Token 分词(上篇)| 想要转型 AI Agent 开发,必须要搞懂
本文面向新手。读完这篇文章,你就会真正理解 token 是什么、为什么要分词、BPE 算法的原理,以及中文为什么比英文更"贵"。
从一个线上报错开始讲
假设你在做 RAG 系统,用户提交了一份产品说明书,你把它塞进 prompt,然后:
Error: This model's maximum context length is 8192 tokens.
However, your messages resulted in 9843 tokens.
你数了一下,文档才 4000 多个字符,怎么会超 8192 tokens?
这就是大多数后端开发者第一次真正需要搞懂分词的时刻。字符数不等于 token 数。理解分词,就是理解大模型真正在处理什么。
Token 是什么?
大模型不处理字符串,也不处理单词。它处理的基本单元叫 token,一种介于字符和单词之间的"子词片段"。
看两个真实的分词结果:
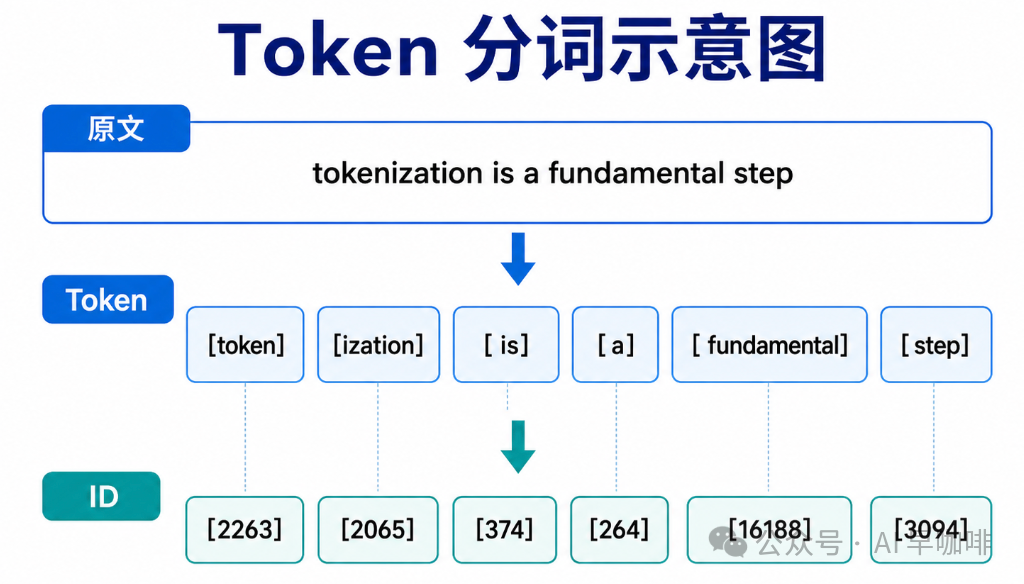
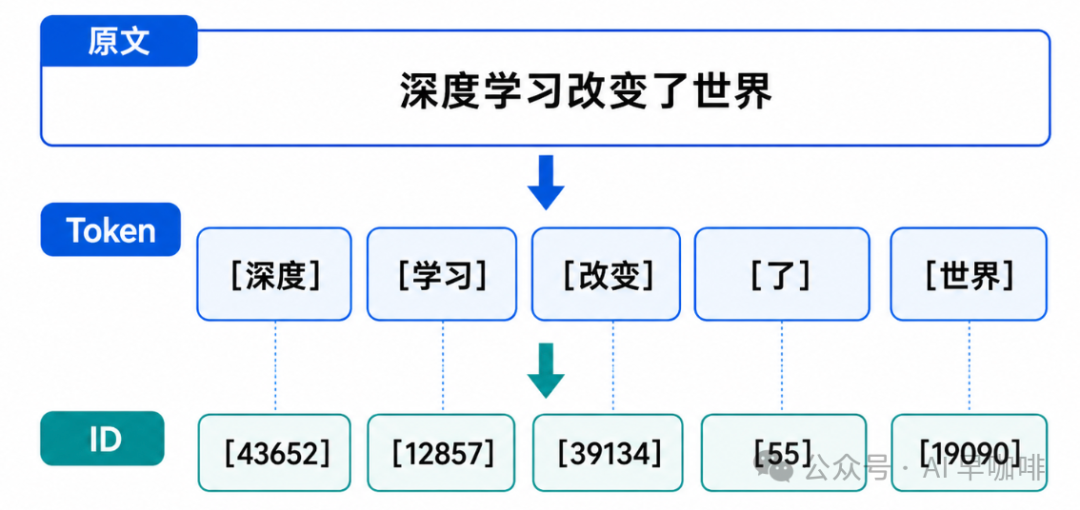
有几个细节我们需要注意:
"tokenization" 被切成了两半。 词表里没有 "tokenization" 这个完整条目,但有 "token" 和 "ization" 这两个片段。这是子词分词的核心思路:常见词保持完整,罕见词拆成更小的已知片段。
每个 token 对应一个整数 ID。 这个 ID 才是真正送进神经网络的东西。模型先把文本变成 ID 序列,再通过 Embedding 层把每个 ID 查表变成一个高维向量(比如 4096 维),后续所有计算都在向量空间里进行。
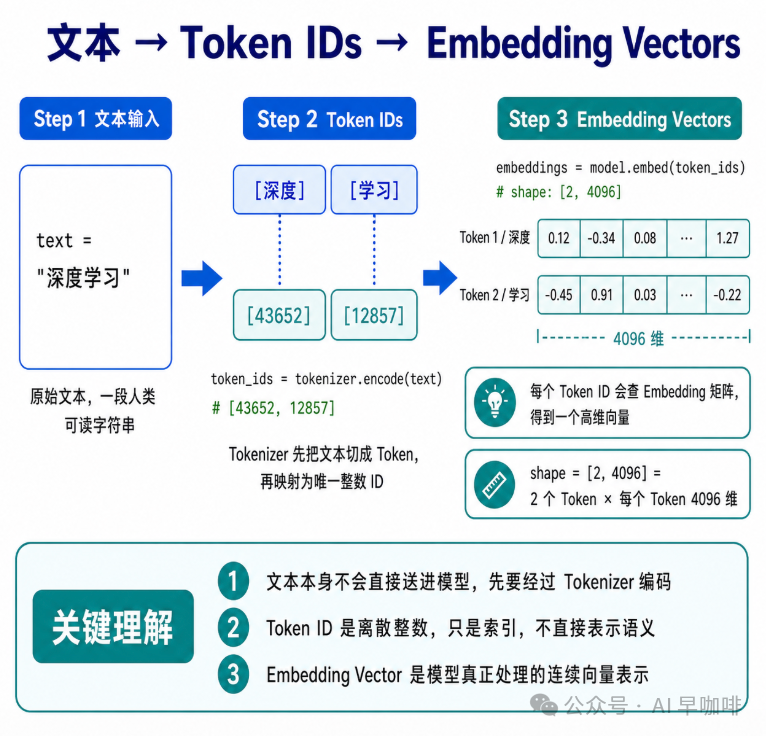
用下面这张表来把相关概念理清楚:
|
概念 |
含义 |
|---|---|
| 词表(Vocabulary) |
所有合法 token 的集合。GPT-4 约 100,277 个,Qwen2.5 约 151,643 个。词表越大,常用词被单个 token 覆盖的概率越高,压缩率越好;但词表大也意味着 Embedding 层参数量更大,训练成本更高 |
| 分词器(Tokenizer) |
把任意文本切成 token 序列,同时支持把 token 序列还原回文本(encode / decode) |
| Embedding 层 |
模型内部的查询表,把每个 token ID 映射成高维浮点向量,这才是神经网络实际运算的输入 |
为什么不直接用字符或单词
理解这个,才能真正理解子词分词解决了什么问题。
方案一:字符级(Character-level)
词表只有几百个字符,但代价是序列太长,"tokenization" 变成 了12 个 token,一篇千字文章可能产生五六千个 token。Transformer 的注意力机制计算复杂度是 O(n²),序列越长计算成本指数级上涨。更麻烦的是,字符之间的语义关联需要模型自己从零学起,层数不够就学不好。
方案二:单词级(Word-level)
每个单词一个 token,序列长度压缩得很好。但真实业务里词表会无限膨胀——英文各种形态变化、专有名词、代码标识符,词表轻松突破百万。更致命的是 OOV 问题:训练时没见过 "GPT-4o",推理时就不知道怎么处理,早期 NLP 系统只能把它变成 [UNK],信息直接丢失。
方案三:当前主流 -> 子词(Subword)
常见词保持完整,罕见词拆成更小的已知片段:
-
the、is、我→ 各 1 个 token -
tokenization→token+ization(2 个 token) -
GPT-4o→GPT+-+4+o(4 个 token,但能处理) -
词表大小可控,通常 30,000–150,000
语言里有大量复用的词素,比如 "-tion"、"-ing"、"pre-"、"un-"、"化"、"性"。把这些词素作为独立 token,既压缩了序列长度,又保留了词根语义,泛化能力还强。
Token 和文本生成的关系
理解了 token,就能真正理解大模型是怎么生成文字的。
大模型生成文本的本质只有一句话:根据已有 token 序列,预测下一个 token。
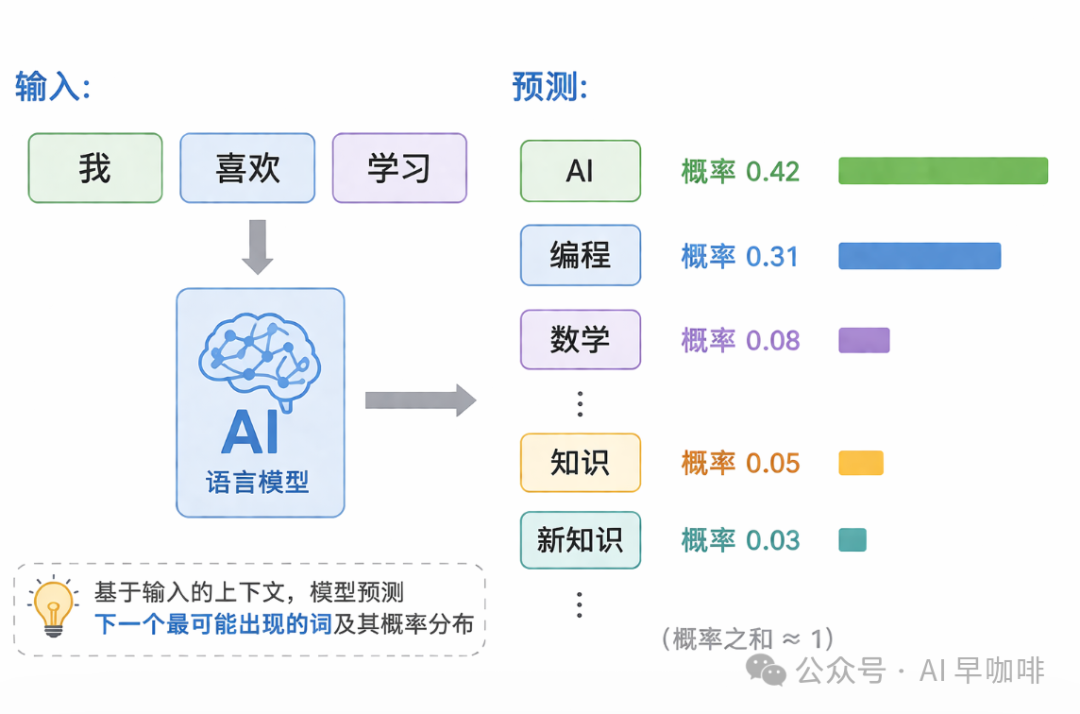
模型从概率分布里采样,得到下一个 token,然后把它加到序列末尾,再继续预测,如此循环,直到生成结束符。这就是为什么流式输出是一个字一个字蹦出来的——模型本来就是一个 token 一个 token 生成的,没有"先全部生成再发出来"这回事。
这个机制还解释了一个常见现象:为什么模型有时候会话说到一半截断?因为 max_output_tokens 控制的是最多生成多少个 token,不是多少个字。如果你设了 100,中文大概只能输出 60–80 个汉字,英文能输出 400 个字符左右。
BPE 算法:从零推导
BPE(Byte Pair Encoding,字节对编码)是目前最主流的分词算法,GPT 系列、LLaMA、Qwen 都在用它或其变体。
BPE 分两个阶段:训练(构建词表)和推理(对新文本分词)。
训练阶段
假设语料只有四个词,括号内是出现频率:
low (5次) lower (2次) newest (6次) widest (3次)
第一步:初始化,把每个词拆成字符序列,词尾加 </w> 标记:
l o w </w> (5)
l o w e r </w> (2)
n e w e s t </w> (6)
w i d e s t </w> (3)
第二步:反复统计相邻字符对频率,合并最高频的那个。
# Iteration 01
统计所有相邻对:
(e, s): 6+3 = 9次 ← 最高频(并列)
(s, t): 6+3 = 9次 ← 最高频(并列)
(l, o): 5+2 = 7次
选择 (e, s) 合并 → 新 token "es"
# Iteration 02
更新后语料:n e w [es] t </w> (6),w i d [es] t </w> (3)...
(es, t) 频率 9次最高 → 合并为 "est"
# Iteration 03
更新后语料:n e w [est] </w> (6),w i d [est] </w> (3)...
(est, </w>) 频率 9次最高 → 合并为 "est</w>"
# Iteration 04–06
依次合并:(l, o) → "lo",(lo, w) → "low",(low, </w>) → "low</w>"
# Iteration 07–09
依次合并:(n, e) → "ne",(ne, w) → "new",(new, est</w>) → "newest</w>"
最终词表:
初始字符:l, o, w, e, r, n, s, t, i, d, </w>
合并得到:es, est, est</w>, lo, low, low</w>, ne, new, newest</w> ...
每一条合并规则(merge rule)都按顺序记录下来,这就是分词器的核心产物。
推理阶段
推理时不重新统计,直接按训练时记录的合并规则顺序执行:
# "newest" 的分词过程
初始: n e w e s t </w>
合并1: n e w [es] t </w> # e + s → es
合并2: n e w [est] </w> # es + t → est
合并3: n e w [est</w>] # est + </w> → est</w>
合并4: [ne] w [est</w>] # n + e → ne
合并5: [new] [est</w>] # ne + w → new
合并6: [newest</w>] # new + est</w> → newest</w>
结果: [newest</w>] # 1个token!
换一个训练语料里没有出现过的词对比看:
# "newer" 的分词过程
初始: n e w e r </w>
合并1: [ne] w e r </w> # n + e → ne
合并2: [new] e r </w> # ne + w → new
# 没有 (w, e) 或 (e, r) 的合并规则,停止
结果: [new][e][r][</w>] # 4个token
这就是 BPE 的核心逻辑:高频出现的序列被合并成一个 token,低频或未见过的序列被拆成更小的片段。 没有任何词真正"无法处理",只是 token 粒度粗细的区别。
现代变体:Byte-level BPE
原始 BPE 在字符级别操作,遇到生僻汉字、emoji、特殊符号时还是会有 OOV。GPT-2 起引入了 Byte-level BPE:直接在字节(0–255)上做 BPE,而不是在字符上。
词表初始集合是 256 个字节,任何 UTF-8 文本都能无损处理,真正做到零 OOV。GPT-4、Claude、Qwen 基本都用这个方案。
但零 OOV 不等于零代价。一个生僻汉字在 UTF-8 下占 3 个字节,如果 BPE 训练时这个字出现得少、没学到对应的合并规则,推理时就会被拆成 3 个字节 token——能处理,但 token 效率很低。这也是为什么 Qwen、ChatGLM 要专门扩充中文词表——让更多汉字和词组能被单个 token 覆盖,既降低 token 消耗,也改善理解质量。
中文分词的特殊问题
中文没有天然的单词边界(英文有空格),这让分词多了一层挑战。
不同模型处理同一段中文,结果差异很大:
原文:人工智能改变了世界
GPT-4 (cl100k 词表): [人工][智能][改变][了][世界] → 5 tokens
Qwen2.5 (152k 词表): [人工智能][改变][了][世界] → 4 tokens
Qwen 把"人工智能"当成一个整体 token,GPT-4 把它拆成两个。这不只是语义问题,直接影响 token 消耗和成本。
中文比英文贵
这是很多团队做成本预算时踩过的坑(以 GPT-4 为例):
|
文本类型 |
粗略 token/字符比 |
|---|---|
|
英文 |
~0.25(4 字符 ≈ 1 token) |
|
中文 |
~0.5(2 字符 ≈ 1 token) |
|
代码 |
~0.18(关键字复用率高) |
同样 4000 字符的内容,中文产生的 token 数可能是英文的两倍。这就是文章开头那个报错的根本原因——4000 个中文字符,加上 prompt 模板和特殊 token,轻松超过 8192。
选用专门针对中文优化词表的模型(Qwen、ChatGLM),在中文场景下有实际的成本优势,这不是营销说法,是词表覆盖率的直接体现。
动手验证
光看理论没用,跑一下最直观:
from transformers import AutoTokenizer
# Qwen 0.5B,模型小,下载快
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2.5-0.5B")
text = "深度学习改变了世界,tokenization is the first step."
tokens = tokenizer.tokenize(text)
ids = tokenizer.encode(text, add_special_tokens=False)
print(f"原文字符数: {len(text)}")
print(f"Token 数量: {len(ids)}")
print(f"Token/字符比: {len(ids)/len(text):.2f}")
print()
for tok, tid in zip(tokens, ids):
print(f" {tok:20s} → {tid}")
运行后你能直接看到中英文混排时 token 粒度的实际差异,比任何文字描述都清楚。
小结
-
Token 是大模型处理文本的基本单元,是介于字符和单词之间的子词片段,每个 token 对应词表中的一个整数 ID
-
为什么分词:字符级序列太长效率低,单词级有 OOV 问题,子词分词是工程上的最优折衷
-
BPE 原理:从字符出发,反复合并语料中频率最高的字节对构建词表;推理时按相同规则执行合并
-
中文特殊性:token 消耗比英文高,选用中文优化词表的模型有实际成本优势
-
大模型生成:本质是逐 token 预测,流式输出和截断问题都从这里来
下一篇我们继续讲 Tokenizer 的完整工作流程——Normalization、Pre-tokenization、Chat Template,以及为什么你自己算的 token 数总是和 API 返回的对不上。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)