【论文精读】生成式预训练之BART
【概要】BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
https://arxiv.org/pdf/1910.13461 BART (Bidirectional and Auto-Regressive Transformers) 是Facebook Al于2019年提出的一种创新的预训练模型架构。它巧妙地结合了BERT的双向编码能力和GPT的自回归生成能力,通过降噪自编码器的方式训练序列到序列模型。这篇论文发表在ACL2020,是预训练语言模型领域的重要里程碑,首次证明了编码器-解码器架构可以同时出色地完成理解和生成任务。
核心思想非常直观:首先用任意噪声函数"破坏"原始文本,然后训练模型重建原始文本。这种设计让BART既能像BERT一样深度理解上下文,又能像GPT一样流畅生成文本,实现了理解与生成的统一。与之前专注于特定任务类型的预训练方法不同,BART的架构灵活性使其适用于广泛的下游任务,从文本分类到机器翻译,从问答系统到摘要生成。
实验结果表明,BART在生成任务上表现卓越,在XSum摘要任务上比前人工作提升3.5个ROUGE分;同时在理解任务上也不逊色,与RoBERTa在GLUE和SQuAD上表现相当。更难得的是,BART通过添加轻量级编码器就能应用于机器翻译,在WMT16罗马尼亚语-英语任
务上比强基线提升1.1个BLEU分。这种通用性使BART成为当时最通用的预训练模型之一。
1. GPT、BERT 和 BART
本节主要介绍 GPT、BERT 和 BART 这三种模型的关联和特点。
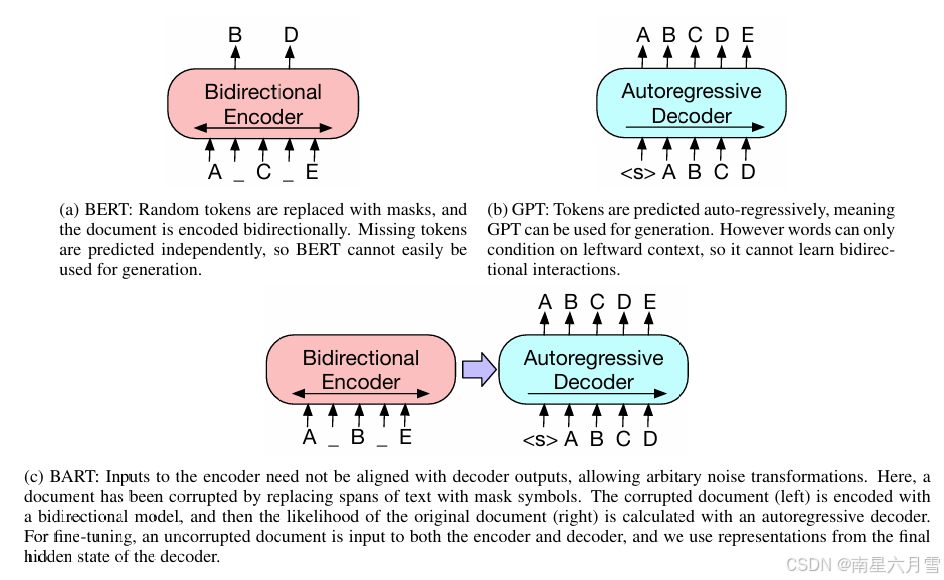
GPT 是一种 Auto-Regressive (自回归) 的语言模型。它也可以看作是 Transformer model 的 Decoder 部分,它的优化目标就是标准的语言模型目标:序列中所有 token 的联合概率。GPT 采用的是自然序列中的从左到右(或者从右到左)的因式分解。
BERT 是一种 Auto-Encoding (自编码) 的语言模型。它也可以看作是 Transformer model 的 Encoder 部分,在输入端随机使用一种特殊的 [MASK]token 来替换序列中的 token,这也可以看作是一种 noise,所以 BERT 也叫 Masked Language Model。
BART吸收了 BERT 的 bidirectional encoder 和 GPT 的 left-to-right decoder 各自的特点,建立在标准的 seq2seq Transformer model 的基础之上,这使得它比 BERT 更适合文本生成的场景;相比GPT,也多了双向上下文语境信息。因此,它对于生成任务和一些文本理解类任务都有较好的效果。
再概括一点:
BART模型是使用标准Transformer模型整体结构的预训练语言模型。
BERT模型是仅使用Transformer-Encoder结构的预训练语言模型。
GPT模型是仅使用Transformer-Decoder结构的预训练语言模型。
2、BART 的训练流程
我们以上图为例,介绍 BART 的训练流程。
BART 在训练时,首先对于 encoder 端,将原始文本(如 A B C D E)做随机破坏,得到一个加噪的输入(如 A _ C _ E)。由于双向自注意力机制的作用,每个 token 都能看到整个序列的所有 token,哪怕是 mask 掉的位置,也能通过上下文推断其含义。从而将这段有噪声的输入编码成一个包含完整的上下文信息的向量表示。
接着看 decoder 端,输入是一段经过 right-shifted 的原始序列,在开头加上了特殊的起始符 <s> (如 <s> A B C D)。这时由于单向自注意力机制的作用,每个 token 只能看到它左边的 token ,保证模型不能知晓未来的 token。同时 decoder 还会接受 encoder 传来的向量,把理解到的上下文信息融入生成的过程。最终 decoder 输出一段未加噪的原始序列。
整体而言,BART 的目标就是从加了噪声的输入,重建出原始文本。
3、BART 在下游任务上的应用
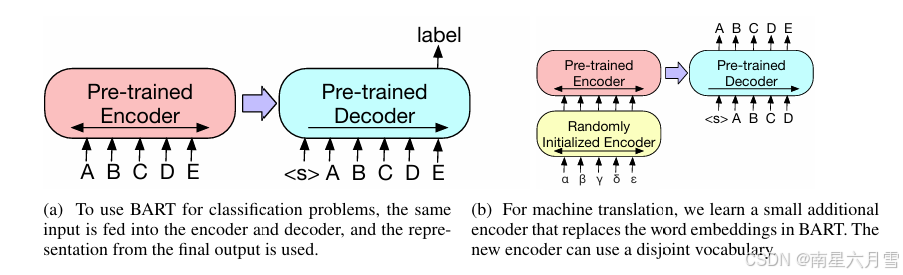
3.1 Sequence Classification Task
将该序列同时输入给 encoder 端和 decoder 端,然后取 decoder 最后一个 token 对应的 final hidden state 作为 label,输入给一个线性多分类器。注意在序列的最后要加一个 token,保证seq2seq 模型输出的 label 包含序列中每一个 token 的信息(因为 decoder 的输入是 right-shifted 的,不这样做的话 label 将不包含最后一个 token 的信息)
3.2 Token Classification Task
这一类问题意思是,将序列的所有token都看作独立的选项,序列长度为M,那么选项的个数就是M,在序列的所有token中选择k个。将该序列同时输入给encoder端和decoder端,使用decoder的 top hidden states作为每个token的向量表达,该表达被作为分类问题的输入,输入到分类系统中去。
简而言之,Token classification 是对序列中每一个 token 独立分类;BART 做该任务时,利用 decoder 最后一层的输出作为每个 token 的特征表示,再通过线性层预测每个 token 的标签。
3.3 Sequence Generation Task
由于BART本身就是在sequence-to-sequence的基础上构建并且预训练的,它天然比较适合做序列生成的任务,比如概括性的问答,文本摘要,机器翻译等。
3.4 Machine Translation
具体的做法是将 BART 的 encoder 端的 embedding 层替换成 randomly initialized encoder,新的 encoder 也可以用不同的 vocabulary。
这里可以分为两步:第一步只更新 randomly initialized encoder + BART positional embedding + BART 的 encoder 第一层的 self-attention 输入映射矩阵。第二步更新全部参数,但是只训练很少的几轮。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)