第四十四周周报
摘要
本周主要学习了 ResNet 残差网络的基本思想与结构。通过对比普通网络和残差网络,理解了残差映射相比直接拟合理想映射更易优化的原因,并掌握了残差块中恒等映射、跨层连接和 1×1 卷积的作用。同时学习了 ResNet 的整体架构,包括不同 stage 的组成方式,以及 ResNet-18、ResNet-152 等不同深度模型的构建思路。
Abstract
This week, I mainly learned the basic idea and structure of RESNET residual network. By comparing the ordinary network and the residual network, the reason why the residual mapping is easier to optimize than the direct fitting ideal mapping is understood, and the functions of identity mapping, cross layer connection and 1 × 1 convolution in the residual block are mastered. At the same time, I learned the overall architecture of RESNET, including the composition of different stages, and the construction ideas of different depth models such as resnet-18 and resnet-152.
本周继续深入学习ResNet残差网络
函数类
首先我们抛出一个问题,随着神经网络的不断加深,网络越复杂就一定越好吗?
不一定。
如下图,蓝色五角星表示最优值,而标有 Fi 的闭合区域对应一个函数,这个区域的面积可以用来体现函数的复杂程度。在每个区域内部,都可以找到一个最优模型(可视为区域中的某个点),该点与最优值之间的距离能够衡量模型的好坏。
从图中可以看出,随着函数复杂度不断增加,虽然对应区域的面积在扩大,但在这些区域内所能找到的最优模型与最优值之间的距离反而可能逐渐变大,也就是说模型所在的区域会随着复杂度的提升逐渐偏离原有区域,与最优值的差距越来越远,这种情况属于非嵌套函数(non-nested function)。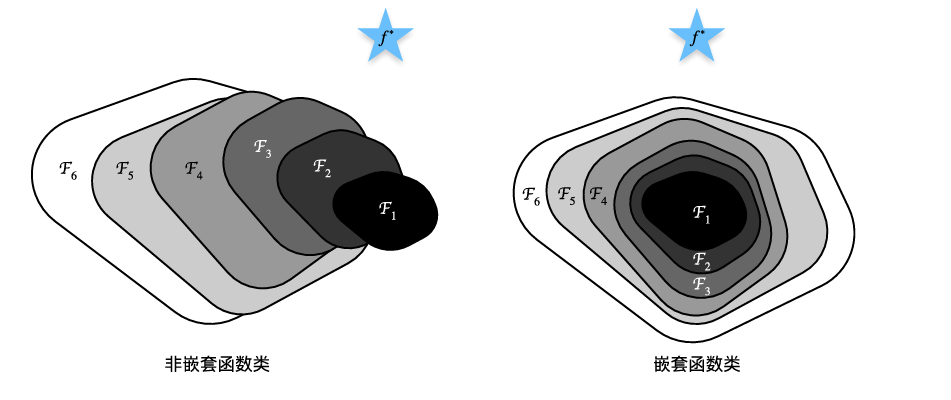
解决上述问题(模型走偏)的方法:每一次增加函数复杂度之后函数所覆盖的区域会包含原来函数所在的区域(嵌套函数(nested function)),只有当较复杂的函数类包含复杂度较小的函数类时,才能确保提高它的性能。
随着函数复杂度的提升,函数所能覆盖的区域只是在原有基础上不断扩展,而不会偏离原先的区域。对于深度神经网络而言,如果新增的层可以被训练为恒等映射(identity function)f(x)=x,那么新模型与原模型在效果上是等价的;由于更深的模型具备拟合更优解的潜力,因此增加层数通常也更有利于降低训练误差。
残差块
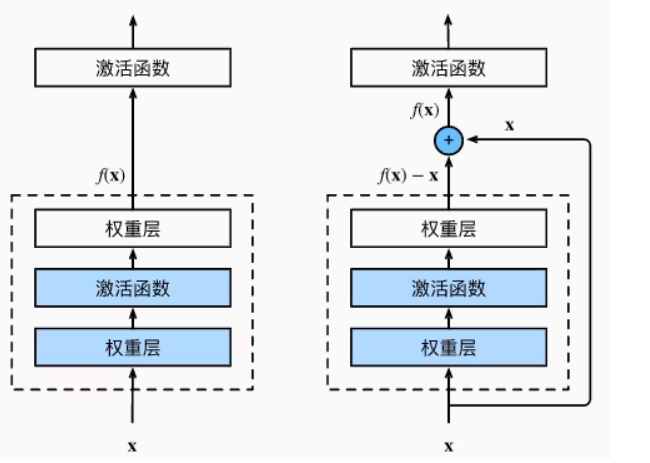
此前增加模型深度的方法通常采用层层堆叠的方式,而 ResNet 的核心思想是在增加网络层数的同时,尽量不增加模型优化的难度。图中左侧表示普通块,右侧表示残差块,其中 x 表示原始输入,f(x) 表示理想映射,也可以理解为激活函数的输入。对于普通块而言,虚线框中的部分需要直接拟合出理想映射 f(x);而对于残差块来说,虚线框中的部分只需要拟合残差映射 。
正是由于残差块不需要直接学习完整的理想映射,而是学习输入与理想输出之间的差值,所以残差映射在实际中往往更容易优化。尤其是当理想映射 f(x) 非常接近恒等映射时,残差结构只需要捕捉恒等映射附近的细微变化即可;如果希望学习到的理想映射就是恒等映射 f(x)=x,那么只需将残差块中虚线框内加权运算的权重和偏置参数设置为 0,最终输出就可以变为恒等映射。同时,在残差块中,输入还可以通过跨层数据线路更快地向前传播。
残差块里首先有2个有相同输出通道数的3×3卷积层。每个卷积层后接一个批量规范化层和ReLU激活函数。然后我们通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。这样的设计要求2个卷积层的输出与输入形状一样,从而使它们可以相加。如果想改变通道数,就需要引入一个额外的1×1卷积层来将输入变换成需要的形状后再做相加运算。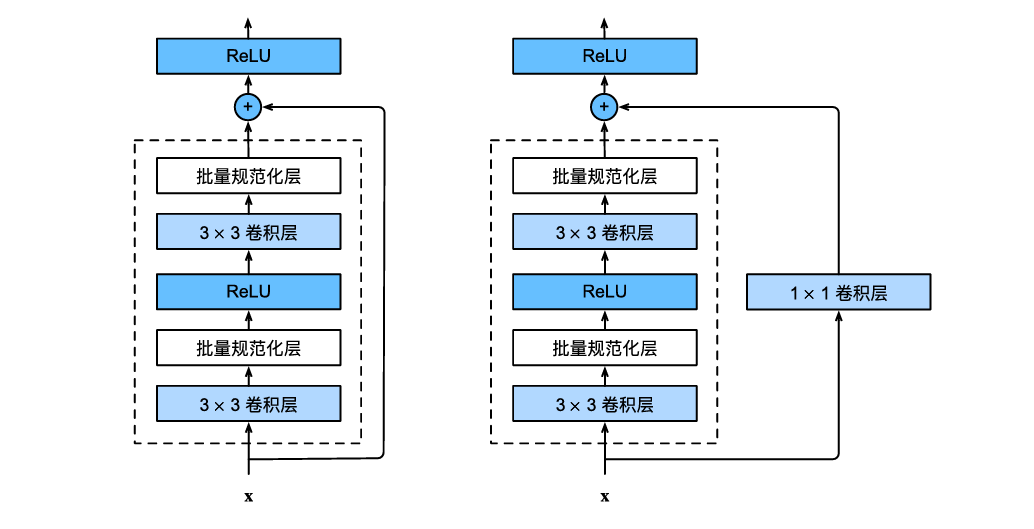
实现代码
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module): #@save
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
- 左图展示的是 ResNet 的第一种实现形式,即不包含 1*1 卷积层的残差块,它会直接将输入加到叠加层的输出上。
- 右图展示的是 ResNet 的第二种实现形式,即包含 1*1 卷积层的残差块,它会先通过 1 *1 卷积对输入进行通道变换,再将变换后的结果加到叠加层的输出上。
- ResNet 沿用了 VGG 中完整的 3*3卷积层设计。
- 在残差块中,通常先包含两个输出通道数相同的 3*3 卷积层,每个卷积层后都会接批量归一化层和 ReLU 激活函数。与此同时,输入会通过跨层数据通路绕过这两个卷积运算,并在最后一个 ReLU 激活函数之前与卷积层的输出相加。因此,这种结构要求两个卷积层的输出形状与原始输入形状保持一致,这样第二个卷积层的输出,也就是第二个激活函数的输入,才能与原始输入进行相加。
- 如果需要改变通道数,就需要额外引入一个 11 卷积层,将输入变换为所需形状后,再进行相加运算,也就是右图所示的包含 11 卷积层的残差块。
ResNet架构
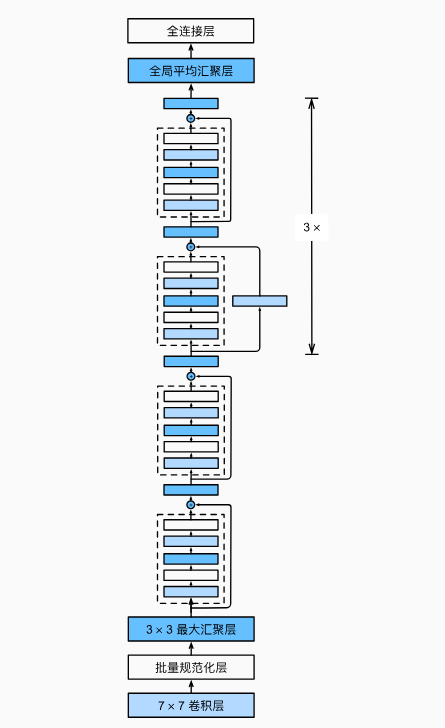
ResNet 的整体结构与 VGG 和 GoogLeNet 类似,但将基本模块换成了残差块,并在每个卷积层后加入批量归一化层。网络前面先经过 7×7 卷积层和 3×3 最大汇聚层,之后分为 4 个由残差块组成的模块:第一个模块保持通道数和特征图大小不变,后续模块则在第一个残差块中将通道数翻倍,并将高和宽减半。通过改变通道数和残差块数量,可以得到不同规模的 ResNet,如 ResNet-18 和更深的 ResNet-152。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)