AI的发展越来越厉害,所以很多人也习惯把任务直接丢给AI。但 AI 在处理自动化任务时有时候还会不稳定,有些还要收费。对于需要每天定时运行、处理大量文件或监控系统状态的任务,依靠 AI 每次生成结果容易出现幻觉偏差。
AI很好,但其实有时候杀鸡没必要用牛刀。Python 一样可以完成一些简单的自动化任务。
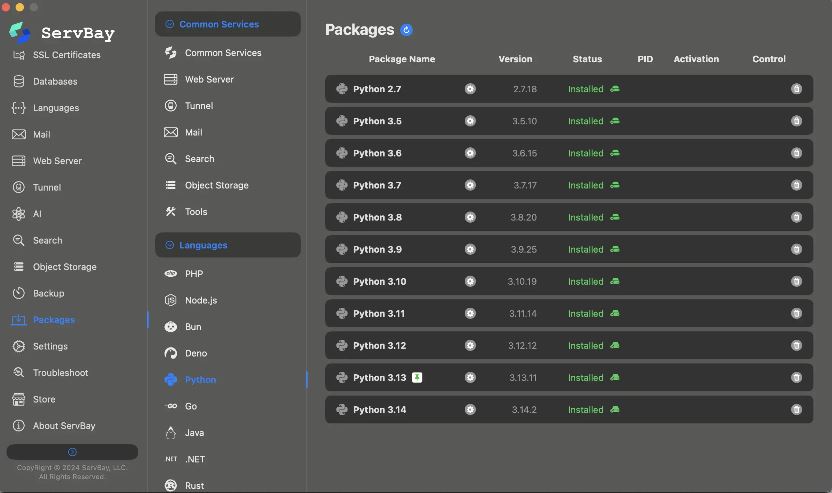
在写 Python 之前,要确保 Python 的环境已经准备好。
推荐使用 ServBay 来管理开发环境,它支持一键安装 Python 环境,覆盖了从半只脚踏进棺材板的 Python 2.7 到Python 3.5 乃至最新的 Python 3.14 版本。而且这些版本可以同时并存,不需要手动去配置环境变量,也不用担心弄乱系统的默认配置。装好就能用,一分钟就能搞定。
有了稳定的环境,下面分享几个在实际工作中常用的自动化脚本模式。
自动重试机制:让网络请求更健壮
写爬虫或调用 API 时,网络波动是常态。与其在每个请求处都写一遍 try-except,不如把重试逻辑封装起来。专业的脚本不会因为一次超时就崩溃。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 |
import time
import requests
from requests.exceptions import RequestException
def fetch_with_retry(url, max_retries=3, pause=2):
"""
带有自动重试机制的GET请求
"""
for attempt in range(max_retries):
try:
# 设置超时是必须的,防止程序无限挂起
response = requests.get(url, timeout=10)
response.raise_for_status() # 如果状态码不是200,抛出异常
return response
except RequestException as e:
print(f"请求失败 (尝试 {attempt + 1}/{max_retries}): {e}")
if attempt == max_retries - 1:
raise # 最后一次尝试也失败,抛出异常
time.sleep(pause)
# 使用示例
try:
data = fetch_with_retry("https://api.github.com")
print(f"请求成功,状态码: {data.status_code}")
except RequestException:
print("重试多次后依然失败,请检查网络或目标服务。")
|
它将网络不稳定的偶发故障在代码层面消化。最大的好处是防止脚本因为一次微小的网络抖动就全盘崩溃,真正实现了“无人值守”运行,特别适合夜间批量任务。
依据文件内容重命名
有时候文件名没有及时修改,就不知道这个文件到底是什么了。
但一个个打开看又非常花时间,我们就可以写个脚本,让它读取内容并重命名。这个逻辑常用于处理发票、日志或自动生成的报告。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28 |
import os
TARGET_DIR = "./reports"
def clean_filename(text):
# 去除文件名中的非法字符
return "".join(c if c.isalnum() else "_" for c in text)[:50]
for filename in os.listdir(TARGET_DIR):
full_path = os.path.join(TARGET_DIR, filename)
# 确保只处理文件
if os.path.isfile(full_path):
try:
with open(full_path, "r", encoding='utf-8') as f:
# 读取第一行作为新文件名
first_line = f.readline().strip()
if first_line:
new_name = clean_filename(first_line) + ".txt"
new_path = os.path.join(TARGET_DIR, new_name)
# 防止覆盖已存在的文件
if not os.path.exists(new_path):
os.rename(full_path, new_path)
print(f"重命名: {filename} -> {new_name}")
except Exception as e:
print(f"无法处理文件 {filename}: {e}")
|
解决了文件名无意义(如 scan_001.txt)的痛点。脚本直接读取文件核心内容来命名,检索文件时效率很高,不再需要逐个打开确认。
清理长期未访问的僵尸文件
磁盘空间总是莫名其妙变少,多半是因为那些下载后就再没打开过的临时文件。这个脚本能清理长期没有访问过的文件,它是依据最后访问时间来运行。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 |
import os
import time
WATCH_DIR = "/path/to/cleanup"
EXPIRY_DAYS = 180 # 6个月未访问则删除
current_time = time.time()
for filename in os.listdir(WATCH_DIR):
filepath = os.path.join(WATCH_DIR, filename)
if os.path.isfile(filepath):
# 获取最后访问时间 (atime)
last_access_time = os.path.getatime(filepath)
# 计算时间差
if current_time - last_access_time > (EXPIRY_DAYS * 86400):
try:
os.remove(filepath)
print(f"已删除陈旧文件: {filename}")
except OSError as e:
print(f"删除失败: {e}")
|
基于“访问时间”而非“创建时间”判断,这非常关键,因为它能精准识别那些真正不再需要的文件。它就像一个隐形的清洁工,防止磁盘空间被无用的临时数据悄悄吃光。
监控并查杀高负载僵尸进程
有些 Python 脚本(尤其是涉及多进程或机器学习任务的)在意外退出后会留下孤儿进程,占用大量 CPU。手动打开活动监视器查找太慢,直接用脚本自检。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 |
import psutil
# 设定阈值:CPU占用超过80%且进程名为python
CPU_THRESHOLD = 80.0
PROCESS_NAME = "python"
for proc in psutil.process_iter(['pid', 'name', 'cpu_percent']):
try:
# psutil获取cpu_percent通常需要interval,这里取瞬时值可能需要两次调用或结合实际场景调整
# 在脚本循环监控中更为有效
if proc.info['name'] and PROCESS_NAME in proc.info['name'].lower():
if proc.info['cpu_percent'] > CPU_THRESHOLD:
print(f"检测到高负载僵尸进程 PID: {proc.info['pid']} (CPU: {proc.info['cpu_percent']}%)")
proc.kill()
print("已终止进程。")
except (psutil.NoSuchProcess, psutil.AccessDenied):
pass
|
复制讲解
这是一种主动防御机制。它解决了长时间运行脚本可能导致的内存泄漏或死循环问题,避免了因单个失控进程拖慢整个系统,省去了你手动打开活动监视器排查的时间。
操作前的后悔药:自动备份
在对配置文件或关键数据进行写入操作前,备份是必须的。但往往都是忘记了备份。那就把自动化备份交给Python吧。


 8
8 0
0


 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)