LLM 工程 tradeoff 拆解:Batch、显存、并行与推理经济学
最近听了 Reiner Pope 在 Dwarkesh Podcast 中关于 LLM 训练与服务背后数学与工程机制 的访谈。这期内容的重点不是 prompt engineering,也不是模型能力评测,而是更实际的问题:
大模型到底是如何被训练和服务的?
为什么训练昂贵?为什么推理也昂贵?
为什么长上下文、低延迟、高并发之间存在天然冲突?
如果从工程化视角看,这期播客最核心的观点是:
LLM 不是一个单纯的“模型文件”,而是一个受算力、显存、带宽、通信、调度和成本共同约束的分布式系统。
理解这一点,对做 AI 应用、Agent 系统、模型平台、推理服务和产品定价都有直接意义。
1. LLM Serving 的本质:不是“调用模型”,而是持续搬运和计算
很多应用层开发者容易把 LLM 推理理解成:
输入 prompt,模型生成 output。
但从系统角度看,推理过程更接近:
每生成一个 token,系统都要读取模型权重、读取上下文缓存、执行矩阵计算,并把结果继续写入缓存。
可以用一个很朴素的类比理解:
LLM 推理像一个超级大的开放式厨房。
厨师很厉害,火力也很猛,但每做一道菜,都要不断从仓库搬食材。
如果仓库离厨房很远,或者通道很窄,厨师再强也会等食材。
这里:
厨师 = GPU 计算能力;
食材 = 模型权重和 KV cache;
仓库通道 = 显存带宽;
厨房大小 = 显存容量。
所以大模型推理慢,不一定是“厨师不会做”,而可能是“食材搬不过来”。
也就是说,LLM serving 的核心成本来自四类资源:
| 资源 | 含义 | 对推理的影响 |
|---|---|---|
| Compute | GPU 的计算能力 | 决定理论计算吞吐 |
| Memory bandwidth | 显存读写速度 | 决定权重和 cache 能多快被读入 |
| Memory capacity | 显存容量 | 决定模型大小、上下文长度和并发量 |
| Communication | GPU/机器之间通信 | 决定多卡、多机扩展效率 |
一个很重要的工程判断是:
LLM 推理很多时候不只是 compute-bound,而是 memory-bound。
也就是说,GPU 不是“算不动”,而是“等数据”。
模型权重太大,KV cache 太大,显存带宽跟不上,计算单元就会空转。
这解释了为什么同一个模型,在不同硬件、不同 batch、不同上下文长度下,成本和延迟差异会非常大。
2. Batch Size:吞吐和延迟之间的核心权衡

播客中一个很重要的点是 batch size 对推理经济学的影响。
如果一次只处理一个请求,GPU 仍然需要读取完整模型权重,但这次读取只服务一个用户。单位 token 成本很高。
如果多个请求组成一个 batch,那么模型权重的一次读取可以同时服务多个请求。这样单位成本会下降,GPU 利用率会提高。
可以简单理解为:
Batch 就像拼车。
一个人打一辆车,成本很高;四个人拼同一辆车,单人成本下降。
但拼车也有代价:你可能要等别人上车,路线也更复杂。
Batch size 越大,单位 token 成本越低;但 batch 越大,用户等待时间可能越长。
这就是 LLM serving 里的基本矛盾:
| 目标 | 倾向策略 | 代价 |
|---|---|---|
| 降低延迟 | 小 batch、快速响应 | GPU 利用率较低,单位成本高 |
| 提高吞吐 | 大 batch、合并请求 | 首 token 延迟可能增加 |
| 降低成本 | 提高 batch 利用率 | 调度复杂度增加 |
| 保持体验 | 动态 batch | 系统实现更复杂 |
所以真实的 LLM 服务平台会使用动态 batching:在很短时间窗口内收集多个请求,尽量提高吞吐,同时控制用户可感知的延迟。
这个点对应用层也很重要。不同任务天然适合不同推理策略:
| 任务类型 | 更关注 | 推理策略 |
|---|---|---|
| 实时聊天 | 低延迟 | 小 batch,快速首 token |
| 文档批处理 | 吞吐 | 大 batch,后台处理 |
| Agent 工作流 | 稳定性 + 成本 | 队列调度、任务分层 |
| 报告生成 | 长输出质量 | 可接受更高延迟 |
所以,LLM 产品不是简单地“接入一个模型 API”。不同业务场景背后对应不同的 serving 策略。
如果用户正在和 AI 聊天,他希望模型马上开始输出,哪怕成本高一点也可以接受。这种场景更偏向小 batch 和低延迟。
但如果公司要在夜里批量总结 10 万条客服记录,就没有必要每条都实时返回。它可以把任务排队、合批、后台处理,用更低成本完成。
3. 长上下文为什么昂贵:问题不只是 token 多,而是 KV Cache 占显存
长上下文常被产品层理解为“模型能读更多内容”。但工程上,长上下文意味着更大的 KV cache。
在自回归生成中,模型每生成一个 token,都需要参考之前 token 的状态。为了避免重复计算,系统会把前文产生的 key/value 中间状态缓存下来,这就是 KV cache。
上下文越长,KV cache 越大。
可以把 KV cache 理解成: 模型的临时工作记忆。
一个更直观的类比是:
你让助理写一份报告。 如果你只给他 1 页材料,他桌面上放一页纸就够了。
如果你给他 300页材料,他需要把大量资料摊在桌面上,随时翻看。
桌子越大,能处理的材料越多;但桌子被一个任务占满后,就没法同时服务更多人。这里:
资料页数 = 上下文长度;
桌面空间 = 显存;
摊在桌上的资料 = KV cache;
同时服务多少人 = 并发能力。
上下文越长,KV cache 越大。它会直接占用 GPU 显存。
它带来的不是一个抽象问题,而是非常具体的工程成本:
| 长上下文带来的变化 | 工程后果 |
|---|---|
| 输入 token 增多 | prefill 阶段更慢 |
| KV cache 增大 | 占用更多显存 |
| 单请求显存占用变高 | 同卡并发量下降 |
| 请求长度差异变大 | batch 调度更困难 |
| 长请求挤占资源 | 短请求延迟变差 |
所以,长上下文的真实成本不是“多收一点 input token 钱”这么简单,而是它会改变整套推理服务的资源利用率。
这也是为什么长上下文 API 往往更贵,为什么 cached input 会单独定价,为什么很多系统会做上下文压缩、RAG、摘要和分层记忆。
小案例:把整本 PDF 塞给模型
假设用户上传一本 200 页 PDF,问:“帮我总结一下。”
最直接的做法是把全文塞进 prompt。
这样看起来简单,但成本很高:
输入 token 很多,prefill 慢; KV cache 很大,占显存;
如果同时有很多用户上传长文档,系统并发会明显下降。
更工程化的做法是:
先把 PDF 切块; 建索引; 根据问题检索相关片段; 只把必要片段放进上下文; 最后生成答案或报告。
这就是 RAG、摘要、结构化索引存在的工程意义。
从工程产品角度看,长上下文不能被当成免费能力。更合理的原则是:
能检索的不要全塞进上下文;能摘要的不要保留全文;能结构化传递的不要反复传自然语言长文本。
4. Prefill 和 Decode:推理其实分成两个不同阶段
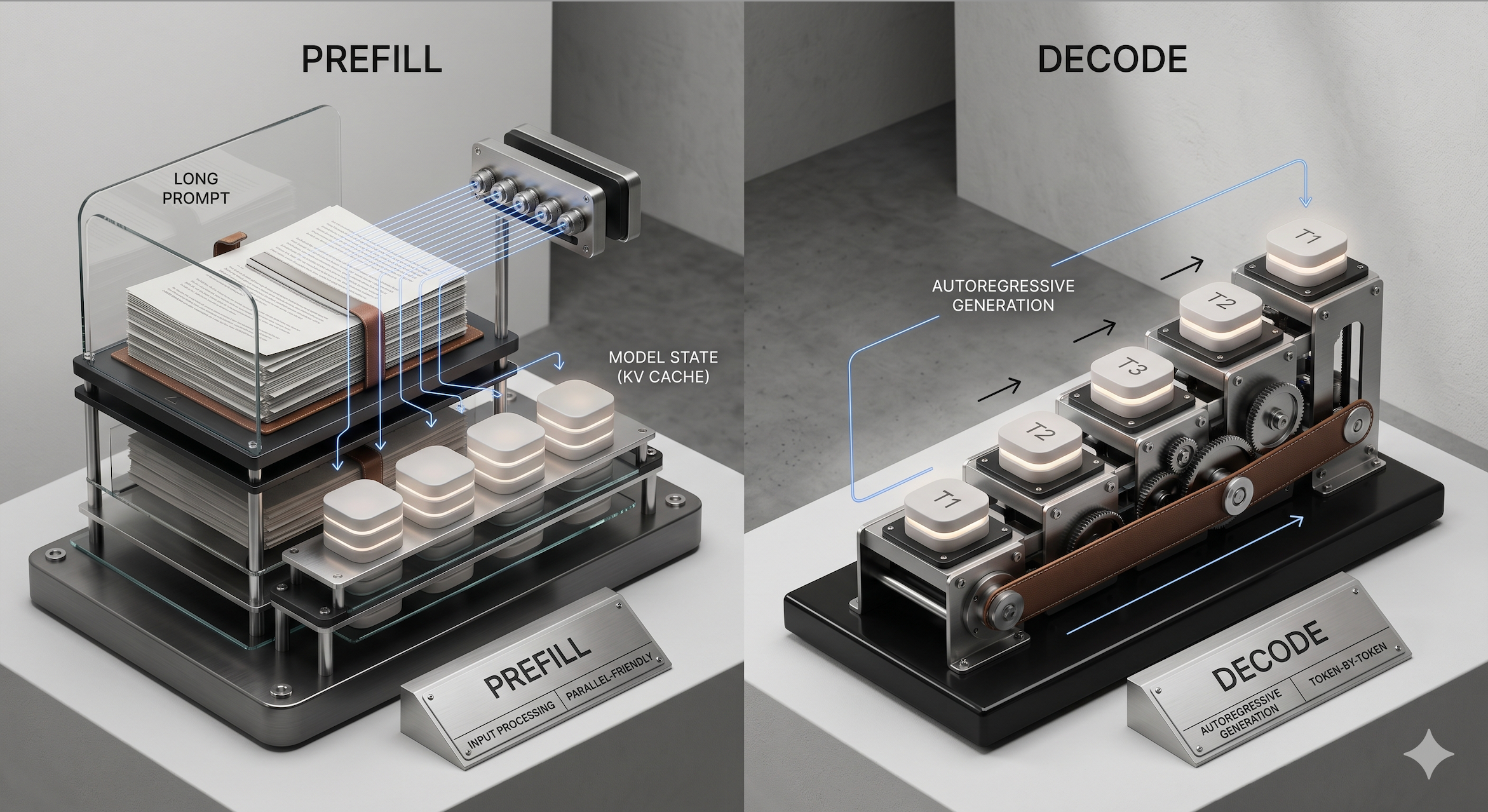
LLM 推理可以粗略分成两个阶段:
第一阶段是 prefill。
模型处理完整输入 prompt,构建上下文状态。
第二阶段是 decode。
模型一个 token 一个 token 地生成输出。
这两个阶段的资源特征不同:
| 阶段 | 做什么 | 主要瓶颈 |
|---|---|---|
| Prefill | 处理输入上下文 | 计算量大,适合并行 |
| Decode | 逐 token 生成 | 受显存带宽和 KV cache 影响明显 |
这解释了一个常见现象:
- 输入很长时,开始生成前会等很久;
- 输出很长时,生成过程会持续占用资源;
- 多轮对话越长,后续每轮的上下文成本越高;
- Agent 如果反复把历史全文塞回模型,成本会快速膨胀。
所以工程上要区分两件事:
长输入主要影响 prefill;长输出主要影响 decode;长对话则会持续扩大 KV cache 和调度压力。
这个视角对 Agent 系统尤其关键。一个 Agent workflow 如果每一步都携带完整上下文,每一步都长输出,系统成本会非常高。
5. MoE:稀疏激活降低计算,但引入路由和通信成本
播客中也讨论了 MoE,也就是 Mixture of Experts。
MoE 的核心思想是:
模型可以拥有很多专家参数,但每个 token 只激活其中一小部分专家。
这带来的好处是:模型总容量变大,但每次实际计算量可控。
但 MoE 的工程难点在于,专家通常分布在不同 GPU 甚至不同机器上。token 被路由到不同专家时,就会产生通信成本。
因此,MoE 的挑战不只是模型结构,而是分布式系统问题:
| MoE 机制 | 工程挑战 |
|---|---|
| token 路由到专家 | 路由开销 |
| 专家分布在多 GPU | 跨卡通信 |
| 不同专家负载不同 | 负载均衡 |
| 激活路径动态变化 | 调度复杂 |
| 参数规模扩大 | 部署复杂度上升 |
小案例:为什么 MoE 不等于免费变强?
假设一个模型有 100 个专家,但每个 token 只用 2 个专家。听起来计算量下降了。
但如果这 2 个专家分布在不同 GPU 上,系统就要把 token 的中间状态传过去,再把结果传回来。如果大量 token 都涌向同一个专家,还会造成拥堵。
所以 MoE 的收益依赖于路由、通信和负载均衡。
这也是大模型系统里一个反复出现的主题:
减少计算不等于减少系统复杂度。很多优化会把瓶颈从计算转移到通信、显存或调度。
6. Pipeline Parallelism:模型太大之后,服务就变成流水线系统
当模型太大,单张 GPU 放不下时,需要把模型切分到多张 GPU 上。
比如:
- 前几层放在 GPU 1;
- 中间层放在 GPU 2;
- 后几层放在 GPU 3。
这就是 pipeline parallelism。
它类似工厂流水线。每个 GPU 负责模型的一部分,数据依次流过不同阶段。
好处是:可以部署更大的模型。
问题是:流水线并不天然高效。
| 问题 | 含义 |
|---|---|
| Pipeline bubble | 有些 GPU 在等待,资源没有被完全利用 |
| Stage imbalance | 某一段计算更慢,拖慢整体 |
| Activation transfer | 中间结果需要跨 GPU 传输 |
| Synchronization | 多设备之间需要协调节奏 |
小案例:为什么加 GPU 不一定线性变快?
假设一个模型原来用 1 张 GPU 很慢。
你把它切到 4 张 GPU 上,直觉上会以为速度提升 4 倍。但实际上,每张 GPU 之间要传中间结果,还要等待前后阶段同步。
如果通信慢、切分不均,最后可能只提升 2 倍,甚至更少。
这就是分布式系统里的经典问题:扩展硬件不等于线性扩展性能
7. 训练和推理的共同难点:分布式系统效率
训练和推理关注点不同,但底层都受分布式效率约束。
训练时,需要处理:
- 数据并行;
- 张量并行;
- pipeline parallelism;
- optimizer state;
- gradient synchronization;
- checkpointing;
- failure recovery。
推理时,需要处理:
- batch scheduling;
- KV cache 管理;
- prefill/decode 分离;
- 多租户请求隔离;
- 模型并行;
- 延迟和吞吐平衡。
二者共同的问题是:
如何让昂贵的 GPU 尽可能少等待、少空转、少通信浪费。
这也是 LLM 工程的核心:不是单点优化,而是全链路资源利用率优化。
8. API 定价背后的工程逻辑
播客中很有启发的一点是:
LLM API 的价格结构,其实反映了底层物理资源约束。
为什么 input token 和 output token 价格不同?
因为输入和输出对应的推理阶段不同。
为什么 long context 更贵?
因为它占用更多 KV cache 和显存,降低并发能力。
为什么 cached input 更便宜?
因为前文状态可以复用,减少重复 prefill 成本。
为什么高性能模型和轻量模型价格差很多?
因为模型规模、显存需求、计算量和部署复杂度不同。
所以 API 定价不是随意的,它背后对应的是:
| 定价项 | 工程含义 |
|---|---|
| Input token | prefill 计算成本 |
| Output token | decode 持续生成成本 |
| Long context | KV cache 和显存占用 |
| Cached input | 复用上下文状态 |
| Fast tier | 更高优先级和低延迟资源 |
| Batch API | 用延迟换吞吐和成本 |
理解这一点之后,应用开发者就能更合理地设计产品能力。
比如,后台报告生成可以用 batch;实时聊天要控制上下文;文件问答要做索引;Agent 多轮执行要避免重复传全文。
9. 对 AI 应用工程的启发
这期播客虽然讲的是 LLM 训练和 serving,但对应用层工程有非常直接的启发。
最重要的一点是:
应用层的每一个产品设计,最后都会映射到底层推理成本。
例如:
| 应用层设计 | 底层成本 |
|---|---|
| 支持超长对话 | KV cache 增长 |
| 每轮都传完整历史 | prefill 成本增加 |
| 多 Agent 互相转发长文本 | token 和上下文成本膨胀 |
| 自动生成完整报告 | decode 成本增加 |
| 文件全部塞进 prompt | 显存和延迟压力 |
| 实时响应所有任务 | batch 利用率下降 |
所以,工程化的 AI 应用设计应该遵循几个原则:
第一,上下文分层。
短期对话、长期记忆、文件内容、结构化状态应该分开管理。
第二,按需检索。
不要把所有资料塞进 prompt,而是通过 RAG 或索引找到当前真正需要的片段。
第三,结构化中间状态。
Agent 之间传递 JSON、表格、引用、文件路径,而不是长篇自然语言复述。
第四,模型分级调用。
简单任务用小模型,复杂推理用强模型,长报告生成单独触发。
第五,任务调度分层。
实时任务追求低延迟,后台任务追求吞吐,批处理任务追求成本。
第六,输出按需生成。
PDF、报告、图表等长输出适合作为可选交付物,而不是每轮默认生成。
10. 一个工程化总结
这期播客最值得记住的,不是某一个公式,而是一套系统视角:
LLM 的能力不是孤立存在的,它始终被硬件、显存、带宽、通信和调度约束。
从工程角度看,可以把 LLM 系统理解成五个关键词:
Batch 摊成本。
多个请求一起处理,可以提高 GPU 利用率,但会影响延迟。
KV 吃显存。
长上下文的主要代价是 KV cache 增长,占用显存并降低并发。
MoE 吃通信。
稀疏激活降低计算量,但引入专家路由和跨设备通信。
Pipeline 吃同步。
模型切分到多 GPU 后,需要处理等待、通信和阶段不均衡。
Agent 吃上下文。
应用层多 Agent 工作流如果设计不好,会把上下文和调用成本迅速放大。
最终,LLM 工程的核心不是“把模型跑起来”,而是:
在模型能力、系统吞吐、用户延迟和推理成本之间做持续权衡。
这也是今天 AI 应用工程和传统软件工程最大的不同之一:
软件系统的每一次“智能输出”,背后都有明确的计算、显存和调度成本。
真正成熟的 AI 产品,不只是会调用模型,而是能把模型调用组织成一个稳定、可控、可扩展、成本合理的工程系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)