。会上要等写得最慢的同学,但每次合并出的版本逻辑一致、可追溯。如果哪里写歪了,回滚到上周版本立刻就能定位问题。
同步 SGD 的工程优势
| 维度 | 异步 SGD | 同步 SGD |
|---|---|---|
| GPU 利用率 | 永远 100% | 等 straggler,有空闲 |
| 数学等价性 | 与单机不等价 | 与单机训练数学等价 |
| 可复现性 | 几乎不可能 | 完全可复现 |
| 调试难度 | 地狱 | 简单 |
| 收敛稳定性 | 后期可能崩 | 稳定 |
为什么异步在 2015 年很火,现在没人用了?
三个变化让"等待成本"几乎归零:
- NVLink/InfiniBand:节点内 GPU 互联带宽达到 900 GB/s,节点间也有 400 Gbps 以上。梯度交换的时间开销大幅降低。
- Ring All-Reduce:抛弃了中央 Parameter Server 的瓶颈架构,GPU 之间手拉手传梯度,通信效率接近理论上限。
- 人比机器贵:算法工程师花两周排查异步导致的不收敛问题,浪费的工资和机会成本,远远超过同步等待节省下来的电费。
教训:宁可让 GPU 等人,不可让人等 GPU。在现代数据中心里,同步 SGD + 混合精度 才是真正的性能与稳定性平衡点。
只有在网络极度恶劣、节点频繁掉线的极端场景(比如某些联邦学习),才会被迫考虑异步策略。
陷阱三:所有 GPU 加载同一批数据——最阴险的"无效分布式"
现象
你把单卡代码改成 4 卡分布式,模型部分认认真真套了 DistributedDataParallel:
model = DDP(model)跑起来一切正常:4 张 H100 风扇狂转,nvidia-smi 显示利用率 100%,loss 平稳下降。看起来加速效果不错。
但你不知道的是:4 张卡正在处理一模一样的数据。
为什么会撞车?
PyTorch 分布式训练里,每张 GPU 实际上是一个独立的 Python 进程。每个进程启动时,DataLoader 默认从索引 0 开始读数据——除非你显式告诉它"你是 1 号工人,请跳过前 N 条",否则所有进程都会忠实地读同一批数据。
后果:双重灾难
第一重灾难——算力浪费:4 张卡跑一轮 = 1 张卡跑一轮的训练效果。你付了 4 倍的钱,等的还是 1 倍的进度。
第二重灾难——梯度逻辑崩坏:DDP 会做梯度的 All-Reduce 求平均。当 4 张卡的梯度完全一致时:
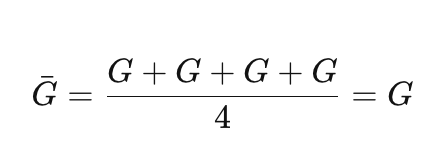
不仅没加速,反而因为多出来的网络通信开销,比单机跑还慢。
大白话比喻:4 个员工抢同一本书抄
你雇了 4 个员工去图书馆抄书。给每人发了一张一模一样的借书卡,叮嘱他们:"去把书架第一排的书抄了。"
结果这 4 个老实人全冲到第一排,抢着抄同一本《红楼梦》。
最阴险的一点:程序不会报错
这才是这个 Bug 真正可怕的地方:
- 没有 Exception
- Loss 正常下降
- GPU 利用率显示 100%
- 模型最终能收敛
你只会觉得"分布式跑得真稳",直到发现训练一个模型从预计的 1 天拖到了 4 天还没完。
救命稻草:DistributedSampler
from torch.utils.data.distributed import DistributedSampler
sampler = DistributedSampler(dataset)
# 注意:用了 sampler 就不能再设 shuffle=True,sampler 内部会处理
loader = DataLoader(dataset, batch_size=32, sampler=sampler)
for epoch in range(num_epochs):
sampler.set_epoch(epoch) # 关键!每轮重设种子,确保切片乱序
for data, target in loader:
...DistributedSampler 做的事情很简单:
- 查看总共有多少 GPU(
world_size) - 查看自己是几号 GPU(
rank) - 把数据集按 rank 切片:GPU 0 拿
[0, N, 2N, ...],GPU 1 拿[1, N+1, 2N+1, ...],以此类推
set_epoch(epoch) 这一行绝对不能忘——没有它,每一轮 epoch 各 GPU 拿到的切片顺序是固定的,模型看到数据的顺序永远一样,等于变相过拟合。
自查方法
进分布式环境后,每张卡打印一下第一个 batch 的特征摘要:
print(f"[Rank {rank}] First batch checksum: {data.sum().item()}")如果 4 个进程打印出来的数字一模一样——恭喜你,中招了。
教训:把单机代码改分布式时,模型端套 DDP 只是冰山一角,数据端必须配 DistributedSampler。一个少改一行的疏忽,足以让你的实验室白白浪费几十万的算力。
陷阱四:迷失在配置海洋里——把 MFU 当作北极星
现象
当训练规模从 8 卡扩展到 800 卡甚至 8000 卡,你会面对一个让人窒息的参数列表:
- 全局批次大小(Global Batch Size)
- 单卡批次大小(Per-Device Batch Size)
- FSDP 还是 HSDP?分片维度怎么切?
- 激活重计算(Activation Checkpointing)开多少层?
- 梯度累积步数?
- 流水线并行(PP)+ 张量并行(TP)+ 数据并行(DP)的 3D 切分比例?
- NCCL 通信参数?
每个参数都和其他参数耦合。改一个,可能让另外三个之前的优化失效。没有人能凭直觉调出最优配置。
解法:盯住 MFU 这一个指标
MFU(Model FLOPs Utilization)的定义:
MFU=训练过程中的实际有效 FLOPs硬件理论巅峰
它告诉你一件最简单的事:这块昂贵的芯片,到底有多少比例的时间在真正算数学题,多少比例在划水?
为什么 MFU 比吞吐量(Tokens/sec)更可靠?
吞吐量会被"假数据"污染。比如开了激活重计算,前向计算被多做了一次以省显存——这部分多出来的"吞吐"对模型训练毫无意义,但它会让 Tokens/sec 数字变好看。
MFU 剔除了所有这些"虚胖",只看有效计算。
怎么算?Transformer 训练的黄金公式
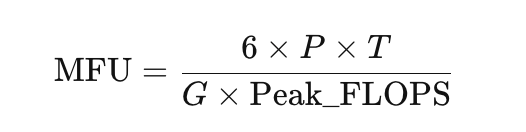
- PP P:模型参数量
- TT T:每秒处理 token 数(吞吐量)
- GG G:参与训练的 GPU 数
- Peak_FLOPS:单卡的理论巅峰算力(H100 BF16 ≈ 989 TFLOPS)
- 系数 66 6:每个 token 的训练成本——前向 2P2P 2P + 反向 4P4P 4P
一个具体例子
假设:8 张 H100 训练 7B 模型,每秒处理 18,000 tokens。
分子(实际有效 FLOPs):
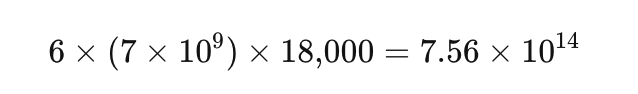
分母(硬件总算力):
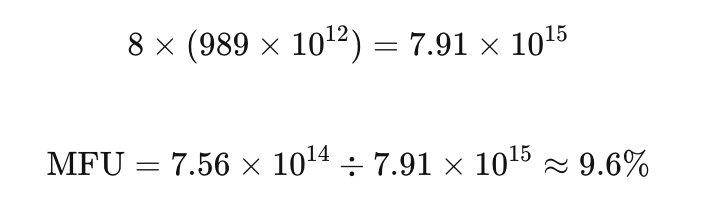
这个数字意味着:你 90% 的算力都被浪费了。要么数据加载是瓶颈,要么通信占用了太多时间,要么算子写得不够好。
警告:千万别只看 nvidia-smi
nvidia-smi 里那个 GPU Utilization 是个大忽悠。它显示的 100% 仅仅意味着"显卡在忙",但没说在忙什么:
- 数据加载慢,GPU 在傻等数据 → 100%
- 算子大量内存读写但没真算东西 → 100%
- 通信阻塞 → 100%
只有 MFU 不撒谎。
MFU 的对照基准
| MFU 范围 | 含义 |
|---|---|
| < 20% | 流水线有大 Bug 或策略选错 |
| 30%–40% | 工业级及格线 |
| 45%–55% | 调优高手 |
| > 60% | 神级水平,一般只在底层框架极致优化下出现 |
怎么用 MFU 反推问题?
当你看到 MFU 很低,不要乱试参数。按下面这个排雷顺序:
1. 通信瓶颈?
如果你用了纯 FSDP 跨节点全分片,节点间通信会非常重。试试切换到 HSDP(节点内 FSDP + 节点间 DP):节点内全分片省显存,节点间只做普通数据并行通信。MFU 通常会立刻拉升一截。
2. Batch Size 太小?
为了不 OOM,你把单卡 batch 调到 1 或 2——这会让 Tensor Cores 几乎跑不起来("喂豆子"问题)。开启激活重计算省显存,把 Batch Size 顶到 GPU 真正吃饱为止。
3. 算子层面没优化?
注意力机制是计算大户。如果还在用原生 PyTorch Attention,换成 FlashAttention-2——它通过减少 HBM 读写次数,能显著拉升 MFU。
4. 数据加载是瓶颈?
打开一个简单的诊断:临时把 DataLoader 的输出换成预先生成的 dummy tensor。如果 MFU 立刻飙升,说明你的数据流水线(CPU 预处理 / IO)跟不上 GPU 吞吐。解法:增大 num_workers、用 prefetch_factor、上 NVMe SSD。
调优的"配置互搏"
工程师们最容易踩的坑是:一个参数的优化会拆掉另一个参数的优化。
- 想省显存 → 开 FSDP → 通信量飙升 → MFU 崩
- 想省通信 → 关 FSDP → 显存炸 → 减小 Batch Size → MFU 又崩
所以不要追求"每个参数都最优",要追求 MFU 这个综合指标最大化。
工作流应该是:
- 跑一个基线,记录 MFU
- 改一个参数
- 看 MFU 升了还是降了
- 沿着 MFU 上升的方向继续
教训:在千卡集群上,MFU 是你唯一的指南针。只要 MFU 在涨,你就在正确的航道上。
把四个坑串起来看
回头看看这四个陷阱,它们其实是一条递进的链条:
| 层级 | 陷阱 | 本质 |
|---|---|---|
| 单卡 | 忘开混合精度 | 没有调用专用硬件 |
| 多卡 | 异步 SGD | 数学逻辑被破坏 |
| 多卡 | 数据重复 | 分布式语义形同虚设 |
| 多机 | 配置迷航 | 缺少综合优化指标 |
它们有一个共同特征:程序不会报错,监控看起来正常,但你在烧钱。
这也是分布式训练最反直觉的地方——它的失败不是显式的崩溃,而是隐式的浪费。一个团队可能用着比别人贵 10 倍的硬件,跑出比别人慢 5 倍的进度,还以为自己在做高端 AI。
给工程师的一份"出门检查清单"
每次启动一个新的分布式训练任务前,把这张清单跑一遍:
- ✅ 是否启用了
torch.cuda.amp.autocast()或 BF16?- ✅ 是否使用了
DistributedDataParallel(同步),而不是异步 RPC 方案?- ✅ 是否给 DataLoader 配了
DistributedSampler+set_epoch()?- ✅ 是否每张卡打印了 first batch checksum 验证数据切分?
- ✅ 是否计算了基线 MFU?是否高于 30%?
- ✅ 通信策略(DDP / FSDP / HSDP / 3D 并行)是否匹配你的网络拓扑?
每一项都对应着真金白银。
结语
分布式训练四大坑
H100 这种级别的硬件,每一秒的算力都比你点的咖啡还贵。它的价值不会自动兑现——只有当你正确激活了 Tensor Cores、选对了同步策略、切对了数据、调对了拓扑配置,那些天文数字的 TFLOPS 才会变成模型 loss 曲线上真实的下降。
否则,你只是在为一台昂贵的暖气片付电费。
愿你的 MFU 永远 > 45%。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)