就在这周, Codex 版的 Ralph loop 上线: AI 终于学会 “自己往下跑” 了
就在这周,Codex /goal 上线:AI 编程终于学会“自己往下跑”了
大家好,今天聊一个我这两天反复看 release notes 和源码的新功能:OpenAI Codex CLI 0.128.0 里的 /goal。
Codex CLI 是 OpenAI 的命令行编码代理。我想大部分本频道的读者对其都十分了解。Codex 在 2026 年 4 月 30 日上线了一个 /goal 的命令。乍一看只是多了个斜杠命令,实际意义却比一个普通的智能体命令要大得多。
以前用 AI 写代码,你给它一个 prompt,它处理一轮,然后停下。你再输入“继续”, “跑测试”, “修一下失败用例”, “确认没有改坏别的地方”。一轮一轮推。
/goal 想改掉的,就是这件事。
你给 Codex 一个目标,它会把目标保存下来,在合适的时候继续推进。社区里有人把这叫 OpenAI 内建版 Ralph loop。

Ralph loop 可以先理解成一种 AI 编程循环:给 AI 一个目标,让它执行、跑测试、看结果、继续修,再检查。只要目标没完成,就进入下一轮,直到任务完成、遇到阻塞,或者 token 预算耗尽。
这里的 Ralph,来自 Ralph Wiggum,是《辛普森一家》里的一个小男孩角色。开发者圈拿 Ralph Wiggum 来命名这个机制,有点自嘲意味:Ralph 天真、笨拙、经常搞不清状况,但他会很认真地说“我在帮忙”。早期 AI coding agent 也很像这样,愿意干活、能给你惊喜,但会忘上下文、重复犯错、过早宣布完成。
所以这个名字其实是在提醒我们:别假设 agent 天生可靠。要给它一个简单循环、外部状态、明确任务清单和验收标准,让它一轮轮试、一轮轮改,直到证据足够。

本篇文章, 我将按下面几点展开讨论:
一、/goal 到底有多香?
用 AI 写代码,第一轮往往不是最烦的。
你丢一个报错,它大概率能定位。你让它补测试,它能很快写出几个 case。你说要重构,它也能先拆出一版结构。
麻烦通常出在第二轮、第三轮。
测试跑了吗?失败用例修了吗?修 A 的时候有没有把 B 搞坏?它说“完成了”,到底是所有要求都过了,还是模型只是想结束这一轮?
以前这些事基本靠人盯。你像一个项目经理一样,隔几分钟回来催一句:
继续。
跑测试。
还有失败。
别总结,先修。
确认一下有没有漏。
这就是 /goal 要处理的地方。
普通 prompt 是一次请求。/goal 更像给当前线程挂了一个任务牌。只要目标还在,Codex 就知道下一轮应该围着什么转。
比如你可以这样写:
/goal 修复 src/auth/session.ts 中刷新 token 失败的问题,
要求 npm test -- auth/session 全部通过,
不得改变 public API,
完成前列出修改文件和验证命令。
这句话里最有价值的部分,是后面的验收条件。AI 未必卡在写代码,常常卡在“看起来已经完成”。/goal 的价值,就是把“继续做”和“怎么才算做完”绑到一起。

二、这不是一个按钮,是一套运行机制
我翻了一遍 0.128.0 对应的 release notes 和源码。/goal 不是简单在终端界面里加了一个菜单。
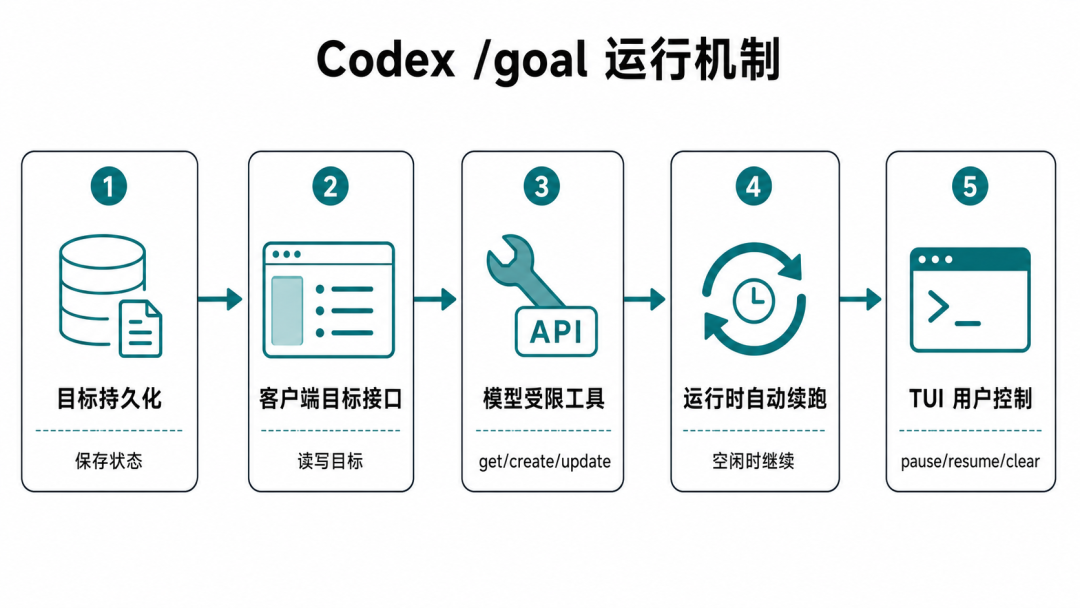
它至少有五层。
第一层,目标会被持久化。
Codex 新增了一个专门保存目标的状态层。它保存的不只是一句目标描述,还包括目标当前处于什么状态、已经用了多少 token、跑了多久。比如一个目标可以是 active、paused、budget-limited、complete。
这一步看起来底层,却决定后面能不能续跑。
没有状态保存,所谓“自主循环”只能靠 prompt 记忆。只要线程恢复、上下文压缩、客户端重连,任务就容易断。
第二层,客户端能直接读写目标。
Codex 在客户端和后台线程状态之间加了目标接口:读取目标、设置目标、清除目标,以及目标更新后的通知。
你恢复一个会话时,客户端不需要靠临时记忆猜当前目标是什么。它可以直接读到目标,也能知道目标状态什么时候变了。
第三层,模型有受限工具。
Codex 给模型开放了三个和目标有关的工具:
-
•
get_goal -
•
create_goal -
•
update_goal
但这个权限不是随便给的。
这三个工具的权限很窄:模型不能从普通任务里自己脑补一个 goal。update_goal 也只能把目标标记成 complete。暂停、恢复、清除、预算耗尽这些状态,仍然由用户或系统运行时控制。
我喜欢这个限制。一个能自动跑的编码代理,如果连自己的目标状态都能随便改,那就太危险了。它必须能做事,但不能给自己无限放权。
第四层,运行时会自动续跑。
Codex 把 goal continuation 放进了核心运行时。当 session 空闲、没有用户输入排队、没有其他待处理工作时,它可以启动下一轮 continuation turn。
它也不是无脑循环。
如果上一轮 continuation 没有任何工具调用,系统会抑制下一次自动续跑,避免模型在那里空转。这个细节很工程化,OpenAI 想做的是“在该继续的时候继续”,而不是让模型无限转圈。
第五层,TUI 有了用户控制。
TUI 是 terminal user interface,也就是终端交互界面。用户可以在这里输入 /goal <objective> 设置目标,也可以用 /goal pause 暂停,用 /goal resume 恢复,用 /goal clear 清掉目标。
这套东西合起来,才是 /goal。
少了状态,它只是 prompt。少了运行时,它不会自己往下走。少了权限边界,它就可能变成失控循环。
三、最狠的不是循环,而是完成审计
很多人看到 /goal,第一反应是:Codex 终于可以一直干活到 token 耗尽了。
这只说对了一半。我更在意 continuation.md 里的 completion audit。
completion audit 可以翻成“完成审计”。说白了,就是模型不能只凭感觉说“我做完了”,它要先把目标拆成具体交付物和成功标准,再逐项找证据。
证据可以是文件、命令输出、测试结果、PR 状态。
这套提示词还写得很直白:
-
• 不要因为“跑过测试”就直接说完成
-
• 不要因为“manifest 看起来完整”就直接说完成
-
• 不要因为“已经做了很多工作”就直接说完成
-
• 不确定,就继续验证
这对 AI 编程很要命。
因为模型太会写总结了。它可能只修了 70%,然后给你一段特别像交付报告的回复:已完成、已验证、建议合并。
结果你一看,关键路径没测,边界条件漏了,甚至 public API 被悄悄改了。
/goal 把这件事写进了续跑提示词:别急着宣布完成,先拿证据对目标。
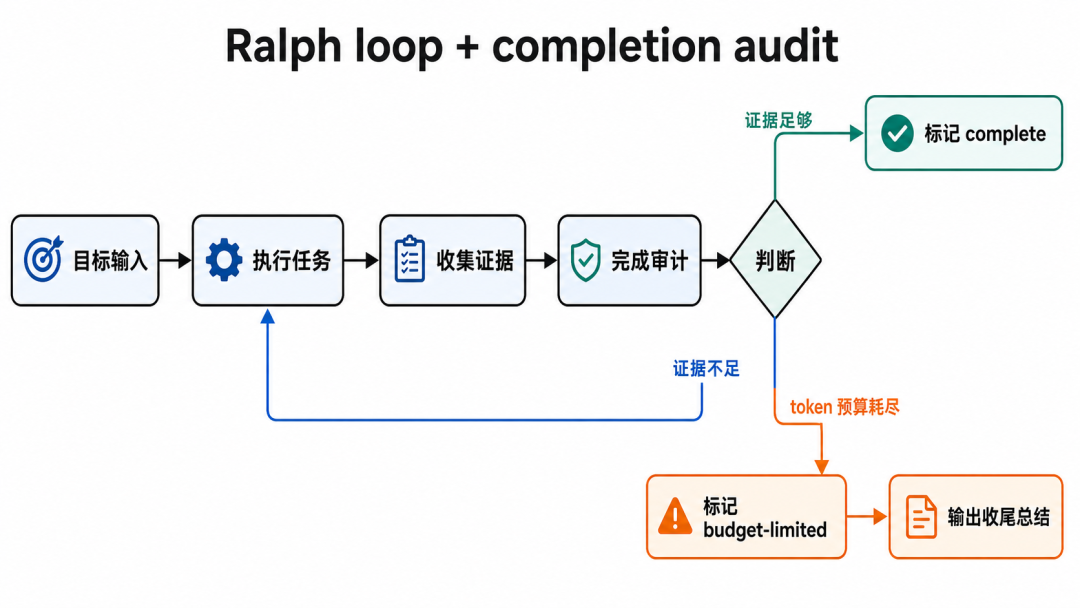
逻辑大概像这样:
while goal.active:
next_action = inspect_current_state(goal)
run(next_action)
evidence = collect_files_tests_commands()
audit_result = audit(goal.requirements, evidence)
if audit_result.all_covered:
update_goal(status="complete")
elif budget.exhausted:
summarize_and_stop()
else:
continue
这里最值钱的是 audit,不是 while。能循环的 agent 很多。能在完成前逼自己拿证据的 agent,才开始像工程工具。
四、token budget 是刹车,不是装饰
长任务一定会烧 token。代码上下文、日志、测试输出、模型回复,全都要占 token 预算。OpenAI 在解释 Codex agent loop 的文章里也提过,随着 turn 和工具输出增加,Codex 的上下文会不断变长。
所以 /goal 需要 token budget。
0.128.0 的处理方式比较温和:预算耗尽后,不是直接把当前任务掐断,而是把 goal 标记成 budget_limited,然后让模型收尾。
也就是告诉你:
-
• 已经做了什么
-
• 还有什么没做
-
• 卡在哪里
-
• 下一步应该怎么继续
这个设计很实用。
没有 token 预算的 agent loop,很容易从“自动工程”变成“自动烧钱”。token 预算不是可有可无的选项,它是长任务的刹车。

五、怎么写一个好 /goal
/goal 强不强,很大程度取决于目标写得好不好。
坏目标长这样:
/goal 优化一下这个项目
这个目标太虚。优化什么?性能?可读性?测试覆盖?构建速度?用户体验?
再看一个:
/goal 自动修完所有问题
这个更危险。范围太大,没有边界,也没有验收方式。
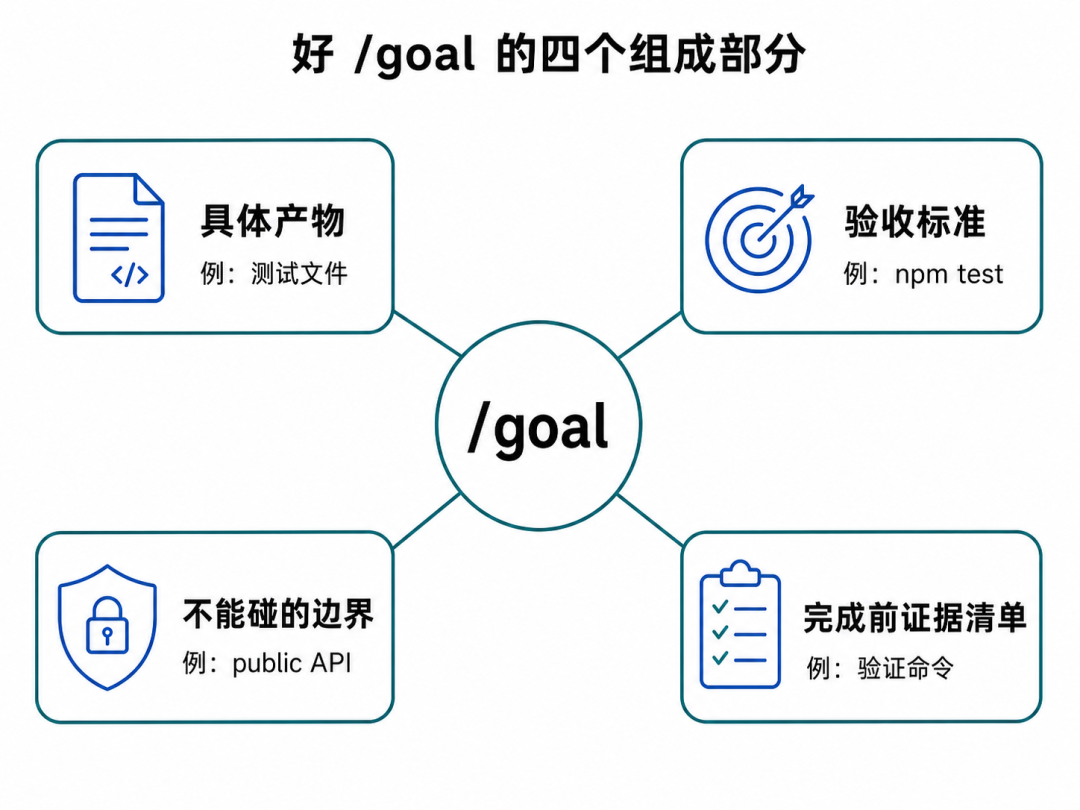
我更建议用这个结构:
/goal 完成 [具体产物],
必须满足 [测试/命令/验收标准],
不得改变 [边界/API/文件],
完成前输出 [证据清单]。
比如:
/goal 为 auth/session 模块补齐边界测试,
覆盖 token 过期、刷新失败、用户撤销三个场景,
要求 npm test -- auth/session 全部通过,
不得修改 public API,
完成前列出新增测试文件和验证命令。
这里面有四个抓手:
-
• 要交付什么
-
• 覆盖哪些场景
-
• 用什么命令验收
-
• 哪些边界不能碰
你会发现,写好 /goal 靠的不是文采,是验收标准。
以后会写 prompt 的人不会少。更稀缺的是会写 Done when 的人。Done when,就是“什么时候算完成”。这句话写不好,agent 就只能猜。
六、别着急把它吹成“无人程序员”
我很喜欢 /goal,但我不建议把它直接吹成“程序员要没了”。
它确实让 Codex 更像一个能持续推进任务的代理:目标能保存,运行时能续跑,用户能暂停恢复,预算耗尽后能收尾,完成前还要做审计。
但工程责任没有消失。
目标是否合理,还是人来定。验收标准是否完整,还是人来定。权限边界是否安全,还是人来定。diff 是否符合产品语义,最后也还是要人 review。
所以我更愿意把 /goal 看成一种角色移动。
以前你在每一轮里推着 AI 走。现在你更像目标设计者和验收者。Codex 则在你给定的目标和边界里循环执行。
这已经是很大的变化,不需要再用“替代程序员”来包装。
七、我的判断
Codex /goal 的意义,不是让 AI 多写几行代码。
它把工程任务里几个麻烦但必要的东西放到了系统层:
-
• 目标
-
• 状态
-
• 预算
-
• 暂停和恢复
-
• 完成审计
这几个词看起来没那么性感,但它们决定一个 AI 编程工具能不能从“聪明助手”走向“可托付一段任务的执行器”。
当然,这还只是开始。/goal 是否默认开启、TUI 里 token budget 怎么暴露、后续版本会不会改交互,都还需要继续实测。
但方向已经很清楚了: AI 编程的下一步,不是只看模型能不能生成更漂亮的代码,而是看工程目标能不能被系统保存、持续推进、拿证据验收。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)