(论文速读)基于困难感知的长尾识别平衡边际损失
论文题目:Difficulty-aware Balancing Margin Loss for Long-tailed Recognition(基于困难感知的长尾识别平衡边际损失)
会议:AAAI2025
摘要:当使用严重不平衡的数据进行训练时,深度神经网络通常难以准确识别只有少数样本的类别。先前的长尾识别研究试图利用已知的样本分布来重新平衡有偏差的学习,主要解决类水平上的不同分类困难。然而,这些方法往往忽略了每个类的实例难度变化。本文提出了一种同时考虑类不平衡和实例困难的困难感知平衡裕度损失方法。DBM损失包括两个组成部分:类明智裕度,以减轻由不平衡的类频率引起的学习偏差,以及基于个体难度分配给硬阳性样本的实例明智裕度。DBM损失通过为更困难的样本分配更大的边际来提高类的判别性。我们的方法与现有方法无缝结合,在各种长尾识别基准测试中不断提高性能。
DBM Loss:让长尾识别同时感知类别不平衡与样本难度
一、背景:长尾识别的老问题,新视角
什么是长尾分布?
现实世界的数据很少是均匀分布的。无论是物种图像数据集(iNaturalist)、大规模图像分类(ImageNet-LT),还是工业质检数据,都呈现出典型的长尾分布:少数几个"头部"类别拥有成千上万的样本,而绝大多数"尾部"类别只有寥寥数张图片。
深度神经网络在这样的数据上直接训练,会严重倾向于"头部"类,导致"尾部"类的识别精度极低。这一问题被称为长尾识别(Long-tailed Recognition,LTR),是计算机视觉领域长期关注的核心挑战之一。
已有方法的局限
过去几年,研究者们从多个角度尝试缓解长尾问题:
- 重采样(Re-sampling):对尾部类过采样或对头部类欠采样,使训练集更加均衡。
- 重加权(Re-weighting):给尾部类分配更高的损失权重,强调稀少类的学习。
- Logit补偿(Logit Adjustment):在推理或训练阶段调整各类别的logit值,修正分布偏差。
- Margin Loss(LDAM等):给少数类分配更大的分类间隔(margin),迫使模型为它们学习更加紧凑的特征。
这些方法都有各自的贡献,但存在一个共同的盲点:它们都是在类级别(class-level)做文章,对同一类内部不同样本之间的难度差异视而不见。
以最具代表性的 LDAM Loss 为例:它为每个少数类分配一个更大的margin,但类内所有样本共享同一个margin值,无论这个样本是轻松分类还是在决策边界附近苦苦挣扎,都被一视同仁地对待。
核心问题:即便在同一个类别内,不同样本的分类难度也存在显著差异。忽视实例级难度,会让那些困难样本的潜力被浪费。
二、DBM Loss 的核心思路
本文提出的 DBM Loss(Difficulty-aware Balancing Margin Loss) 的核心思路可以用一句话概括:
在类级别margin的基础上,对类内被错误分类的困难样本额外施加一个与其难度正相关的实例级margin。
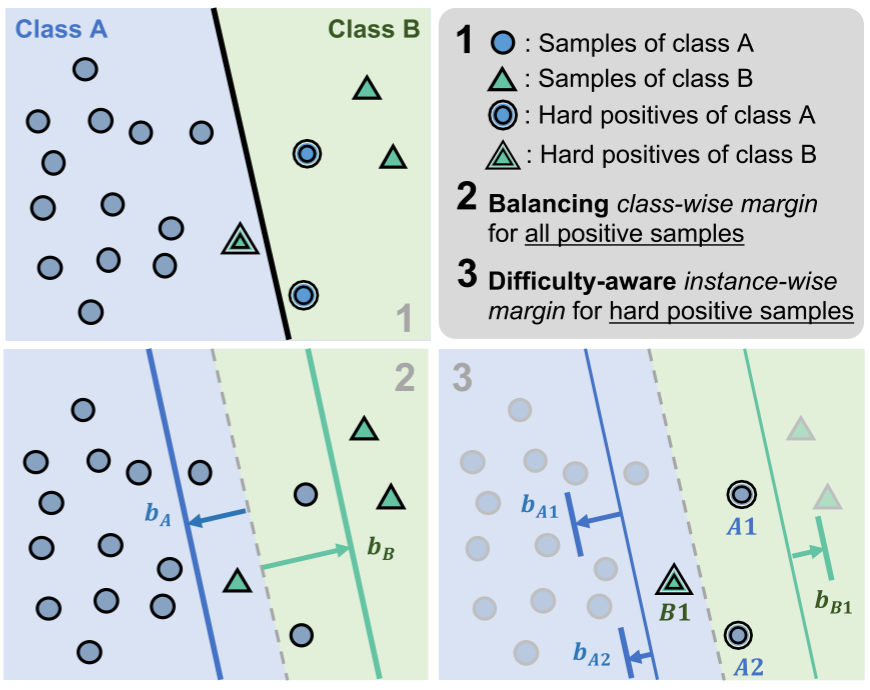
【此处配图:论文 Figure 1 方法总览图】
Figure 1 清晰地展示了这一思路。图中展示了一个二分类场景(A类样本多,B类样本少):
- Hard Positive Samples:被错误分类的样本(双线边框)被识别为"困难正样本"。
- Class-wise Margin:根据类别频率为每个类分配不同大小的 margin,少数类获得更大的
,多数类获得较小的
。
- Instance-wise Margin:在 class-wise margin 的基础上,对困难样本额外施加与其角距离成正比的 margin。样本 A1 比 A2 更远离类中心,因此 A1 获得更大的 margin,
比
偏移更多。
这样设计的物理直觉是:对困难样本施加更大的 margin,等价于给模型施加更强的压力,迫使这些样本的特征向类中心靠拢,从而提升类内紧凑性,同时增大类间可分性。
三、方法详解
3.1 预备知识:Cosine Classifier 与 Margin Loss
DBM Loss 建立在 cosine classifier 之上。与普通线性分类器不同,cosine classifier 将特征和类中心都归一化到单位超球面上,用角度来衡量相似度:
其中 s 为缩放因子, 为样本特征 f(x) 与第 i 类权重向量
之间的角距离。
基于此,一般的 margin loss 形式为:
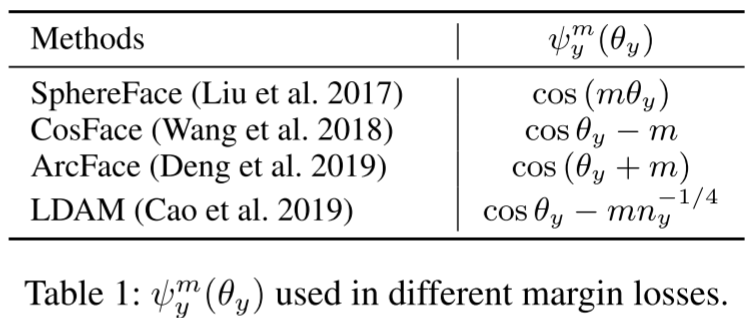
【此处配表:论文 Table 1 各 Margin Loss 的 logit 函数对比】
Table 1 总结了各代表性 margin loss 的正类 logit 函数。可以看到,SphereFace、CosFace、ArcFace 都对所有类使用固定 margin,而 LDAM 引入了与类频率相关的类级别可变 margin()。DBM 则在此基础上进一步引入实例级别的自适应 margin。
3.2 Class-wise Margin:处理类别不平衡
类级别 margin 定义为:
其中:
,即当前类样本数与最少类样本数之比;
控制不同类之间 margin 的差异幅度;
- K 为整体缩放系数。
当 (即该类就是最少样本的类),
,获得最大 margin;当
很大(头部类),
趋近于 0,几乎不受影响。
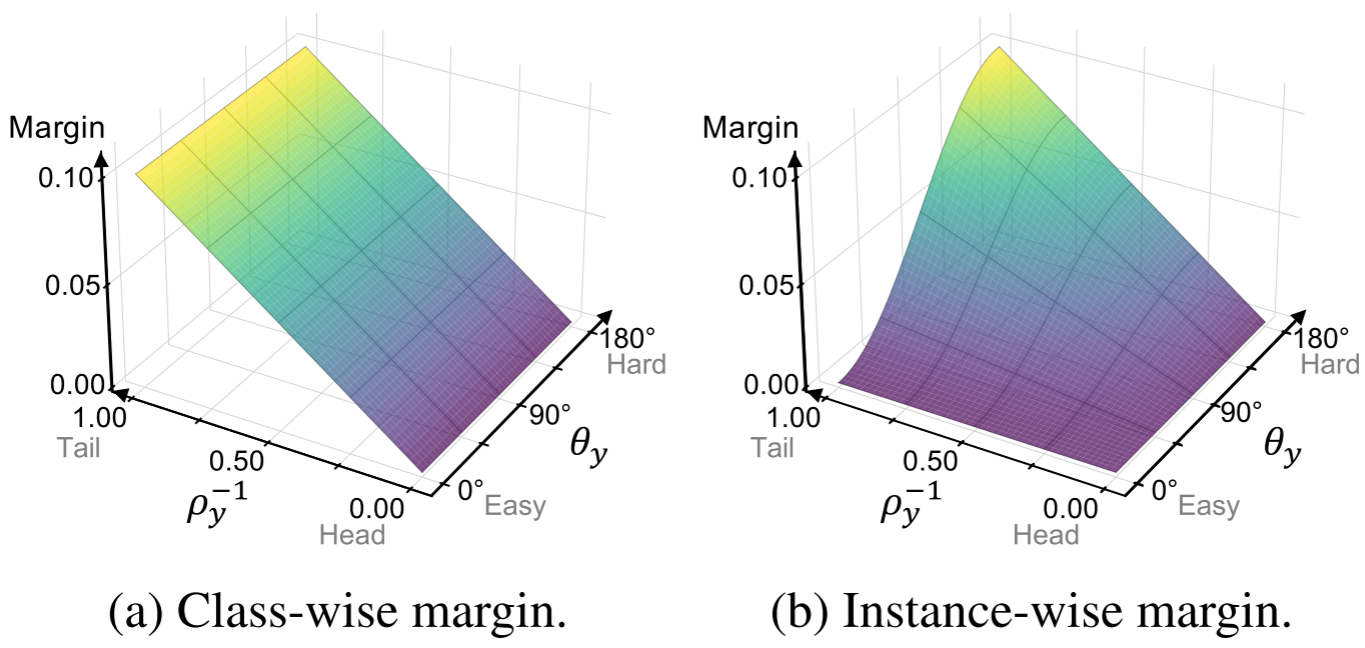
【此处配图:论文 Figure 2(a) margin 三维可视化】
Figure 2(a) 直观地展示了 随
和
的变化(注意此时
只与
相关,
轴上值不变)。作者通过实验验证,设
在所有实验中均表现稳定。
3.3 Instance-wise Margin:处理样本级难度差异
实例难度通过样本特征与正类中心的角距离来量化:
- 当样本特征恰好位于类中心时,
,
(最容易);
- 当样本特征与类中心方向相反时,
,
(最困难)。
实例级 margin 定义为:
这个设计有两个精妙之处:
- 与
耦合:少数类本身的
,对"少数类中的困难样本"施加双重强调。
- 有界性:
,保证实例级 margin 不会超过类级别 margin,数值稳定。
Figure 2(b) 展示了 同时随
(类别频率)和
(样本难度)变化的曲面,直观体现了"少数类+困难样本"的叠加效果。
3.4 完整的 DBM Logit 函数与损失
将两个 margin 整合进 ArcFace 风格的 logit 函数:
$$s\psi_y^{dbm}(\theta_y) = s\cos\Big(\theta_y + m_C + \mathbf{1}\big[\mathop{\arg\min}i{\theta_i}{i=1}^N \neq y\big] \cdot m_I\Big)$$
其中指示函数 $\mathbf{1}[\cdot]$ 的条件为:样本被错误分类(即正类的角距离不是最小的),此时该样本为 hard positive sample,才施加额外的 $m_I$。
将此 logit 代入一般 margin loss 框架,得到 DBM-CE 损失。
与其他方法的融合
DBM 可以无缝替换多种已有方法中的分类损失:
DBM-CB(结合 Class-Balanced Loss): $$L_{\text{DBM-CB}} = -\frac{1-\beta}{1-\beta^{n_y}} \log \frac{e^{s\psi_y^{dbm}(\theta_y)}}{e^{s\psi_y^{dbm}(\theta_y)} + \sum_{i\neq y} e^{s\cos\theta_i}}$$
DBM-BS(结合 Balanced Softmax Loss): $$L_{\text{DBM-BS}} = -\log \frac{e^{s\psi_y^{dbm}(\theta_y) + \log p_y}}{e^{s\psi_y^{dbm}(\theta_y) + \log p_y} + \sum_{i\neq y} e^{s\cos\theta_i + \log p_i}}$$
此外还支持 DBM-DRW、DBM-BCL、DBM-GML、DBM-NCL 等多种组合。
计算开销方面:$m_C$ 在训练前根据样本分布预计算完毕;$m_I$ 利用 forward pass 中已有的 $\cos\theta_y$ 即可得到,无需额外前向或反向传播。
四、实验结果
4.1 长尾 CIFAR 基准
【此处配表:论文 Table 2 CIFAR-10-LT 和 CIFAR-100-LT 结果对比】
在 CIFAR-10-LT 和 CIFAR-100-LT 上,使用 ResNet-32 作为 backbone,结果如 Table 2 所示。
主要观察:
- 全面提升:在所有基线方法(CE、DRW、BS、BCL、GML、NCL)上,加入 DBM 后均能稳定提升性能,验证了方法的普适性。
- 超越仅用类级别 margin 的方法:DBM-CE(46.53%)和 DBM-DRW(49.41%)均优于对应的 LDAM(45.25%)和 LDAM-DRW(48.99%),差距约 1.3~1.4%p,说明实例级 margin 带来了实质性的额外增益。
- DBM-BS 超越 BCL:DBM-BS(51.30%)超越了依赖对比学习分支的 BCL(50.23%),说明 DBM 无需增加模型复杂度即可实现强竞争力。
- 尾部类提升显著:在 CIFAR-100-LT (IF=100) 的细分统计中,DBM-NCL 的 Few 类精度达到 39.30%,比 NCL 基线的 36.20% 提升了 3.1%p,体现了 DBM 在最困难的尾部类上的优势。
4.2 ImageNet-LT
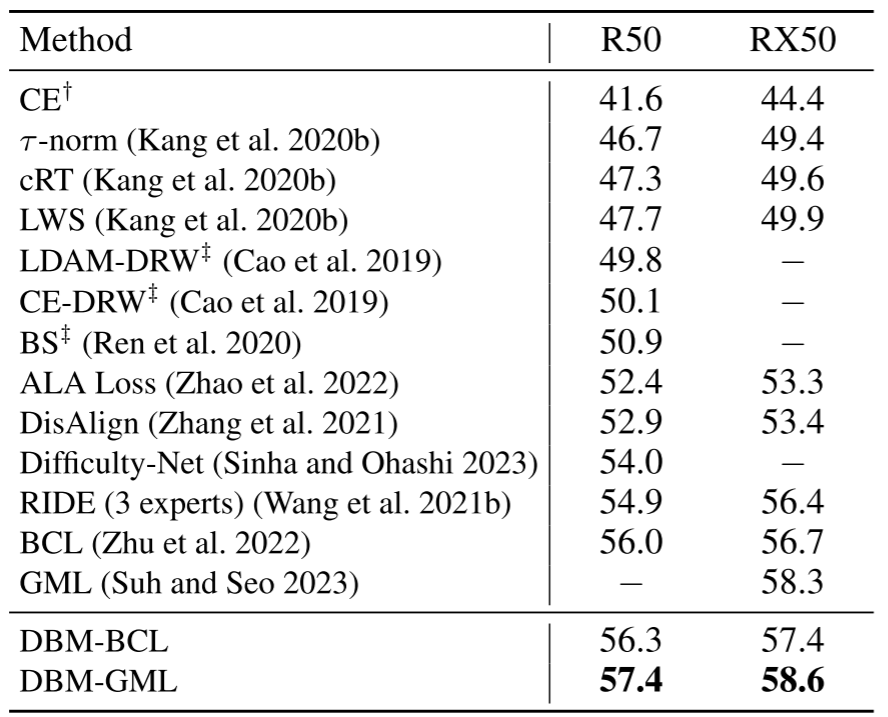
【此处配表:论文 Table 3 ImageNet-LT 结果对比】
在 ImageNet-LT 上,使用 ResNet-50 和 ResNeXt-50 进行评测,结果如 Table 3 所示。
- DBM-BCL(RX50):57.4%,比 BCL(56.7%)提升 +0.7%p
- DBM-GML(RX50):58.6%,比 GML(58.3%)提升 +0.3%p,达到该表中最高精度
值得注意的是,DBM-GML(58.6%)在不增加 expert 数量、不引入复杂结构的情况下,超越了需要 3 个 expert 的 RIDE(56.4%),体现出 margin 方法的简洁高效。
4.3 iNaturalist2018
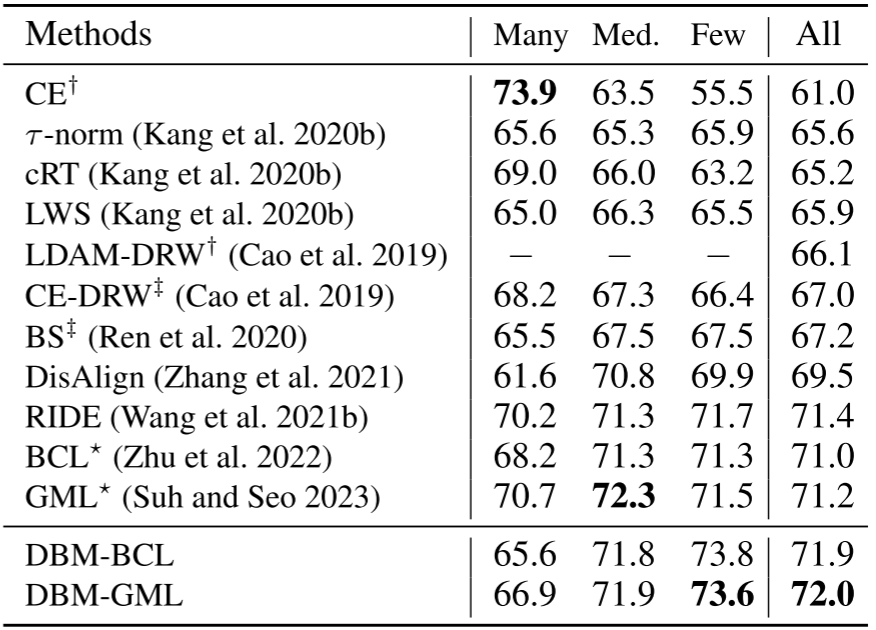
【此处配表:论文 Table 4 iNaturalist2018 结果对比(含 Many/Med./Few 分组)】
iNaturalist2018 是一个 8142 类的大规模细粒度真实场景长尾数据集(imbalance factor = 500),是检验长尾方法实际能力的严格基准。
- DBM-BCL:71.9%(+0.9%p vs BCL 71.0%),Few 类提升至 73.8%(+2.5%p)
- DBM-GML:72.0%(+0.8%p vs GML 71.2%),Few 类提升至 73.6%(+2.1%p)
两者在 Few 类上的大幅提升再次印证:实例级 margin 对于真实场景中极度稀少类别的识别具有显著帮助。
五、分析与消融实验
5.1 逐组件消融
Table 5 的消融实验系统地验证了每个组件的贡献,以 CIFAR-100-LT (IF=100) 为基准:
| 配置 | CE | BS |
|---|---|---|
| 基线(线性分类器) | 44.60 | 49.35 |
| + Cosine 分类器 | 44.29 | 49.84 |
| + mC(类级别 margin) | 45.85 | 50.61 |
| + mI(对所有正样本) | 46.38 | 50.93 |
| + mI(仅对 hard positive,DBM) | 46.53 | 51.30 |
关键结论:
- 单独引入 cosine 分类器对性能影响不大;
- 加入 class-wise margin 带来约 +1.5%p 的提升;
- 在此基础上加入 instance-wise margin 再带来约 +0.7%p;
- 只对 hard positive 施加 $m_I$(而非所有正样本)效果更好,说明聚焦真正困难的样本比"雨露均沾"更有效。
5.2 超参数敏感性
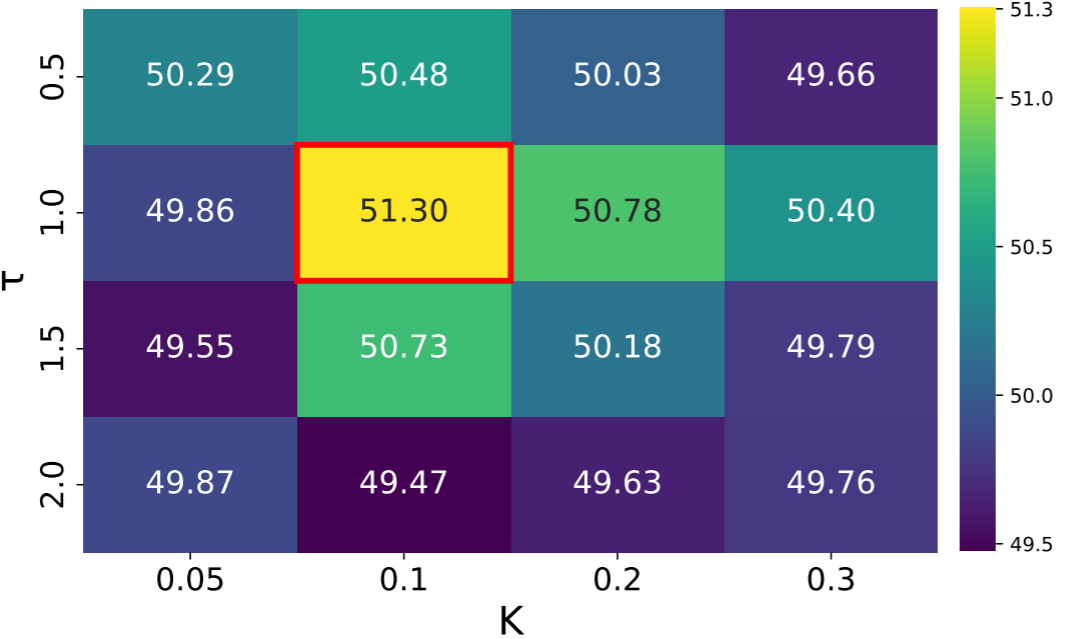
【此处配图:论文 Figure 3 超参数 τ 和 K 的热力图】
Figure 3 展示了 DBM-BS 在不同 τ 和 K 组合下的精度热力图。结果显示:所有 τ-K 组合均优于基线 BS(49.35%),说明 DBM 对超参数并不敏感,鲁棒性良好。实践中推荐 τ=1.0,K=0.1。
5.3 特征空间分析:类内紧密性与类间可分性
类内紧密性(Intra-class Compactness):
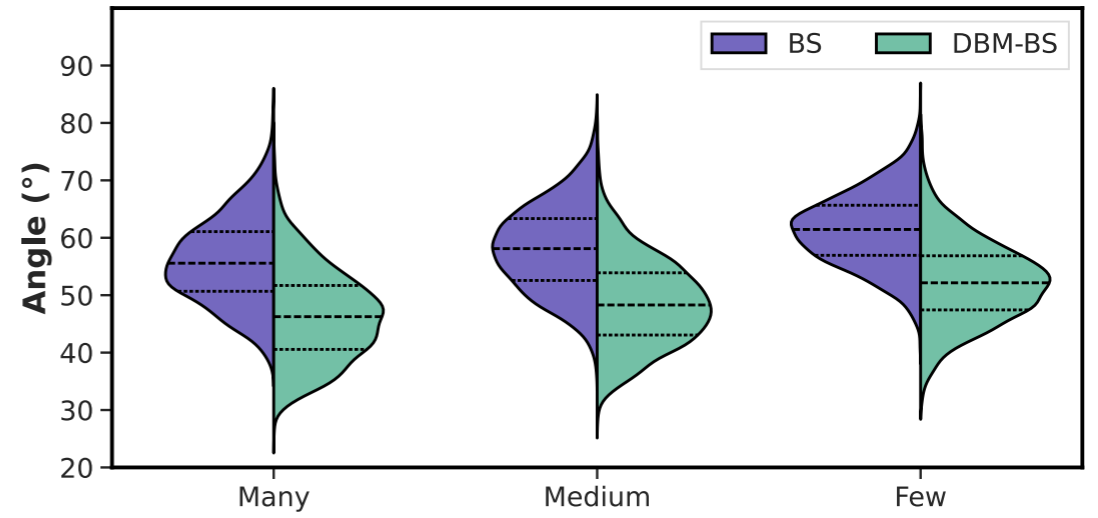
【此处配图:论文 Figure 4 BS vs DBM-BS 角距离分布小提琴图】
Figure 4 对比了 BS 和 DBM-BS 下样本特征与正类中心角距离的分布。DBM-BS 在 Many、Medium、Few 三组上均将平均角距离缩小了约 10°,表明实例级 margin 有效地将困难样本"拉向"了类中心,特征分布更加紧密。
类间可分性(Inter-class Separability):

【此处配表:论文 Table 6 Fisher 判别准则分析结果】
以 Fisher 判别准则(Fisher Criterion)衡量类间分离程度,值越大表示分离越好。如 Table 6 所示,DBM-BS 在所有类别组上均提升了类间可分性,All 组从 5.89 提升至 6.15。
六、总结与思考
方法优点
- 思路简洁:在已有 margin loss 框架上进行最小化改动,概念清晰,易于理解和实现。
- 兼容性强:与 CE、BS、DRW、BCL、GML、NCL 等主流 LTR 方法均可无缝结合,实际使用灵活。
- 计算高效:mC 预计算,mI 复用 forward pass 结果,无额外训练开销。
- 效果稳定:在 CIFAR-10/100-LT、ImageNet-LT、iNaturalist2018 四个基准上全面验证,且超参数不敏感。
局限与展望
- 方法依赖 cosine classifier,需要将已有线性分类器替换为 cosine 分类器,对某些特殊架构可能需要额外改动。
- 实例难度的度量仅使用了角距离一种指标,未来可探索更丰富的难度量化方式(如基于训练历史的动态难度估计)。
- 在 NCL 等更强基线上的提升幅度(约 0.8%p)相对有限,说明随着基线越来越强,进一步提升的空间逐渐收窄。
核心 Takeaway
DBM Loss 提醒我们:长尾识别不只是类别分布不均的问题,更是类内样本难度分布不均的问题。 将"困难在哪里"的问题从类级别细化到实例级别,是一个自然而有效的方向。这一思路与 hard example mining、curriculum learning 等领域的核心理念一脉相承,但 DBM 以极低的实现成本将其融入了 margin loss 框架,是一篇值得关注的工程友好型研究。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)