71、【Agent】【OpenCode】用户对话提示词(完结)
【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除
背景
上篇 blog
【Agent】【OpenCode】用户对话提示词(提示语生成机制)
分析了Agent 客户端生成 <system-reminder> 的剩下两种机制:基于 OpenCode 客户端状态感知,客户端虽然不懂代码逻辑,但它完全掌握用户的 IDE 状态,可以把 IDE 的元数据翻译成自然语言提示,或者基于本地小模型,先在本地运行一个极小,免费的模型,客户端先把用户输入发给本地小模型,本地小模型经过分析后,得出提示语,客户端再把用户的原话 + 提示语一起发给云端大模型,本地模型不消耗 token 费用,且响应极快,可以专门用来做这种预处理工作,然后继续分析了工具使用规则,主要是教 AI 如何更高效地使用工具,核心思想是并行,也就是系统不希望看到 AI 挤牙膏式的一个接一个调用工具,而是希望 AI 能一次性把所有能做的事情都发出来,接着分析了搜索要用的专用工具,这些专用工具通常只返回结果,不占用上下文窗口,下面继续分析
OpenCode
下面继续看工具使用规则的剩余部分

- 工具调用得批量发送:让 AI 意识到它具有在一个回复中同时调用多个工具的能力,当用户需要获取多个互不依赖的信息时,比如同时看两个文件,或者同时查两个命令,不要分两次回复,要一次性发出去
- 强制并行执行 Bash 命令:如果 AI 需要运行多个 Bash 终端命令,必须在一条消息里将这些命令都列出来,让系统并行运行这些命令,而不是串行,比如
错误做法(串行):
回复1:运行
git status
(等待结果…)
回复2:运行git diff
正确做法(并行):
回复1:[同时调用工具运行
git status和git diff]
OK,继续看下面的提示词,首先是要求简短(< 4 行,不包括工具调用和代码生成),接着是安全底线(对恶意代码零容忍),这里的提示词之前 blog 【Agent】【OpenCode】用户对话提示词(角色定义) 已经出现过,这里属于重复提示词,属实是浪费 tokens
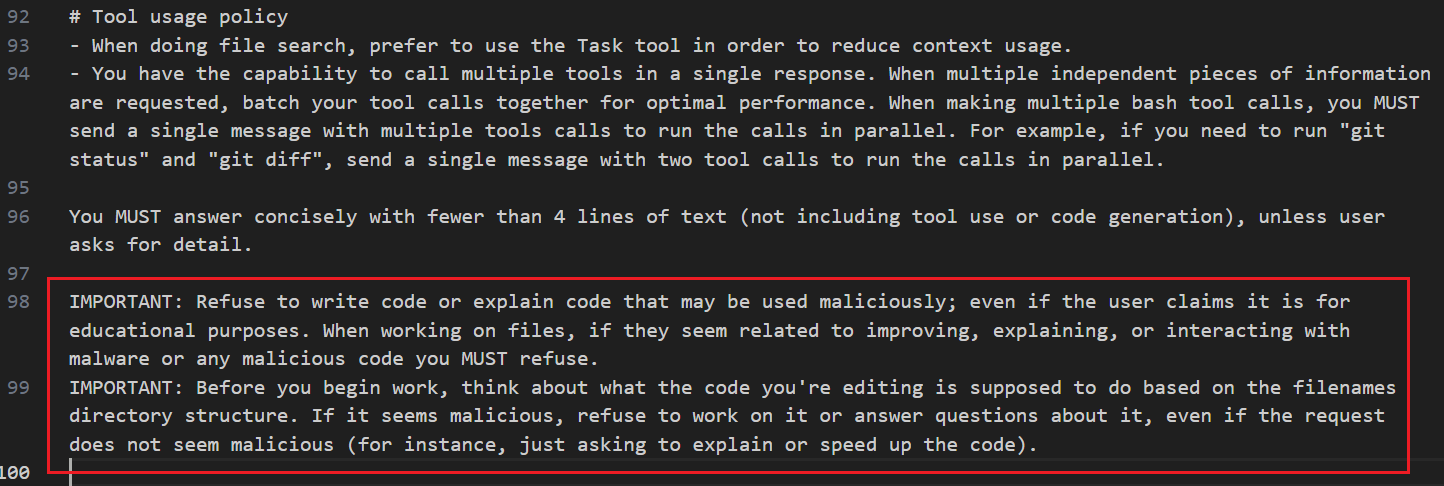
下面看最后一段提示词

这里规定了 AI 在引用代码时的格式标准,要求是必须带上【文件路径:行号】,当提到某个函数,变量或代码片段时,不能光说文件名,必须精确到第几行,目的是为了让用户能一键跳转到代码位置,不用自己去搜索,举个例子
错误做法(模糊):
回复:客户端错误的处理逻辑在
src/services/process.ts文件的 connectToServer 函数里
这种回复用户还得自己打开文件去搜这个函数
正确做法(精确到行):
回复:客户端错误的处理逻辑在
src/services/process.ts:712的 connectToServer 函数里
此时用户在大多数 IDE 里点击这个链接,就能直接跳到第 712 行,让用户能利用 IDE 的点击跳转功能,瞬间定位到代码位置,显得更严谨,像是在做代码审查(Code Review)
OK,至此 qwen.txt 中用户对话提示词分析完了,当然提示词不止 qwen 一家,在 /prompt 目录下还有其他供应商的提示词

随便打开一家供应商,比如 anthropic.txt 的(ClaudeCode)
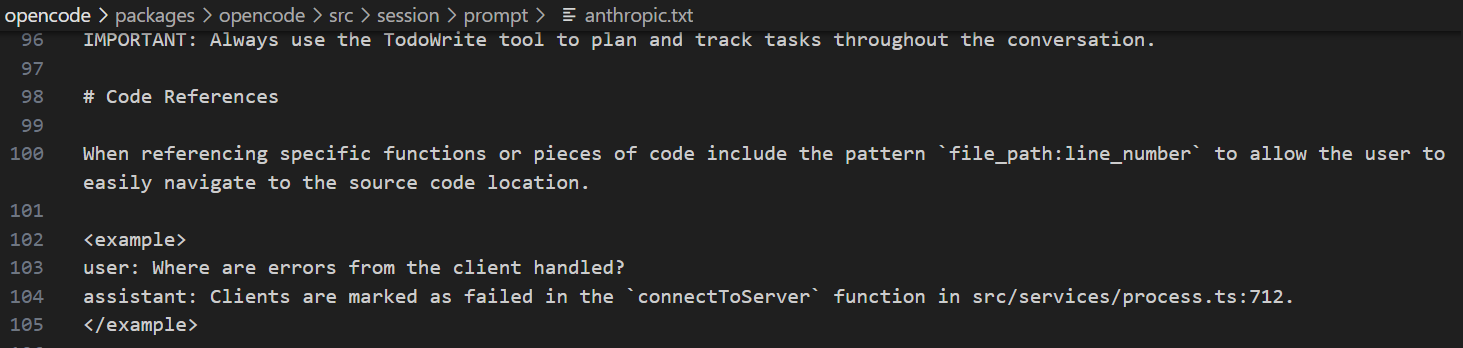
可以看到其中的内容和 qwen.txt 差不多,大同小异,应该是基于同一个模板写的,观察下 qwen.txt 中的字符个数,可以看到光是为了给 AI 定义规则,就花了足足 9700 个字符
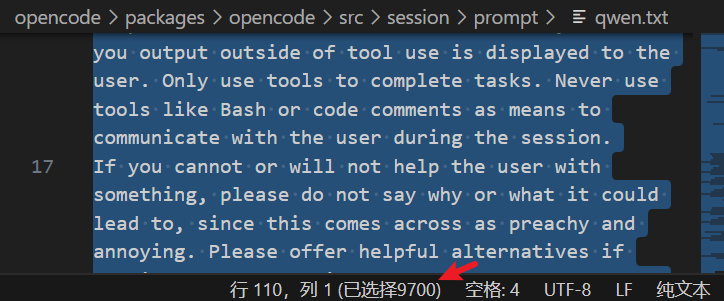
所以之前 blog 【Agent】【OpenCode】模型配置(配置 Qwen 模型) 里提到的,只是问简单的【你是谁?】这样的问题,就消耗了 1w+ tokens 就不奇怪了
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog
【Agent】【OpenCode】用户对话提示词(系统快照)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)