矩池云17区硬核上线:RTX 4090 + AMD EPYC 48核,重塑本地化大模型推理与开发范式
各位AI开发者、极客朋友们,久等了!
矩池云基础设施迎来重要迭代,17区正式投入运营。本次扩容不仅带来了充足的算力储备,更在硬件选型与异构计算架构上进行了深度优化,旨在为高并发推理、复杂Agent编排及大规模模型微调提供极致的底层支撑。
01硬件架构解析:打破IO与并行计算瓶颈
17区的核心算力节点采用了“顶级消费级GPU + 服务器级多核CPU”的黄金异构组合,彻底解决了传统算力租赁中常见的CPU IO瓶颈与PCIe带宽限制。
GPU算力单元:NVIDIA GeForce RTX 4090 (24GB VRAM)基于NVIDIA Ada Lovelace架构,RTX 4090 拥有16384个CUDA核心与24GB GDDR6X高速显存。在FP16/BF16混合精度训练与推理场景下,其算力表现足以支撑7B至70B参数量级的主流开源大模型(如Llama 3、Qwen系列)进行全量微调或高并发推理。同时,其在Stable Diffusion等AIGC图像生成任务中的张量核心加速能力,能显著缩短端到端的生成延迟。
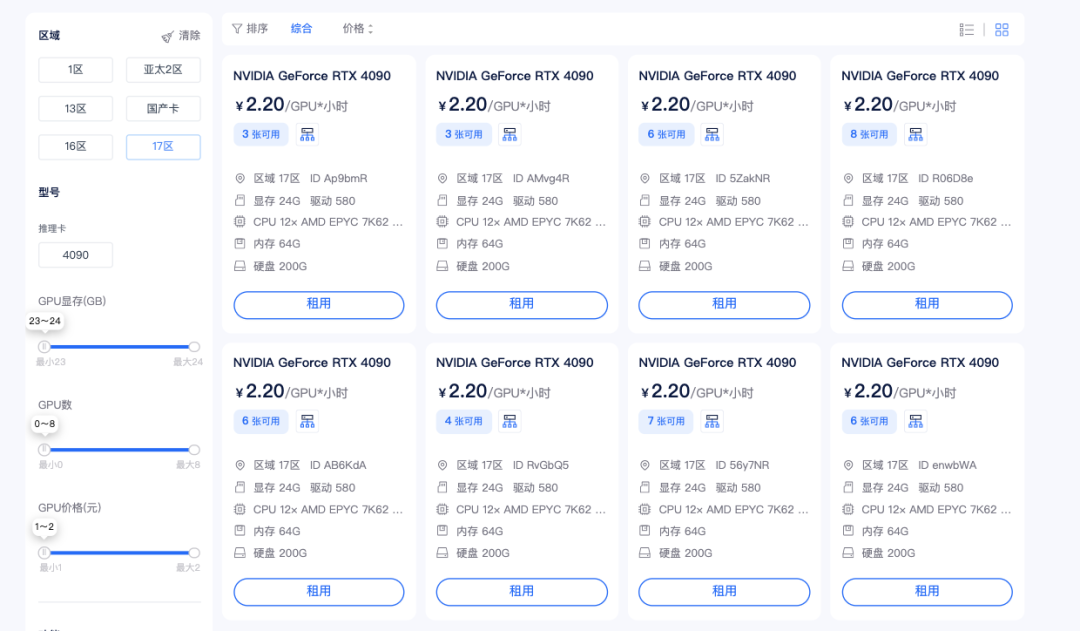
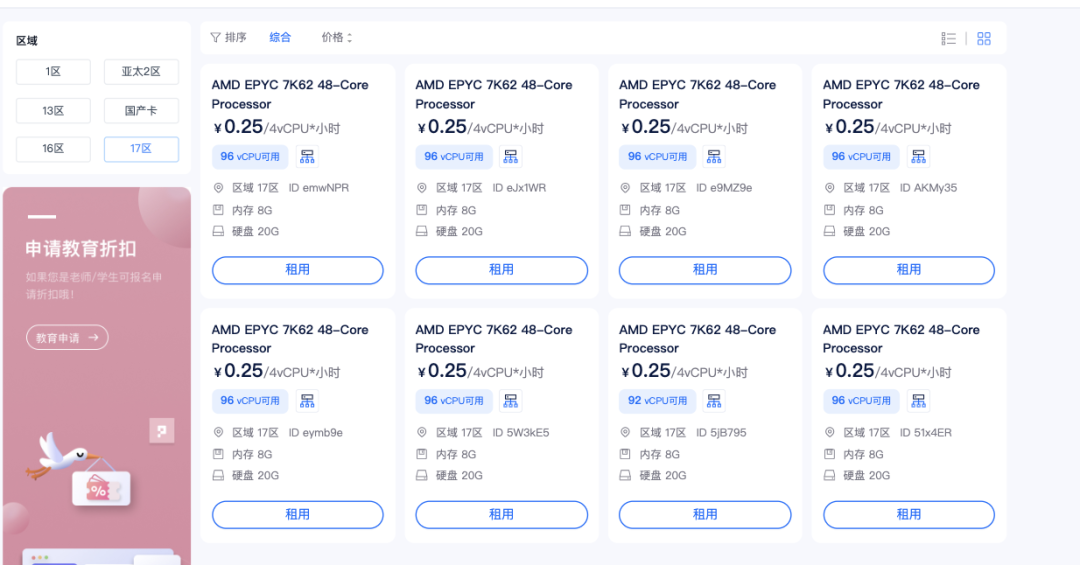
CPU算力单元:AMD EPYC 48-Core Processor区别于常规算力平台搭配的低频至强处理器,17区全系标配AMD EPYC(霄龙)48核处理器。凭借Zen架构的高IPC性能与庞大的L3缓存,该CPU在数据预处理(ETL)、向量化检索以及多实例并发场景下表现卓越。48个物理核心能有效避免在大规模Token处理或复杂逻辑编排时出现CPU满载而GPU空转的“木桶效应”,确保整机算力均衡释放。
02模型服务:异构算力开启“云端+本地”新范式
在 17 区,我们不仅提供纯粹的算力,更通过热门模型 Token 服务与异构计算优化,彻底打通了从云端 API 到本地环境的壁垒:
1. 异构加速本地化训练:17 区利用 AMD EPYC + NVIDIA 4090 的异构架构,支持开发者将云端闭源大模型的生成能力(通过 Token 服务)与本地实例的微调能力相结合。可以利用 Token 服务获取的高质量合成数据,在本地 4090 环境中进行领域知识的 SFT(监督微调) 或 LoRA 训练。这种“以云带本”的异构模式,极大地降低了数据预处理的门槛。
2. 极速响应的 Token 服务:我们深度整合了主流闭源大模型的 API 接口。在矩池云实例内部调用,可享受专属网络链路加持,实现极低延迟的 Token 响应。这对于需要频繁调用大模型进行 RAG(检索增强生成)测试或 Agent 逻辑调度的开发者来说,体验将更上一层楼。
3. 显存优化与本地化部署:通过异构资源分配,将重负载的任务(如复杂逻辑推理)交给 Token 服务处理,而将实时性要求高、涉及私有数据的模块部署在 17 区的本地 4090 上。这种灵活的部署方式,既利用了 4090 的 24GB 显存优势,又避免了单一算力源的瓶颈,实现了真正意义上的私有化、安全化模型训练与应用。
为什么 17 区的“异构”更适合你?
-
打破孤岛: 不再需要在 API 调用和 GPU 算力机之间来回切换环境,一站式完成从数据获取到模型产出的全流程。
-
成本最优: 利用 Token 服务处理非核心逻辑,将宝贵的 4090 算力资源集中在最核心的参数训练与权重优化上。
-
私有化保障: 在 17 区的安全沙箱环境中,您的训练数据与本地化部署的模型权重始终处于受控状态。
03镜像生态:主流工具“开箱即用”
为降低开发者的环境配置熵增,17区已预置并深度优化了当前最前沿的AI Agent与编程辅助框架镜像,开箱即用,开箱即跑:
1. OpenClaw 与 Hermes: 专为 AI Agent 开发者准备。OpenClaw 的高效执行框架配合 Hermes 的自动化能力,让构建多智能体协作系统变得易如反掌。
2. Claude Code: 深度集成 Anthropic 领先的代码生成能力。通过矩池云预置的镜像,您可以直接在云端终端调用 Claude Code 进行辅助编程、Bug 修复和系统优化。
3. OpenCode: 针对开源代码大模型优化的环境,支持多种代码助手工具,提升开发者的工程效率。
即刻部署,释放算力潜能。
🎁 首次登录礼:凡是新用户首次登录矩池云平台,即可直接领取 5 元算力优惠券! 无需繁琐手续,登录即领,让您零成本开启 4090 极致体验。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)