给“虾马”装记忆系统,Hermes+Obsidian 让AI 更懂你
文档信息
字 数:3800 字 阅读时间:13 分钟 难度等级:⭐⭐(有 Python 基础更佳,代码可直接复制使用)
核心价值:从原理到代码完整拆解 Agent 记忆系统,看完就能自己搭
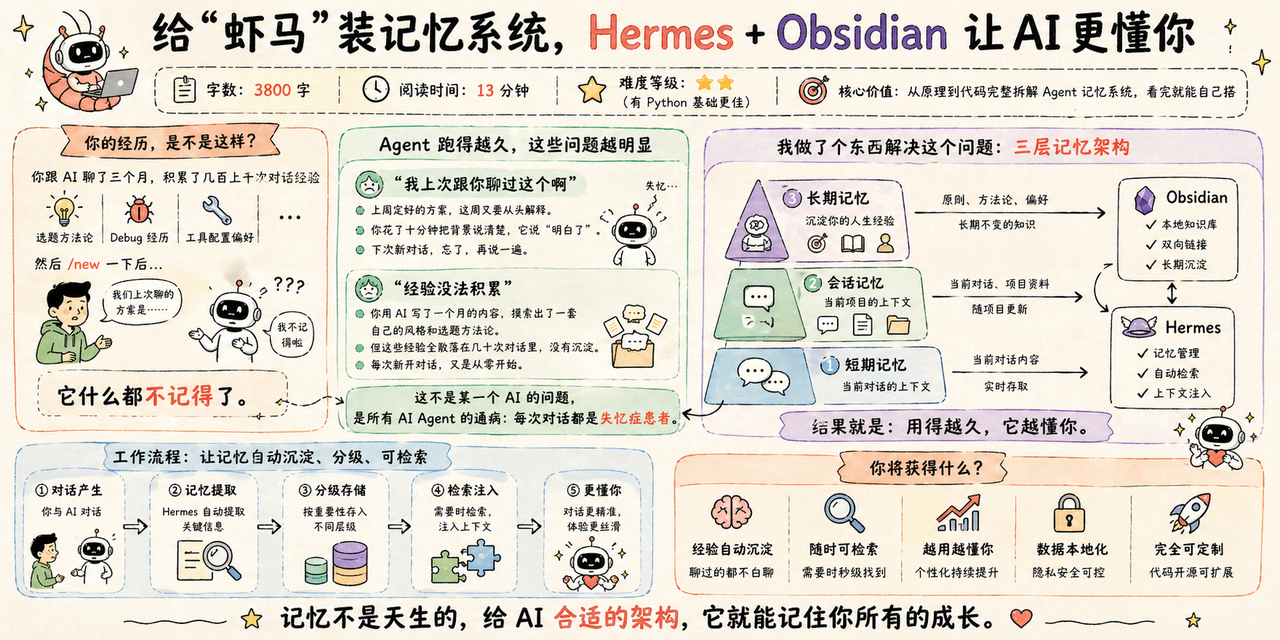 你跟 AI 聊了三个月,积累了几百上千次次对话的经验
你跟 AI 聊了三个月,积累了几百上千次次对话的经验
选题方法论、Debug 经历、工具配置偏好
然后/new一下后
它什么都不记得了。
Agent 跑的越久,这些问题越明显:
- "我上次跟你聊过这个啊"
- 上周定好的方案,这周又要从头解释。
- 你花了十分钟把背景说清楚,它说"明白了"。
- 下次新对话
- 忘了,再说一遍。
- "经验没法积累"
- 你用 AI 写了一个月的内容,摸索出了一套自己的风格和选题方法论。
- 但这些经验全散落在几十次对话里,没有沉淀。
每次新开对话,又是从零开始。
如果你有同感,往下看。
🎯
这不是某一个 AI 的问题
是所有 AI Agent 的通病:每次对话都是失忆症患者。
我做了个东西解决这个问题。
一个三层记忆架构,让 AI 的对话经验自动沉淀、分级、可检索。
结果就是:用得越久,它越懂你。
 这个记忆系统做了什么
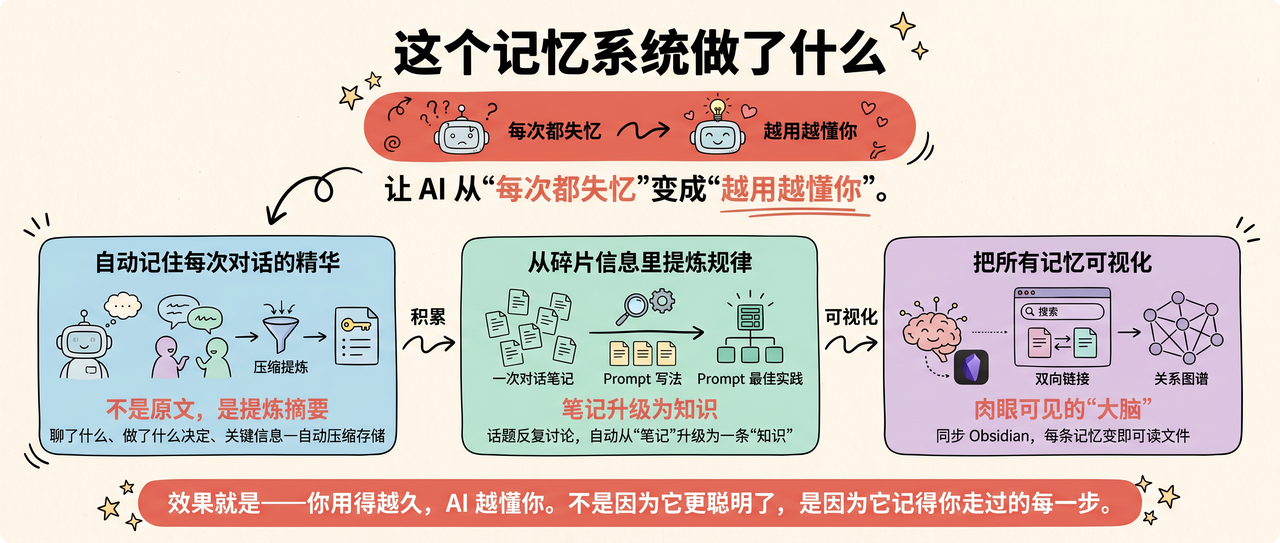
这个记忆系统做了什么
一句话概括:让 AI 从"每次都失忆"变成"越用越懂你"。
具体来说,它做了三件事:
- 自动记住每次对话的精华。
- 不是存聊天记录原文,是提炼成摘要。
- 聊了什么、做了什么决定、有什么关键信息——自动压缩,存下来。
- 从碎片信息里提炼规律。
- 当某个话题被反复讨论,系统会自动把它从"一次对话的笔记"升级为"一条知识"。
- 比如你聊了十次 prompt 写法,系统会把这十次的经验压缩成一条结构化的"Prompt 最佳实践"。
- 把所有记忆可视化。
- 同步到 Obsidian,每条记忆变成一个可读的 Markdown 文件。
- 能搜索、能双向链接、能看关系图谱。你的 AI 的"大脑",肉眼可见。
效果就是——你用得越久,AI 越懂你。不是因为它更聪明了,是因为它记得你走过的每一步。
 这个系统是怎么设计的(原理拆解)
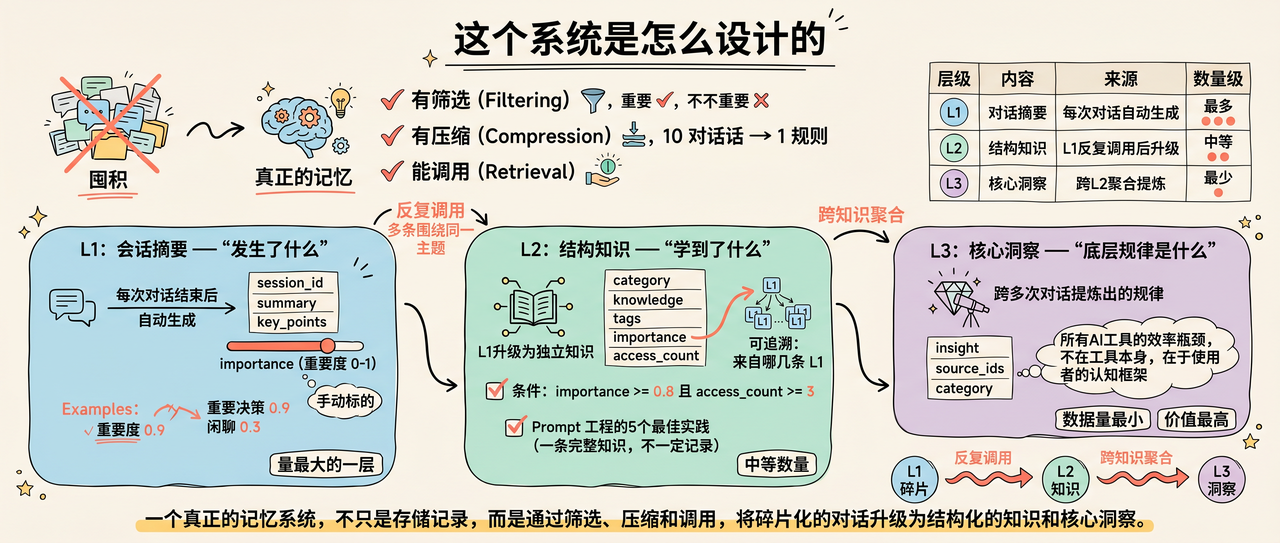
这个系统是怎么设计的(原理拆解)
设计之前我画了一条线:记忆不等于存储。
把所有聊天记录存下来不叫记忆,那叫囤积。
真正的记忆有三个特征:
- 有筛选 — 重要的记住,不重要的忘掉
- 有压缩 — 十次对话提炼成一条规律
- 能调用 — 下次对话时主动使用
这三个特征对应了三层架构:
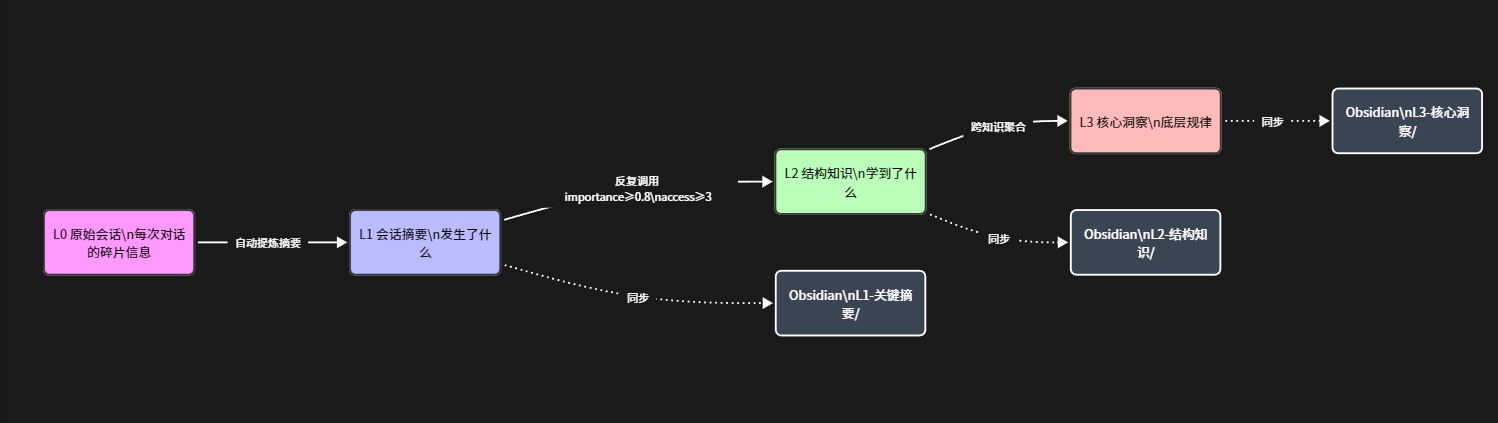
L1:会话摘要 — "发生了什么"
每次对话结束后,自动生成一条摘要。
存的东西包括:
- 会话ID
- 摘要文本
- 关键要点
重要度(0-1)。
重要度是我手动标的。
参考数值:一次重要的技术决策标 0.9,一次闲聊标 0.3。
CREATE TABLE IF NOT EXISTS memory_l1 (
id INTEGER PRIMARY KEY AUTOINCREMENT,
session_id TEXT NOT NULL,
summary TEXT NOT NULL,
key_points TEXT,
importance REAL DEFAULT 0.5,
access_count INTEGER DEFAULT 0,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
decay_score REAL DEFAULT 1.0
);
L1 是量最大的一层。你聊了多少次,就有多少条 L1。
L2:结构知识 — "学到了什么"
当一条 L1 记录被反复调用,或者多条 L1 围绕同一个主题,系统会把它升级为 L2。
L2 不是"某次对话的记录",是"一条独立的知识"。
比如"Prompt 工程的5个最佳实践",这条知识可能来自 10 次不同的对话,但它本身是一条完整的知识条目。
CREATE TABLE IF NOT EXISTS memory_l2 (
id INTEGER PRIMARY KEY AUTOINCREMENT,
category TEXT NOT NULL,
knowledge TEXT NOT NULL,
source_ids TEXT,
tags TEXT,
importance REAL DEFAULT 0.5,
access_count INTEGER DEFAULT 0,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
decay_score REAL DEFAULT 1.0
);
💡 核心观点:可追溯的知识升级
注意 source_ids 字段——它记录了这条知识是从哪几条 L1 提炼出来的。可追溯,不是凭空生成的。
🎯
背后的思考:升级条件是 importance >= 0.8 且 access_count >= 3。
也就是说,一条记忆必须同时"足够重要"和"被频繁使用",才会升级。
这避免了低质量记忆污染知识库。
L3:核心洞察 — "底层规律是什么"
最高层,数据量最小,价值最高。L3 不是某次对话的结论,是跨多次对话提炼出的规律。
比如:"所有 AI 工具的效率瓶颈,不在工具本身,在于使用者的认知框架。"
这种洞察不是一次聊天能得出的,是从几十次实践中沉淀出来的。
CREATE TABLE IF NOT EXISTS memory_l3 (
id INTEGER PRIMARY KEY AUTOINCREMENT,
insight TEXT NOT NULL,
source_ids TEXT,
category TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
decay_score REAL DEFAULT 1.0
);
三层的关系:
| 层级 | 内容 | 来源 | 数量级 |
| L1 | 对话摘要 | 每次对话自动生成 | 最多 |
| L2 | 结构知识 | L1 反复调用后升级 | 中等 |
| L3 | 核心洞察 | 跨 L2 聚合提炼 | 最少 |
🎯
L1(碎片)→ 反复调用 → L2(知识)→ 跨知识聚合 → L3(洞察)
 最酷的一个设计:会遗忘的记忆
最酷的一个设计:会遗忘的记忆
请允许我自夸一下:这是整个系统我最满意的部分。
每条记忆有个 decay_score(衰减分),初始值 1.0。
- 被访问时:+0.1(上限 1.0)
- 每小时自动衰减:×0.99
- 低于 0.05:标记为清理候选
算一下:一条从不被访问的记忆,大约 7 天衰减到 0.5,一个月衰减到 0.1。
你天天调用的记忆,衰减分一直在 0.9 以上。
⚠️ 这不是 Bug
如果你什么都记住,那不叫记忆,叫垃圾场。人脑就是这么工作的。
你天天用的技能刻在肌肉里,三年不碰的知识自然就模糊了。
🎯
记忆的价值不在于"记住了多少",在于"记住的是不是最重要的东西"。
而且衰减不是删除。低衰减分的记忆只是被标记为"候选清理",不会自动删除。
永远保留"反悔"的余地。
后台自动化:装完就不用管了
5 个 Cron 脚本在后台自动跑,不需要人工维护:
| 脚本 | 频率 | 干什么 |
| memory_decay.py | 每小时 | 全局衰减,降低长期不用的记忆权重 |
| memory_index.py | 每5分钟 | 刷新缓存,保证搜索速度 |
| memory_cleanup.py | 每小时30分 | 分析哪些记忆快过期了,只报告不删 |
| memory_compress.py | 每日凌晨3点 | 分析各层状态,输出升级候选报告 |
| memory_stats_report.py | 每日午夜 | 生成日报,推送飞书 |
你唯一需要做的:每次对话结束时,用一条命令写入摘要。
python3 memory_tiered.py add-l1 \
--session-id "本次会话ID" \
--summary "完成了小红书选题规划,确定了3个方向" \
--key-points "封面优化,标题10字法则,会员反馈" \
--importance 0.8写进去之后,什么都不用管。衰减、升级、同步、清理,全部自动。
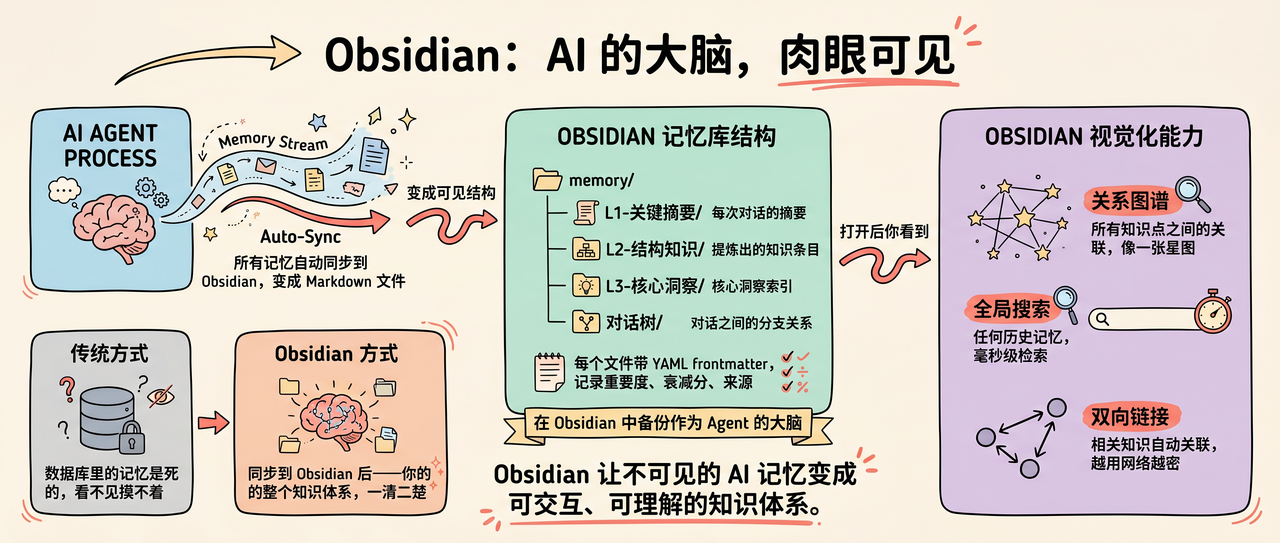 Obsidian:AI 的大脑,肉眼可见
Obsidian:AI 的大脑,肉眼可见
所有记忆自动同步到 Obsidian,变成 Markdown 文件。
memory/
├── L1-关键摘要/ ← 每次对话的摘要
├── L2-结构知识/ ← 提炼出的知识条目
├── L3-核心洞察/ ← 核心洞察索引
└── 对话树/ ← 对话之间的分支关系
每个文件带 YAML frontmatter,记录重要度、衰减分、来源。
在Obsidian中备份作为 Agent 的大脑
打开这些文件,你能看到:
- 关系图谱:所有知识点之间的关联,像一张星图
- 全局搜索:任何历史记忆,毫秒级检索
- 双向链接:相关知识自动关联,越用网络越密
数据库里的记忆是死的,看不见摸不着。
同步到 Obsidian 后——你的 AI 的整个知识体系,一清二楚。
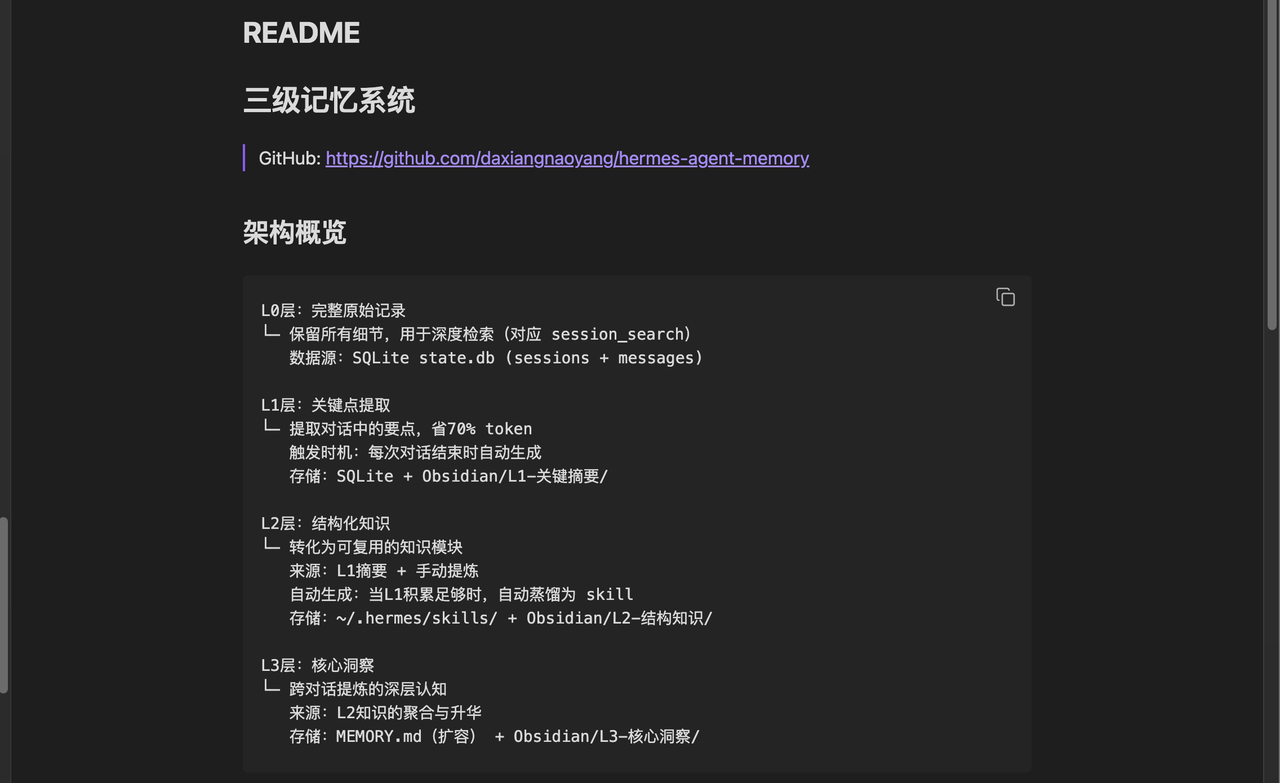
全部代码:一个文件,纯标准库
整个系统就一个 Python 文件 memory_tiered.py,1927 行。零第三方依赖。
SQLite、json、hashlib、datetime、collections、os、sys——全是 Python 自带的。
🎯 技术设计:6 个类,职责分明
🎯
背后的思考:单一职责原则。
每个类只管一件事,改一个不影响其他。
数据库存在 ~/.hermes/state/state.db,打开就能看。
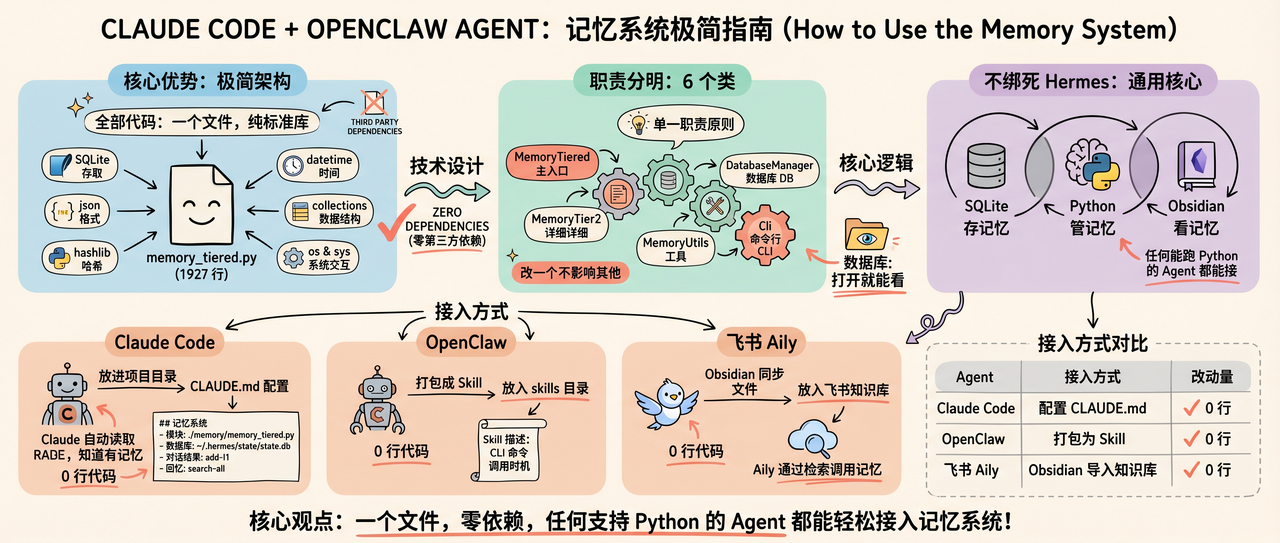 Claude code + Openclaw Agent 怎么用
Claude code + Openclaw Agent 怎么用
不绑死在 Hermes 上。
核心就是:SQLite 存记忆 + Python 管理记忆 + Obsidian 看记忆。
任何能跑 Python 的 Agent 都能接。
Claude Code
把 memory_tiered.py 放进项目目录,在 CLAUDE.md 里加一段:
## 记忆系统
- 模块:./memory/memory_tiered.py
- 数据库:~/.hermes/state/state.db
- 对话结束后用 add-l1 写入摘要
- 需要回忆时用 search-all 搜索
Claude Code 自动读取,知道有记忆系统可用。
OpenClaw
把记忆系统打包成一个 Skill,放进 OpenClaw 的 skills 目录。Skill 描述里写清楚 CLI 命令和调用时机就行。
飞书 Aily
把 Obsidian 同步的 Markdown 文件放进飞书知识库,Aily 通过知识库检索来"调用记忆"。不需要改代码,加一步飞书上传即可。
| Agent | 接入方式 | 改动量 |
| Claude Code | 放入项目目录 + CLAUDE.md 配置 | 0 行代码 |
| OpenClaw | 打包为 Skill | 0 行代码 |
| 飞书 Aily | Obsidian 文件导入知识库 | 0 行代码 |
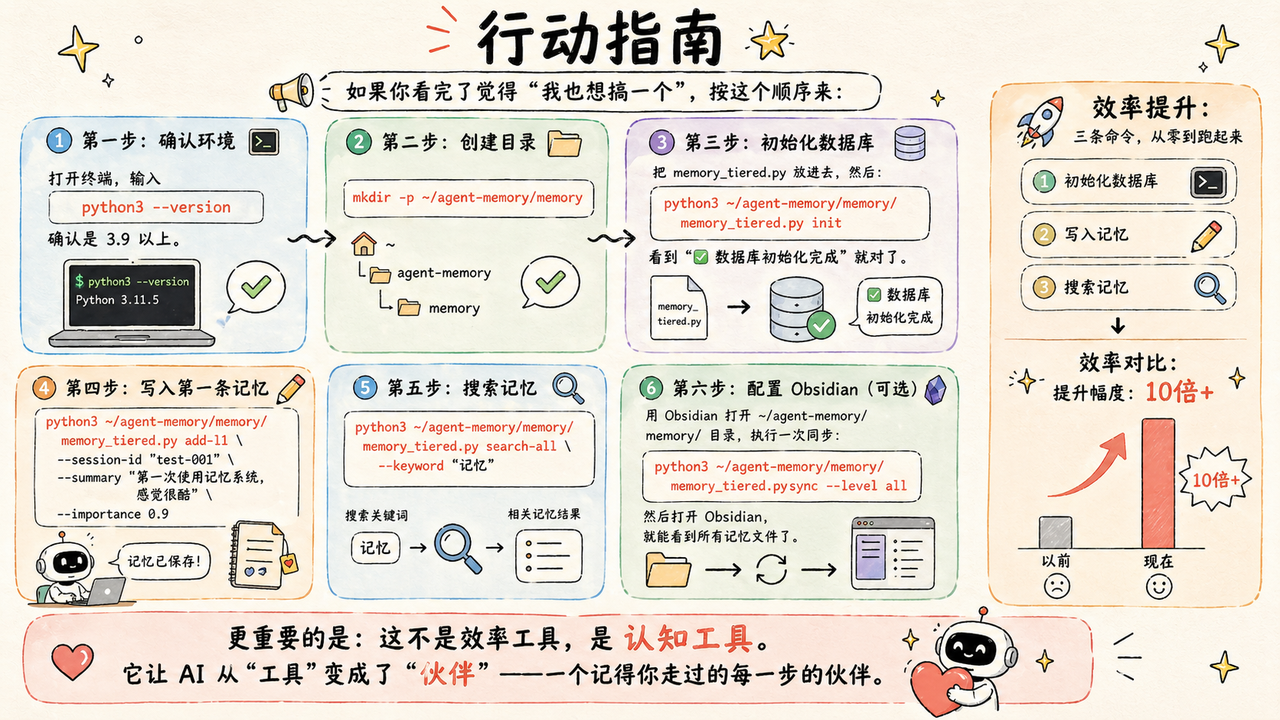 行动指南
行动指南
如果你看完了觉得"我也想搞一个",按这个顺序来:
第一步:确认环境
打开终端,输入 python3 --version,确认是 3.9 以上。
第二步:创建目录
mkdir -p ~/agent-memory/memory
第三步:初始化数据库
把 memory_tiered.py 放进去,然后:
python3 ~/agent-memory/memory/memory_tiered.py init
看到"✅ 数据库初始化完成"就对了。
第四步:写入第一条记忆
python3 ~/agent-memory/memory/memory_tiered.py add-l1 \
--session-id "test-001" \
--summary "第一次使用记忆系统,感觉很酷" \
--importance 0.9
第五步:搜索记忆
python3 ~/agent-memory/memory/memory_tiered.py search-all --keyword "记忆"
第六步:配置 Obsidian(可选)
用 Obsidian 打开 ~/agent-memory/memory/ 目录,执行一次同步:
python3 ~/agent-memory/memory/memory_tiered.py sync --level all
然后打开 Obsidian,就能看到所有记忆文件了。
🚀 效率提升:三条命令,从零到跑起来 效率对比:提升幅度:10倍+
更重要的是:这不是效率工具,是认知工具。它让 AI 从"工具"变成了"伙伴"——一个记得你走过的每一步的伙伴。
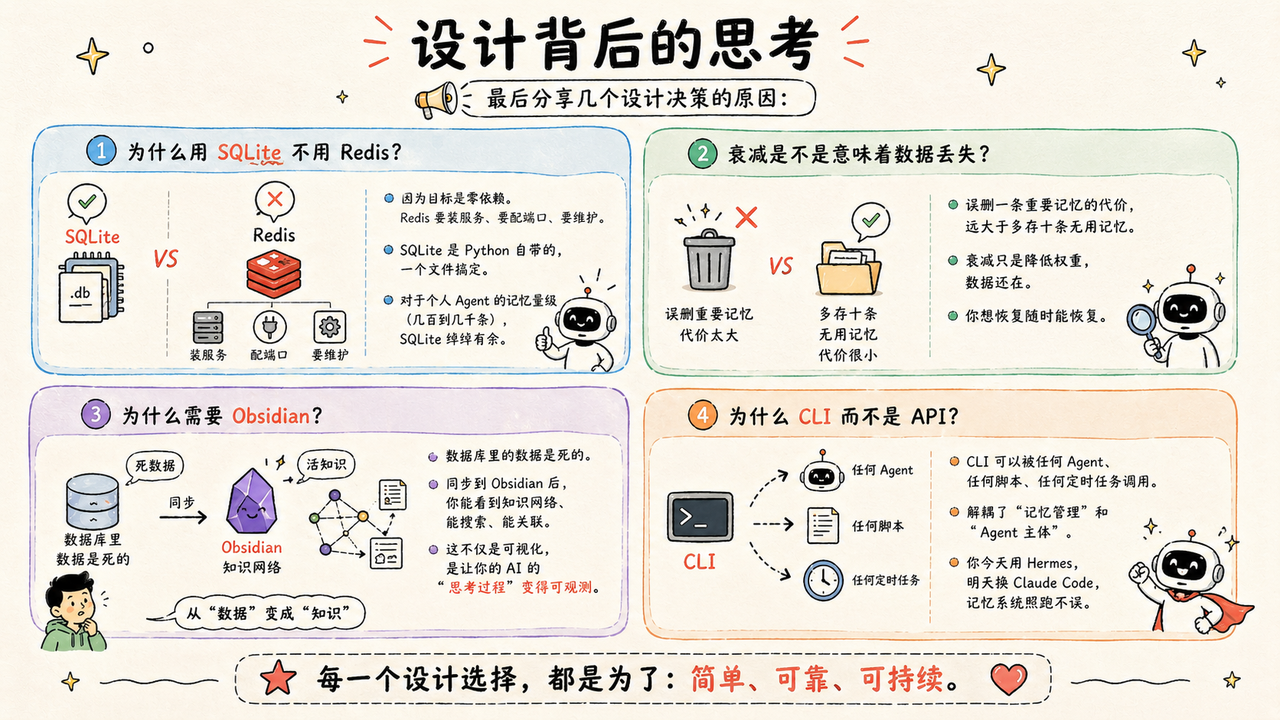 设计背后的思考
设计背后的思考
最后分享几个设计决策的原因:
- 为什么用 SQLite 不用 Redis?
- 因为目标是零依赖。Redis 要装服务、要配端口、要维护。
- SQLite 是 Python 自带的,一个文件搞定。
- 对于个人 Agent 的记忆量级(几百到几千条),SQLite 绰绰有余。
- 衰减是不是意味着数据丢失?
- 误删一条重要记忆的代价,远大于多存十条无用记忆。
- 衰减只是降低权重,数据还在。
- 你想恢复随时能恢复。
- 为什么需要 Obsidian?
- 数据库里的数据是死的。
- 同步到 Obsidian 后,你能看到知识网络、能搜索、能关联。
- 这不仅是可视化,是让你的 AI 的"思考过程"变得可观测。
- 为什么 CLI 而不是 API?
- CLI 可以被任何 Agent、任何脚本、任何定时任务调用。
- 解耦了"记忆管理"和"Agent 主体"。
- 你今天用 Hermes,明天换 Claude Code,记忆系统照跑不误。
#AI Agent #记忆系统 #Obsidian #Claude Code #开源项目 #Python #自动化 #长期记忆 #知识管理 #零依赖
相关链接
- GitHub 仓库:https://github.com/daxiangnaoyang/openclaw-advanced-memory
三句话总结
- AI 的记忆问题可以解决——不是靠更大的上下文窗口,而是靠分层蒸馏
- 三级架构是关键——从原始事实到结构化知识再到心智模型,信息在每一层被提纯
- 代码已经开源——1927 行 Python,零依赖,直接拿来用,你的 Agent 也能拥有长期记忆
作者:大象

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 32
32 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)