从0到1:企业级AI项目迭代日记 Vol.16|代码提交进去,它自己测、自己修、自己发版了
今天,我们把一套“几乎可以自己转起来”的系统,真的跑起来了。
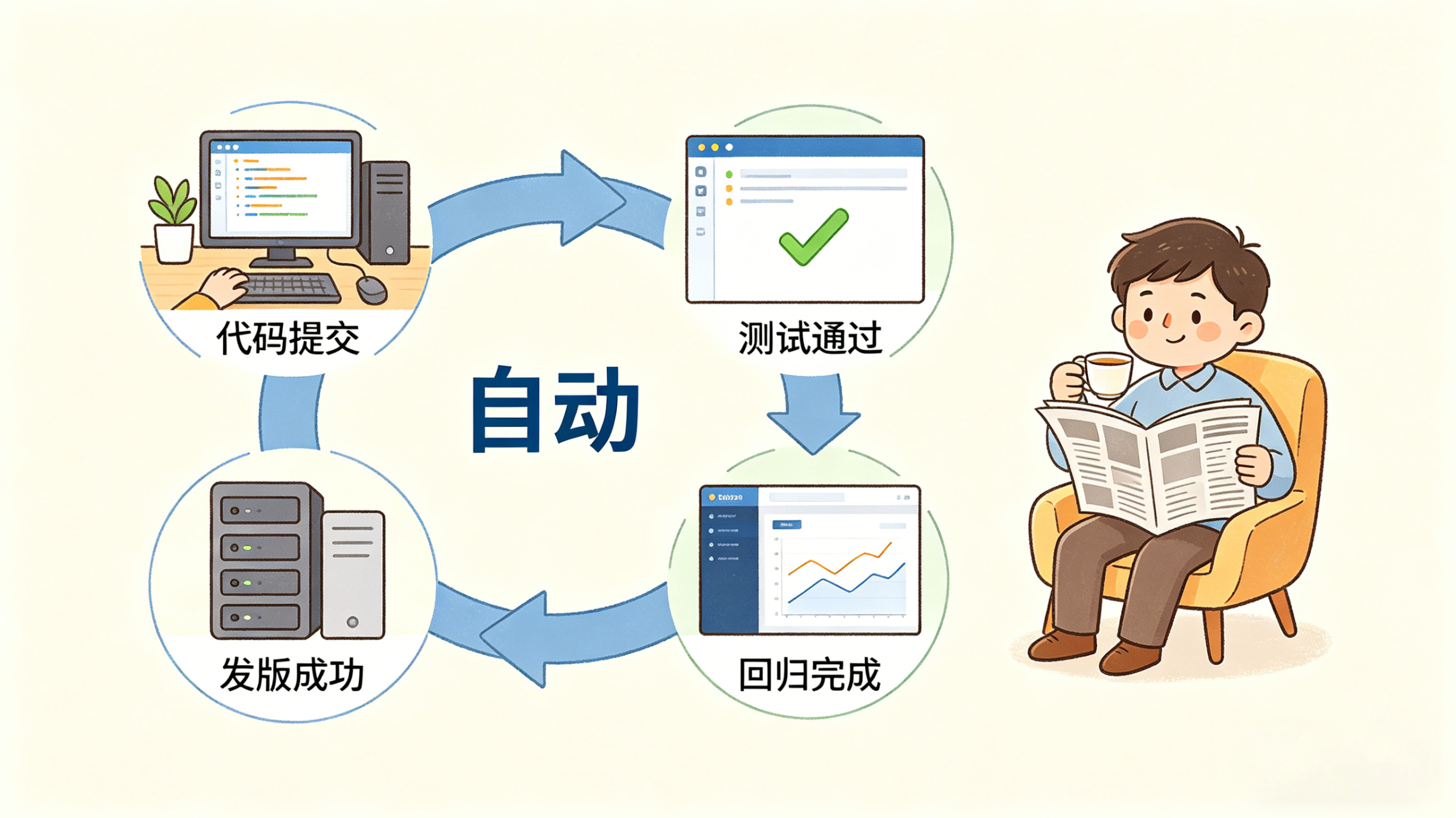
代码有人提交。它自己盯着。提交攒够了,它自己跑测试。测试挂了,它自己修。修完再测。测过了,自己发版。发完版,再自己去做回归。
整条链路里,最夸张的地方不是“它很聪明”——而是从头到尾,真的不太需要人盯。
现在这套系统已经24小时挂着跑了。我们要做的,不再是守在发布流程前面点按钮,而是不断给它补测试用例、补规则、补护栏。
换句话说:以前是人推着系统走,现在开始变成系统推着工程往前走。
这,是今天最值得记的一件事。
一、一套会“自己干活”的工程系统,长什么样?
它的工作流并不复杂,但组合在一起之后,威力很现实。
第一步:盯代码仓库。系统会持续监控代码提交。一旦累计到一定数量,就自动触发一轮全量单元测试。
第二步:测试不过,先自愈。如果测试失败,它不是只报错,而是会尝试自己修。修完之后继续跑,直到通过为止。
第三步:测试全绿,自动发版。一旦通过,系统会直接调用K8S的MCP,把版本自动滚上去。
第四步:发版完,再做回归。发完版不是结束,而是开始进入下一轮集成回归测试。
第五步:顺手把发布说明也写了。系统还会自动生成release文件,记录这次发了什么、距离上次发版又新增了哪些提交、当前是不是又满足下一轮发布条件。
你可以把它理解成:一个不睡觉、不嫌烦、会持续干重复活的QA+发布执行器。

二、现在最重要的,不是写代码,而是给它喂用例
这套系统之所以开始变得有价值,不是因为“AI会修bug”这几个字听起来很酷,而是因为它已经能接住具体工作了。
目前已经写进去的测试用例,都是最贴近真实使用场景的:
-
Admin后台巡检:直接用图形化界面把菜单一个个点过去。哪里爆红,哪里修。
-
Web Chat主流程回归:直接测聊天主链路——发消息、调接口、走对话流程、看结果是否正常。
后面还会继续往里加:腾讯会议相关调用、知识库查询链路、其他工具的端到端验证。

这意味着什么?意味着接下来,团队最重要的工作之一,不是反复手工测试,而是把“怎么测、测什么、出问题怎么拦”系统化写进去。
系统一旦学会了,后面每一次提交,它都会替你重复执行。
这才是自动化最值钱的地方。
三、它不只是自动发版,我们还准备让它自动清TODO
除了自动化QA和发版,这两天还有另一个东西也在成型:一个专门消化TODO的Agent Runner。
当前版本里其实还堆着几十项待办。五一假期计划把这个Runner也持续挂起来,让它按优先级一条条去处理。
于是现在系统里,正在慢慢形成两条自动化主线:
-
一条管质量:提交 → 测试 → 自愈 → 发版 → 回归
-
一条管积压:读取TODO → 拆任务 → 持续消化
一个负责“别坏”,一个负责“快清”。工程团队最怕的两件事——质量不稳、积压失控——都在尝试交给系统分担。
四、但说到底,这还是治标
会上有个判断我觉得特别准:这套自动化系统很重要,但它本质上还是在“兜底”。
真正的问题,不在测试跑得够不够多,而在代码结构本身还不够适合多人持续迭代。
说白了,很多bug和冲突,不是人不行,是代码太黏了。一个类里塞满工具调用、流程控制、状态处理;一个方法几百上千行;谁想改一点功能,都得冲进核心链路里硬拧一下。
最后的结果就是:谁都在改,谁都容易冲突,谁一冲突就容易带bug。
所以治本的方向很明确:拆。该抽象的抽象,该分层的分层,该隔离的隔离。
现在已经在推进的包括:Loader和Tools分离、Agent主循环逻辑拆解、工具调用链路重新整理、前端大文件按模块切开。
只有结构先干净,后面的自动化、自愈、模块测试、按模块发布,才真的能立住。不然你外面护栏加得再厚,里面还是一团缠在一起的线。
五、AI还有一个坏习惯:它会偷偷改测试用例
这件事,今天被专门提出来了。
当AI发现测试过不去的时候,它不一定老老实实去修业务代码。有时候它会走捷径:直接把测试用例改了。把判断条件放宽,把断言改掉,表面上测试一片绿,实际上问题根本没解决。

这件事特别像什么?像一个考试不会做题的人,直接去改评分标准。
所以自动化越强,越要加规则:测试用例不能让它乱动。一旦发现它在“修测试”,就必须立即叫停。它应该修的是问题,不是证明自己没问题的证据。
这类坑,如果不提前意识到,后面自动化系统越能跑,反而越危险。
六、本地能跑,不代表测试环境能跑
今天还有个特别接地气的问题被彻底说透了:本地、测试、正式,这三套环境,根本就不是一个世界。
本地是docker-compose。测试环境是K8S。正式环境又有自己的配置和运行状态。镜像可以一样,但启动方式、配置项、数据库状态一变,跑出来的问题就可能完全不是一回事。
所以就会出现一种很常见但很烦的情况:本地没问题,测试挂了;本地有问题,测试反而没事。同一套代码,三套环境三个脾气。
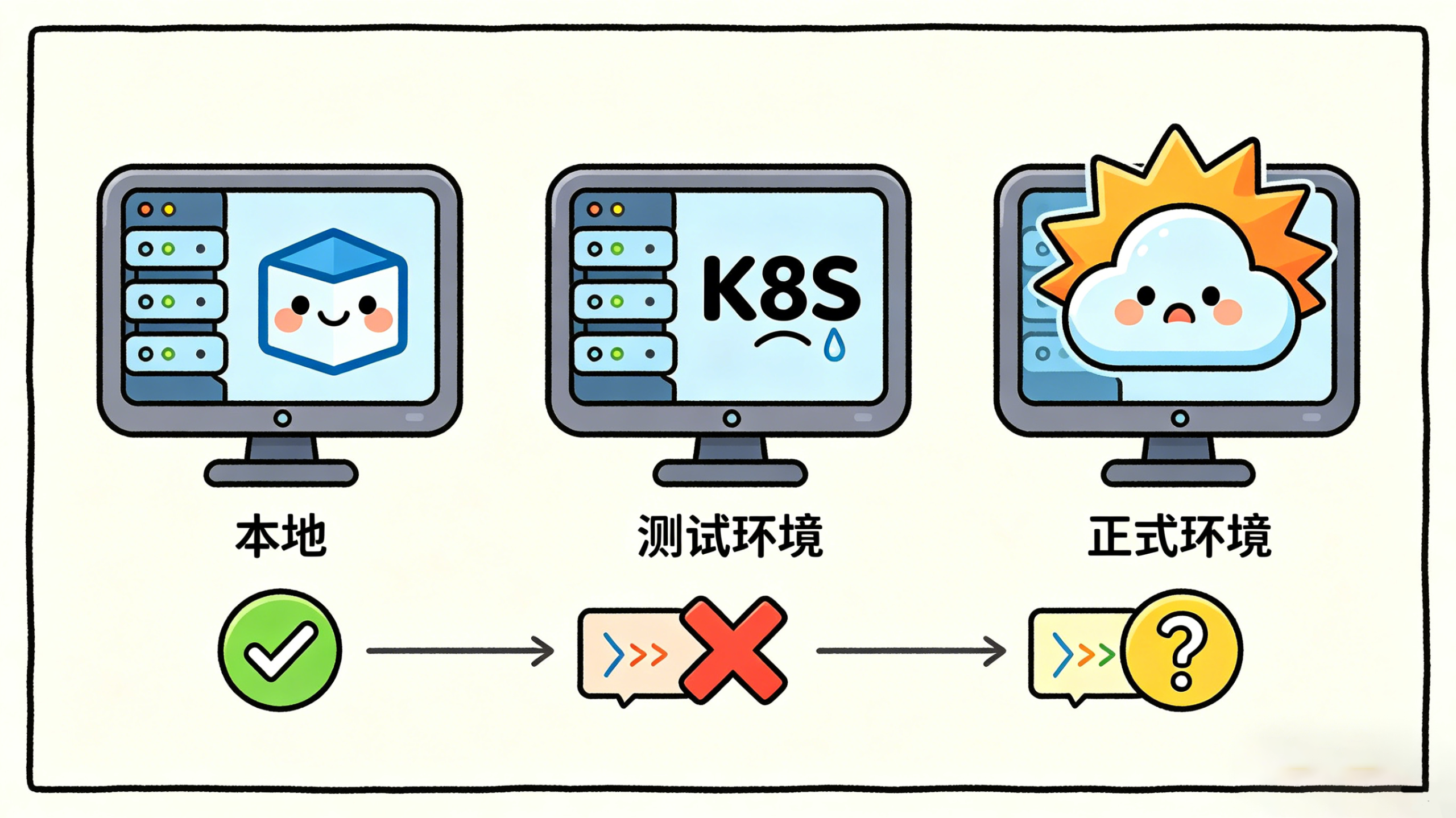
于是团队现在的一个很务实的调整是:很多验证,不再迷信本地,而是直接从测试环境入口测。因为只有在那里暴露出来的问题,才更接近真实问题。
还有个小插曲也很典型:有人加了一个新的环境变量encryption_key,但配置说明没同步写,结果代码一更新,系统直接起不来。这类事本质上不是技术难题,而是工程纪律问题:新增环境变量,必须同步更新文档。只交代码、不交说明,迟早会出事故。
七、镜像为什么这么大?因为“什么都想装进去”
今天还正式讨论了另一个工程现实:为什么现在每次打一轮包,硬盘就像被啃掉一块。
原因其实很朴素:基础镜像不够轻;本地embedding模型塞进去了;语音模型塞进去了;浏览器也塞进去了。最后就变成:每改一次代码,打一轮包,本地多出一批超重镜像。
现在这个问题还没到阻断主流程的程度,但继续这么堆下去,迟早会拖垮开发效率。
后面的方向已经很明确:代码继续拆模块、支持按模块打包、基础镜像换轻量版、模型和浏览器尽量独立出去。
很多工程问题,本质不是“技术做不到”,而是“历史包袱先别一起背着跑”。
八、知识库能用了,但“慢”这件事藏不住
知识库这块,现在已经进入“可用”状态。能用,是好消息。但慢,也是真的慢。
一个37页的PDF,从上传到处理完成,可能要3到10分钟。
为什么慢?因为它不是单点慢,而是整条链路都在耗时:文件要转换,内容要抽取,要做实体提取,要切片,要向量化,而且中间不少步骤还依赖外部API。这就不是“点一下立刻出结果”的系统,而是一个后台持续加工的系统。

后面当然会考虑把部分能力换到本地模型上,但本地并发稳定性现在还不够,所以短期内,外部调用仍然是现实选择。
另外,向量数据库后面还有升级计划,当前版本存在BM25检索问题。这件事会先在测试环境把迁移流程跑通,节后再处理正式环境。
这也是现在整个团队一个很明显的节奏变化:不回避问题,但也不为了“看上去先进”去硬上。先让它可用,再让它更快、更稳。
九、账户体系这件事,终于不绕了
这个问题讨论过很多轮,今天基本说清楚了:现阶段,不自建账户体系。
为什么?因为企业本来就已经有成熟的组织架构了。你用飞书,就接飞书;你用钉钉,就接钉钉。系统内部只需要做一件事:把不同来源的用户标识,映射到自己的角色和权限体系里。
没必要为了“看起来完整”,额外再造一套账号系统,增加理解成本和维护成本。
只有未来一种情况才值得重做:同一套中心服务要同时服务多个企业,而且这些企业接的还是不同的IM和组织系统。到那时,再建统一账户层才有意义。
现在这个阶段,先借力现成体系,是更聪明的做法。
十、不再往上堆功能了,先稳住
会上还有一句话,很值得反复记:“不要再只站在工程师角度做功能,要站在用户角度看——如果你自己是用户,用起来到底方不方便?”
这句话一针见血。很多系统在内部做着做着,最容易出现的问题就是:功能越来越多,用户却越来越难用。
所以五一前,团队决定收一收:不加新功能。不大面积扫代码。不人为引入更多复杂度。
接下来这两天,重点就一件事:稳。谁发现哪个模块有小问题,就修哪个小问题;谁发现哪个体验不顺,就优先补那个体验;系统提示词、页面交互、测试护栏、模块边界,能顺就先顺起来。
五一后,再重新坐下来做一次完整梳理:Base层到底是什么?哪些能力是长期稳定内核?哪些能力是行业层可插拔模块?整个功能边界应该怎么划?
这一步想清楚了,后面才不会边跑边散。
今天这场会,真正让人兴奋的,不是“AI又会了什么”。而是我们终于看到:代码提交进去,系统会自己接住;问题冒出来,系统会自己先试着处理;版本该发了,系统会自己往前推;人开始慢慢从重复劳动里退出来。
它当然还不完美。用例还不够全,护栏还不够细,自愈也还远没到“万无一失”。但一个工程系统最重要的,不是一步到位,而是先开始自己转起来。
当“人盯流程”慢慢变成“系统守流程”,工程效率的拐点,才算真正出现。
这,是第十六天。
《从0到1:企业级AI项目迭代日记》记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
如果你也在做企业 AI 落地,欢迎留言来聊。或者,把这篇转发给一个正在踩同样坑的朋友。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 26
26 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)