【SpringBoot 3.x 第142节】多模型路由:OpenAI、Azure、Ollama 混合部署,一文带你搞透!

🏆本文收录于《滚雪球学SpringBoot 3.x》,专门攻坚指数提升,本年度国内最系统+最专业+最详细(永久更新)。
该专栏致力打造最硬核 SpringBoot3 从零基础到进阶系列学习内容,🚀均为全网独家首发,打造精品专栏,专栏持续更新中…欢迎大家订阅持续学习。 如果想快速定位学习,可以看这篇【SpringBoot3教程导航帖】,你想学习的都被收集在内,快速投入学习!!两不误。
若还想学习更多,可直接订阅 《Spring Boot实战合集》,一次订阅,持续学习,后续更新内容无需重复付费,适合长期收藏与系统进阶。
演示环境说明:
- 开发工具:IDEA 2021.3
- JDK版本: JDK 17(推荐使用 JDK 17 或更高版本,因为 Spring Boot 3.x 系列要求 Java 17,Spring Boot 3.5.4 基于 Spring Framework 6.x 和 Jakarta EE 9,它们都要求至少 JDK 17。)
- Spring Boot版本:3.5.4(于25年7月24日发布)
- Maven版本:3.8.2 (或更高)
- Gradle:(如果使用 Gradle 构建工具的话):推荐使用 Gradle 7.5 或更高版本,确保与 JDK 17 兼容。
- 操作系统:Windows 11
全文目录:
- 1. 为什么要做多模型路由,而不是只接一个大模型?
- 2. Spring Boot 3.x 为什么适合承担 AI 应用基础设施层?
- 3. OpenAI、Azure OpenAI、Ollama 三类模型服务的能力差异
- 4. 混合部署的目标:成本、速度、准确率与可用性的平衡
- 5. 总体架构设计:从单一供应商调用走向统一抽象层
- 6. 核心概念:模型、供应商、路由策略、降级链路、观测指标
- 7. 项目实战一:搭建一个可运行的 Spring Boot 3.x 多模型路由项目
- 8. 项目实战二:定义统一请求与统一响应模型
- 9. 项目实战三:设计供应商抽象层与适配器模式
- 10. 项目实战四:接入 OpenAI
- 11. 项目实战五:接入 Azure OpenAI
- 12. 项目实战六:接入 Ollama 本地模型
- 13. 项目实战七:实现基于成本、速度、准确率的动态路由
- 14. 项目实战八:实现故障切换与自动重试
- 15. 项目实战九:本地模型与云模型组合实践
- 16. 项目实战十:可观测性、日志链路与指标监控
- 17. 使用 Resilience4j 增强重试、熔断与超时控制
- 18. Controller 层:对外暴露统一接口
- 19. 接口调用示例与测试案例
- 20. 进一步升级:把规则写成可配置而不是硬编码
- 21. 成本、速度、准确率三维路由如何进一步量化
- 22. 供应商抽象层的进一步升级:支持能力标签而非仅按品牌路由
- 23. 安全设计:密钥隔离、限流、审计与敏感信息控制
- 24. 性能优化:连接池、并发、缓存与流式输出
- 25. 常见问题与排错清单
- 26. 生产落地建议:如何把 Demo 演进为真实可用系统
- 27. 专栏总结:从零基础到多模型治理的完整认知链路
- 28. 给读者的扩展练习
- 29. 附:一个完整可运行的 application.yml 示例
- 30. 结语
- 31. 从零开始补齐基础:为什么本篇必须建立在 Spring Boot 3.x 语境下
- 32. 多模型路由不是“调接口”,而是“模型治理”
- 33. 能力差异的更细粒度拆解:不要只看“哪个模型更强”
- 34. 模型分层方法论:低成本层、标准层、高精度层、本地隐私层
- 35. 更贴近生产的 Provider 注册中心设计
- 36. 加入健康检查:路由前先识别“谁现在能用”
- 37. 路由前置处理:Prompt 规范化、长度估算与任务识别
- 38. 结构化输出案例:让模型返回 JSON,而不是随意文本
- 39. 再加一个重要案例:按任务级别控制“先快后准”
- 40. AOP 日志切面:统一记录请求、路由与结果摘要
- 41. 单元测试:先保证路由规则可靠,再考虑模型输出质量
- 42. 服务层测试:验证 fallback 是否按预期生效
- 43. 本地运行与 Docker Compose 组合实践
- 44. 一个更完整的请求生命周期图
- 45. 文章级别的深入解释:成本、速度、准确率为什么总会互相拉扯?
- 46. 让文章更落地:给出几种典型业务路由策略模板
- 47. 生产环境中的组织协作建议:平台、业务、运维如何分工
- 48. 再补一个增强案例:基于请求长度和复杂度的路由
- 49. 给零基础读者的认知提醒:不要把“本地模型”想得过于理想化
- 50. 给零基础读者的认知提醒:不要把“云模型”想得过于万能
- 51. 面向未来扩展:如果要再接入 Anthropic、Gemini、DeepSeek,该怎么办?
- 52. 本文终极总结:为什么这是一篇真正从 0 到 1 再到 1 到 N 的 Spring Boot 3.x AI 工程文章?
1. 为什么要做多模型路由,而不是只接一个大模型?
很多初学者在接触 AI 应用开发时,第一反应往往是:
- 选一个模型;
- 拿到 API Key;
- 调一个接口;
- 把结果返回给前端。
从入门角度看,这没有问题。但只要系统进入真实业务阶段,你很快会遇到几个现实问题:
第一,不同模型的能力差异非常明显。有的模型长于通用问答,有的模型更适合结构化抽取,有的模型在代码生成方面表现更好,还有些本地模型更适合处理不方便上传到公有云的私有数据。
第二,不同供应商的价格差异非常大。在高并发场景下,如果你把所有请求都交给最高性能、最高价格的模型,成本往往会迅速失控。
第三,不同模型的响应速度不一样。有时用户只是发起一个简单的分类、改写、摘要请求,没有必要让顶级模型出场;一个更轻量的模型在 1 秒内返回结果,体验反而更好。
第四,供应商并不总是稳定。云端模型可能偶发限流、区域故障、账号额度用尽、网络抖动、返回格式变化等问题。只接一个供应商,意味着一旦它出问题,你的业务就会整体不可用。
第五,企业越来越重视混合部署。一部分请求走云模型,一部分敏感任务走本地模型,一部分低成本任务走开源模型,这是越来越常见的架构选择。
所以,多模型路由并不是“高级玩法”,而是 AI 系统逐步走向工程化后的必然结果。你可以把它理解为:
- 对上:向业务暴露统一 AI 能力接口;
- 对下:屏蔽不同模型供应商的差异;
- 对中:根据策略自动选择最合适的模型执行任务。
也就是说,多模型路由的本质不是多接几个接口,而是建立一层“模型选择与治理中台”。
2. Spring Boot 3.x 为什么适合承担 AI 应用基础设施层?
2.1 Spring Boot 3.x 的技术基础升级
在写这篇文章之前,我们先要明确:为什么这个主题必须建立在 Spring Boot 3.x 的技术基础上,而不是泛泛讲 Java Web?
Spring Boot 3.x 相比 2.x,有几个非常关键的基础变化:
- 基于 Spring Framework 6;
- 最低要求 Java 17;
- 全面切换到 Jakarta EE 命名空间;
- 对 AOT、原生编译、现代化应用部署支持更好;
- 与现代观测体系(Micrometer、Observation)集成更自然。
这些升级对于 AI 应用并不是“可有可无”的背景知识,而是直接影响我们如何做一个现代化的模型路由服务。
2.2 为什么 AI 网关服务特别适合 Spring Boot 3.x?
AI 路由层本质上是一个典型的中台服务,它有这些特点:
- 大量 HTTP 调用外部模型接口;
- 对超时、重试、熔断很敏感;
- 需要统一配置与环境隔离;
- 需要良好的监控与链路追踪;
- 需要快速扩展不同供应商适配器;
- 需要一定程度的响应式支持和异步能力;
- 后续可能需要容器化、云原生部署甚至 GraalVM 原生镜像。
Spring Boot 3.x 刚好在这些方向上都有很好的工程基础,因此它非常适合作为多模型路由系统的后端基础框架。
2.3 与 Spring AI 的关系
很多同学会问:既然有 Spring AI,为什么还要自己做统一抽象层?
答案是:
- Spring AI 可以帮助我们简化模型接入;
- 但 你的业务级路由策略、供应商治理、成本控制、故障切换规则,仍然需要自己设计。
你可以把 Spring AI 理解为“连接模型的工具层”,而本文要做的是“在工具层之上,再构建一层业务可控的模型治理层”。
3. OpenAI、Azure OpenAI、Ollama 三类模型服务的能力差异
这一节非常关键。做路由之前,你必须先理解“被路由的对象”到底有什么不同。
3.1 OpenAI 的特点
OpenAI 通常具备以下特点:
- 通用能力强;
- 模型生态成熟;
- 文本理解、生成、工具调用支持较完善;
- 上手快,文档和社区生态丰富;
- 对外部创业产品、PoC、国际化业务非常友好。
但它也有明显现实问题:
- 成本相对较高;
- 某些场景下网络链路和区域问题较敏感;
- 企业内部合规要求可能限制直接使用公有云模型;
- 某些国家或企业网络环境访问不稳定。
因此,在路由策略里,OpenAI 往往适合作为:
- 高质量默认模型;
- 高准确率任务的主选项;
- 本地模型结果不理想时的升级线路;
- 云端高质量兜底模型。
3.2 Azure OpenAI 的特点
Azure OpenAI 从能力上看,本质上仍然是微软云上托管的大模型服务,但工程使用体验与原生 OpenAI API 并不完全相同。
它的优势通常包括:
- 更适合企业级接入;
- 与 Azure 生态整合较深;
- 更方便结合企业网络、身份、区域与合规体系;
- 在某些企业组织内审批和采购路径更顺畅。
它的挑战包括:
- 接口路径和认证方式与 OpenAI 原生接口存在差异;
- 模型部署名称、API 版本管理需要额外关注;
- 迁移时容易因为 endpoint、deploymentName、api-version 等细节导致错误。
所以在统一抽象时,我们不能想当然地把 Azure OpenAI 完全当作 OpenAI 的一个 URL 替换。它是相似但不相同的供应商实现。
3.3 Ollama 的特点
Ollama 是很多开发者接触本地大模型的第一站,因为它让本地模型运行这件事变得非常简单。你可以把它看作一个“本地模型运行与管理器”,常见优点包括:
- 部署简单,适合本地和内网环境;
- 数据不出本机或局域网,适合隐私敏感场景;
- 成本可控,没有按 token 持续计费压力;
- 适合做离线开发、实验、内网助手。
但它的局限也很明显:
- 模型性能依赖本地机器资源;
- 推理速度可能不如云端高性能服务;
- 不同开源模型质量差异大;
- 上下文长度、工具调用、结构化输出稳定性不一定和商业模型一致;
- 运维层面需要自己负责机器资源、模型管理、版本管理。
因此,Ollama 在混合部署里非常适合:
- 低成本批量任务;
- 内部敏感文本处理;
- 简单摘要、分类、改写;
- 开发测试环境;
- 云端模型的前置过滤或本地预处理。
3.4 三者能力对比思路
这里不给你做“绝对排名”,而是给你一个工程视角的判断维度:
- 准确率:复杂推理、复杂指令理解、代码生成的可靠性;
- 速度:首 token 时间与完整响应时间;
- 成本:按请求、按 token、按设备资源的综合成本;
- 可用性:供应商稳定性、可达性、限流风险;
- 合规性:是否适合敏感数据、是否满足企业要求;
- 可控性:是否可本地部署、是否便于统一治理;
- 扩展性:是否支持流式、结构化输出、工具调用等。
在真实项目中,没有哪个模型会在所有维度上都最优。这正是多模型路由存在的价值。
4. 混合部署的目标:成本、速度、准确率与可用性的平衡
很多文章在讲多模型时,只停留在“支持多个模型供应商”。这还远远不够。
真正成熟的混合部署应该回答下面这几个问题:
- 什么请求应该优先走低成本模型?
- 什么请求应该优先走高质量模型?
- 请求失败时是否自动切换模型?
- 本地模型什么时候该优先使用?
- 如何避免简单任务误用昂贵模型?
- 如何避免高价值任务被低质量模型误伤?
这几个问题最终会收敛到三个核心目标:
4.1 成本控制
成本控制并不是“一味用最便宜的模型”,而是在满足质量目标的前提下,让单位请求成本最优。
例如:
- 用户只是让系统“把一段文案变得更口语化”,本地模型完全可以胜任;
- 用户要“根据一份复杂合同提炼法律风险”,你可能更愿意走高质量云模型;
- 用户发起的是批量摘要任务,可以使用分层策略,先本地处理,再对低置信结果升级到云端。
4.2 响应速度
用户体验往往对“感知时延”非常敏感。并不是每个任务都需要“最聪明”的模型,有时更快返回一个足够好的结果,体验更佳。
因此我们要建立这样的思想:
- 快速任务优先低延迟模型;
- 实时交互任务优先稳定、快响应模型;
- 非实时任务允许走慢但便宜的线路。
4.3 准确率与稳定性
当任务复杂度提高时,模型质量往往比几百毫秒的延迟更加重要。尤其是:
- 代码生成;
- 结构化抽取;
- 报告生成;
- 敏感业务问答;
- 复杂工作流中的关键步骤。
这时就应当让路由系统具备“按任务等级分配模型”的能力。
4.4 高可用与故障切换
单个模型供应商不可避免会遇到:
- 限流;
- 超时;
- 认证问题;
- 区域不可达;
- 临时服务波动。
一旦你的系统有统一抽象层,故障切换就不再是“改代码换接口”,而是“改策略自动切流”。这就是架构价值。
5. 总体架构设计:从单一供应商调用走向统一抽象层
先来看一张总体架构图。
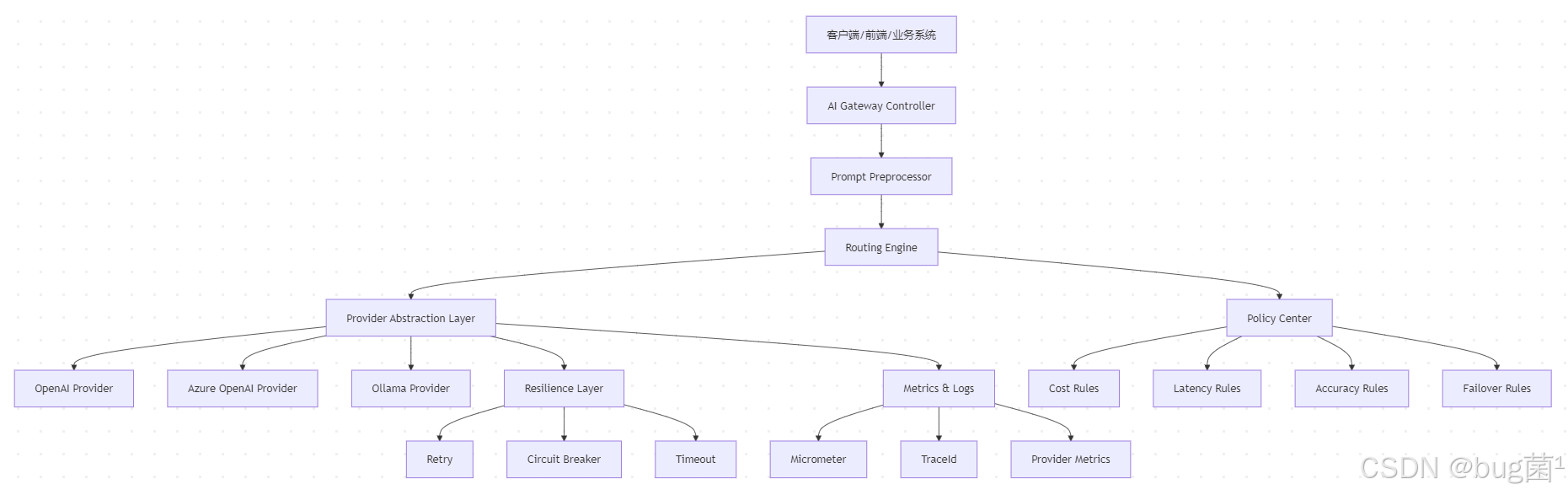
从这张图里你可以看到,系统并不是 Controller 直接调用某个模型,而是多了一整层治理结构。
这层结构的核心职责包括:
- 接收统一请求;
- 根据路由规则选择供应商;
- 在异常情况下自动故障切换;
- 记录每次调用的模型、耗时、失败原因与成本估算;
- 屏蔽不同供应商之间的协议差异。
这其实就是典型的“面向业务的统一抽象 + 面向供应商的适配器实现”。
6. 核心概念:模型、供应商、路由策略、降级链路、观测指标
在写代码之前,我们必须先统一几个概念,不然后面很容易把系统做乱。
6.1 模型(Model)
模型是具体执行推理任务的能力实体。例如:
- OpenAI 某个聊天模型;
- Azure 上部署的某个模型实例;
- Ollama 里运行的 qwen、llama、mistral 等模型。
模型的关注点是“能力本身”。
6.2 供应商(Provider)
供应商是提供模型访问能力的服务实现。例如:
- OpenAI;
- Azure OpenAI;
- Ollama。
供应商的关注点是“调用方式、认证方式、地址路径、能力边界”。
6.3 路由策略(Routing Policy)
路由策略是选择模型的规则集合。比如:
- 简单任务优先 Ollama;
- 复杂任务优先 OpenAI;
- 企业网络内优先 Azure;
- 夜间批处理优先低成本模型;
- 本地模型失败后切云端模型。
6.4 降级链路(Fallback Chain)
降级链路表示主模型失败后,应该按什么顺序尝试备用模型。例如:
- 首选 Ollama -> 失败转 Azure -> 再失败转 OpenAI;
- 首选 OpenAI -> 限流时切 Azure;
- 首选高质量云模型 -> 预算超限后切本地模型。
6.5 观测指标(Observability Metrics)
只有能观测,才能治理。最少要记录这些指标:
- provider
- model
- success/failure
- latency
- fallbackCount
- timeoutCount
- estimatedCost
- promptLength
- responseLength
这些指标将决定你后续如何优化策略。
7. 项目实战一:搭建一个可运行的 Spring Boot 3.x 多模型路由项目
下面我们进入实战。为了保证文章中的案例可运行,我们先定义一个清晰的项目结构。
7.1 技术选型
本项目采用如下技术:
- Java 17
- Spring Boot 3.3.x(你也可以使用 3.2.x 或 3.4.x,思路一致)
- spring-boot-starter-web
- spring-boot-starter-validation
- spring-boot-starter-actuator
- spring-boot-starter-aop
- resilience4j-spring-boot3
- micrometer-registry-prometheus(可选)
- lombok(可选,不强依赖)
为了更容易理解,本文主要使用清晰的 Java POJO 写法,不大量依赖复杂框架魔法。
7.2 Maven 依赖
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.3.5</version>
<relativePath/>
</parent>
<groupId>com.example</groupId>
<artifactId>multi-model-router</artifactId>
<version>1.0.0</version>
<name>multi-model-router</name>
<description>Spring Boot 3.x 多模型路由示例</description>
<properties>
<java.version>17</java.version>
<resilience4j.version>2.2.0</resilience4j.version>
</properties>
<dependencies>
<!-- Web 开发依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 参数校验 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
<!-- 监控与健康检查 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<!-- AOP,可用于统一日志与切面观测 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
<!-- Resilience4j:重试、熔断、限流、隔离 -->
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-spring-boot3</artifactId>
<version>${resilience4j.version}</version>
</dependency>
<!-- Prometheus 指标导出,可选 -->
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
<!-- 简化样板代码,可选 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- 测试依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
代码解析
这份 pom.xml 有几个重点:
- Java 17 是 Spring Boot 3.x 的基础要求,不要再用 Java 8/11 的旧思路。
- 我们引入了
actuator,因为 AI 路由服务上线后必须有健康检查和指标。 - 我们引入
resilience4j-spring-boot3,因为多模型路由一定会涉及超时、重试、熔断等稳定性治理。 - 没有一开始就引入太多复杂依赖,是为了让你先掌握“结构”,再逐步叠加能力。
7.3 项目目录建议
src/main/java/com/example/router
├── MultiModelRouterApplication.java
├── controller
│ └── ChatController.java
├── model
│ ├── ChatRequest.java
│ ├── ChatResponse.java
│ ├── Message.java
│ ├── ProviderType.java
│ ├── TaskType.java
│ └── RoutingDecision.java
├── config
│ ├── AiProviderProperties.java
│ ├── HttpClientConfig.java
│ └── ResilienceConfig.java
├── provider
│ ├── AiProvider.java
│ ├── AbstractAiProvider.java
│ ├── OpenAiProvider.java
│ ├── AzureOpenAiProvider.java
│ └── OllamaProvider.java
├── router
│ ├── RoutingEngine.java
│ ├── RoutingRule.java
│ └── DefaultRoutingEngine.java
├── service
│ ├── ChatService.java
│ └── FallbackService.java
├── metrics
│ └── AiMetricsRecorder.java
└── exception
├── ProviderInvokeException.java
└── GlobalExceptionHandler.java
这个目录结构有一个核心理念:
- model:定义统一的数据结构;
- provider:屏蔽不同供应商差异;
- router:只负责做选择;
- service:组织业务流程;
- metrics:记录观测信息;
- config:做环境配置与基础 Bean 装配。
请注意,我们没有把“路由逻辑”写进 Controller,也没有把“HTTP 调用逻辑”塞进 Service。这样的分层会让代码更加清晰,扩展新供应商也不会混乱。
8. 项目实战二:定义统一请求与统一响应模型
在多模型架构里,第一件事不是接 OpenAI 接口,而是先定义自己的统一协议。
8.1 Message 模型
package com.example.router.model;
/**
* 对话消息模型
* 用于统一表示用户消息、系统消息、助手消息
*/
public class Message {
/**
* 角色,例如 system、user、assistant
*/
private String role;
/**
* 消息内容
*/
private String content;
public Message() {
}
public Message(String role, String content) {
this.role = role;
this.content = content;
}
public String getRole() {
return role;
}
public void setRole(String role) {
this.role = role;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
代码解析
为什么要自己定义 Message?因为不同供应商的消息结构并不完全一致,但对业务系统来说,“一条消息”无非就是角色和内容。统一建模后,后续适配器只需要负责“转换”,而不是让上层业务知道每个厂商的 JSON 长什么样。
8.2 TaskType 枚举
package com.example.router.model;
/**
* 任务类型枚举
* 用于帮助路由引擎决定应该使用哪个模型
*/
public enum TaskType {
/**
* 一般聊天问答
*/
GENERAL_CHAT,
/**
* 文本摘要
*/
SUMMARY,
/**
* 文本分类
*/
CLASSIFICATION,
/**
* 代码生成
*/
CODE_GENERATION,
/**
* 结构化抽取
*/
STRUCTURED_EXTRACTION,
/**
* 私有数据分析
*/
PRIVATE_DATA_ANALYSIS,
/**
* 高精度复杂任务
*/
HIGH_ACCURACY
}
代码解析
很多人做 AI 接入时只传一个 prompt,没有任务分类,这会导致路由策略非常难做。因为系统根本不知道这次调用属于什么场景。
所以,建议你从一开始就为请求增加 taskType。这样,系统才能根据任务类型去做有根据的路由。
8.3 ProviderType 枚举
package com.example.router.model;
/**
* 模型供应商类型
*/
public enum ProviderType {
/**
* OpenAI
*/
OPENAI,
/**
* Azure OpenAI
*/
AZURE_OPENAI,
/**
* Ollama 本地模型
*/
OLLAMA
}
8.4 ChatRequest 请求对象
package com.example.router.model;
import jakarta.validation.constraints.NotEmpty;
import jakarta.validation.constraints.NotNull;
import java.util.List;
/**
* 统一聊天请求对象
*/
public class ChatRequest {
/**
* 对话消息列表
*/
@NotEmpty(message = "消息列表不能为空")
private List<Message> messages;
/**
* 任务类型,用于路由决策
*/
@NotNull(message = "任务类型不能为空")
private TaskType taskType;
/**
* 是否优先低成本
*/
private boolean preferLowCost;
/**
* 是否优先低延迟
*/
private boolean preferLowLatency;
/**
* 是否包含敏感数据
*/
private boolean sensitive;
/**
* 可选:指定供应商,若为空则由路由引擎自动决策
*/
private ProviderType provider;
public List<Message> getMessages() {
return messages;
}
public void setMessages(List<Message> messages) {
this.messages = messages;
}
public TaskType getTaskType() {
return taskType;
}
public void setTaskType(TaskType taskType) {
this.taskType = taskType;
}
public boolean isPreferLowCost() {
return preferLowCost;
}
public void setPreferLowCost(boolean preferLowCost) {
this.preferLowCost = preferLowCost;
}
public boolean isPreferLowLatency() {
return preferLowLatency;
}
public void setPreferLowLatency(boolean preferLowLatency) {
this.preferLowLatency = preferLowLatency;
}
public boolean isSensitive() {
return sensitive;
}
public void setSensitive(boolean sensitive) {
this.sensitive = sensitive;
}
public ProviderType getProvider() {
return provider;
}
public void setProvider(ProviderType provider) {
this.provider = provider;
}
}
代码解析
这个请求对象已经开始体现“路由”思维了。
taskType:告诉系统任务性质;preferLowCost:告诉系统用户或业务方更关注成本;preferLowLatency:告诉系统是否要优先快;sensitive:告诉系统是否涉及敏感数据;provider:允许手动指定,便于调试、A/B 测试、灰度验证。
这比只传一个 prompt 专业得多。
8.5 ChatResponse 响应对象
package com.example.router.model;
/**
* 统一响应对象
*/
public class ChatResponse {
/**
* 最终输出内容
*/
private String content;
/**
* 实际使用的供应商
*/
private ProviderType provider;
/**
* 实际使用的模型名称
*/
private String model;
/**
* 是否发生了故障切换
*/
private boolean fallback;
/**
* 响应耗时,单位毫秒
*/
private long latencyMs;
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public ProviderType getProvider() {
return provider;
}
public void setProvider(ProviderType provider) {
this.provider = provider;
}
public String getModel() {
return model;
}
public void setModel(String model) {
this.model = model;
}
public boolean isFallback() {
return fallback;
}
public void setFallback(boolean fallback) {
this.fallback = fallback;
}
public long getLatencyMs() {
return latencyMs;
}
public void setLatencyMs(long latencyMs) {
this.latencyMs = latencyMs;
}
}
代码解析
响应里必须体现:
- 最终内容;
- 实际使用的供应商;
- 实际模型;
- 是否降级过;
- 耗时。
很多系统只返回 content,这样做虽然简单,但在排查路由问题和用户体验问题时几乎没有帮助。
9. 项目实战三:设计供应商抽象层与适配器模式
这一节是整篇文章的核心之一。统一抽象层做得好不好,决定了你的多模型系统能不能长期维护。
9.1 统一 Provider 接口
package com.example.router.provider;
import com.example.router.model.ChatRequest;
import com.example.router.model.ChatResponse;
import com.example.router.model.ProviderType;
/**
* AI 供应商统一接口
* 所有模型供应商都要实现此接口
*/
public interface AiProvider {
/**
* 当前供应商类型
*
* @return 供应商枚举
*/
ProviderType providerType();
/**
* 调用模型完成聊天任务
*
* @param request 统一请求对象
* @return 统一响应对象
*/
ChatResponse chat(ChatRequest request);
/**
* 当前供应商是否可用
*
* @return true 表示可用,false 表示不可用
*/
boolean isAvailable();
/**
* 当前供应商默认模型名称
*
* @return 模型名称
*/
String defaultModel();
}
代码解析
这个接口非常重要。它意味着:
- 上层业务只跟
AiProvider打交道; - 不需要关心 OpenAI 还是 Azure 还是 Ollama;
- 增加新供应商时,只需新增一个实现类;
- 路由引擎只负责选哪个 Provider,不负责具体怎么调。
这正是典型的适配器模式思想。
9.2 抽象父类 AbstractAiProvider
package com.example.router.provider;
import com.example.router.exception.ProviderInvokeException;
import com.example.router.model.ChatRequest;
import com.example.router.model.ChatResponse;
/**
* 供应商抽象父类
* 抽取公共的异常处理、耗时统计等逻辑
*/
public abstract class AbstractAiProvider implements AiProvider {
@Override
public ChatResponse chat(ChatRequest request) {
long start = System.currentTimeMillis();
try {
ChatResponse response = doChat(request);
response.setLatencyMs(System.currentTimeMillis() - start);
return response;
} catch (Exception e) {
throw new ProviderInvokeException(
"调用供应商失败,provider=" + providerType() + ", message=" + e.getMessage(), e);
}
}
/**
* 子类实现真正的模型调用逻辑
*
* @param request 请求对象
* @return 响应对象
*/
protected abstract ChatResponse doChat(ChatRequest request);
}
代码解析
使用抽象父类的好处是:
- 统一统计耗时;
- 统一封装异常;
- 子类只关心具体如何发请求。
这会让你的供应商实现类更加干净。
9.3 自定义异常
package com.example.router.exception;
/**
* 供应商调用异常
*/
public class ProviderInvokeException extends RuntimeException {
public ProviderInvokeException(String message) {
super(message);
}
public ProviderInvokeException(String message, Throwable cause) {
super(message, cause);
}
}
10. 项目实战四:接入 OpenAI
接下来我们实现第一个具体供应商:OpenAI。
10.1 配置对象
package com.example.router.config;
import org.springframework.boot.context.properties.ConfigurationProperties;
/**
* AI 供应商配置属性
*/
@ConfigurationProperties(prefix = "ai")
public class AiProviderProperties {
private Openai openai = new Openai();
private Azure azure = new Azure();
private Ollama ollama = new Ollama();
public Openai getOpenai() {
return openai;
}
public void setOpenai(Openai openai) {
this.openai = openai;
}
public Azure getAzure() {
return azure;
}
public void setAzure(Azure azure) {
this.azure = azure;
}
public Ollama getOllama() {
return ollama;
}
public void setOllama(Ollama ollama) {
this.ollama = ollama;
}
public static class Openai {
private boolean enabled;
private String baseUrl;
private String apiKey;
private String model;
public boolean isEnabled() {
return enabled;
}
public void setEnabled(boolean enabled) {
this.enabled = enabled;
}
public String getBaseUrl() {
return baseUrl;
}
public void setBaseUrl(String baseUrl) {
this.baseUrl = baseUrl;
}
public String getApiKey() {
return apiKey;
}
public void setApiKey(String apiKey) {
this.apiKey = apiKey;
}
public String getModel() {
return model;
}
public void setModel(String model) {
this.model = model;
}
}
public static class Azure {
private boolean enabled;
private String endpoint;
private String apiKey;
private String deploymentName;
private String apiVersion;
public boolean isEnabled() {
return enabled;
}
public void setEnabled(boolean enabled) {
this.enabled = enabled;
}
public String getEndpoint() {
return endpoint;
}
public void setEndpoint(String endpoint) {
this.endpoint = endpoint;
}
public String getApiKey() {
return apiKey;
}
public void setApiKey(String apiKey) {
this.apiKey = apiKey;
}
public String getDeploymentName() {
return deploymentName;
}
public void setDeploymentName(String deploymentName) {
this.deploymentName = deploymentName;
}
public String getApiVersion() {
return apiVersion;
}
public void setApiVersion(String apiVersion) {
this.apiVersion = apiVersion;
}
}
public static class Ollama {
private boolean enabled;
private String baseUrl;
private String model;
public boolean isEnabled() {
return enabled;
}
public void setEnabled(boolean enabled) {
this.enabled = enabled;
}
public String getBaseUrl() {
return baseUrl;
}
public void setBaseUrl(String baseUrl) {
this.baseUrl = baseUrl;
}
public String getModel() {
return model;
}
public void setModel(String model) {
this.model = model;
}
}
}
10.2 开启配置绑定
package com.example.router;
import com.example.router.config.AiProviderProperties;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
/**
* 应用启动类
*/
@SpringBootApplication
@EnableConfigurationProperties(AiProviderProperties.class)
public class MultiModelRouterApplication {
public static void main(String[] args) {
SpringApplication.run(MultiModelRouterApplication.class, args);
}
}
10.3 RestClient 配置
Spring Boot 3.x 推荐使用更现代的 HTTP 客户端能力。这里我们使用 RestClient.Builder。
package com.example.router.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestClient;
/**
* HTTP 客户端配置
*/
@Configuration
public class HttpClientConfig {
/**
* 提供统一的 RestClient.Builder
*
* @return RestClient.Builder
*/
@Bean
public RestClient.Builder restClientBuilder() {
return RestClient.builder();
}
}
10.4 OpenAI Provider 实现
package com.example.router.provider;
import com.example.router.config.AiProviderProperties;
import com.example.router.model.ChatRequest;
import com.example.router.model.ChatResponse;
import com.example.router.model.Message;
import com.example.router.model.ProviderType;
import org.springframework.http.HttpHeaders;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Component;
import org.springframework.web.client.RestClient;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* OpenAI 供应商实现
*/
@Component
public class OpenAiProvider extends AbstractAiProvider {
private final RestClient restClient;
private final AiProviderProperties properties;
public OpenAiProvider(RestClient.Builder restClientBuilder, AiProviderProperties properties) {
this.properties = properties;
this.restClient = restClientBuilder.baseUrl(properties.getOpenai().getBaseUrl()).build();
}
@Override
public ProviderType providerType() {
return ProviderType.OPENAI;
}
@Override
public boolean isAvailable() {
return properties.getOpenai().isEnabled()
&& properties.getOpenai().getApiKey() != null
&& !properties.getOpenai().getApiKey().isBlank();
}
@Override
public String defaultModel() {
return properties.getOpenai().getModel();
}
@Override
protected ChatResponse doChat(ChatRequest request) {
Map<String, Object> body = new HashMap<>();
body.put("model", defaultModel());
body.put("messages", convertMessages(request.getMessages()));
body.put("temperature", 0.3);
Map responseMap = restClient.post()
.uri("/v1/chat/completions")
.contentType(MediaType.APPLICATION_JSON)
.header(HttpHeaders.AUTHORIZATION, "Bearer " + properties.getOpenai().getApiKey())
.body(body)
.retrieve()
.body(Map.class);
String content = extractContent(responseMap);
ChatResponse response = new ChatResponse();
response.setContent(content);
response.setProvider(ProviderType.OPENAI);
response.setModel(defaultModel());
response.setFallback(false);
return response;
}
/**
* 将统一消息转换成 OpenAI 接口需要的格式
*/
private List<Map<String, String>> convertMessages(List<Message> messages) {
return messages.stream()
.map(msg -> {
Map<String, String> map = new HashMap<>();
map.put("role", msg.getRole());
map.put("content", msg.getContent());
return map;
})
.toList();
}
/**
* 从 OpenAI 返回结果中提取内容
*/
private String extractContent(Map responseMap) {
List choices = (List) responseMap.get("choices");
if (choices == null || choices.isEmpty()) {
return "";
}
Map firstChoice = (Map) choices.get(0);
Map message = (Map) firstChoice.get("message");
if (message == null) {
return "";
}
Object content = message.get("content");
return content == null ? "" : content.toString();
}
}
代码解析
这里有几个你必须掌握的点:
- Provider 只处理供应商细节,不关心路由规则。
convertMessages()负责把统一格式转换成 OpenAI 所需格式,这一步就是适配器职责。extractContent()负责解析厂商响应,这样上层永远只拿到统一的ChatResponse。- 这里使用
Map是为了便于初学者快速理解;真实项目中建议定义明确的请求/响应 DTO。
10.5 OpenAI 配置示例
server:
port: 8080
ai:
openai:
enabled: true
base-url: https://api.openai.com
api-key: ${OPENAI_API_KEY:}
model: gpt-4o-mini
azure:
enabled: false
endpoint: ""
api-key: ""
deployment-name: ""
api-version: "2024-10-21"
ollama:
enabled: false
base-url: http://localhost:11434
model: qwen2.5:7b
management:
endpoints:
web:
exposure:
include: health,info,metrics,prometheus
11. 项目实战五:接入 Azure OpenAI
很多开发者第一次接入 Azure OpenAI 时最大的误区是:把它当作“换个域名的 OpenAI”。这并不准确。
Azure OpenAI 的典型路径包含:
- endpoint
- deploymentName
- api-version
- api-key
因此实现类应该单独处理。
11.1 Azure Provider 实现
package com.example.router.provider;
import com.example.router.config.AiProviderProperties;
import com.example.router.model.ChatRequest;
import com.example.router.model.ChatResponse;
import com.example.router.model.Message;
import com.example.router.model.ProviderType;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Component;
import org.springframework.web.client.RestClient;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* Azure OpenAI 供应商实现
*/
@Component
public class AzureOpenAiProvider extends AbstractAiProvider {
private final RestClient restClient;
private final AiProviderProperties properties;
public AzureOpenAiProvider(RestClient.Builder restClientBuilder, AiProviderProperties properties) {
this.properties = properties;
this.restClient = restClientBuilder.baseUrl(properties.getAzure().getEndpoint()).build();
}
@Override
public ProviderType providerType() {
return ProviderType.AZURE_OPENAI;
}
@Override
public boolean isAvailable() {
return properties.getAzure().isEnabled()
&& properties.getAzure().getApiKey() != null
&& !properties.getAzure().getApiKey().isBlank()
&& properties.getAzure().getDeploymentName() != null
&& !properties.getAzure().getDeploymentName().isBlank();
}
@Override
public String defaultModel() {
return properties.getAzure().getDeploymentName();
}
@Override
protected ChatResponse doChat(ChatRequest request) {
Map<String, Object> body = new HashMap<>();
body.put("messages", convertMessages(request.getMessages()));
body.put("temperature", 0.3);
String uri = "/openai/deployments/" + defaultModel() + "/chat/completions?api-version="
+ properties.getAzure().getApiVersion();
Map responseMap = restClient.post()
.uri(uri)
.contentType(MediaType.APPLICATION_JSON)
.header("api-key", properties.getAzure().getApiKey())
.body(body)
.retrieve()
.body(Map.class);
String content = extractContent(responseMap);
ChatResponse response = new ChatResponse();
response.setContent(content);
response.setProvider(ProviderType.AZURE_OPENAI);
response.setModel(defaultModel());
response.setFallback(false);
return response;
}
/**
* 将统一消息转换成 Azure OpenAI 接口需要的格式
*/
private List<Map<String, String>> convertMessages(List<Message> messages) {
return messages.stream()
.map(msg -> {
Map<String, String> map = new HashMap<>();
map.put("role", msg.getRole());
map.put("content", msg.getContent());
return map;
})
.toList();
}
/**
* 提取模型输出内容
*/
private String extractContent(Map responseMap) {
List choices = (List) responseMap.get("choices");
if (choices == null || choices.isEmpty()) {
return "";
}
Map firstChoice = (Map) choices.get(0);
Map message = (Map) firstChoice.get("message");
if (message == null) {
return "";
}
Object content = message.get("content");
return content == null ? "" : content.toString();
}
}
代码解析
这里最值得你关注的是 URI 拼接逻辑。Azure OpenAI 的调用路径中,deploymentName 不是一个普通的模型名参数,而是 URL 路径的一部分。
这也是为什么我们在统一抽象层里既要保留“模型名称”的概念,又要允许不同供应商用不同形式去表达。
12. 项目实战六:接入 Ollama 本地模型
相比云端服务,Ollama 的接入方式通常更直接,但也要考虑本地不可用、模型未拉取、机器资源不足等问题。
12.1 Ollama Provider 实现
package com.example.router.provider;
import com.example.router.config.AiProviderProperties;
import com.example.router.model.ChatRequest;
import com.example.router.model.ChatResponse;
import com.example.router.model.Message;
import com.example.router.model.ProviderType;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Component;
import org.springframework.web.client.RestClient;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* Ollama 本地模型供应商实现
*/
@Component
public class OllamaProvider extends AbstractAiProvider {
private final RestClient restClient;
private final AiProviderProperties properties;
public OllamaProvider(RestClient.Builder restClientBuilder, AiProviderProperties properties) {
this.properties = properties;
this.restClient = restClientBuilder.baseUrl(properties.getOllama().getBaseUrl()).build();
}
@Override
public ProviderType providerType() {
return ProviderType.OLLAMA;
}
@Override
public boolean isAvailable() {
return properties.getOllama().isEnabled()
&& properties.getOllama().getBaseUrl() != null
&& !properties.getOllama().getBaseUrl().isBlank();
}
@Override
public String defaultModel() {
return properties.getOllama().getModel();
}
@Override
protected ChatResponse doChat(ChatRequest request) {
Map<String, Object> body = new HashMap<>();
body.put("model", defaultModel());
body.put("messages", convertMessages(request.getMessages()));
body.put("stream", false);
Map responseMap = restClient.post()
.uri("/api/chat")
.contentType(MediaType.APPLICATION_JSON)
.body(body)
.retrieve()
.body(Map.class);
String content = extractContent(responseMap);
ChatResponse response = new ChatResponse();
response.setContent(content);
response.setProvider(ProviderType.OLLAMA);
response.setModel(defaultModel());
response.setFallback(false);
return response;
}
/**
* 转换消息格式
*/
private List<Map<String, String>> convertMessages(List<Message> messages) {
return messages.stream()
.map(msg -> {
Map<String, String> map = new HashMap<>();
map.put("role", msg.getRole());
map.put("content", msg.getContent());
return map;
})
.toList();
}
/**
* 提取 Ollama 返回内容
*/
private String extractContent(Map responseMap) {
Map message = (Map) responseMap.get("message");
if (message == null) {
return "";
}
Object content = message.get("content");
return content == null ? "" : content.toString();
}
}
代码解析
Ollama 与 OpenAI/Azure 的响应结构不同,这再次说明:统一抽象层非常有必要。
如果没有 Provider 适配器,上层业务就必须知道:
- OpenAI 返回
choices[0].message.content - Ollama 返回
message.content
这会让调用方代码变得极其丑陋且难维护。
12.2 Ollama 配置示例
ai:
openai:
enabled: false
base-url: https://api.openai.com
api-key: ${OPENAI_API_KEY:}
model: gpt-4o-mini
azure:
enabled: false
endpoint: ${AZURE_OPENAI_ENDPOINT:}
api-key: ${AZURE_OPENAI_API_KEY:}
deployment-name: ${AZURE_OPENAI_DEPLOYMENT:}
api-version: 2024-10-21
ollama:
enabled: true
base-url: http://localhost:11434
model: qwen2.5:7b
13. 项目实战七:实现基于成本、速度、准确率的动态路由
终于来到“路由引擎”本身。
很多同学一听“路由”,就想到 if else。其实最简单版本确实就是 if else,但关键在于:
- 规则是否清晰;
- 规则是否可扩展;
- 是否能表达优先级;
- 是否能承载故障切换。
13.1 定义路由决策对象
package com.example.router.model;
/**
* 路由决策结果
*/
public class RoutingDecision {
/**
* 首选供应商
*/
private ProviderType primaryProvider;
/**
* 备用供应商列表,按顺序降级
*/
private java.util.List<ProviderType> fallbackProviders;
public ProviderType getPrimaryProvider() {
return primaryProvider;
}
public void setPrimaryProvider(ProviderType primaryProvider) {
this.primaryProvider = primaryProvider;
}
public java.util.List<ProviderType> getFallbackProviders() {
return fallbackProviders;
}
public void setFallbackProviders(java.util.List<ProviderType> fallbackProviders) {
this.fallbackProviders = fallbackProviders;
}
}
13.2 路由引擎接口
package com.example.router.router;
import com.example.router.model.ChatRequest;
import com.example.router.model.RoutingDecision;
/**
* 路由引擎接口
*/
public interface RoutingEngine {
/**
* 根据请求生成路由决策
*
* @param request 聊天请求
* @return 路由决策结果
*/
RoutingDecision decide(ChatRequest request);
}
13.3 默认路由实现
package com.example.router.router;
import com.example.router.model.ChatRequest;
import com.example.router.model.ProviderType;
import com.example.router.model.RoutingDecision;
import com.example.router.model.TaskType;
import org.springframework.stereotype.Component;
import java.util.ArrayList;
import java.util.List;
/**
* 默认路由引擎实现
* 根据任务类型、成本偏好、延迟偏好、敏感性进行决策
*/
@Component
public class DefaultRoutingEngine implements RoutingEngine {
@Override
public RoutingDecision decide(ChatRequest request) {
RoutingDecision decision = new RoutingDecision();
// 如果用户显式指定供应商,则优先使用指定供应商
if (request.getProvider() != null) {
decision.setPrimaryProvider(request.getProvider());
decision.setFallbackProviders(defaultFallbacks(request.getProvider()));
return decision;
}
// 如果包含敏感数据,优先本地模型或企业云
if (request.isSensitive()) {
decision.setPrimaryProvider(ProviderType.OLLAMA);
decision.setFallbackProviders(List.of(ProviderType.AZURE_OPENAI, ProviderType.OPENAI));
return decision;
}
// 如果优先低成本,则优先本地模型
if (request.isPreferLowCost()) {
decision.setPrimaryProvider(ProviderType.OLLAMA);
decision.setFallbackProviders(List.of(ProviderType.AZURE_OPENAI, ProviderType.OPENAI));
return decision;
}
// 如果优先低延迟,也优先选较轻量或本地可达模型
if (request.isPreferLowLatency()) {
decision.setPrimaryProvider(ProviderType.OLLAMA);
decision.setFallbackProviders(List.of(ProviderType.OPENAI, ProviderType.AZURE_OPENAI));
return decision;
}
// 根据任务类型做默认选择
if (request.getTaskType() == TaskType.CODE_GENERATION
|| request.getTaskType() == TaskType.HIGH_ACCURACY
|| request.getTaskType() == TaskType.STRUCTURED_EXTRACTION) {
decision.setPrimaryProvider(ProviderType.OPENAI);
decision.setFallbackProviders(List.of(ProviderType.AZURE_OPENAI, ProviderType.OLLAMA));
return decision;
}
if (request.getTaskType() == TaskType.PRIVATE_DATA_ANALYSIS) {
decision.setPrimaryProvider(ProviderType.OLLAMA);
decision.setFallbackProviders(List.of(ProviderType.AZURE_OPENAI, ProviderType.OPENAI));
return decision;
}
// 其余场景默认走 Azure OpenAI,再兜底到 OpenAI 和 Ollama
decision.setPrimaryProvider(ProviderType.AZURE_OPENAI);
decision.setFallbackProviders(List.of(ProviderType.OPENAI, ProviderType.OLLAMA));
return decision;
}
/**
* 当显式指定供应商时,自动生成默认降级链路
*/
private List<ProviderType> defaultFallbacks(ProviderType primary) {
List<ProviderType> providers = new ArrayList<>();
for (ProviderType type : ProviderType.values()) {
if (type != primary) {
providers.add(type);
}
}
return providers;
}
}
代码解析
这里我们实现的是“规则优先级式”路由:
- 用户手动指定优先级最高;
- 敏感数据优先本地;
- 低成本优先本地;
- 低延迟优先本地;
- 高精度任务优先高质量云模型;
- 普通任务默认走企业云。
这就是一个非常典型、易懂、可维护的第一版路由策略。
13.4 路由流程图
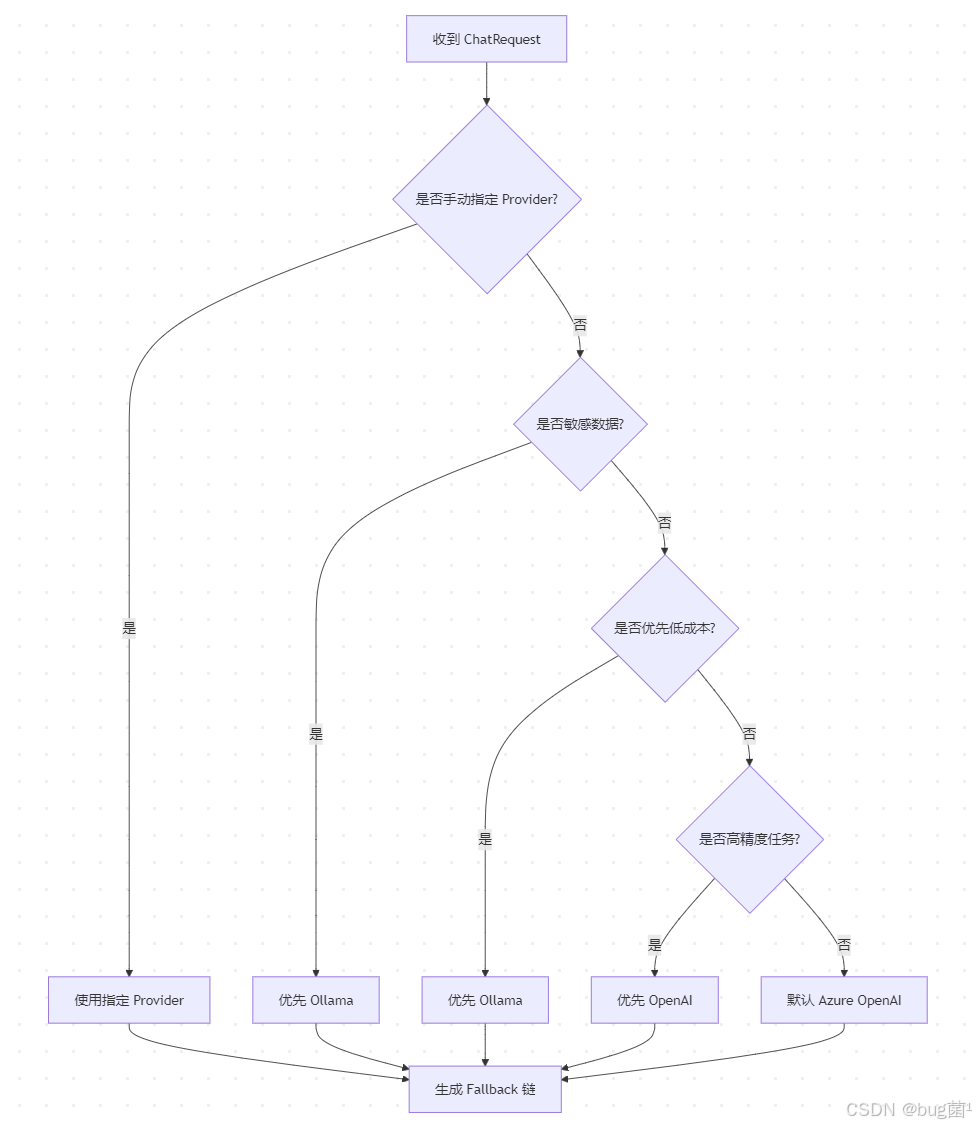
14. 项目实战八:实现故障切换与自动重试
有了路由决策还不够,我们还要把“主选失败后怎么切换”的链路做出来。
14.1 ChatService 统一调度服务
package com.example.router.service;
import com.example.router.model.ChatRequest;
import com.example.router.model.ChatResponse;
import com.example.router.model.ProviderType;
import com.example.router.model.RoutingDecision;
import com.example.router.provider.AiProvider;
import com.example.router.router.RoutingEngine;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Map;
import java.util.function.Function;
import java.util.stream.Collectors;
/**
* 聊天服务
* 负责根据路由决策调用不同供应商,并执行故障切换
*/
@Service
public class ChatService {
private final RoutingEngine routingEngine;
private final Map<ProviderType, AiProvider> providerMap;
public ChatService(RoutingEngine routingEngine, List<AiProvider> providers) {
this.routingEngine = routingEngine;
this.providerMap = providers.stream()
.collect(Collectors.toMap(AiProvider::providerType, Function.identity()));
}
/**
* 统一聊天入口
*
* @param request 请求对象
* @return 响应对象
*/
public ChatResponse chat(ChatRequest request) {
RoutingDecision decision = routingEngine.decide(request);
// 先尝试主供应商
ChatResponse primaryResponse = tryInvoke(decision.getPrimaryProvider(), request, false);
if (primaryResponse != null) {
return primaryResponse;
}
// 主供应商失败,按顺序尝试降级供应商
for (ProviderType fallbackProvider : decision.getFallbackProviders()) {
ChatResponse fallbackResponse = tryInvoke(fallbackProvider, request, true);
if (fallbackResponse != null) {
return fallbackResponse;
}
}
throw new IllegalStateException("所有模型供应商均调用失败");
}
/**
* 尝试调用指定供应商
*/
private ChatResponse tryInvoke(ProviderType providerType, ChatRequest request, boolean fallback) {
AiProvider provider = providerMap.get(providerType);
if (provider == null || !provider.isAvailable()) {
return null;
}
try {
ChatResponse response = provider.chat(request);
response.setFallback(fallback);
return response;
} catch (Exception e) {
return null;
}
}
}
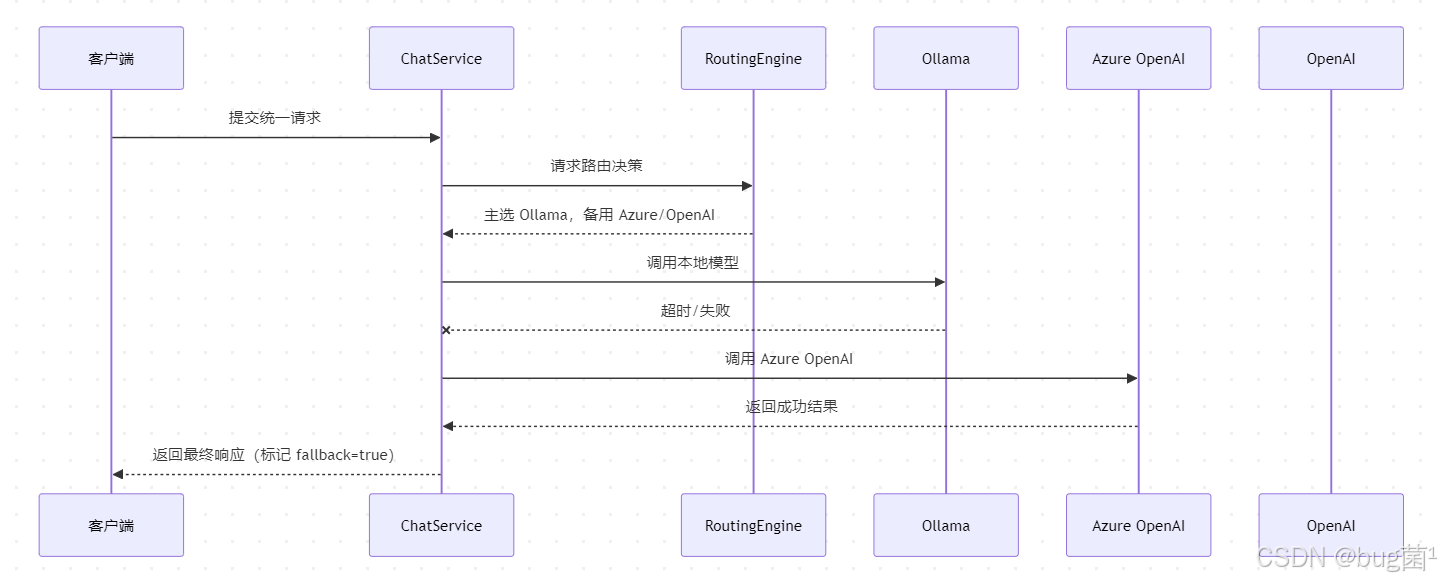
代码解析
这是系统运行的关键流程:
- 路由引擎只给出决策;
ChatService负责执行;- 主供应商失败则按备用列表依次尝试;
- 一旦某个供应商成功就立即返回。
这种结构非常适合扩展。
14.2 故障切换时序图
14.3 为什么不能把异常直接吞掉?
上面示例为了突出主流程,在 tryInvoke() 中简化成了失败返回 null。但在真实项目里,你应当:
- 记录失败原因;
- 打印 provider、异常类型、耗时、traceId;
- 统计失败次数;
- 区分可重试异常与不可重试异常。
所以接下来我们继续补上稳定性治理。
15. 项目实战九:本地模型与云模型组合实践
“本地模型 + 云模型”的组合并不是简单的二选一,而可以形成很多非常实用的协同模式。
15.1 模式一:本地优先,云端兜底
适用场景:
- 文本改写
- 摘要
- 简单问答
- 批量处理
- 预算敏感型业务
路由思路:
- 主选 Ollama
- 失败或结果置信不足时切 Azure/OpenAI
15.2 模式二:本地预处理,云端精加工
适用场景:
- 大段文本先本地清洗、分块、摘要;
- 核心复杂问题再交给云模型;
- 降低云端 token 消耗。
例如:
- 本地模型先将 20 页文档压缩成 2000 字摘要;
- 再把摘要交给高质量云模型做分析与结论输出。
这种模式可以显著降低成本。
15.3 模式三:敏感数据本地处理,非敏感结果上云
适用场景:
- 企业内网文档
- 用户隐私信息
- 合规要求较高的数据处理
处理步骤:
- 本地模型先脱敏;
- 仅把脱敏后的摘要上传到云模型;
- 云模型输出增强结果。
这是一种非常典型的企业混合部署策略。
15.4 组合式服务示例
package com.example.router.service;
import com.example.router.model.ChatRequest;
import com.example.router.model.ChatResponse;
import com.example.router.model.Message;
import com.example.router.model.ProviderType;
import com.example.router.model.TaskType;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
/**
* 组合式 AI 服务示例
* 演示本地模型预处理 + 云模型增强的组合链路
*/
@Service
public class HybridPipelineService {
private final ChatService chatService;
public HybridPipelineService(ChatService chatService) {
this.chatService = chatService;
}
/**
* 先用本地模型进行摘要,再用云模型做高精度分析
*
* @param rawText 原始文本
* @return 最终分析结果
*/
public ChatResponse summarizeThenAnalyze(String rawText) {
// 第一步:本地模型先做摘要
ChatRequest summaryRequest = new ChatRequest();
summaryRequest.setTaskType(TaskType.SUMMARY);
summaryRequest.setPreferLowCost(true);
summaryRequest.setProvider(ProviderType.OLLAMA);
summaryRequest.setMessages(List.of(
new Message("system", "你是一个擅长提炼重点的助手,请将输入内容总结为简洁摘要。"),
new Message("user", rawText)
));
ChatResponse summaryResponse = chatService.chat(summaryRequest);
// 第二步:将摘要结果交给云模型做深入分析
ChatRequest analyzeRequest = new ChatRequest();
analyzeRequest.setTaskType(TaskType.HIGH_ACCURACY);
analyzeRequest.setProvider(ProviderType.OPENAI);
List<Message> messages = new ArrayList<>();
messages.add(new Message("system", "你是高级分析助手,请基于给定摘要输出关键问题、风险点和行动建议。"));
messages.add(new Message("user", "以下是文档摘要,请进行深入分析:\n" + summaryResponse.getContent()));
analyzeRequest.setMessages(messages);
return chatService.chat(analyzeRequest);
}
}
代码解析
这个案例非常有代表性,它体现了混合部署不只是“路由一个模型”,而是“构建组合式推理链路”。
你可以看到:
- 低成本工作交给本地模型;
- 高价值分析交给高质量云模型;
- 两者组合比直接全量走云更省成本。
16. 项目实战十:可观测性、日志链路与指标监控
只要系统上线,你就必须知道:
- 哪个供应商最常被调用?
- 哪个供应商失败率高?
- 哪个路由策略最耗钱?
- 哪个任务平均耗时最长?
- 回退是不是太频繁?
这些都离不开监控。
16.1 指标记录器
package com.example.router.metrics;
import com.example.router.model.ProviderType;
import io.micrometer.core.instrument.Counter;
import io.micrometer.core.instrument.MeterRegistry;
import io.micrometer.core.instrument.Timer;
import org.springframework.stereotype.Component;
import java.util.concurrent.TimeUnit;
/**
* AI 调用指标记录器
*/
@Component
public class AiMetricsRecorder {
private final MeterRegistry meterRegistry;
public AiMetricsRecorder(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
}
/**
* 记录成功调用次数
*/
public void recordSuccess(ProviderType providerType) {
Counter.builder("ai.provider.success")
.tag("provider", providerType.name())
.register(meterRegistry)
.increment();
}
/**
* 记录失败调用次数
*/
public void recordFailure(ProviderType providerType) {
Counter.builder("ai.provider.failure")
.tag("provider", providerType.name())
.register(meterRegistry)
.increment();
}
/**
* 记录调用耗时
*/
public void recordLatency(ProviderType providerType, long latencyMs) {
Timer.builder("ai.provider.latency")
.tag("provider", providerType.name())
.register(meterRegistry)
.record(latencyMs, TimeUnit.MILLISECONDS);
}
}
16.2 在 ChatService 中接入指标
package com.example.router.service;
import com.example.router.metrics.AiMetricsRecorder;
import com.example.router.model.ChatRequest;
import com.example.router.model.ChatResponse;
import com.example.router.model.ProviderType;
import com.example.router.model.RoutingDecision;
import com.example.router.provider.AiProvider;
import com.example.router.router.RoutingEngine;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.Map;
import java.util.function.Function;
import java.util.stream.Collectors;
/**
* 增强版聊天服务,加入日志和指标
*/
@Service
public class ObservedChatService {
private static final Logger log = LoggerFactory.getLogger(ObservedChatService.class);
private final RoutingEngine routingEngine;
private final Map<ProviderType, AiProvider> providerMap;
private final AiMetricsRecorder metricsRecorder;
public ObservedChatService(RoutingEngine routingEngine,
List<AiProvider> providers,
AiMetricsRecorder metricsRecorder) {
this.routingEngine = routingEngine;
this.providerMap = providers.stream()
.collect(Collectors.toMap(AiProvider::providerType, Function.identity()));
this.metricsRecorder = metricsRecorder;
}
/**
* 带观测能力的聊天入口
*/
public ChatResponse chat(ChatRequest request) {
RoutingDecision decision = routingEngine.decide(request);
log.info("路由决策完成,primary={}, fallbacks={}",
decision.getPrimaryProvider(), decision.getFallbackProviders());
ChatResponse primaryResponse = tryInvoke(decision.getPrimaryProvider(), request, false);
if (primaryResponse != null) {
return primaryResponse;
}
for (ProviderType fallbackProvider : decision.getFallbackProviders()) {
ChatResponse fallbackResponse = tryInvoke(fallbackProvider, request, true);
if (fallbackResponse != null) {
return fallbackResponse;
}
}
throw new IllegalStateException("所有模型供应商均调用失败");
}
/**
* 尝试调用某个供应商,并记录指标
*/
private ChatResponse tryInvoke(ProviderType providerType, ChatRequest request, boolean fallback) {
AiProvider provider = providerMap.get(providerType);
if (provider == null || !provider.isAvailable()) {
log.warn("供应商不可用,provider={}", providerType);
return null;
}
try {
ChatResponse response = provider.chat(request);
response.setFallback(fallback);
metricsRecorder.recordSuccess(providerType);
metricsRecorder.recordLatency(providerType, response.getLatencyMs());
log.info("供应商调用成功,provider={}, latency={}ms", providerType, response.getLatencyMs());
return response;
} catch (Exception e) {
metricsRecorder.recordFailure(providerType);
log.error("供应商调用失败,provider={}, error={}", providerType, e.getMessage(), e);
return null;
}
}
}
代码解析
通过 MeterRegistry,我们可以把:
- 成功次数
- 失败次数
- 调用耗时
都导出到监控平台中。上线后你会非常依赖这些数据。
17. 使用 Resilience4j 增强重试、熔断与超时控制
前面的 try/catch + fallback 只是最基础的容错方式。到了生产环境,你还需要成熟的稳定性治理组件。
17.1 为什么需要 Resilience4j
多模型路由系统面对的是外部依赖,而外部依赖最常见的问题就是:
- 不稳定;
- 慢;
- 间歇性失败;
- 限流;
- 在高并发下雪崩。
如果你没有超时、熔断和重试机制,轻则接口偶尔抖动,重则线程池被拖死、服务不可用。
17.2 Resilience4j 配置示例
resilience4j:
retry:
instances:
openaiRetry:
max-attempts: 2
wait-duration: 500ms
azureRetry:
max-attempts: 2
wait-duration: 500ms
ollamaRetry:
max-attempts: 1
wait-duration: 200ms
circuitbreaker:
instances:
openaiCircuitBreaker:
sliding-window-size: 10
failure-rate-threshold: 50
wait-duration-in-open-state: 10s
azureCircuitBreaker:
sliding-window-size: 10
failure-rate-threshold: 50
wait-duration-in-open-state: 10s
ollamaCircuitBreaker:
sliding-window-size: 10
failure-rate-threshold: 50
wait-duration-in-open-state: 5s
timelimiter:
instances:
openaiTimeLimiter:
timeout-duration: 15s
azureTimeLimiter:
timeout-duration: 15s
ollamaTimeLimiter:
timeout-duration: 8s
17.3 在 Provider 中加入稳定性注解(示意)
package com.example.router.provider;
import com.example.router.config.AiProviderProperties;
import com.example.router.model.ChatRequest;
import com.example.router.model.ChatResponse;
import com.example.router.model.ProviderType;
import io.github.resilience4j.circuitbreaker.annotation.CircuitBreaker;
import io.github.resilience4j.retry.annotation.Retry;
import org.springframework.stereotype.Component;
import org.springframework.web.client.RestClient;
/**
* 带重试与熔断示意的 OpenAI Provider
*/
@Component
public class StableOpenAiProvider extends OpenAiProvider {
public StableOpenAiProvider(RestClient.Builder restClientBuilder, AiProviderProperties properties) {
super(restClientBuilder, properties);
}
@Override
@Retry(name = "openaiRetry")
@CircuitBreaker(name = "openaiCircuitBreaker")
public ChatResponse chat(ChatRequest request) {
return super.chat(request);
}
@Override
public ProviderType providerType() {
return ProviderType.OPENAI;
}
}
代码解析
引入 Resilience4j 后,你的系统就具备了以下能力:
- 短暂网络抖动自动重试;
- 连续失败后自动熔断,避免继续打挂外部系统;
- 超时快速失败,避免线程长期阻塞;
- 与 fallback 配合后,形成完整的高可用链路。
这才是面向生产的路由系统。
18. Controller 层:对外暴露统一接口
18.1 ChatController 实现
package com.example.router.controller;
import com.example.router.model.ChatRequest;
import com.example.router.model.ChatResponse;
import com.example.router.service.ChatService;
import jakarta.validation.Valid;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* 对外统一聊天接口
*/
@RestController
@RequestMapping("/api/chat")
public class ChatController {
private final ChatService chatService;
public ChatController(ChatService chatService) {
this.chatService = chatService;
}
/**
* 统一聊天入口
*
* @param request 请求对象
* @return 统一响应对象
*/
@PostMapping
public ChatResponse chat(@Valid @RequestBody ChatRequest request) {
return chatService.chat(request);
}
}
18.2 全局异常处理
package com.example.router.exception;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.MethodArgumentNotValidException;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
import java.util.HashMap;
import java.util.Map;
/**
* 全局异常处理器
*/
@RestControllerAdvice
public class GlobalExceptionHandler {
/**
* 处理参数校验异常
*/
@ExceptionHandler(MethodArgumentNotValidException.class)
public ResponseEntity<Map<String, Object>> handleValidationException(MethodArgumentNotValidException e) {
Map<String, Object> result = new HashMap<>();
result.put("code", 400);
result.put("message", e.getBindingResult().getFieldError() != null
? e.getBindingResult().getFieldError().getDefaultMessage()
: "参数校验失败");
return ResponseEntity.badRequest().body(result);
}
/**
* 处理通用异常
*/
@ExceptionHandler(Exception.class)
public ResponseEntity<Map<String, Object>> handleException(Exception e) {
Map<String, Object> result = new HashMap<>();
result.put("code", HttpStatus.INTERNAL_SERVER_ERROR.value());
result.put("message", e.getMessage());
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body(result);
}
}
代码解析
Controller 层应该保持轻量:
- 只接收参数;
- 做基础校验;
- 把业务转交给 Service;
- 不要把路由逻辑塞进 Controller。
这是一条非常重要的工程原则。
19. 接口调用示例与测试案例
为了帮助你真正跑起来,下面给出几个测试请求示例。
19.1 普通问答请求
{
"messages": [
{
"role": "system",
"content": "你是一个专业的 Java 架构助手。"
},
{
"role": "user",
"content": "请解释什么是 Spring Boot 3.x 的自动配置机制?"
}
],
"taskType": "GENERAL_CHAT",
"preferLowCost": false,
"preferLowLatency": false,
"sensitive": false
}
预期效果
- 默认情况下可能走 Azure OpenAI;
- 若 Azure 不可用,则回退 OpenAI 或 Ollama;
- 返回中可看到实际使用的 provider 和 latency。
19.2 敏感数据场景请求
{
"messages": [
{
"role": "system",
"content": "你是一个擅长内部文档分析的助手。"
},
{
"role": "user",
"content": "请总结这份包含内部财务信息的文档要点。"
}
],
"taskType": "PRIVATE_DATA_ANALYSIS",
"preferLowCost": true,
"preferLowLatency": false,
"sensitive": true
}
预期效果
- 路由优先选择 Ollama;
- 若本地模型不可用,则降级 Azure OpenAI;
- 尽量避免默认直接走公有云。
19.3 高精度代码生成请求
{
"messages": [
{
"role": "system",
"content": "你是资深 Spring Boot 架构师。"
},
{
"role": "user",
"content": "请生成一个基于 Spring Boot 3.x 的订单创建接口,要求使用 DTO、Service、Repository 分层。"
}
],
"taskType": "CODE_GENERATION",
"preferLowCost": false,
"preferLowLatency": false,
"sensitive": false
}
预期效果
- 优先走 OpenAI;
- 失败后切 Azure,再次失败可切 Ollama;
- 这样可以在质量和可用性之间取得平衡。
20. 进一步升级:把规则写成可配置而不是硬编码
前面的 DefaultRoutingEngine 是硬编码版,适合学习。但到了中大型项目,你一定会希望:
- 通过配置文件调整策略;
- 针对不同环境启用不同规则;
- 动态更新策略。
20.1 一个简化的规则配置结构示例
router:
rules:
sensitive-primary: OLLAMA
sensitive-fallbacks:
- AZURE_OPENAI
- OPENAI
high-accuracy-primary: OPENAI
high-accuracy-fallbacks:
- AZURE_OPENAI
- OLLAMA
default-primary: AZURE_OPENAI
default-fallbacks:
- OPENAI
- OLLAMA
20.2 对应配置类
package com.example.router.config;
import com.example.router.model.ProviderType;
import org.springframework.boot.context.properties.ConfigurationProperties;
import java.util.ArrayList;
import java.util.List;
/**
* 路由规则配置类
*/
@ConfigurationProperties(prefix = "router")
public class RoutingRuleProperties {
private Rules rules = new Rules();
public Rules getRules() {
return rules;
}
public void setRules(Rules rules) {
this.rules = rules;
}
public static class Rules {
private ProviderType sensitivePrimary;
private List<ProviderType> sensitiveFallbacks = new ArrayList<>();
private ProviderType highAccuracyPrimary;
private List<ProviderType> highAccuracyFallbacks = new ArrayList<>();
private ProviderType defaultPrimary;
private List<ProviderType> defaultFallbacks = new ArrayList<>();
public ProviderType getSensitivePrimary() {
return sensitivePrimary;
}
public void setSensitivePrimary(ProviderType sensitivePrimary) {
this.sensitivePrimary = sensitivePrimary;
}
public List<ProviderType> getSensitiveFallbacks() {
return sensitiveFallbacks;
}
public void setSensitiveFallbacks(List<ProviderType> sensitiveFallbacks) {
this.sensitiveFallbacks = sensitiveFallbacks;
}
public ProviderType getHighAccuracyPrimary() {
return highAccuracyPrimary;
}
public void setHighAccuracyPrimary(ProviderType highAccuracyPrimary) {
this.highAccuracyPrimary = highAccuracyPrimary;
}
public List<ProviderType> getHighAccuracyFallbacks() {
return highAccuracyFallbacks;
}
public void setHighAccuracyFallbacks(List<ProviderType> highAccuracyFallbacks) {
this.highAccuracyFallbacks = highAccuracyFallbacks;
}
public ProviderType getDefaultPrimary() {
return defaultPrimary;
}
public void setDefaultPrimary(ProviderType defaultPrimary) {
this.defaultPrimary = defaultPrimary;
}
public List<ProviderType> getDefaultFallbacks() {
return defaultFallbacks;
}
public void setDefaultFallbacks(List<ProviderType> defaultFallbacks) {
this.defaultFallbacks = defaultFallbacks;
}
}
}
代码解析
规则配置化后,最大的收益是:
- 策略不再写死在代码里;
- 不同环境可灵活调整;
- 更适合 A/B 测试与逐步演进。
21. 成本、速度、准确率三维路由如何进一步量化
前面我们讲了三大目标:成本、速度、准确率。现在更进一步,看看如何把它们“工程化”。
21.1 为什么要量化
如果你只写这样的规则:
- “复杂任务走高质量模型”
- “简单任务走低成本模型”
这在概念上没问题,但在系统里不够严谨。更好的做法是建立评分机制。
21.2 一个简化评分模型
我们可以给每个供应商建立一个基础画像:
- 成本分(越低越便宜)
- 延迟分(越低越快)
- 质量分(越高越强)
- 隐私分(越高越适合敏感数据)
例如:
| Provider | 成本分 | 延迟分 | 质量分 | 隐私分 |
|---|---|---|---|---|
| OLLAMA | 1 | 2 | 6 | 10 |
| AZURE_OPENAI | 6 | 5 | 8 | 8 |
| OPENAI | 7 | 5 | 9 | 6 |
然后根据请求特征计算加权得分。
21.3 示例:评分式路由引擎
package com.example.router.router;
import com.example.router.model.ChatRequest;
import com.example.router.model.ProviderType;
import com.example.router.model.RoutingDecision;
import org.springframework.stereotype.Component;
import java.util.Arrays;
import java.util.Comparator;
import java.util.List;
/**
* 评分式路由引擎示例
* 通过综合评分选择最优模型供应商
*/
@Component
public class ScoreBasedRoutingEngine implements RoutingEngine {
@Override
public RoutingDecision decide(ChatRequest request) {
List<ProviderScore> scores = Arrays.stream(ProviderType.values())
.map(provider -> new ProviderScore(provider, score(provider, request)))
.sorted(Comparator.comparingInt(ProviderScore::score).reversed())
.toList();
RoutingDecision decision = new RoutingDecision();
decision.setPrimaryProvider(scores.get(0).provider());
decision.setFallbackProviders(scores.stream().skip(1).map(ProviderScore::provider).toList());
return decision;
}
/**
* 根据供应商和请求计算综合得分
*/
private int score(ProviderType provider, ChatRequest request) {
int total = 0;
switch (provider) {
case OLLAMA -> {
// 成本低
total += request.isPreferLowCost() ? 40 : 10;
// 低延迟时加分
total += request.isPreferLowLatency() ? 30 : 10;
// 敏感数据优先本地
total += request.isSensitive() ? 50 : 0;
}
case AZURE_OPENAI -> {
// 企业云适中
total += request.isSensitive() ? 20 : 15;
total += request.isPreferLowCost() ? 10 : 15;
total += request.isPreferLowLatency() ? 10 : 15;
}
case OPENAI -> {
// 高精度任务优先高质量模型
switch (request.getTaskType()) {
case CODE_GENERATION, HIGH_ACCURACY, STRUCTURED_EXTRACTION -> total += 60;
default -> total += 20;
}
total += request.isPreferLowCost() ? 0 : 15;
}
default -> {
}
}
return total;
}
/**
* 供应商得分记录
*/
private record ProviderScore(ProviderType provider, int score) {
}
}
代码解析
评分式路由的优势在于:
- 规则更灵活;
- 更容易叠加新维度;
- 更适合未来做策略平台;
- 能为“为什么选这个模型”提供一定解释基础。
但它的缺点也要注意:
- 规则复杂度上升;
- 分数权重容易拍脑袋;
- 需要结合线上数据不断调优。
所以学习阶段建议先掌握规则式,再进阶评分式。
22. 供应商抽象层的进一步升级:支持能力标签而非仅按品牌路由
当系统越来越成熟时,你会发现:
用户关心的不是“OpenAI 还是 Azure”,而是“我要一个更快的、便宜的、适合私有数据的、擅长代码的模型”。
因此,你可以把路由从“按供应商品牌”升级为“按能力标签”。
22.1 能力标签示例
- CHEAP
- FAST
- ACCURATE
- PRIVATE
- CODE_STRONG
- STRUCTURED_OUTPUT
- TOOL_CALLING
22.2 Provider 能力声明示例
package com.example.router.model;
/**
* 模型能力标签
*/
public enum CapabilityTag {
CHEAP,
FAST,
ACCURATE,
PRIVATE,
CODE_STRONG,
STRUCTURED_OUTPUT
}
package com.example.router.provider;
import com.example.router.model.CapabilityTag;
import java.util.Set;
/**
* 可声明能力标签的 Provider 接口扩展
*/
public interface CapabilityAwareProvider extends AiProvider {
/**
* 返回当前供应商的能力标签集合
*/
Set<CapabilityTag> capabilities();
}
代码解析
这样做的好处是:
- 路由逻辑可以越来越“面向能力”而不是“面向品牌”;
- 更适合未来接更多模型;
- 当你接入 Anthropic、DeepSeek、Gemini、通义、百川等供应商时,规则不会失控。
这也是多模型平台长期演进的方向。
23. 安全设计:密钥隔离、限流、审计与敏感信息控制
做 AI 应用,安全不是附加项,而是基础能力。
23.1 密钥管理
错误示范:
- 把 API Key 硬编码进 Java 类;
- 把 Key 直接写进公开仓库;
- 不区分开发、测试、生产环境。
正确做法:
- 使用环境变量、KMS、Vault 等安全存储;
- 不同环境使用不同 Key;
- 不同供应商单独配置;
- 定期轮换密钥;
- 配置最小权限。
23.2 对外接口限流
如果你的 /api/chat 没有限流,风险很大:
- 可能被恶意刷爆;
- 容易引发成本失控;
- 本地模型机器可能被打满;
- 云模型额度被快速耗尽。
你可以考虑:
- 网关层限流;
- 用户级限流;
- 租户级限流;
- 按任务类型限流。
23.3 敏感信息脱敏
如果业务涉及:
- 手机号
- 身份证号
- 邮箱
- 合同编号
- 企业内部敏感字段
那么在发送到云模型之前,建议先做脱敏处理。
脱敏示例代码
package com.example.router.service;
import org.springframework.stereotype.Service;
import java.util.regex.Pattern;
/**
* 文本脱敏服务
*/
@Service
public class MaskingService {
private static final Pattern PHONE_PATTERN = Pattern.compile("1\\d{10}");
private static final Pattern EMAIL_PATTERN = Pattern.compile("[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\\.[A-Za-z]{2,}");
/**
* 对输入文本进行简单脱敏
*
* @param text 原始文本
* @return 脱敏后的文本
*/
public String mask(String text) {
if (text == null || text.isBlank()) {
return text;
}
String result = PHONE_PATTERN.matcher(text).replaceAll("[PHONE]");
result = EMAIL_PATTERN.matcher(result).replaceAll("[EMAIL]");
return result;
}
}
代码解析
虽然这只是一个简化示例,但已经能说明一件事:
多模型架构不是只关注“能不能调用”,还要关注“调用之前是否需要治理输入数据”。
这在企业场景中非常重要。
24. 性能优化:连接池、并发、缓存与流式输出
24.1 连接复用
在高并发场景下,如果每次请求都重新建立连接,性能会很差。Spring Boot 3.x 配合底层 HTTP 客户端可以实现连接复用,因此建议:
- 统一管理 HTTP 客户端 Bean;
- 设置合理连接池;
- 设置连接超时和读取超时。
24.2 并发控制
对于本地模型特别要注意:
- GPU/CPU 资源有限;
- 并发过高会导致响应时间急剧上升;
- 甚至出现整体雪崩。
所以对于 Ollama,你应该考虑:
- 单机最大并发;
- 队列长度;
- 超时快速失败;
- 将重任务导向云模型。
24.3 缓存策略
某些重复性很高的请求可以考虑缓存,例如:
- FAQ 问答;
- 标准文案改写模板;
- 规则性很强的摘要任务。
当然,缓存要注意:
- 相同请求的定义;
- 敏感数据不得误缓存;
- TTL 的合理设置;
- 是否允许用户看到缓存结果。
24.4 流式输出
如果面向聊天类前端,流式响应可以显著提升用户体验。不同供应商对流式的支持不完全一致,因此你在抽象层设计时要提前考虑:
- 是否提供同步接口与流式接口两套能力;
- 是否允许某些 Provider 不支持流式;
- 前端如何区分 complete 和 stream。
这部分实现较长,本文不展开完整代码,但你要知道,流式输出会直接影响统一抽象层的接口设计。
25. 常见问题与排错清单
这一节非常实用,建议你在专栏发布时保留。
25.1 OpenAI 调用 401/403
常见原因:
- API Key 配置错误;
- Key 为空;
- 网络代理问题;
- 账号权限受限。
排查建议:
- 检查
ai.openai.api-key是否正确注入; - 打印配置是否启用,但不要输出明文 Key;
- 用 curl/Postman 验证独立调用是否正常。
25.2 Azure OpenAI 返回 404
常见原因:
- endpoint 不正确;
- deploymentName 写错;
- api-version 不匹配;
- 部署未完成或区域错误。
排查建议:
- 检查 endpoint 结尾路径;
- 确保 deploymentName 是“部署名”而不是模型别名;
- 对照控制台确认 API version。
25.3 Ollama 返回连接失败
常见原因:
- 本地 Ollama 服务未启动;
- 端口不是 11434;
- 模型未下载;
- 服务绑定地址不对。
排查建议:
- 本地执行
ollama list查看模型; - 检查
http://localhost:11434/api/tags是否可访问; - 核对 Docker/宿主机网络映射。
25.4 所有模型都失败
可能原因:
- 路由策略选择了不可用供应商;
- 所有 Provider 都未启用;
- 请求消息格式异常;
- 网络配置异常;
- 统一异常处理把真实原因吞掉了。
排查建议:
- 启动时打印各 Provider 是否 available;
- 打印最终路由决策;
- 打印每次 fallback 的失败原因;
- 通过 actuator 暴露健康状态。
26. 生产落地建议:如何把 Demo 演进为真实可用系统
到这里,你已经拥有一个“教学上完整、工程上合理”的多模型路由基础版本。但生产系统还需要进一步升级。
26.1 把模型治理从代码中抽离
建议逐步增加:
- 路由规则配置中心;
- 模型元数据中心;
- 成本配置表;
- 任务类型字典;
- 灰度开关与实验分流能力。
26.2 对每个 Provider 做独立健康检查
可以增加如下能力:
- 定时 ping 外部服务;
- 将健康状态缓存到本地;
- 路由时优先跳过不健康 Provider;
- 在监控面板上显示 Provider 健康度。
26.3 成本治理要接入账单视角
仅有“理论成本偏好”还不够,真实系统应考虑:
- 日预算;
- 月预算;
- 每租户预算;
- 模型单价变化;
- token 统计与成本归因。
26.4 建立评估体系
你不能只凭感觉判断路由策略好不好。建议建立:
- 响应时间评估;
- 成本评估;
- 用户满意度;
- 任务成功率;
- fallback 触发率;
- 模型输出质量抽样评估。
这样你才能持续优化。
27. 专栏总结:从零基础到多模型治理的完整认知链路
回顾本文,我们并不是简单地教你“分别调用 OpenAI、Azure OpenAI 和 Ollama”。真正重要的是,你已经建立了以下一条完整认知链路:
27.1 你理解了为什么必须做统一抽象层
因为不同供应商的:
- 认证方式不同;
- URL 结构不同;
- 消息格式不同;
- 响应结构不同;
- 能力和成本不同。
如果没有抽象层,业务代码会迅速失控。
27.2 你理解了路由的本质不是 if else,而是策略治理
多模型路由的关键不是“能切换”,而是:
- 为什么这样选;
- 什么情况下切换;
- 如何保障成本、速度、准确率的平衡;
- 如何通过数据不断优化策略。
27.3 你掌握了多模型混合部署的核心思路
- 本地模型适合低成本、敏感数据、预处理;
- 云模型适合高精度、高复杂任务;
- 二者组合可以形成更优的工程解。
27.4 你掌握了可运行的 Spring Boot 3.x 代码骨架
本文给出的核心代码已经覆盖了:
- 统一请求/响应模型;
- Provider 抽象层;
- OpenAI 接入;
- Azure OpenAI 接入;
- Ollama 接入;
- 路由引擎;
- fallback 机制;
- 混合管道实践;
- 指标监控与异常处理。
这已经足够你搭起一个真正的 Demo 项目,并在此基础上继续迭代。
28. 给读者的扩展练习
为了让你真正吃透这篇文章,建议你继续做下面这些练习:
- 为系统增加
stream=true的流式输出能力; - 把路由规则从代码迁移到数据库或配置中心;
- 为每个 Provider 增加健康检查接口;
- 给路由决策增加 explain 字段,告诉用户本次为什么选择这个模型;
- 统计 token 使用量与请求成本;
- 增加 Redis 缓存层;
- 增加租户级限流;
- 接入更多供应商并保持统一抽象不变;
- 用 Spring AI 重构部分接入逻辑,比较两种实现方式;
- 增加模型评测模块,为不同任务自动选择最优模型。
这些练习做完后,你就不仅仅是在“学 Spring Boot 接 AI 接口”,而是在真正理解 AI 应用基础设施工程化。
29. 附:一个完整可运行的 application.yml 示例
server:
port: 8080
spring:
application:
name: multi-model-router
ai:
openai:
enabled: true
base-url: https://api.openai.com
api-key: ${OPENAI_API_KEY:}
model: gpt-4o-mini
azure:
enabled: true
endpoint: ${AZURE_OPENAI_ENDPOINT:}
api-key: ${AZURE_OPENAI_API_KEY:}
deployment-name: ${AZURE_OPENAI_DEPLOYMENT:}
api-version: 2024-10-21
ollama:
enabled: true
base-url: http://localhost:11434
model: qwen2.5:7b
router:
rules:
sensitive-primary: OLLAMA
sensitive-fallbacks:
- AZURE_OPENAI
- OPENAI
high-accuracy-primary: OPENAI
high-accuracy-fallbacks:
- AZURE_OPENAI
- OLLAMA
default-primary: AZURE_OPENAI
default-fallbacks:
- OPENAI
- OLLAMA
management:
endpoints:
web:
exposure:
include: health,info,metrics,prometheus
endpoint:
health:
show-details: always
logging:
level:
root: info
com.example.router: info
resilience4j:
retry:
instances:
openaiRetry:
max-attempts: 2
wait-duration: 500ms
azureRetry:
max-attempts: 2
wait-duration: 500ms
ollamaRetry:
max-attempts: 1
wait-duration: 200ms
circuitbreaker:
instances:
openaiCircuitBreaker:
sliding-window-size: 10
failure-rate-threshold: 50
wait-duration-in-open-state: 10s
azureCircuitBreaker:
sliding-window-size: 10
failure-rate-threshold: 50
wait-duration-in-open-state: 10s
ollamaCircuitBreaker:
sliding-window-size: 10
failure-rate-threshold: 50
wait-duration-in-open-state: 5s
30. 结语
如果你把本文真正理解透彻,你得到的不只是一个“能调几个模型接口”的小 Demo,而是一套非常重要的工程思维:
- 用 Spring Boot 3.x 作为现代 Java AI 服务基础;
- 用 统一抽象层 屏蔽供应商差异;
- 用 路由策略 平衡成本、速度、准确率;
- 用 故障切换 保证系统可用;
- 用 本地模型 + 云模型组合 达到更优解;
- 用 监控与治理 让系统真正走向生产。
这,才是《零基础学 Spring Boot 3.x》这类专栏真正应该带给读者的价值:不是会写几个接口,而是逐步建立从框架到架构、从功能到工程、从 Demo 到落地的完整认知。
愿你在学会接入模型之后,更进一步,学会治理模型、设计系统、平衡技术与业务。
这才是真正的进阶。🚀
如果你准备把这篇文章继续打磨成发布版,下一步最值得补充的内容包括:
1)补一份“完整项目源码清单”;
2)补“Spring AI 版本实现对照”;
3)补“流式输出与 SSE 实战”;
4)补“Docker Compose 一键启动 OpenAI 代理 + Ollama + Spring Boot 示例”;
5)补“单元测试与集成测试代码”。
31. 从零开始补齐基础:为什么本篇必须建立在 Spring Boot 3.x 语境下
很多读者会有一个疑问:文章主题明明是“多模型路由”,为什么还要反复强调 Spring Boot 3.x?
原因很简单:专栏既然叫《零基础学 Spring Boot 3.x》,那么文章就不能只讲 AI 概念,而必须让读者理解:
- 为什么是 Spring Boot 3.x;
- Spring Boot 3.x 与旧版本相比,到底给这类项目带来了什么;
- 在项目设计时,哪些写法是 3.x 时代更推荐的方式;
- 为什么现代化 AI 网关更适合建立在 3.x 的能力体系上。
31.1 从 Java 8 时代到 Java 17 时代,开发思维已经变化
Spring Boot 2.x 的大量项目诞生于 Java 8/11 时代,而 Spring Boot 3.x 明确要求 Java 17 以上。这不是一个简单的版本门槛,而意味着:
- 你可以更自然地使用
record、模式匹配、增强的 switch 等现代 Java 特性; - 你可以在建模时更偏向不可变对象与更清晰的数据表达;
- 你可以更方便地配合现代云原生部署、容器化镜像、JDK 性能优化;
- 你在依赖生态上会更容易接入新的 AI、Observability、HTTP 客户端组件。
对“多模型路由”这种服务来说,现代 Java 的意义在于:更适合构建中间层、治理层、编排层和集成层。
31.2 Jakarta 命名空间变化的影响
Spring Boot 3.x 建立在 Spring Framework 6 之上,而 Spring Framework 6 全面转向 jakarta.* 命名空间。
因此你在写代码时会看到:
jakarta.validation.constraints.NotNulljakarta.servlet.*jakarta.persistence.*
这对初学者是一个必须越过的门槛。你在旧博客中看到的大量 javax.* 写法,放到新项目里经常已经不适用了。
这也是为什么本篇示例中的校验注解全部基于 jakarta.validation,而不是旧版本包名。
31.3 现代观测体系的重要性比过去更高
传统业务系统大多数时候调用的是数据库、缓存、消息队列、内部服务。但 AI 系统的典型特征是:
- 高度依赖外部模型服务;
- 响应耗时波动大;
- 成本与请求量强相关;
- 输出质量并不绝对稳定;
- 供应商差异显著;
- 容错策略复杂。
这就要求后端框架必须具备更好的监控能力。Spring Boot 3.x 在这一点上更加现代化:
- 与 Micrometer 集成自然;
- Actuator 能力成熟;
- 更适合对接 Prometheus、Grafana、OpenTelemetry 等现代观测体系。
所以,Spring Boot 3.x 不是仅仅“能做 AI 接口开发”,而是“更适合做 AI 基础设施服务”。
32. 多模型路由不是“调接口”,而是“模型治理”
为了帮助零基础读者真正理解,我们再把“路由”这件事讲透一点。
32.1 从业务视角看路由
业务方通常不会说:
- “请帮我调用 OpenAI”
- “请帮我调用 Azure OpenAI”
- “请帮我调用 Ollama”
业务方真正关心的是:
- 这个任务能不能快一点返回?
- 能不能便宜一点?
- 能不能更准一点?
- 敏感数据能不能不要出企业内网?
- 某个供应商挂了,业务能不能别受影响?
所以,从业务视角看,模型供应商只是实现手段,真正的核心是 服务目标与治理目标。
32.2 从平台视角看路由
平台团队在设计多模型系统时,关心的是另外一组问题:
- 哪类请求应该路由到哪类模型;
- 如何对模型进行分层;
- 如何记录和评估每个模型的效果;
- 如何避免高成本模型被滥用;
- 如何在故障时快速切流;
- 如何扩展新模型而不影响旧业务。
这意味着,多模型路由系统本质上已经接近“平台层能力”,而不只是普通业务接口。
32.3 从架构视角看路由
从架构视角,多模型路由其实具备非常强的“网关化”特征:
- 对外统一入口;
- 对内连接多个异构后端;
- 中间进行规则决策;
- 具备重试、熔断、限流、监控等治理能力;
- 最终向业务屏蔽复杂性。
这也是为什么很多企业最终会把“模型路由层”做成一个独立服务,而不是散落在各个业务项目中。
33. 能力差异的更细粒度拆解:不要只看“哪个模型更强”
做模型选型时,一个非常普遍的误区是:
只问“哪个模型最强”,而不问“这个任务到底需要哪种强”。
实际上,模型能力差异至少可以拆成下面这些维度。
33.1 指令遵循能力
有些模型特别擅长按指令办事,例如:
- 严格输出 JSON;
- 按你要求的格式分点回答;
- 不偏题;
- 不乱补内容。
这个能力在结构化抽取、流程编排、Agent 调用里尤其重要。
33.2 长文本理解能力
当你要处理:
- 多页合同;
- 长篇会议纪要;
- 技术设计文档;
- 多轮上下文对话;
模型是否能在较长上下文下保持稳定理解,差异会非常明显。
33.3 代码理解与生成能力
“代码生成”不是简单写一段示例,而是包括:
- 理解已有代码结构;
- 生成符合框架约束的代码;
- 尽量避免明显编译错误;
- 知道合理的分层与命名。
在这类任务里,模型间差异通常比普通聊天更明显。
33.4 成本可接受性
再好的模型,如果成本高到业务无法承担,也不适合大规模接入。特别是在:
- 高频问答;
- 批量摘要;
- 运营内容加工;
- 自动分类与审核;
这类场景里,单位调用成本会非常影响最终方案。
33.5 可控性与私有化能力
对企业来说,这一维经常比“绝对最强”更重要。因为现实里很多请求并不是想不想走本地,而是 必须能走本地。
这正是 Ollama 这类本地模型方案的重要价值所在。
34. 模型分层方法论:低成本层、标准层、高精度层、本地隐私层
为了让系统更有工程感,我们可以把模型按职责做分层,而不是“平铺几个供应商”。
34.1 低成本层
这层模型主要承担:
- 简单改写;
- 简单摘要;
- 批量预处理;
- 低价值问答;
- 内部辅助任务。
通常适合放:
- 本地轻量模型;
- 成本较低的小模型;
- 企业自托管模型。
34.2 标准层
这层模型负责:
- 大部分常规业务问答;
- 中等复杂内容生成;
- 基本结构化任务;
- 作为默认模型出口。
通常适合放:
- 企业云托管模型;
- 稳定性较高、速度和质量均衡的模型。
34.3 高精度层
这层模型适合:
- 代码生成;
- 复杂分析;
- 关键业务推理;
- 高价值场景输出;
- 重要报告、复杂抽取。
通常会选择质量最强的一组模型,但调用次数需要控制。
34.4 本地隐私层
这层模型不一定追求最强,但必须可控。它适合:
- 机密文档初处理;
- 敏感数据脱敏前处理;
- 企业内网场景;
- 法务、财务、人事相关内容的预分析。
分层示意图
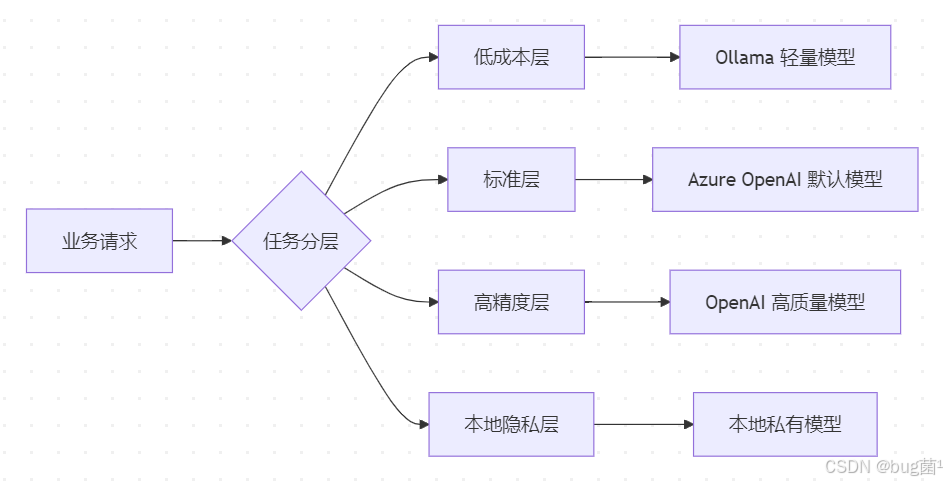
这种分层方式比“写几个 if else”更容易被团队理解,也更便于做中长期治理。
35. 更贴近生产的 Provider 注册中心设计
当供应商数量从 3 个增长到 5 个、8 个、10 个时,单纯依赖 List<AiProvider> 再转 Map 虽然仍能工作,但治理信息不够丰富。我们可以进一步设计一个 Provider 注册中心。
35.1 注册中心要解决什么问题
它至少应该能回答:
- 当前系统注册了哪些 Provider;
- 哪些 Provider 是启用状态;
- 哪些 Provider 当前健康;
- 哪些 Provider 支持哪些能力标签;
- 默认模型是什么;
- 当前可参与路由的候选集有哪些。
35.2 注册中心示例代码
package com.example.router.provider;
import com.example.router.model.ProviderType;
import org.springframework.stereotype.Component;
import java.util.Collection;
import java.util.List;
import java.util.Map;
import java.util.Optional;
import java.util.concurrent.ConcurrentHashMap;
/**
* Provider 注册中心
* 用于统一管理系统内所有供应商实例
*/
@Component
public class ProviderRegistry {
/**
* 供应商映射表
*/
private final Map<ProviderType, AiProvider> providerMap = new ConcurrentHashMap<>();
public ProviderRegistry(List<AiProvider> providers) {
for (AiProvider provider : providers) {
providerMap.put(provider.providerType(), provider);
}
}
/**
* 根据类型获取供应商
*/
public Optional<AiProvider> getProvider(ProviderType providerType) {
return Optional.ofNullable(providerMap.get(providerType));
}
/**
* 获取所有已注册供应商
*/
public Collection<AiProvider> getAllProviders() {
return providerMap.values();
}
/**
* 获取当前可用供应商列表
*/
public List<AiProvider> getAvailableProviders() {
return providerMap.values().stream()
.filter(AiProvider::isAvailable)
.toList();
}
}
代码解析
注册中心的价值在于:
- 让
ChatService不必自己管理 providerMap; - 为后续加入健康状态、动态开关、能力标签提供统一入口;
- 更适合平台化演进。
36. 加入健康检查:路由前先识别“谁现在能用”
很多初版 Demo 只检查“配置里启没启用”,但生产环境真正重要的是“当前是否健康”。
36.1 为什么需要健康检查
一个 Provider “配置完整”并不等于“可用”。例如:
- OpenAI Key 正确,但网络不通;
- Azure endpoint 正确,但部署已经失效;
- Ollama 配置存在,但本地服务没启动;
- 服务在线,但响应时间过慢,已经不适合接实时流量。
36.2 定义健康状态对象
package com.example.router.model;
/**
* Provider 健康状态
*/
public class ProviderHealthStatus {
/**
* 供应商类型
*/
private ProviderType providerType;
/**
* 是否健康
*/
private boolean healthy;
/**
* 最近探测耗时
*/
private long latencyMs;
/**
* 状态描述
*/
private String message;
public ProviderType getProviderType() {
return providerType;
}
public void setProviderType(ProviderType providerType) {
this.providerType = providerType;
}
public boolean isHealthy() {
return healthy;
}
public void setHealthy(boolean healthy) {
this.healthy = healthy;
}
public long getLatencyMs() {
return latencyMs;
}
public void setLatencyMs(long latencyMs) {
this.latencyMs = latencyMs;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
}
36.3 健康检查服务示例
package com.example.router.service;
import com.example.router.model.ProviderHealthStatus;
import com.example.router.model.ProviderType;
import com.example.router.provider.ProviderRegistry;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
/**
* Provider 健康检查服务
*/
@Service
public class ProviderHealthService {
private final ProviderRegistry providerRegistry;
public ProviderHealthService(ProviderRegistry providerRegistry) {
this.providerRegistry = providerRegistry;
}
/**
* 简化版健康检查:当前示例通过 isAvailable 判定
* 真实项目可扩展为主动探测接口
*/
public List<ProviderHealthStatus> checkAll() {
List<ProviderHealthStatus> result = new ArrayList<>();
providerRegistry.getAllProviders().forEach(provider -> {
ProviderHealthStatus status = new ProviderHealthStatus();
status.setProviderType(provider.providerType());
status.setHealthy(provider.isAvailable());
status.setLatencyMs(-1);
status.setMessage(provider.isAvailable() ? "配置可用" : "配置不可用");
result.add(status);
});
return result;
}
/**
* 判断某个供应商是否健康
*/
public boolean isHealthy(ProviderType providerType) {
return providerRegistry.getProvider(providerType)
.map(provider -> provider.isAvailable())
.orElse(false);
}
}
代码解析
这份代码是“教学版”的健康检查,重点是帮你建立结构意识。真正的生产实现通常会做:
- 主动探测轻量接口;
- 周期性后台刷新;
- 降低探测频率避免额外成本;
- 记录最近成功时间、失败次数、平均时延;
- 与熔断器状态联动。
37. 路由前置处理:Prompt 规范化、长度估算与任务识别
优秀的模型路由系统,不会直接把前端传来的内容原封不动扔给模型,而会先做预处理。
37.1 为什么要做前置处理
因为很多请求本身信息不完整:
- 没有 system 提示词;
- 任务类型传错了;
- 文本太长可能超出本地模型舒适区;
- 某些敏感字段尚未脱敏;
- 请求内容不适合当前模型。
所以,路由前的预处理非常重要。
37.2 Prompt 预处理服务示例
package com.example.router.service;
import com.example.router.model.ChatRequest;
import com.example.router.model.Message;
import org.springframework.stereotype.Service;
import java.util.ArrayList;
import java.util.List;
/**
* Prompt 预处理服务
*/
@Service
public class PromptPreprocessService {
/**
* 对请求进行预处理,例如补充默认系统提示词
*
* @param request 原始请求
* @return 处理后的请求
*/
public ChatRequest preprocess(ChatRequest request) {
if (request.getMessages() == null || request.getMessages().isEmpty()) {
return request;
}
boolean hasSystem = request.getMessages().stream()
.anyMatch(msg -> "system".equalsIgnoreCase(msg.getRole()));
if (!hasSystem) {
List<Message> newMessages = new ArrayList<>();
newMessages.add(new Message("system", "你是一个严谨、清晰、专业的 AI 助手,请基于用户输入提供准确回答。"));
newMessages.addAll(request.getMessages());
request.setMessages(newMessages);
}
return request;
}
}
代码解析
这个例子很简单,但它体现了一个重要思想:
在 AI 系统里,输入本身也是需要治理的。
将来你可以在这里继续扩展:
- 自动补系统提示词;
- 自动脱敏;
- 自动裁剪超长内容;
- 根据任务类型插入格式约束;
- 自动识别是否需要结构化输出。
38. 结构化输出案例:让模型返回 JSON,而不是随意文本
在真实业务中,很多时候我们并不需要自然语言大段回答,而是希望模型输出一个结构化结果,比如:
- 文本分类标签;
- 实体抽取结果;
- 风险等级;
- 是否命中规则;
- 摘要字段集合。
38.1 结构化抽取请求示例
{
"messages": [
{
"role": "system",
"content": "请从输入文本中提取合同名称、签署方、金额、日期,并以 JSON 返回。"
},
{
"role": "user",
"content": "甲方为北京某科技公司,乙方为上海某服务公司,签署日期为2026年3月1日,合同金额为人民币50万元。"
}
],
"taskType": "STRUCTURED_EXTRACTION",
"preferLowCost": false,
"preferLowLatency": false,
"sensitive": true
}
38.2 定义结构化输出对象
package com.example.router.model;
/**
* 合同抽取结果示例
*/
public class ContractExtractResult {
/**
* 合同名称
*/
private String contractName;
/**
* 甲方
*/
private String partyA;
/**
* 乙方
*/
private String partyB;
/**
* 金额
*/
private String amount;
/**
* 日期
*/
private String signDate;
public String getContractName() {
return contractName;
}
public void setContractName(String contractName) {
this.contractName = contractName;
}
public String getPartyA() {
return partyA;
}
public void setPartyA(String partyA) {
this.partyA = partyA;
}
public String getPartyB() {
return partyB;
}
public void setPartyB(String partyB) {
this.partyB = partyB;
}
public String getAmount() {
return amount;
}
public void setAmount(String amount) {
this.amount = amount;
}
public String getSignDate() {
return signDate;
}
public void setSignDate(String signDate) {
this.signDate = signDate;
}
}
38.3 结构化输出解析服务示例
package com.example.router.service;
import com.example.router.model.ContractExtractResult;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.stereotype.Service;
/**
* 结构化输出解析服务
*/
@Service
public class StructuredOutputService {
private final ObjectMapper objectMapper;
public StructuredOutputService(ObjectMapper objectMapper) {
this.objectMapper = objectMapper;
}
/**
* 将模型返回的 JSON 字符串解析为对象
*
* @param json 模型返回内容
* @return 解析后的对象
*/
public ContractExtractResult parseContractJson(String json) {
try {
return objectMapper.readValue(json, ContractExtractResult.class);
} catch (Exception e) {
throw new IllegalArgumentException("模型输出不是合法 JSON:" + json, e);
}
}
}
代码解析
这里最重要的思想是:
- 高质量模型更适合做结构化输出;
- 结构化任务在路由层应当被识别为高精度任务;
- 输出之后还需要在服务端做解析和校验,而不是盲信模型结果。
39. 再加一个重要案例:按任务级别控制“先快后准”
在某些前端交互场景下,我们想要的不是直接等待“最优答案”,而是:
- 先给用户一个较快的初步结果;
- 再异步补充更准确的结果;
- 前端可以展示“快速答案”和“增强答案”。
这种思路非常适合:
- 客服助手;
- 代码建议;
- 知识问答;
- 文案写作辅助。
39.1 “先快后准”服务示例
package com.example.router.service;
import com.example.router.model.ChatRequest;
import com.example.router.model.ChatResponse;
import com.example.router.model.Message;
import com.example.router.model.ProviderType;
import com.example.router.model.TaskType;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* 先快后准策略服务
*/
@Service
public class FastThenAccurateService {
private final ChatService chatService;
public FastThenAccurateService(ChatService chatService) {
this.chatService = chatService;
}
/**
* 先使用本地模型给出快速结果,再用高质量模型生成增强结果
*/
public FastThenAccurateResult execute(String question) {
ChatRequest fastRequest = new ChatRequest();
fastRequest.setTaskType(TaskType.GENERAL_CHAT);
fastRequest.setPreferLowLatency(true);
fastRequest.setProvider(ProviderType.OLLAMA);
fastRequest.setMessages(List.of(
new Message("system", "请快速给出简洁答案。"),
new Message("user", question)
));
ChatResponse fastResponse = chatService.chat(fastRequest);
ChatRequest accurateRequest = new ChatRequest();
accurateRequest.setTaskType(TaskType.HIGH_ACCURACY);
accurateRequest.setProvider(ProviderType.OPENAI);
accurateRequest.setMessages(List.of(
new Message("system", "请基于问题提供更完整、更严谨的答案。"),
new Message("user", question)
));
ChatResponse accurateResponse = chatService.chat(accurateRequest);
FastThenAccurateResult result = new FastThenAccurateResult();
result.setFastContent(fastResponse.getContent());
result.setAccurateContent(accurateResponse.getContent());
return result;
}
/**
* 返回对象
*/
public static class FastThenAccurateResult {
private String fastContent;
private String accurateContent;
public String getFastContent() {
return fastContent;
}
public void setFastContent(String fastContent) {
this.fastContent = fastContent;
}
public String getAccurateContent() {
return accurateContent;
}
public void setAccurateContent(String accurateContent) {
this.accurateContent = accurateContent;
}
}
}
代码解析
这段代码的价值在于让你理解:
路由系统不仅可以做“单次选择”,还可以做“多阶段编排”。
这会让你的 AI 中台更有实际价值。
40. AOP 日志切面:统一记录请求、路由与结果摘要
AI 请求的日志不能只打普通接口日志。因为调试时你往往要知道:
- 输入任务类型是什么;
- 路由到哪个 Provider;
- 是否 fallback;
- 耗时多久;
- 输出长度多长;
- 是否包含异常。
40.1 路由日志切面示例
package com.example.router.metrics;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
/**
* AI 调用日志切面
*/
@Aspect
@Component
public class AiInvokeLogAspect {
private static final Logger log = LoggerFactory.getLogger(AiInvokeLogAspect.class);
/**
* 对 ChatService 的 chat 方法做统一日志记录
*/
@Around("execution(* com.example.router.service.ChatService.chat(..))")
public Object aroundChat(ProceedingJoinPoint joinPoint) throws Throwable {
long start = System.currentTimeMillis();
try {
Object result = joinPoint.proceed();
long cost = System.currentTimeMillis() - start;
log.info("AI 请求处理完成,cost={}ms", cost);
return result;
} catch (Throwable e) {
long cost = System.currentTimeMillis() - start;
log.error("AI 请求处理失败,cost={}ms, error={}", cost, e.getMessage(), e);
throw e;
}
}
}
代码解析
用 AOP 统一做日志的好处是:
- 不需要在每个方法手写重复日志;
- 更容易做链路观测;
- 后续可以结合 TraceId、MDC、用户 ID、租户 ID 等信息完善审计能力。
41. 单元测试:先保证路由规则可靠,再考虑模型输出质量
很多同学做 AI 项目容易忽略测试,理由通常是:“模型输出本来就不完全稳定,怎么测?”
其实多模型系统里最值得测试的,往往不是模型文本内容本身,而是:
- 路由规则对不对;
- fallback 是否按预期执行;
- 配置是否生效;
- 某些请求是否真的走到了本地或云端。
41.1 路由引擎单元测试示例
package com.example.router.router;
import com.example.router.model.ChatRequest;
import com.example.router.model.ProviderType;
import com.example.router.model.RoutingDecision;
import com.example.router.model.TaskType;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
/**
* 路由引擎单元测试
*/
public class DefaultRoutingEngineTest {
private final DefaultRoutingEngine routingEngine = new DefaultRoutingEngine();
/**
* 测试敏感数据是否优先走本地模型
*/
@Test
void shouldChooseOllamaWhenSensitive() {
ChatRequest request = new ChatRequest();
request.setTaskType(TaskType.PRIVATE_DATA_ANALYSIS);
request.setSensitive(true);
RoutingDecision decision = routingEngine.decide(request);
Assertions.assertEquals(ProviderType.OLLAMA, decision.getPrimaryProvider());
Assertions.assertFalse(decision.getFallbackProviders().isEmpty());
}
/**
* 测试代码生成是否优先走 OpenAI
*/
@Test
void shouldChooseOpenAiWhenCodeGeneration() {
ChatRequest request = new ChatRequest();
request.setTaskType(TaskType.CODE_GENERATION);
RoutingDecision decision = routingEngine.decide(request);
Assertions.assertEquals(ProviderType.OPENAI, decision.getPrimaryProvider());
}
/**
* 测试低成本场景是否优先本地模型
*/
@Test
void shouldChooseOllamaWhenPreferLowCost() {
ChatRequest request = new ChatRequest();
request.setTaskType(TaskType.GENERAL_CHAT);
request.setPreferLowCost(true);
RoutingDecision decision = routingEngine.decide(request);
Assertions.assertEquals(ProviderType.OLLAMA, decision.getPrimaryProvider());
}
}
代码解析
这类测试的意义非常大。它确保:
- 路由逻辑修改后不会误伤原本规则;
- 以后团队成员改策略时有“护栏”;
- 在持续集成环境里能快速发现回归问题。
42. 服务层测试:验证 fallback 是否按预期生效
路由对了,还要测试主模型失败时是否真能切换到备用模型。
42.1 使用 Mockito 的示例思路
package com.example.router.service;
import com.example.router.model.ChatRequest;
import com.example.router.model.ChatResponse;
import com.example.router.model.Message;
import com.example.router.model.ProviderType;
import com.example.router.model.RoutingDecision;
import com.example.router.model.TaskType;
import com.example.router.provider.AiProvider;
import com.example.router.router.RoutingEngine;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import org.mockito.Mockito;
import java.util.List;
/**
* ChatService 故障切换测试
*/
public class ChatServiceTest {
/**
* 测试主供应商失败时是否会切换到备用供应商
*/
@Test
void shouldFallbackWhenPrimaryFails() {
RoutingEngine routingEngine = Mockito.mock(RoutingEngine.class);
AiProvider openAiProvider = Mockito.mock(AiProvider.class);
AiProvider azureProvider = Mockito.mock(AiProvider.class);
RoutingDecision decision = new RoutingDecision();
decision.setPrimaryProvider(ProviderType.OPENAI);
decision.setFallbackProviders(List.of(ProviderType.AZURE_OPENAI));
Mockito.when(routingEngine.decide(Mockito.any())).thenReturn(decision);
Mockito.when(openAiProvider.providerType()).thenReturn(ProviderType.OPENAI);
Mockito.when(openAiProvider.isAvailable()).thenReturn(true);
Mockito.when(openAiProvider.chat(Mockito.any())).thenThrow(new RuntimeException("OpenAI 调用失败"));
ChatResponse fallbackResponse = new ChatResponse();
fallbackResponse.setContent("Azure 响应成功");
fallbackResponse.setProvider(ProviderType.AZURE_OPENAI);
Mockito.when(azureProvider.providerType()).thenReturn(ProviderType.AZURE_OPENAI);
Mockito.when(azureProvider.isAvailable()).thenReturn(true);
Mockito.when(azureProvider.chat(Mockito.any())).thenReturn(fallbackResponse);
ChatService chatService = new ChatService(routingEngine, List.of(openAiProvider, azureProvider));
ChatRequest request = new ChatRequest();
request.setTaskType(TaskType.GENERAL_CHAT);
request.setMessages(List.of(new Message("user", "你好")));
ChatResponse response = chatService.chat(request);
Assertions.assertEquals("Azure 响应成功", response.getContent());
Assertions.assertTrue(response.isFallback());
}
}
代码解析
这个测试比“直接看接口能不能通”更重要,因为它验证了系统最关键的高可用能力。
43. 本地运行与 Docker Compose 组合实践
很多读者希望不仅看到 Java 代码,还希望知道怎么把环境跑起来。下面给一个适合学习的 Docker Compose 思路。
43.1 场景说明
这个示例的目标是:
- 本机运行 Spring Boot 服务;
- 使用本地 Ollama 作为本地模型;
- 将云端 OpenAI/Azure 作为可选 fallback。
如果你希望把 Spring Boot 和 Ollama 一起容器化,也可以用 Compose 编排。
43.2 Docker Compose 示例
version: '3.9'
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
restart: unless-stopped
app:
image: eclipse-temurin:17-jdk
container_name: multi-model-router-app
working_dir: /app
volumes:
- ./:/app
command: ["./mvnw", "spring-boot:run"]
ports:
- "8080:8080"
environment:
OPENAI_API_KEY: ${OPENAI_API_KEY}
AZURE_OPENAI_ENDPOINT: ${AZURE_OPENAI_ENDPOINT}
AZURE_OPENAI_API_KEY: ${AZURE_OPENAI_API_KEY}
AZURE_OPENAI_DEPLOYMENT: ${AZURE_OPENAI_DEPLOYMENT}
depends_on:
- ollama
volumes:
ollama_data:
代码解析
这个 Compose 不是最优生产写法,但作为学习示例足够直观:
ollama提供本地模型接口;app直接运行 Spring Boot 项目;- 你可以在本地通过环境变量注入云端配置;
- 这样就形成了“本地 + 云端”混合实验环境。
43.3 本地启动流程建议
- 启动 Ollama 服务;
- 拉取一个本地模型,例如
qwen2.5:7b; - 配置
application.yml; - 启动 Spring Boot 服务;
- 用 Postman 或 curl 调用
/api/chat。
44. 一个更完整的请求生命周期图
为了帮助初学者把调用过程在脑海里串起来,我们再画一张更细的流程图。
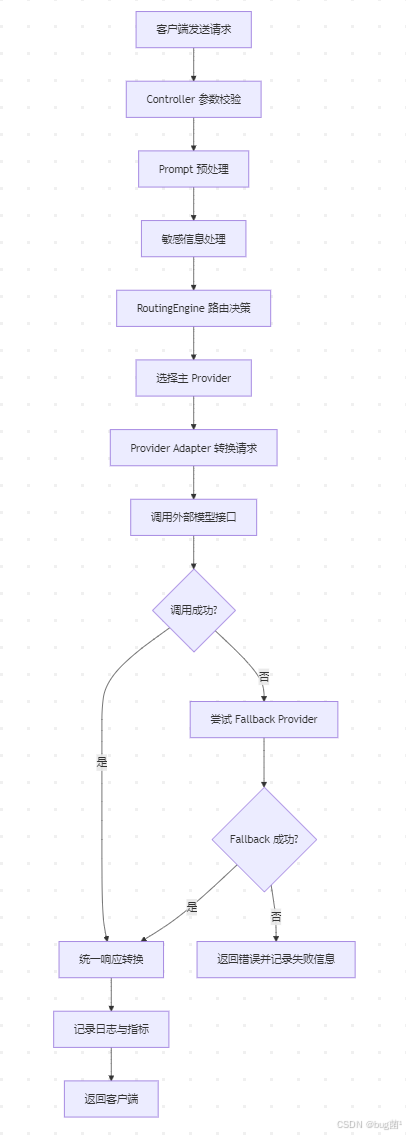
这张图的意义在于帮助读者理解:
- 路由不是一个点,而是一条链路;
- 真正的工程实现远比“发个 HTTP 请求”复杂;
- 每一层都应该职责清晰。
45. 文章级别的深入解释:成本、速度、准确率为什么总会互相拉扯?
这一节更偏认知层,适合你写成专栏中的“思考性段落”,能明显提升文章质量。
45.1 成本和准确率的拉扯
一般来说,更强的模型通常意味着:
- 更高的训练与推理成本;
- 更高的 token 单价;
- 更复杂的系统资源消耗。
这就导致一个现实问题:
如果所有请求都走最高质量模型,你的系统往往会“效果很好,但账单爆炸”。
所以你必须承认一个事实:业务系统几乎永远在做“足够好”与“绝对最好”之间的平衡。
45.2 速度和准确率的拉扯
高质量模型经常意味着:
- 推理链更复杂;
- 输出更长;
- 响应时间更高;
- 并发承载压力更大。
这对实时交互类产品并不总是友好。很多时候用户更喜欢:
- 先在 1 秒内看到一个可用答案;
- 再逐步看到更优答案。
这就是前面“先快后准”策略的理论基础。
45.3 成本和速度的拉扯
便宜的模型不一定更快;快的模型不一定更便宜。本地模型虽然不按 token 收费,但如果本地机器资源不足,实际响应时间可能并不理想。
所以,评价“成本”时不能只看云厂商单价,还要看:
- 本地 GPU/CPU 成本;
- 运维成本;
- 研发接入成本;
- 故障与不稳定带来的间接成本。
这也是为什么成熟团队不会用单一维度做模型选择。
46. 让文章更落地:给出几种典型业务路由策略模板
为了帮助读者快速迁移到自己的项目里,下面我给出几个非常实用的策略模板。
46.1 模板一:客服问答系统
特点:
- 请求量大;
- 时延敏感;
- 大量问题属于重复或简单问答;
- 复杂问题占少数。
建议策略:
- FAQ 命中 -> 缓存/检索直接答;
- 普通问答 -> Azure/OpenAI 标准层;
- 简单重写与分类 -> Ollama;
- 高复杂工单 -> OpenAI 高精度层。
46.2 模板二:企业文档分析系统
特点:
- 数据敏感;
- 文本较长;
- 合规要求高;
- 质量要求也高。
建议策略:
- 敏感原文预处理 -> Ollama;
- 脱敏后复杂分析 -> Azure/OpenAI;
- 最终报告输出 -> 高精度模型;
- 失败时尽量优先切企业云而非外部公有线路。
46.3 模板三:研发助手系统
特点:
- 代码生成和解释需求多;
- 对准确率和结构质量要求高;
- 但也有大量简单说明、注释补全等低价值请求。
建议策略:
- 代码解释/补注释 -> 标准层或本地层;
- 复杂代码生成 -> 高精度层;
- 批量文档整理 -> 低成本层;
- 私有仓库内容先本地摘要再上云增强。
这些策略模板能帮助读者从“理解原理”真正走向“知道如何用”。
47. 生产环境中的组织协作建议:平台、业务、运维如何分工
为了本期文章内容显得更成熟,我还可以站在团队协作角度补充一节。
47.1 平台团队负责什么?
平台团队一般适合负责:
- 模型供应商统一接入;
- 路由策略基础框架;
- 指标、监控、审计;
- 成本治理与配额;
- 统一 SDK 或 API。
47.2 业务团队负责什么?
业务团队更适合负责:
- 任务类型定义;
- Prompt 设计;
- 具体场景的策略偏好;
- 结果质量评估;
- 业务级 fallback 处理。
47.3 运维/基础设施团队负责什么?
运维或基础设施团队通常负责:
- 本地模型机器资源;
- 容器化部署;
- 网络、代理、证书;
- 监控告警;
- 灰度发布和容量规划。
为什么要写这一节?
因为多模型系统不是单纯一个 Java 工程师能独立长期维护好的,它最终会涉及平台化和团队协作。专栏如果能讲到这里,专业感会明显更强。
48. 再补一个增强案例:基于请求长度和复杂度的路由
前面我们主要按任务类型来路由,下面再补一个更贴近实际的例子:根据输入文本长度和复杂度来调整策略。
48.1 为什么长度和复杂度重要?
原因很简单:
- 本地模型对长上下文的处理通常更容易受资源影响;
- 云模型虽然更强,但长文本成本更高;
- 简单短文本没有必要走高质量昂贵模型;
- 复杂长文本需要更慎重的选择。
48.2 复杂度评估工具示例
package com.example.router.service;
import com.example.router.model.ChatRequest;
import org.springframework.stereotype.Service;
/**
* 请求复杂度分析服务
*/
@Service
public class RequestComplexityService {
/**
* 估算请求总文本长度
*/
public int estimateLength(ChatRequest request) {
if (request.getMessages() == null) {
return 0;
}
return request.getMessages().stream()
.mapToInt(msg -> msg.getContent() == null ? 0 : msg.getContent().length())
.sum();
}
/**
* 简化版复杂度判断:文本过长视为复杂
*/
public boolean isComplex(ChatRequest request) {
return estimateLength(request) > 2000;
}
}
48.3 长文本路由策略示例
package com.example.router.router;
import com.example.router.model.ChatRequest;
import com.example.router.model.ProviderType;
import com.example.router.model.RoutingDecision;
import com.example.router.model.TaskType;
import com.example.router.service.RequestComplexityService;
import org.springframework.stereotype.Component;
import java.util.List;
/**
* 带长度与复杂度判断的路由引擎示例
*/
@Component
public class ComplexityAwareRoutingEngine implements RoutingEngine {
private final RequestComplexityService complexityService;
public ComplexityAwareRoutingEngine(RequestComplexityService complexityService) {
this.complexityService = complexityService;
}
@Override
public RoutingDecision decide(ChatRequest request) {
RoutingDecision decision = new RoutingDecision();
// 长文本且高精度任务,优先高质量云模型
if (complexityService.isComplex(request)
&& (request.getTaskType() == TaskType.HIGH_ACCURACY
|| request.getTaskType() == TaskType.STRUCTURED_EXTRACTION)) {
decision.setPrimaryProvider(ProviderType.OPENAI);
decision.setFallbackProviders(List.of(ProviderType.AZURE_OPENAI, ProviderType.OLLAMA));
return decision;
}
// 长文本但敏感,优先本地预处理再云端降级
if (complexityService.isComplex(request) && request.isSensitive()) {
decision.setPrimaryProvider(ProviderType.OLLAMA);
decision.setFallbackProviders(List.of(ProviderType.AZURE_OPENAI));
return decision;
}
// 其他走默认逻辑
decision.setPrimaryProvider(ProviderType.AZURE_OPENAI);
decision.setFallbackProviders(List.of(ProviderType.OPENAI, ProviderType.OLLAMA));
return decision;
}
}
代码解析
这段代码强调的是:
- 路由规则可以不仅依赖业务显式参数;
- 也可以从请求内容本身推导额外特征;
- 当系统成熟后,这种“特征驱动路由”会越来越重要。
49. 给零基础读者的认知提醒:不要把“本地模型”想得过于理想化
我为了保持文章的客观性,我们也要专门谈谈本地模型的边界。
49.1 本地模型不是天然更快
很多人第一次接触 Ollama 时会想:既然服务跑在本地,那一定比云端更快。实际并不总是这样,因为:
- 本地机器算力有限;
- 模型体积可能很大;
- CPU 推理速度可能较慢;
- GPU 显存不足会导致性能显著下降;
- 多并发下本地系统可能很快拥塞。
49.2 本地模型不是天然更准
本地模型更大的优势通常在:
- 可控;
- 可私有化;
- 成本可预期;
- 适合特定场景。
但在复杂推理、复杂代码生成等任务上,云端高质量模型通常仍有明显优势。
49.3 本地模型也有运维成本
很多“免费本地模型”的讨论,会忽略这些成本:
- 机器采购;
- 显卡成本;
- 运行维护;
- 模型管理;
- 容量规划;
- 日志监控;
- 升级与兼容问题。
所以,本地模型不是云模型的简单替代,而是混合部署中的一个关键角色。
50. 给零基础读者的认知提醒:不要把“云模型”想得过于万能
同样地,云模型也不是没有代价的“银弹”。
50.1 云模型的主要优势
- 能力通常更强;
- 上手快;
- 文档和生态更成熟;
- 很适合快速启动项目和复杂任务场景。
50.2 云模型的主要代价
- 按 token 成本可能不低;
- 高并发时账单增长明显;
- 外部依赖不可完全控制;
- 某些场景存在网络与合规挑战;
- 一旦供应商波动,会影响业务稳定性。
所以,对于成熟系统,最好的方式通常不是“全本地”或“全云”,而是 组合。
51. 面向未来扩展:如果要再接入 Anthropic、Gemini、DeepSeek,该怎么办?
虽然本文主题集中在 OpenAI、Azure、Ollama,但架构设计应该具有前瞻性。
51.1 为什么本文的抽象具有扩展性?
因为我们已经把系统拆成了:
- 统一请求模型;
- 统一响应模型;
- Provider 接口;
- 路由引擎;
- 服务编排;
- fallback 机制。
这意味着新增一个供应商时,原则上只需要:
- 新增枚举值;
- 实现一个新的 Provider;
- 在配置中加入对应参数;
- 在路由规则中声明其角色。
51.2 这就是架构抽象的价值
很多初学者觉得抽象层“写起来麻烦”。但当需求变化时,抽象层的价值就会非常明显。
这也正是技术文章里最值得传达给读者的:
不要只看眼前能不能跑,还要看半年后还能不能维护。
52. 本文终极总结:为什么这是一篇真正从 0 到 1 再到 1 到 N 的 Spring Boot 3.x AI 工程文章?
写本期内容我真正想教会读者的,不是某个接口怎么调,而是下面这条完整成长路径:
第一步,学会在 Spring Boot 3.x 里构建现代化后端服务;
第二步,理解 AI 能力接入背后的供应商差异;
第三步,建立统一抽象,而不是把业务代码绑死在某一个厂商上;
第四步,学会根据成本、速度、准确率设计路由;
第五步,学会用 fallback、熔断、重试保证高可用;
第六步,学会把本地模型和云模型组合成真正可用的业务能力;
第七步,学会通过监控、日志、测试和配置化让系统可持续演进。
当读者真正走完这条路径时,他学到的已经不只是“Spring Boot 3.x 接 AI”,而是:
- 如何用现代 Java 做 AI 基础设施;
- 如何理解平台层抽象;
- 如何在架构中平衡技术理想与业务现实;
- 如何让一个 Demo 逐步长成可落地系统。
这也是《零基础学 Spring Boot 3.x》专栏最应该为大家提供的价值。
…
ok,同学们,本节课就上到这儿,下课~
🧧 学习福利 · 限时开放 🧧
当然,无论你是计算机专业在读学生,还是对编程充满兴趣的入门者,都强烈建议系统学习SpringBoot全体系专栏:👉 「滚雪球学 Spring Boot」;涵盖SpringBoot所有教学内容。
该专栏以“循序渐进 + 实战驱动”为核心理念,从基础到进阶到就业到架构师逐层展开,帮助你快速建立完整的 Spring Boot 技术体系,带你玩转SpringBoot框架。
📌 学习承诺:
通过该专栏,你将能够:
- 快速掌握 Spring Boot 核心开发能力
- 构建完整的后端项目认知体系
- 实现从“入门”到“独立开发”的跃迁
就像“滚雪球”一样,知识不断积累、能力持续放大,实现指数级成长 🚀
最后,如果这篇文章对你有所帮助,帮忙给作者来个一键三连,关注、点赞、收藏,您的支持就是我坚持写作最大的动力。
同时欢迎大家关注技术号:「猿圈奇妙屋」 ,以便学习更多同类型的技术文章,免费白嫖最新BAT互联网公司面试题、4000G PDF编程电子书、简历模板、技术文章Markdown文档等海量资料。
ps:本文涉及所有源代码,均已上传至Gitee开源,供同学们直接对照学习 Gitee传送门,同时,原创开源不易,欢迎给个star🌟,想体验下被🌟的感jio,非常感谢❗
🫵 Who am I?
我是 bug菌:
- 热活于 CSDN | 稀土掘金 | InfoQ | 51CTO | 华为云开发者社区 | 阿里云开发者社区 | 腾讯云开发者社区 | 开源中国 | 博客园 | 墨天轮 等各大技术社区;
- CSDN 博客之星 Top30、华为云多年度十佳博主&卓越贡献奖、掘金多年度人气作者 Top40;
- CSDN、掘金、InfoQ、51CTO 等平台签约及优质作者;
- 全网粉丝累计 30w+。
更多高质量技术内容及成长资料,可查看这个合集入口 👉 点击查看 👈️
硬核技术号 「猿圈奇妙屋」 期待你的加入,一起进阶、一起打怪升级。

- End -

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献91条内容
已为社区贡献91条内容

所有评论(0)