智能影记 (Memoria) —— 创新项目实训中期工作总结报告
项目名称: 智能影记 - Memoria
团队名称: Mnemosyne
报告日期: 2026年5月初(中期阶段)
一、 项目概述与整体进度
“智能影记”旨在利用多模态 AI 技术,打造一套兼顾隐私保护的智能生活记忆回顾系统。系统采用“端侧小模型感知 + 云端大模型推理”的协同架构,旨在将海量碎片化图片自动重构为高质量的图文日志与视听故事。
截至中期检查阶段,本项目严格遵循《任务书》中制定的敏捷开发周期。目前已顺利完成前四个核心阶段(需求规划、端侧感知与净洗、混合检索引擎、视听合成渲染)的开发任务,总体进度已达到 80%。核心技术管线已全部打通,实现了从原始图集输入到具备转场特效与节拍同步的 MP4 视频的自动化生成闭环。
二、 中期已实现的核心功能与技术成果
-
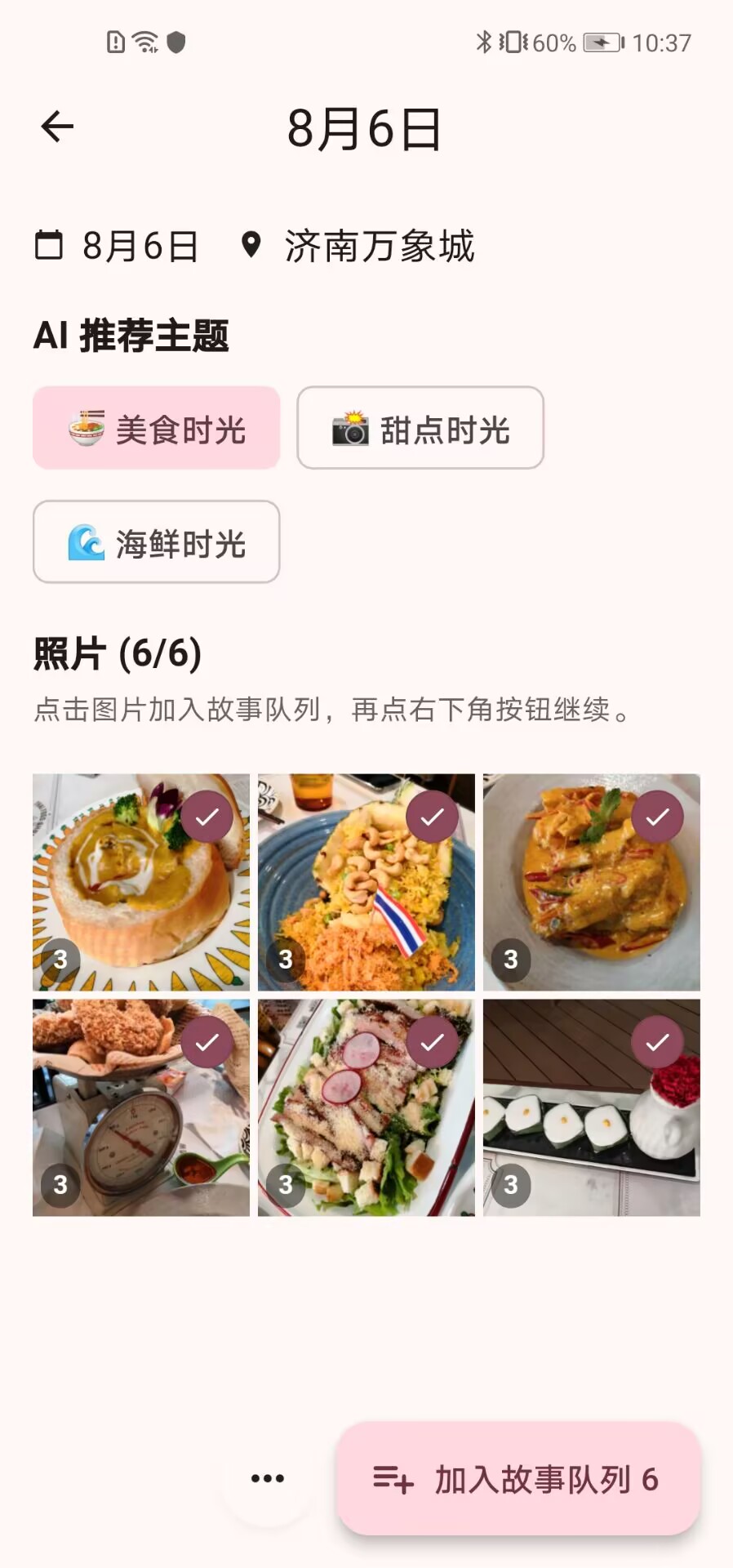
跨平台基建与本地数据底座(Phase 1-2)
- 高性能前端架构: 搭建了基于 Flutter 的跨平台客户端应用。针对海量图片加载问题,重构了基于 CustomScrollView 的懒加载瀑布流架构,配合 Provider/Riverpod 状态管理,实现了十万级图片数据下的首屏快速加载与平滑滚动。
- 边缘数据库部署: 部署了轻量级 Isar 本地数据库(替代原定的 ObjectBox)。完成了数据表结构设计(如 PhotoEntity),实现了图片基础信息、地理坐标、AI 标签以及高维图像向量的结构化存储与检索功能。

-
端侧多模态感知与隐私隔离引擎(Phase 2-3)
- 异构双后端推理引擎: 通过 Flutter FFI 技术桥接了底层 C++ 推理层,成功在移动端本地部署了 MobileCLIP 视觉大模型,并支持 NCNN 和 ONNX Runtime 两种后端的动态切换。
- 数据净洗与时空聚类功能: 集成端侧 OCR 技术与高低长宽比计算逻辑,实现了针对 UI 截图与非相机拍摄内容的自动化过滤。
- 接入高德地图逆地址解析(POI)API,结合拍摄时间戳,在手机本地完成了 HDBSCAN 叙事片段聚类算法。上述特征提取与聚类过程均在端侧完成,确保原始照片不上传云端。
-
云端大模型智能编导系统(Phase 3)
- LLM 语义转译与生成: 成功对接 Qwen (通义千问) 等大语言模型 API。设计了特定的少样本提示词模板,将端侧提取的脱敏文本(拍摄时间、地点、欢乐值分数、OCR内容)传输至云端,由 LLM 自动生成具有起承转合结构的图文日志以及带有分镜信息的视频脚本。
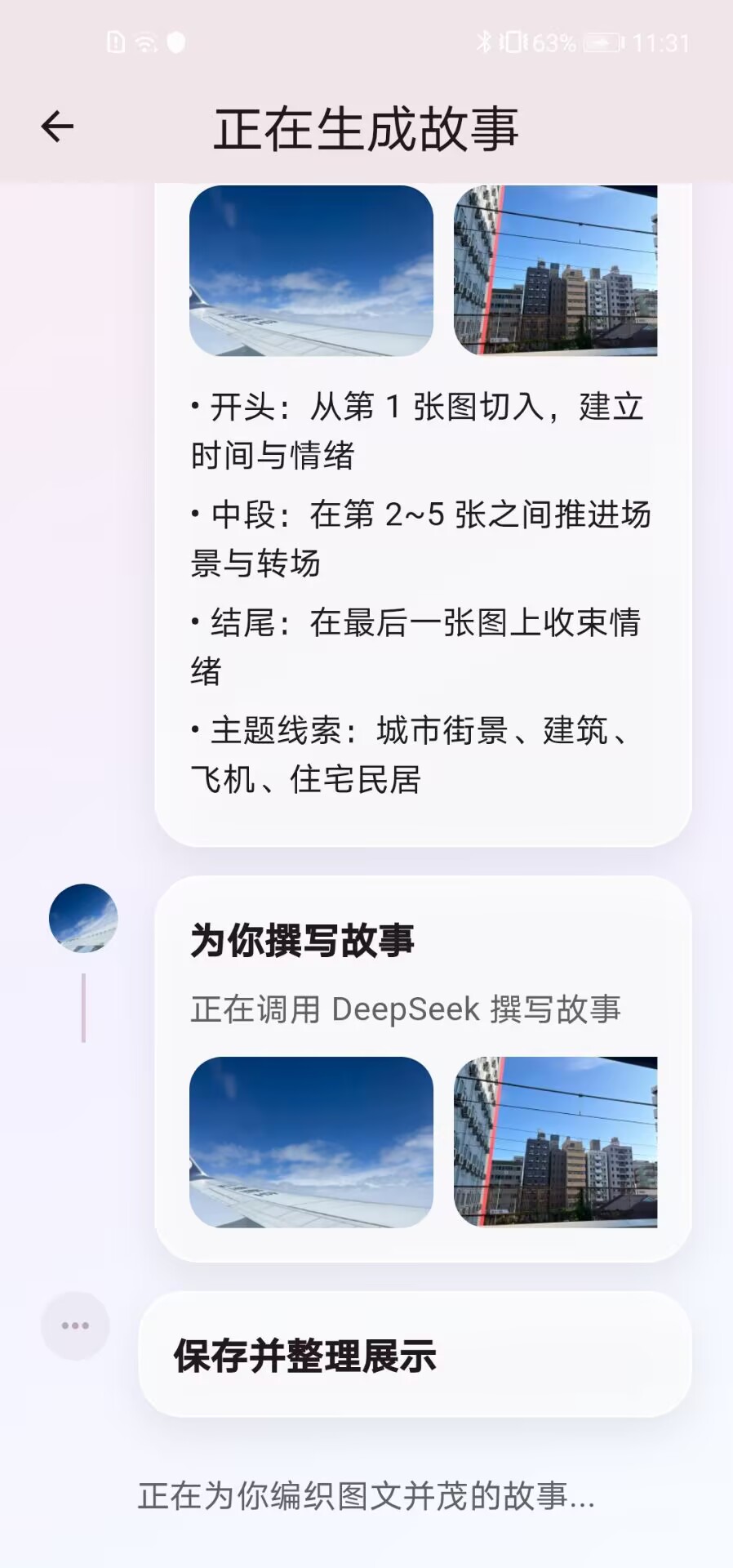
- LLM 语义转译与生成: 成功对接 Qwen (通义千问) 等大语言模型 API。设计了特定的少样本提示词模板,将端侧提取的脱敏文本(拍摄时间、地点、欢乐值分数、OCR内容)传输至云端,由 LLM 自动生成具有起承转合结构的图文日志以及带有分镜信息的视频脚本。
-
帧级动态视听渲染引擎(Phase 4)
- 云端音频特征解析: 部署了基于 FastAPI + Librosa 的音频处理微服务(后端使用 AWS Cognito JWT 鉴权)。该服务能够接收客户端上传的音频,计算并返回音频的 BPM(每分钟节拍数)、毫秒级节拍时间戳数组以及对应的 RMS 能量值。
- 逻辑驱动视听同步: 在 Flutter 端摒弃了传统的定时器切换机制。通过实时监听音频的真实播放进度,将音频的 RMS 能量数据动态映射至 AnimationController 的数值变化中,从而实现画面震动、缩放及硬切等视觉转场特效与音乐节拍的精准对齐。

-
硬件加速视频导出管线(Phase 4)
- 基于内存像素流的编码导出: 实现了端侧的视频渲染与导出。利用 RepaintBoundary 提取 UI 渲染树中的原生 rawRgba 像素流数据,通过对接 flutter_quick_video_encoder 及 Android MediaCodec 硬件编码接口,避免了将中间帧存储为本地图片的 I/O 开销。最后联合 ffmpeg_kit_flutter 完成音视频混流,有效提升了 1080P 视频的导出效率。
三、 攻克的重大工程难点
在开发上述功能的过程中,团队解决了一系列工程痛点:
-
端侧模型 OOM (内存溢出) 防御: 移动端并发运行视觉模型易耗尽内存。团队设计了基于引用计数的模型轮转与闲置释放机制(如 _workflowLeaseCount),在任务空闲时自动卸载底层模型实例并释放显存,通过了连续高强度视频生成的防崩溃测试。
-
音画同步误差控制: 由于主线程渲染耗时波动,常规时间戳机制存在同步误差。团队实现了以音频采样位置为绝对基准的时钟体系,将视觉动效与音频进度强制绑定,解决了视听偏移问题。
-
硬件编码器分辨率适配机制: 针对移动端 DSP/NPU 硬件编码器对输入图像缓冲区的严格对齐要求,在内存帧提取阶段引入了动态奇偶校验与强制裁剪算法,确保传入 MediaCodec 的视频长宽严格为偶数,修复了由此导致的编码器初始化失败及画面撕裂问题。
-
基于面积加权的智能构图: 针对源图片比例不一致的情况,开发了基于面部识别包围盒的面积加权视觉重心算法。系统能够自动计算特征点的权重分布,将画面焦点动态平移至主要人物面部,优化了自适应裁剪的视觉效果。
四、 下一阶段工作计划(冲刺与交付)
目前,项目的核心骨架已经十分健壮,接下来的几周(Phase 5),团队将重点聚焦于体验打磨与系统收尾:
-
智能检索引擎并网: 上线端侧向量空间比对功能,全面开放“长文本自然语言搜图(V2版)”接口。
-
多线程调度优化: 引入 Offscreen Render Worker 将视频像素抓取与编码导出任务转移至后台 Isolate 执行,进一步保障前台交互的流畅性。
-
视觉滤镜扩展与社交闭环: 增加电影感噪点、暗角等基于 Shader 的静态滤镜,并打通生成视频一键分享至主流社交平台的闭环流程。
-
结项准备: 完善项目全架构设计文档与 API 说明,输出不同硬件平台的性能测试报告,并准备最终结项答辩事宜。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)