阿里Qwen-VLA:统一视觉-语言-动作建模,迈向通用具身智能
基于大规模联合预训练的跨任务、跨环境、跨本体具身基础模型
论文来源:arXiv:2605.30280v1 | 研究团队:Qwen Team
具身智能旨在构建能够感知物理世界、理解自然语言指令、进行时空推理并执行动作以完成目标的智能体。然而,现有研究往往针对单一任务或场景设计专用模型,例如专注于桌面操作的机械臂策略,或针对室内环境的导航模型,这种碎片化的研究范式限制了模型在不同任务、环境与机器人本体之间的泛化能力。近期,Qwen Team 提出了 Qwen-VLA,一个统一的视觉-语言-动作(Vision-Language-Action, VLA)基础模型,尝试将异质的具身决策问题纳入单一的建模框架,在操作、导航与轨迹预测等多个领域展现出一致的跨任务性能与分布外泛化能力。
一、研究背景:从专用模型到统一框架
近年来,视觉-语言模型(VLM)在开放世界视觉理解与语言 grounding 方面取得了长足进步,而基于扩散或流匹配的策略模型在连续高维机器人动作建模上亦显示出巨大潜力。尽管如此,大多数现有具身系统仍局限于狭窄的任务族、机器人本体或评估设定。操作模型通常针对桌面或灵巧控制进行训练,导航模型则围绕室内环境中的路径点或离散移动决策进行设计。这种碎片化不仅限制了跨任务、跨环境与跨本体的迁移能力,也使得具身学习难以像通用视觉-语言模型那样实现规模化扩展。
从表面看,机器人操作与视觉-语言导航似乎是异质问题:前者可能需要预测末端执行器位姿、关节位置或夹爪状态,后者则需要输出路径点或离散移动决策;第一人称人类演示提供的是腕部与手部轨迹,而非机器人控制信号。这些任务在观测格式、控制频率、预测时域、动作维度与评估协议上均存在差异。然而,它们共享一个共同的计算结构:智能体必须基于视觉观测、语言指令与本体约束进行条件判断,进而预测与任务在物理与语义上对齐的未来动作或轨迹。正是这一观察启发了 Qwen-VLA 的统一建模思路。
**核心洞察:**操作、导航与以轨迹为中心的任务,可被视为共享动作-轨迹预测问题的不同表现形式。通过统一的条件预测框架,单一模型即可吸收来自异质数据源的监督信号。
二、统一架构:认知主干与运动专家的协同
2.1 统一问题建模
Qwen-VLA 将操作、导航、轨迹预测与第一人称人类动作建模纳入统一的条件预测框架。在时刻 t,模型接收视觉上下文 ot(可包含单帧或多帧图像、视频观测或历史窗口)、语言指令 x、本体描述 e 以及可选的任务标识符 z,被训练用于预测未来 H 步的目标序列 yt:t+H-1:
pθ(yt:t+H-1 | ot, x, e, z)
对于操作任务,目标序列对应末端执行器位置等机器人动作;对于导航任务,表示导航决策或路径点;对于轨迹中心任务(如自动驾驶),表示智能体或周围实体在连续坐标空间中的精确未来空间轨迹;对于第一人称数据,则捕捉人体或手部运动轨迹。这一统一形式使模型能够在单一框架内联合优化异质数据集。
2.2 模型架构
Qwen-VLA 采用"认知主干 + 运动专家"的双模块架构。认知主干选用 Qwen3.5-4B,这是一个原生多模态模型,通过早期视觉-语言融合将 ViT 产生的视觉 token 直接交错插入文本 token 流,实现图像、视频与语言的统一处理。其混合注意力设计在大部分层采用门控线性注意力,并在间隔层保留分组查询 softmax 注意力,可在高效编码长多模态序列的同时保持全局推理精度。
运动专家则是一个单流的 DiT(Diffusion Transformer)风格流匹配策略头,用于预测跨机器人与人类数据的精确连续动作。该模块将 VLM 隐状态与噪声动作块拼接为统一序列,通过联合自注意力与 AdaLN 时间步条件进行处理。这种解耦设计让运动专家专注于细粒度动作生成,同时保留主干的预训练能力。推理时,动作序列通过少量欧拉积分步骤生成,支持低延迟实时控制。
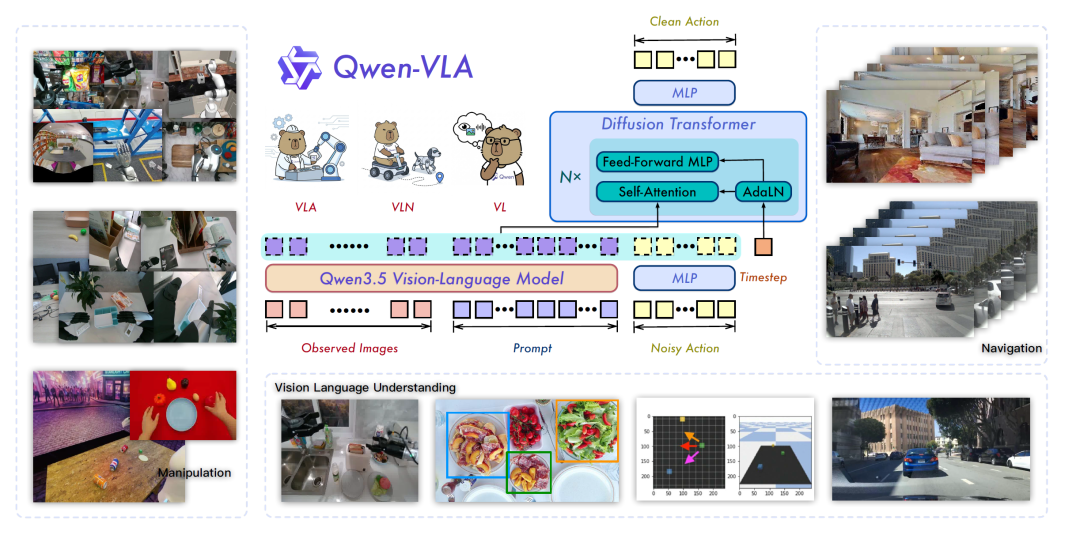
图 1:Qwen-VLA 统一具身模型总览。模型在混合操作、导航与视觉-语言理解数据上进行训练,能够生成机器人动作与文本输出。
2.3 本体感知提示条件
为在共享模型中支持多种机器人平台,Qwen-VLA 引入了本体感知提示条件(Embodiment-aware Prompt Conditioning)。每个训练样本前均附加一段描述当前平台的文本,包括机器人型号、臂配置、控制约定、控制频率与预测时域。例如:
“The robot is {robot_tag} with {single arm / dual arms} [, waist] [, and mobile base]. The control frequency is {FPS} Hz. Please predict the next {chunk_size} control actions to execute the following task:”
该提示作为模型获知本体相关控制语义的唯一接口。结合统一的动作表示,同一动作解码器即可处理不同的控制模式、动作维度与时域,无需为每种本体单独设计输出头。
2.4 统一动作与轨迹表示
模型统一了张量接口与掩码机制,但并未强制将所有本体纳入单一物理语义空间。每种数据集保留其原生控制约定,通过本体提示与数据集特定的归一化进行区分。具体而言,每个样本贡献目标张量 Y ∈ ℝH×K,其中 H 为固定预测时域,K 为跨所有控制模式共享的固定通道维度。控制信号分为两类:操作信号(包括 delta 末端执行器位置、旋转欧拉角或四元数、绝对关节位置、夹爪开度与灵巧手关节角)与导航轨迹信号(遵循 VLN 约定的路径点 Δx, Δy, Δθ)。尽管物理语义不同,二者均被视作时域上的实值向量序列,由运动专家统一处理。
三、四阶段渐进训练:从语言到动作,再到视觉 grounding
训练一个可用的 VLA 模型需要协同优化认知主干与运动解码器,但二者进入训练时的状态极不对称:VLM 主干已完成大规模预训练,而 DiT 解码器随机初始化。若直接启动多模态联合训练,解码器需同时学习动作分布形状、语言与本体条件、流匹配动力学以及视觉 grounding,效率低下且可能破坏预训练表示。
Qwen-VLA 采用基于"压缩视角"的四阶段渐进训练配方,将动作先验压缩、视觉 grounding、任务特化与成功驱动优化分离为不同阶段:
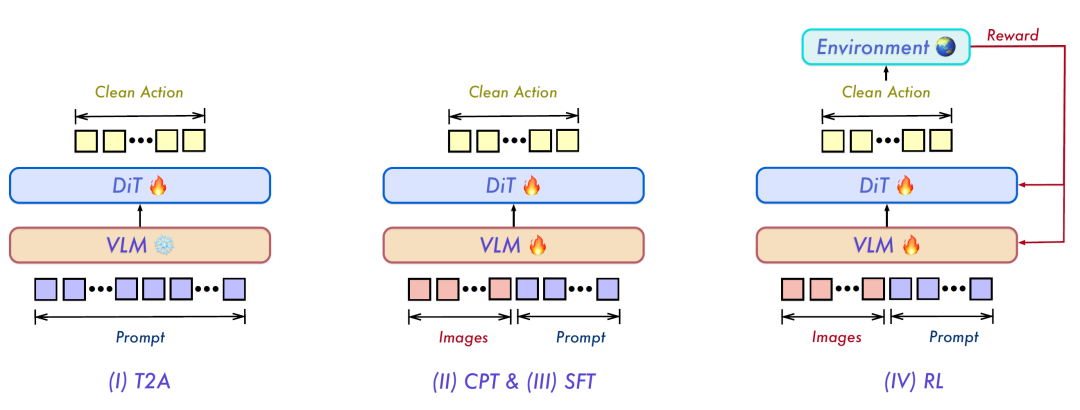
图 2:Qwen-VLA 四阶段训练策略。(I)T2A 阶段仅训练 DiT 解码器从文本重建动作;(II)CPT 阶段解冻双模块,将动作先验 grounded 于视觉观测;(III)SFT 阶段分化为多任务与真实机器人两条轨道;(IV)RL 阶段通过环境奖励优化闭环任务成功率。
3.1 文本到动作预训练(T2A)
第一阶段冻结 VLM,仅训练 DiT 解码器以文本与本体提示为条件重建动作,故意 withholding 图像输入。此阶段迫使解码器作为纯粹的语言-动作解压器:必须从紧凑的语言编码中重建高维动作分布,建立以语言为索引的结构化动作先验。实验表明,T2A 阶段在约 2,000 步时达到性能峰值(71.1%),继续训练至 40,000 步反而因过拟合导致下降至 60.4%。
3.2 持续预训练(CPT)
第二阶段解冻双模块,在异质混合数据上训练,使解码器将已建立的动作先验 grounded 于视觉观测,同时让主干适应具身感知。该阶段刻意混合仿真与真实机器人轨迹,使后续阶段能够面向任一领域进行特化。
3.3 监督微调(SFT)
第三阶段从 CPT 检查点分化为两条并行轨道:多任务 SFT 在异质任务上联合微调,包括视觉问答、空间 grounding、操作与导航;真实机器人轨道则在内部遥操作数据上微调,用于物理世界部署。
3.4 强化学习(RL)
第四阶段以多任务 SFT 为起点,采用 PPO(Proximal Policy Optimization)与 GAE(Generalized Advantage Estimation),在单一仿真环境(SimplerEnv)中基于稀疏二元成功奖励优化闭环任务成功率,得到最终模型 Qwen-VLA-Instruct。值得注意的是,RL 的增益不仅限于训练环境,在未见过的基准上亦保持或略有提升,表明任务成功优化可迁移至分布外设定。
四、大规模异质数据混合:覆盖操作、导航与理解
预训练语料的质量与多样性直接决定了认知主干与运动解码器能否跨本体与任务族协同适应。Qwen-VLA 构建了涵盖五大类数据源的大规模混合语料:
|
数据来源
|
占比
|
说明
|
| — | — | — |
|
机器人操作轨迹
|
74.2%
|
真实与仿真操作数据,覆盖单臂、双臂、移动与灵巧手控制
|
|
第一人称人类轨迹
|
6.0%
|
Ego4D、EPIC-KITCHENS、EgoDex、EgoVerse、Xperience 等
|
|
导航轨迹
|
7.5%
|
指令跟随、目标搜索与目标跟踪数据
|
|
合成仿真轨迹(自研)
|
3.7%
|
基于 IsaacLab 与 cuRobo 生成,覆盖短程与长程任务
|
|
通用视觉-语言数据
|
3.4%
|
图像描述、知识问答、OCR 与 grounding 任务
|
|
二维空间 grounding
|
2.5%
|
边界框定位数据,强化对象级空间理解
|
|
自动驾驶 VQA
|
2.4%
|
时序场景理解、环视空间推理与语言 grounding
|
|
细粒度具身动作描述
|
0.2%
|
13 维度的密集动作视频-文本对
|
4.1 机器人操作轨迹
操作轨迹构成预训练语料的核心(74.2%)。公开数据集包括 RobotSet、Galaxea、AgiBot World、RoboCOIN、RoboMIND V1/V2、RDT-1B、DROID、BridgeData V2、RH20T、RT-1 与 BC-Z 等,涵盖超过 10,000 小时的交互数据。此外,团队补充了超过 1,000 小时的内部真实机器人轨迹,并通过自研的 ROBOINF 可扩展仿真管线生成了超过 800 万条合成轨迹。
数据覆盖的代表性本体包括 WidowX、Google Robot、Franka Panda、ARX5、Fourier GR-1、Mobile ALOHA、AgiBot A2-D、Galaxea R1、AIRBOT MMK2、TienKung 等,动作类型涵盖 delta 末端执行器位姿、绝对关节位置、夹爪状态与灵巧手关节角。所有动作维度均采用分位数归一化,消除跨本体与动作空间的尺度差异。
4.2 第一人称人类数据
相较于遥操作机器人轨迹,第一人称人类演示提供了更丰富、更可扩展的真实世界操作经验。Qwen-VLA 引入了 6.0% 的第一人称人类操作数据,来源包括经 VITRA 处理的 Ego4D 与 EPIC-KITCHENS 子集(含逐帧 3D 手部与相机运动轨迹)、基于 Apple Vision Pro 采集的 EgoDex(829 小时,194 项桌面任务)、协作平台 EgoVerse(1,300 小时,1,965 项任务,240 个场景)以及大规模多模态数据集 Xperience(含深度、手部与身体动作捕捉及分层语言标注)。
人类手腕运动以 SE(3) 变换表示,手部姿态通过 PCA 降维为 10 个主成分(eigengrasps),每步共 32 维动作信号。这些数据为模型提供了超越机器人遥操作范围的广泛操作先验。
4.3 合成仿真数据
为提升覆盖度、可控性与鲁棒性,团队基于 IsaacLab 与 cuRobo 构建了大规模合成数据管线。视觉-语言-动作数据通过 ROBOINF 生成,包含 20 个桌面场景、200 种基础配置与 450 项操作任务(短程与长程),每项任务生成 300 条成功轨迹,并在光照、相机位姿、背景、桌面纹理、机器人初始状态与控制器动力学等方面进行域随机化。长程任务还被自动分割为子任务轨迹,提供多时间粒度的监督。
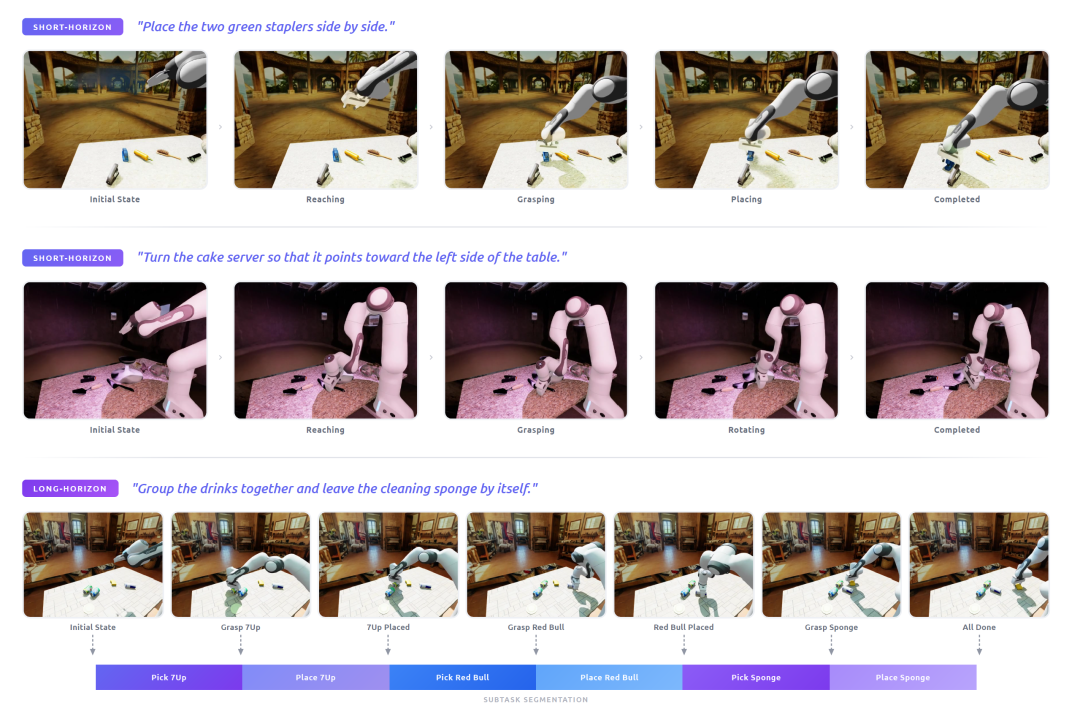
图 3:ROBOINF 生成的合成数据示例。上排为短程任务"将两个绿色订书机并排放置";下排为长程任务"将饮料归拢并将清洁海绵单独放置",可分解为多个子任务段。
4.4 导航与视觉-语言辅助数据
导航数据(7.5%)涵盖指令跟随(4.3%)、目标搜索(2.3%)与目标跟踪(1.0%),赋予模型长程指令跟随、探索与移动能力。辅助视觉-语言数据(8.5% 合计)包括细粒度具身动作描述(48,000 对视频-文本,13 维度标注)、自动驾驶 VQA(2.4%,覆盖 LingoQA、DriveAction、MMAU、nuScenes-QA 等)以及通用视觉-语言数据(3.4%),用于缓解灾难性遗忘并强化空间推理与指令跟随能力。
五、实验评估:跨本体、跨任务与分布外泛化
5.1 仿真操作基准
团队在 LIBERO、Simpler-WidowX、RoboCasa-GR1 与 RoboTwin 2.0 四个仿真环境上评估了操作能力,覆盖单臂桌面、双臂人形厨房与双臂协作场景。如下表所示,Qwen-VLA-Instruct 作为单一通才模型,在多数基准上超越了专用模型:
|
方法
|
类型
|
LIBERO
|
RoboCasa-GR1
|
Simpler-WidowX
|
RoboTwin-Easy
|
RoboTwin-Hard
|
| — | — | — | — | — | — | — |
|
π0
|
专用
|
94.4
|
—
|
—
|
65.9
|
58.4
|
|
GR00T N1.6
|
专用
|
97.2
|
49.9
|
63.2
|
47.6
|
—
|
|
π0.5
|
专用
|
97.6
|
37.0
|
46.9
|
82.7
|
76.8
|
|
ABot-M0
|
专用
|
98.6
|
58.3
|
—
|
86.0
|
85.0
|
|
Qwen-VLA-Base
|
通才
|
90.8
|
40.4
|
64.3
|
64.3
|
66.4
|
| Qwen-VLA-Instruct |
通才
|
97.9
|
56.7
|
73.7
|
86.1
|
87.2
|
在 LIBERO 上,Qwen-VLA-Instruct 达到 97.9%,与最优专用模型持平;在 RoboCasa-GR1 上取得 56.7%,超越 π0.5(37.0%)与 GR00T N1.6(49.9%);在 Simpler-WidowX 上达到 73.7%,超越 StarVLA-OFT(64.6%);在 RoboTwin-Easy/Hard 上分别取得 86.1% 与 87.2%,超越此前最优专用模型 ABot-M0(86.0% / 85.0%)。这些结果证实,联合多本体训练并未牺牲任务专用性能,通才模型甚至在多个基准上超越了专用模型。
5.2 真实世界操作评估
在 ALOHA 双臂机器人平台上,团队评估了域内任务与分布外(OOD)泛化能力。域内任务涵盖拾取放置、桌面清理、碗碟堆叠、毛巾折叠与细粒度操作(如开抽屉放物、插槽、堆叠积木)。Qwen-VLA-aloha w/ pretrain(基于 Qwen-VLA-Base 微调)平均成功率达 83.6%,显著优于 GR00T N1.6(28.6%)与 π0.5(71.6%)。

图 4:ALOHA 双臂平台上的真实世界评估任务概览,包含域内任务(拾取放置、桌面清理、碗碟堆叠等)与多种分布外泛化测试(颜色、实例、位置、背景、指令泛化)。
在 OOD 泛化测试中,模型面对未见颜色、未见物体实例、未见空间位置、未见背景光照与未见指令变体。Qwen-VLA-aloha w/ pretrain 平均 OOD 成功率达 76.9%,较 π0.5(41.5%)提升 35.4 个百分点,较从头训练版本(36.2%)提升 40.7 个百分点。尤其在背景泛化(80.8%)与指令泛化(84.6%)上表现突出,表明大规模预训练不仅提升了域内性能,更显著增强了视觉条件与指令理解的鲁棒性。
5.3 视觉-语言导航
在 VLN-CE 连续环境导航基准的 R2R 与 RxR Val-Unseen 分割上,Qwen-VLA-Instruct 在多数指标上取得最优。R2R 上 Oracle Success 达 69.0,Success Rate 达 57.5;在更具挑战性的 RxR 上,Success Rate 达 59.6,SPL 达 47.8,均超越现有开源基线。这表明联合训练 VLA 与 VLN 数据能够在保持操作能力的同时,维持合理的导航性能。
5.4 分布外泛化:静态与动态操作
为测试预训练先验是否超越微调分布,团队构建了 SimplerEnv-OOD 基准:所有模型仅在包含简单拾取放置的 Bridge 训练集上微调,却在评估时面对六种未见任务类型(如 MoveAway、MoveRight、PlaceNear、StackYellow 等)。Qwen-VLA-Instruct 平均成功率达 32.0%,显著超越 π0.5(12.6%)。在颜色推理任务 StackYellow 上(训练数据仅包含绿叠黄,测试要求黄叠绿),模型取得 22.9%,而 π0.5 仅为 4.2%,显示出对新颖颜色-物体绑定的强泛化能力。
在 DOMINO 动态操作基准的零样本测试中,Qwen-VLA-Instruct 取得 Success Rate 26.6% 与 Manipulation Score 39.5,超越所有动态操作专用基线(包括经 DOMINO 专用微调的 PUMA,SR 17.2%)。值得注意的是,模型在推理时仅使用当前帧观测,未接受任何动态操作微调,其优势源于统一的动作-轨迹预训练策略所习得的可迁移空间-运动学映射。

图 5:Qwen-VLA-Base 在 ALOHA 双臂机器人上的定性分布外泛化结果。左上:按颜色条件抓取(绿、蓝、红、黄球);右上:零样本抓取未见物体(西兰花、玩具鸭)与组合式桌面清理;左下:与完全未见物体交互(太阳镜、毛绒娃娃);右下:在未见过黄色背景下完成拧笔帽放置任务。
5.5 消融实验
消融实验系统验证了各设计选择的有效性:
**T2A 数据构成:**纯真实数据 T2A 得 51.0%,纯合成数据得 64.1%,而约 20% 合成 + 80% 真实混合达到最优 71.1%。合成数据拓宽了语言-动作对应覆盖,真实数据则将先验锚定在物理合理的动力学上。
**序列预测模式:**全序列预测在所有数据混合上均优于分块预测(10% 合成时差距 +4.94pp),因为全序列使解码器学习语言到完整动作序列的映射,包括轨迹级连贯性与组合性。
**T2A 阶段 withhold 视觉输入:**在 10% 合成数据设置下,带图像的分块预测得 57.6%,不带图像得 60.4%,包含视觉反而带来 -2.87pp 惩罚。这证实 T2A 阶段应完全抑制图像 token,迫使解码器建立可靠的语言-动作映射。
**流匹配时间步分布:**T2A 阶段采用 Sigmoid-Normal 分布(在中间噪声水平峰值)、CPT/SFT 阶段采用 Beta 分布(在干净端峰值)的组合取得最优 71.1%。无视觉条件时,中间时间步携带最多学习信号;有 VLM 丰富条件后,偏向干净端的 Beta 分布更样本高效。
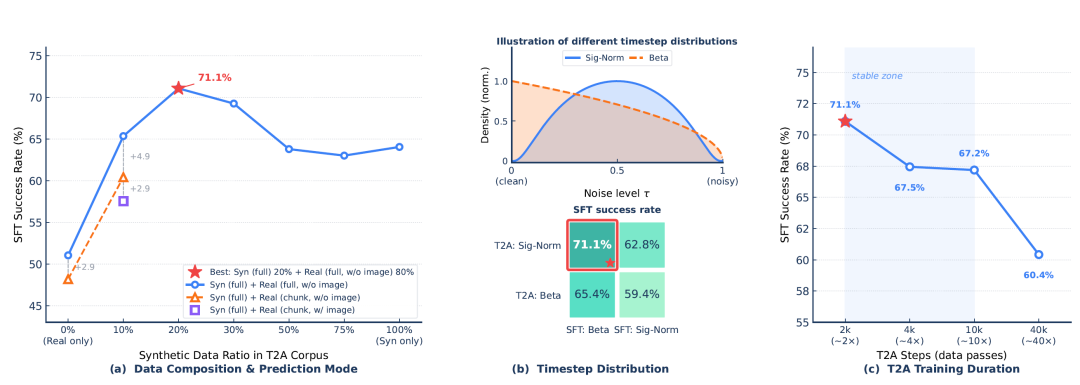
图 6:T2A 预训练消融实验。(a)数据构成与预测模式;(b)流匹配时间步分布;(c)T2A 训练时长。约 20% 合成 + 80% 真实、全序列预测、T2A 采用 Sigmoid-Normal 且训练 2,000 步为最优配置。
**视觉-语言数据共训练:**在操作学习中混入 VL 数据对简单基准(LIBERO、Simpler-WidowX)无干扰,但对需要细粒度物体识别与组合指令解析的基准带来显著提升:RoboCasa-GR1 +4.9pp(51.1%→56.0%),RoboTwin-2.0 +4.6pp(81.8%→86.4%)。
**异质动作空间投影:**对比 Multi-MLP、Concatenation 与 Zero-Padding 三种投影设计,三者在任务成功率上差异微小(<1.2%),但 Zero-Padding 参数量最少,被采纳为默认方案。
**后训练累积效应:**CPT → +SFT → +RL 的逐阶段提升在 SimplerEnv 上分别为 64.3% → 70.8% → 73.7%。RL 增益不仅限于训练环境,在 RoboCasa、RoboTwin-Hard、LIBERO 与 DOMINO 上均保持或略有提升,表明任务成功优化可泛化。
**状态条件:**显式加入本体感知状态(关节角)仅带来至多 +0.7pp(Easy)与 +1.3pp(Hard)的边际增益。多视角视觉观测已提供足够的机器人配置信息,且流匹配解码器预测相对位移而非绝对位姿,降低了对显式状态参考的需求。
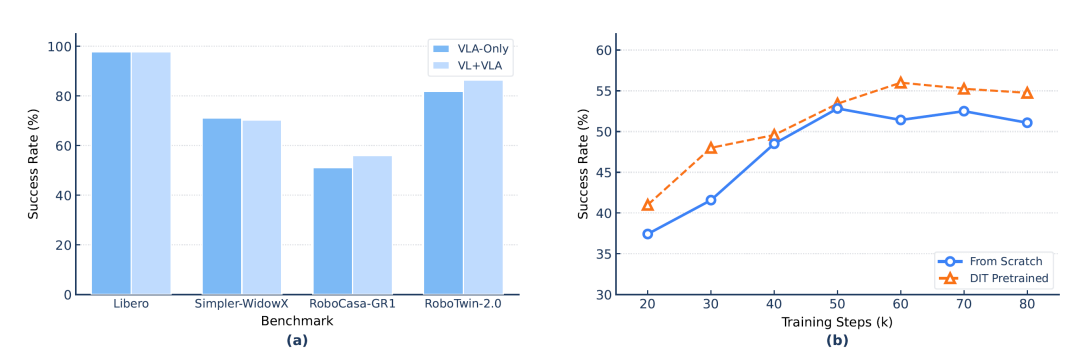
图 7:视觉-语言联合训练消融。(a)VL 数据对操作学习的影响:在 RoboCasa-GR1 与 RoboTwin-2.0 上共训练带来显著提升;(b)预训练 DiT 的迁移性:预训练解码器收敛更快且峰值更高。
六、结论与未来方向
Qwen-VLA 通过将操作、导航与第一人称动作建模纳入共享的动作-轨迹预测空间,展示了视觉-语言-动作模型作为统一具身基础模型的可行性。基于 Qwen3.5 认知主干与 DiT 流匹配运动专家的架构,结合本体感知提示条件、大规模异质数据联合预训练与四阶段渐进训练配方,该模型在跨本体、跨任务与分布外泛化方面展现出强劲性能。
实验结果表明,语言 grounding 的 VLA 模型为多模态感知、指令理解、本体约束与可执行动作的对齐提供了一条实用路径。与侧重视觉预测的世界模型相比,Qwen-VLA 强调将多模态理解 grounding 为可被具身智能体执行的动作,从而架起了高层语言推理与低层物理控制之间的桥梁。
展望未来,团队指出若干值得探索的方向:通过自主采集、仿真与 sim-to-real 迁移进一步扩展真实世界交互数据;充分利用大规模人类视频(第一人称与第三人称)获取超越机器人演示的物理先验与时序抽象;引入长程规划、情景记忆与世界建模能力,使智能体能够追踪状态、分解任务、从失败中恢复并预判动作后果;融合力觉、触觉与本体感知等更丰富的物理反馈,结合大规模仿真与真实世界强化学习,进一步弥合语言 grounding 的具身理解与可靠物理控制之间的差距。
参考文献
- Qwen Team. Qwen-VLA: Unifying Vision-Language-Action Modeling across Tasks, Environments, and Robot Embodiments. arXiv:2605.30280v1, 2026.
具身智能&世界模型blog: https://jinxindeep.github.io/blog/blog2026.html

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)