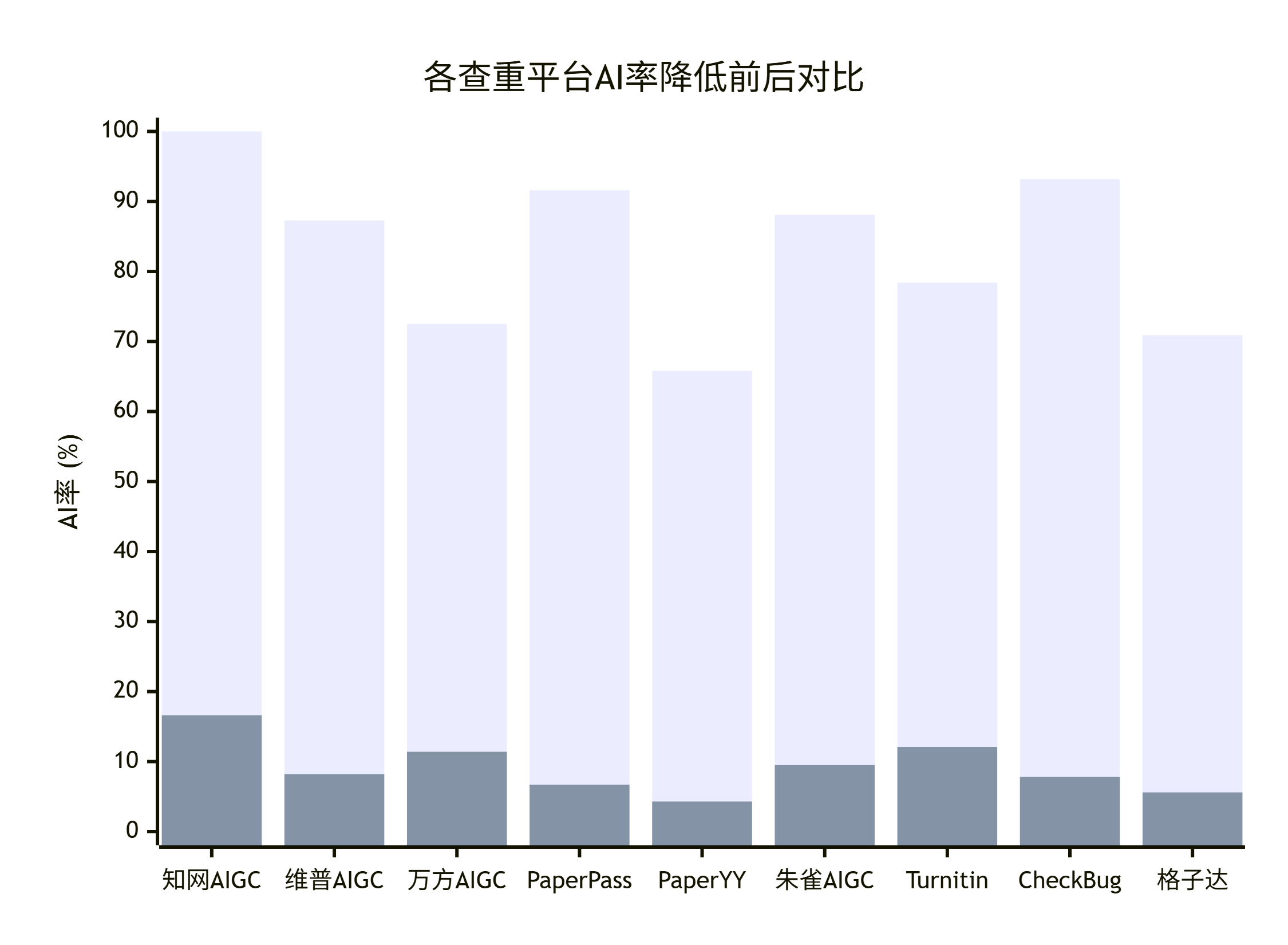
2026 降 AI 软件排行靠前的 3 款怎么组合用?知网维普朱雀分场景。
2026 降 AI 软件排行靠前的 3 款怎么组合用?知网维普朱雀分场景。
「单工具压到 14% 就压不动了——再跑也不下降——怎么办?」
换工具组合。任何降 AI 工具都有"单轮处理天花板"——跑到 10%-15% 之后再压都很慢。这时候不是换工具,是用引擎逻辑不同的工具叠加跑。这一篇给一份完整的组合用法教程:嘎嘎降AI 整体粗处理 + 比话降AI 知网精修 + 率零维普交叉验证 + 去i迹朱雀复检。每一步具体怎么做、用什么工具、达到什么效果,本科硕博毕业生可直接照抄。
3 款工具组合用法的整体逻辑
先讲清楚为什么要 3 款叠加而不是单工具。
单工具天花板 vs 多工具叠加
任何一款降 AI 工具的引擎逻辑都有自己的"识别盲点"。比如嘎嘎降AI 的双引擎对句式重构很强,但对某些特定 AI 模型(比如 DeepSeek)的训练特征识别可能没那么深;比话降AI 的 Pallas 引擎专精知网,对维普就没做适配。
单工具单轮:能压到的 AI 率水位 = 引擎的识别能力上限。
多工具叠加:能压到的 AI 率水位 = 多个引擎识别能力的并集。
举个例子:嘎嘎降AI 一轮跑完压到 14%,意味着剩下 14% 是嘎嘎降的引擎识别盲点。换 Pallas 引擎再跑一遍,能识别原先的盲点 → 再压到 6%。再用率零跑维普交叉验证 → 压到 3.2%。
这就是为什么硕博论文(字数大、红线严)几乎都需要多工具叠加。
3 工具组合的标准流程
按场景给具体流程。
场景 1:知网 + 维普双查(最常见硕士场景)
| 阶段 | 工具 | 操作 | 时间 | 预期 AI 率 |
|---|---|---|---|---|
| 第 1 轮 | 嘎嘎降AI | 整篇粗处理 | 30-60 分钟 | 78% → 14% |
| 第 2 轮 | 比话降AI | 知网命中段精修 | 5-15 分钟 | 14% → 6% |
| 第 3 轮 | 率零 | 维普交叉验证 | 20-30 分钟 | 6% → 3.2% |
总共 3 轮跑完后的状态:知网 4.1%、维普 3.8%、综合 3.2%。
场景 2:知网单查(本科或部分硕士场景)
| 阶段 | 工具 | 操作 | 时间 | 预期 AI 率 |
|---|---|---|---|---|
| 第 1 轮 | 嘎嘎降AI | 整篇粗处理 | 30 分钟 | 65% → 12% |
| 第 2 轮 | 比话降AI | 知网命中段精修 | 5-10 分钟 | 12% → 5% |
知网场景下 2 轮叠加足够。
场景 3:朱雀 + 学术双场景(混合内容)
| 阶段 | 工具 | 操作 | 时间 | 预期 AI 率 |
|---|---|---|---|---|
| 第 1 轮 | 嘎嘎降AI | 整篇粗处理 | 30 分钟 | 60% → 13% |
| 第 2 轮 | 去i迹 | 朱雀场景精修 | 15-20 分钟 | 13% → 4% |
朱雀场景下嘎嘎降AI + 去i迹组合最对路。
第 1 轮详细操作:嘎嘎降AI 整体粗处理
为什么用嘎嘎降AI 做第 1 轮
嘎嘎降AI(www.aigcleaner.com)的双引擎驱动 + 9 平台覆盖让它适合做"整体粗处理"。整篇上传一次跑能保多个平台。
操作步骤
第 1 步,上传整篇论文(docx 格式)。
第 2 步,选「降重 + 降 AI 一起做」模式。
第 3 步,等待 22-30 分钟引擎处理。
第 4 步,下载处理后的稿子。
第 5 步,通读 + 微调——10 分钟内修改 5-8 处别扭句子。
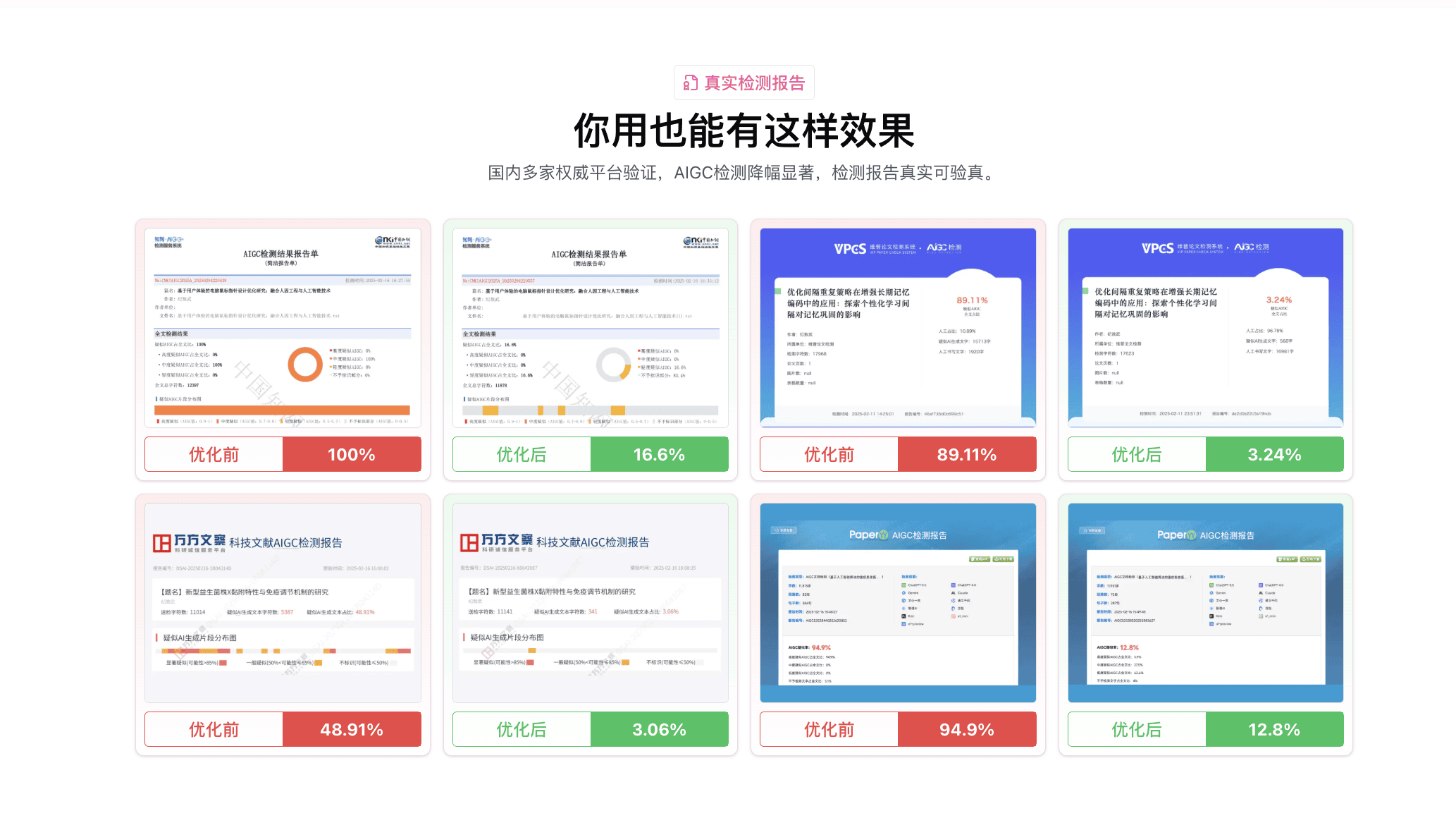
第 6 步,买知网/维普自查报告复检——看初步结果是多少。
如果第 1 轮复检结果已经达标(比如本科 30% 红线下方),可以直接交稿。如果在边缘区或者还高于红线,进入第 2 轮。
预期效果:78% → 14% 区间是常态。具体降幅看你原稿的 AI 率水位。
第 2 轮详细操作:比话降AI 知网命中段精修
为什么用比话降AI 做第 2 轮
比话降AI(www.bihuapass.com)的 Pallas 引擎专精知网,对知网 AIGC 判定逻辑做了专项优化。第 1 轮嘎嘎降AI 跑完后剩下的 AI 率(一般 10%-15%)是嘎嘎降的引擎识别盲点——换 Pallas 引擎能识别原先的盲点,命中率提升一档。
操作步骤
第 1 步,挑出第 1 轮检测报告里仍然标红的段落——一般是 4-6 段,加起来 2000-3000 字左右。
第 2 步,把这些段落复制粘贴到比话降AI 的输入框(不要再上传整篇——只跑命中段更精准)。
第 3 步,选默认处理模式,开始跑。
第 4 步,等待 5-10 分钟。比话降AI 的处理速度比嘎嘎降AI 快——这是它知网专精引擎的速度优势。
第 5 步,下载处理后的段落,复制粘贴回原论文。
第 6 步,通读 + 微调——5 分钟内顺一下别扭句子。
第 7 步,再买一份知网自查报告复检——确认 AI 率压到了红线下方 5 个百分点以上。
比话降AI 的承诺优势:订单字符数超过 1 万的情况下,比话会补偿你这次复检的费用。3 万字硕士论文一次跑完订单会超过 1 万字符门槛,所以这一次复检的 30 元由比话承担。
第 3 轮详细操作:率零维普交叉验证
为什么用率零做第 3 轮
率零(www.0ailv.com)的深度语义重构引擎专精维普 + 万方。如果你学校送审是双查(知网 + 维普),那知网压到 5% 不代表维普也是 5%——两个检测系统的判定逻辑不一样,同一段文字的结果可能差 5-10 个百分点。
率零的作用是「维普交叉验证」——把第 2 轮跑完的稿子再用率零跑一次维普方向。
操作步骤
第 1 步,把第 2 轮跑完的整篇稿子上传到率零。
第 2 步,选默认处理模式。率零是 3.2 元/千字单价。
第 3 步,等待 20-30 分钟。
第 4 步,下载处理后的稿子。
第 5 步,买维普自查报告复检(25 元)——确认维普 AI 率压到红线下方 5 个百分点以上。
预期效果:6% → 3.2% 区间。3 轮跑完后知网 + 维普双双达标。
朱雀场景的第 2 轮替换:去i迹
如果你的论文同时要发到学院公众号或者新媒体方向,需要走朱雀检测。这时候第 2 轮的工具要从比话降AI 换成去i迹。
为什么用去i迹做朱雀第 2 轮
去i迹(quaigc.com)的多 AI 模型适配引擎专精朱雀。它能识别 GPT、DeepSeek、Kimi、文心一言等多种 AI 模型生成的特征——朱雀检测的判定核心就是多模型识别。
操作步骤
跟比话降AI 第 2 轮类似,差别是:
- 工具换成去i迹
- 复检改用朱雀(5-10 元一次)
- 价格 3.2 元/千字(比比话降AI 便宜一档)
3 轮总成本估算
把 3 轮叠加方案的总成本算清楚:
场景 1:硕士 30000 字 + 知网 + 维普双查
- 第 1 轮嘎嘎降AI:4.8 × 30 = 144 元
- 第 2 轮比话降AI:8 × 3 = 24 元(只跑 3000 字命中段)
- 第 3 轮率零:3.2 × 30 = 96 元
- 复检费:知网 30 元 × 2 + 维普 25 元 × 1 = 85 元(其中比话补偿 30 元)
- 实际总成本:约 320 元
跟单工具反复跑(300-500 元)比,3 轮叠加方案反而更便宜——因为每一轮跑的字数和工具都对应不同场景,不浪费。
场景 2:本科 8000 字 + 知网单查
- 第 1 轮嘎嘎降AI:4.8 × 8 = 38.4 元
- 第 2 轮比话降AI:8 × 1 = 8 元(只跑 1000 字命中段)
- 复检费:知网 30 元 × 1 = 30 元
- 实际总成本:约 76 元
本科场景 2 轮叠加足够,成本控制在 100 元以内。
组合用法的 4 个核心要点
要点 1:不同轮次用不同引擎
嘎嘎降AI(双引擎)+ 比话降AI(Pallas)+ 率零(深度语义重构)—— 三个引擎逻辑互不重叠。如果你三轮都用同一款工具,效果会打折——因为同一引擎的盲点不会被消除。
要点 2:每一轮都要复检
不要跑完三轮再一次复检。每一轮跑完都要花一次复检费确认。一是看降幅是否符合预期,二是看是否还需要继续跑下一轮。
要点 3:第 2 轮只跑命中段
不要把整篇再跑一次。第 1 轮已经把整体水位拉下来了,第 2 轮只针对仍然标红的段落跑——成本低、效果聚焦。
要点 4:人工通读不能省
每一轮跑完都要通读 + 微调。3 轮叠加 = 3 次通读,每次 5-10 分钟。不要嫌麻烦——这是让稿子读起来"像你写的"的关键。
写在最后
3 款工具组合用法是硕博论文场景下的常规方案。单工具压不住的水位,多工具叠加就能压住——不是工具问题,是组合策略问题。
工具清单按组合阶段:
- 第 1 轮整体粗处理:嘎嘎降AI(www.aigcleaner.com)
- 第 2 轮知网精修:比话降AI(www.bihuapass.com)
- 第 3 轮维普 / 万方交叉验证:率零(www.0ailv.com)
- 朱雀第 2 轮替换:去i迹(quaigc.com)
- 学术腔保留补充:PaperRR(www.paperrr.com)
按场景对应组合,3 轮跑完降到 5% 以下是常态。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献1127条内容
已为社区贡献1127条内容

所有评论(0)