一文读懂 Claude Code 的架构设计
原文:Dive into Claude Code: The Design Space of Today’s and Future AI Agent Systems
本文为个人翻译总结版本,如需原文pdf,公众号回复:Future AI 自取
摘要
Claude Code 是一种代理式编程工具,可以代表用户运行 Shell 命令、编辑文件,并调用外部服务。本文通过分析公开可得的 TypeScript 源代码,描述其综合架构,并进一步将其与 OpenClaw 进行比较。OpenClaw 是一个独立的开源 AI Agent 系统,在不同部署语境下回答了许多相同的设计问题。
研究识别出驱动该架构的五类人类价值、哲学与需求:
-
人类决策权;
-
安全、安全性与隐私;
-
可靠执行;
-
能力放大;
-
上下文适应性。
论文进一步把这些价值追踪到十三项设计原则,再映射到具体实现选择。系统核心是一个简单的 while 循环:调用模型、运行工具、重复迭代。然而,大部分代码并不在这个循环本身,而是在循环周围的系统中:拥有七种模式和基于机器学习分类器的权限系统、用于上下文管理的五层压缩流水线、四类扩展机制(MCP、插件、技能、Hooks)、子 Agent 委派与编排机制,以及面向追加写入的会话存储。
与 OpenClaw 的比较表明,当部署环境发生变化时,同一批反复出现的设计问题会产生不同的架构答案:从逐动作安全评估转向边界级访问控制,从单一 CLI 循环转向嵌入网关控制平面的运行时,从上下文窗口扩展转向网关级能力注册。最后,论文结合近期经验研究、架构文献与政策文献,提出未来 Agent 系统的六个开放设计方向。
1. 引言
AI 辅助软件开发已经从 GitHub Copilot 这类自动补全式工具,发展到 Cursor 这类 IDE 集成助手,再到能够自主规划多步修改、执行 Shell 命令、读写文件并自我迭代的完整代理式系统。
Claude Code 是 Anthropic 发布的代理式编程工具。其官方文档描述了一个“agentic loop”:系统围绕目标进行计划和执行,可调用工具、评估结果并持续行动,直到任务完成。与基于补全的工具相比,从“建议”转向“自主行动”引入了新的架构要求:安全、上下文管理、扩展性、委派、持久化等问题都需要在系统层面回答。
虽然 Claude Code 已被广泛采用,Anthropic 主要发布的是面向用户的文档,而非详细架构说明。本文通过源代码分析来重构其架构设计。Anthropic 内部对 132 名工程师与研究人员的调查显示,约 27% 的 Claude Code 辅助任务属于“如果没有该工具本不会尝试的工作”,这说明该架构不只是加速已有流程,也启用了新的工作方式。
论文组织为三部分:
- 设计空间分析
:识别围绕推理位置、迭代循环、安全策略、扩展面、上下文管理、子 Agent 委派与会话持久化的反复出现的设计问题,并分析 Claude Code 的回答。
- 与 OpenClaw 的架构对比
:通过六个维度比较一个商业化编程 Agent 与一个开源多通道个人助手网关,说明部署环境、产品目标、安全假设和用户假设如何塑造架构。
- 未来 Agent 系统的开放方向
:从可观测性与评估、跨会话持久化、Harness 边界演化、长时程扩展、治理,以及长期人类能力保存等方面提出开放问题。
论文贯穿使用一个运行示例:用户提出“修复 auth.test.ts 中失败的测试”。这个简单请求会触发多层架构机制:工具调用、权限检查、上下文选择、迭代修复、子 Agent 委派与会话持久化。
2. 设计哲学、设计原则与架构动机
生产级编程 Agent 由人构建、为人服务,其架构内嵌了创造者对于“什么重要”的判断。论文首先抽象出五类价值,再把这些价值落到十三项设计原则。
2.1 五类价值与哲学
2.1.1 人类决策权
人类应保留对系统行为的最终决策权。该原则通过权限层级体现:Anthropic、操作者、用户分别拥有不同层级的权威。系统让用户能够实时观察、批准或拒绝操作、中断兼容的进行中操作,并在事后审计。
当 Anthropic 发现用户会批准约 93% 的权限提示时,其应对并不是增加更多弹窗,而是重新组织问题:在清晰边界之内让 Agent 自由工作,例如使用沙箱与自动模式分类器,而不是依赖用户逐项审查。
2.1.2 安全、安全性与隐私
系统必须保护用户、代码、数据和基础设施,即使用户分心或犯错也应如此。安全不同于决策权:决策权强调人能选择,安全强调系统即便在人类监督失效时也有保护义务。
自动模式威胁模型关注四类风险:过度积极行为、诚实错误、提示注入与模型错位。
2.1.3 可靠执行
Agent 应准确理解用户意图,并在长时程任务中保持一致。可靠性包括单轮正确性,也包括跨上下文窗口、恢复会话和多 Agent 委派时的长期一致性。
Claude Code 的产品文档把循环分为三阶段:收集上下文、采取行动、验证结果。工具执行后环境返回的“真实反馈”被用来判断进展。
2.1.4 能力放大
系统应显著提升人类在单位努力和成本下能完成的工作。Claude Code 的设计者把它描述为“Unix 工具,而非传统产品”:由小而可理解、可组合、可扩展的构件组成。
该架构把投资重点放在确定性的基础设施上,如上下文管理、工具路由、恢复机制,而不是显式规划器或状态图。这一选择建立在一个判断上:随着模型能力提升,丰富的操作环境比限制模型选择的框架更有价值。
2.1.5 上下文适应性
系统应适应用户的项目、工具、约定和技能水平,并随关系发展而改进。Claude Code 通过 CLAUDE.md、技能、MCP、Hooks、插件等机制,在不同上下文成本层级上提供配置能力。
纵向数据表明,用户与 Agent 的关系会变化:少于 50 次会话的用户自动批准率约 20%,到 750 次会话时超过 40%。这说明“自治”不是固定状态,而是由模型、用户与产品共同构建的信任轨迹。
2.2 十三项设计原则
|
设计原则 |
服务的价值 |
回答的设计问题 |
|---|---|---|
|
默认拒绝并升级给人类 |
决策权、安全 |
未识别动作应允许、阻止还是询问用户? |
|
渐进式信任谱 |
决策权、适应性 |
权限是固定等级,还是用户随时间穿越的谱系? |
|
多层防御 |
安全、决策权、可靠性 |
单一边界是否足够,还是需要多种机制重叠? |
|
外部化、可编程策略 |
安全、决策权、适应性 |
策略应硬编码,还是作为配置和生命周期 Hook 暴露? |
|
把上下文视为稀缺资源 |
可靠性、能力 |
绑定约束是什么,如何逐级管理? |
|
追加式持久状态 |
可靠性、决策权 |
使用可变状态、快照,还是追加日志? |
|
最小脚手架、最大操作 Harness |
能力、可靠性 |
投资推理框架,还是让模型自由推理并强化执行环境? |
|
价值优先于规则 |
能力、决策权 |
使用刚性规则,还是上下文判断加确定性护栏? |
|
可组合的多机制扩展 |
能力、适应性 |
统一扩展 API,还是不同成本层级的机制? |
|
按可逆性加权风险 |
能力、安全 |
所有动作同等监督,还是对可逆/只读动作放宽? |
|
透明的文件化配置与记忆 |
适应性、决策权 |
使用不透明数据库、向量检索,还是用户可见文件? |
|
隔离的子 Agent 边界 |
可靠性、安全、能力 |
子 Agent 共享上下文和权限,还是隔离运行? |
|
优雅恢复与韧性 |
可靠性、能力 |
遇错硬失败,还是自动恢复并只在必要时打扰人? |
2.3 从价值到架构
五类价值分别映射到具体架构:
-
人类决策权驱动默认拒绝、渐进信任、追加日志、外部策略与价值优先原则。
-
安全驱动多层防御、默认拒绝、按可逆性加权、外部策略与子 Agent 隔离。
-
可靠执行驱动上下文管理、追加式状态、优雅恢复、子 Agent 隔离与多层防御。
-
能力放大驱动最小脚手架、可组合扩展、风险加权、上下文管理与恢复机制。
-
上下文适应性驱动文件化记忆、可组合扩展、渐进信任和可编程策略。
这些映射也说明系统没有做什么:它没有强制显式规划图,没有单一统一扩展机制,也不会在恢复会话时恢复所有会话级信任状态。
2.4 评估镜头:长期能力保存
论文额外提出一个横向评估问题:该架构是否保存了人类长期能力?Anthropic 内部研究提到“监督悖论”:过度依赖 AI 可能让人类失去监督 AI 所需技能。其他研究也发现,AI 辅助条件下开发者在理解测试中的得分可能更低。
论文将长期能力保存作为评估镜头,而不是与五类价值并列的第六项设计价值,因为它在 Claude Code 的公开设计与架构中并未被明确体现。
3. 架构概览
构建生产级编程 Agent 需要回答几个反复出现的问题:推理应位于何处?需要多少执行引擎?默认安全姿态是什么?把什么资源视为瓶颈?
Claude Code 的答案是:模型负责推理,Harness 负责执行与约束;所有入口最终汇入同一个查询循环;默认安全姿态是“先拒绝、再升级给人”;上下文窗口是核心瓶颈。
3.1 设计问题与运行示例
推理位于何处?
Claude Code 中,模型决定要做什么;Harness 执行动作。模型输出 tool_use 块,Harness 解析、检查权限、调度工具并收集结果。模型不能直接访问文件系统、运行 Shell 或发起网络请求。它只能通过结构化工具协议与外部世界交互。
这一分离具有安全意义:即使模型被攻击或误导,也不能绕过沙箱、权限检查和默认拒绝规则。
有多少执行引擎?
Claude Code 使用同一个 queryLoop() 函数,无论用户通过交互式终端、无头 CLI、Agent SDK 还是 IDE 集成来使用。变化的是渲染层和用户交互层,而不是核心执行循环。
默认安全姿态是什么?
系统采用默认拒绝并升级给人的策略:拒绝规则高于询问规则,高于允许规则;未识别动作会升级给用户,而不是静默执行。权限规则、Hooks、自动模式分类器和 Shell 沙箱构成多层防御。
绑定资源约束是什么?
上下文窗口是最关键约束。系统在每次模型调用前运行五类上下文缩减策略:预算缩减、Snip、Microcompact、Context Collapse、Auto-Compact。其他系统设计也服务于节省上下文,例如懒加载指令、延迟工具 Schema、子 Agent 只返回摘要。
3.2 七个高层组件
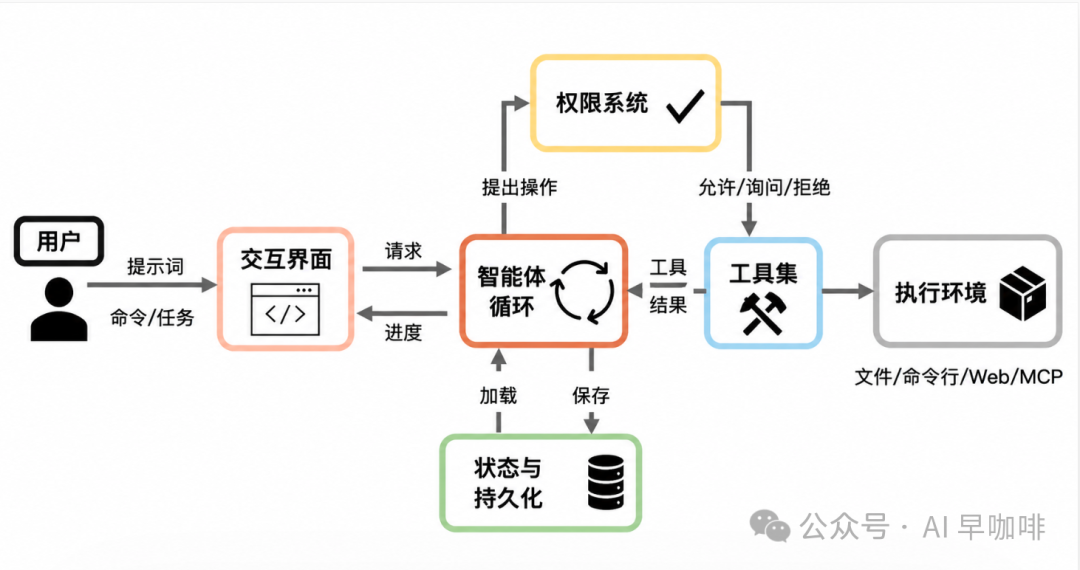
Claude Code 可分解为七个功能组件:
- 用户
:提交提示、批准权限、审阅输出。
- 接口
:交互式 CLI、无头 CLI、Agent SDK、IDE/桌面/浏览器入口。
- Agent 循环
:模型调用、工具分发与结果收集的迭代周期。
- 权限系统
:默认拒绝规则、自动模式分类器、Hook 拦截。
- 工具
:内置工具、MCP 工具、插件与技能间接贡献的能力。
- 状态与持久化
:JSONL 会话记录、全局提示历史、子 Agent Sidechain。
- 执行环境
:Shell、文件系统、Web、MCP 服务器、远程执行环境。
数据流从用户请求进入 Agent 循环,循环把动作提交给权限系统;被批准的动作进入工具层,工具与执行环境交互并把结果作为 tool_result 返回循环。状态与持久化系统记录整个过程。
3.3 五层子系统分解
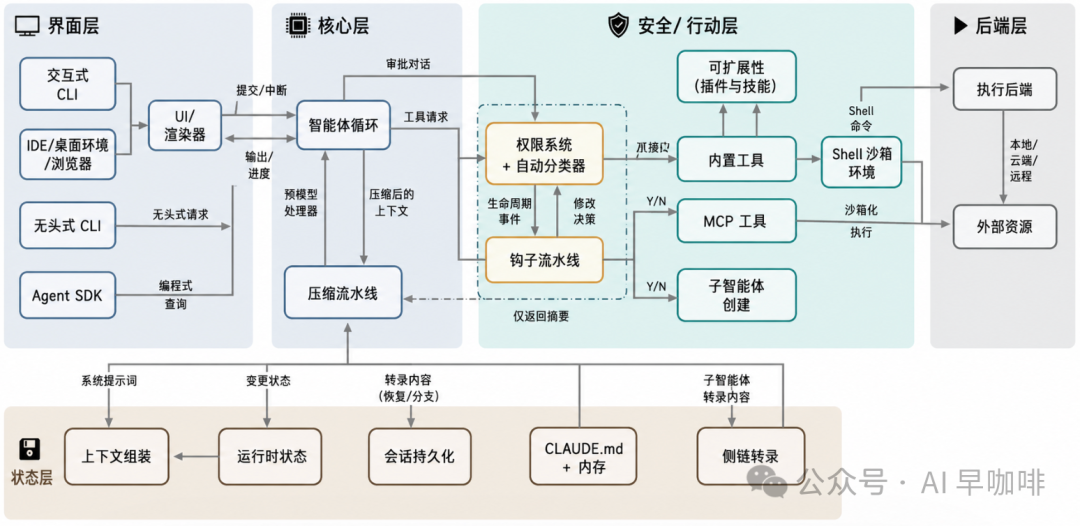
论文进一步把系统分成五层:
- 页面层
:入口与渲染,包括交互式 CLI、无头 CLI、Agent SDK、IDE/桌面/浏览器,以及终端 UI 组件。
- 核心层
:
queryLoop()与五层上下文压缩流水线。 - 安全/行动层
:权限系统、Hooks、扩展系统、内置工具、MCP 工具、Shell 沙箱、子 Agent 创建。
- 状态层
:上下文装配、运行时状态、会话持久化、
CLAUDE.md与记忆、子 Agent Sidechain。 - 后端层
:Shell 执行、远程执行、MCP 多传输连接、外部资源访问。
3.4 QueryEngine 的澄清
QueryEngine 并不是核心执行引擎,而是面向无头/SDK 路径的会话包装类。真正的共享代码路径是 query() 与内部 queryLoop()。交互式 CLI 也调用 query(),并不经过 QueryEngine。
3.5 权限与安全层
一个工具请求必须通过七个独立安全层,任意一层都可阻止它:
-
工具预过滤:被整体拒绝的工具在模型看到前就移除。
-
默认拒绝规则评估:拒绝规则永远优先。
-
权限模式约束:当前模式决定无显式规则时如何处理。
-
自动模式分类器:基于机器学习评估工具安全性。
-
Shell 沙箱:即使被批准,Shell 命令也可能在沙箱内执行。
-
恢复会话不恢复权限:会话级权限不会跨恢复/分支继承。
-
Hook 拦截:
PreToolUse、PermissionRequest等事件可介入。
3.6 上下文作为瓶颈
除压缩流水线外,多个设计都反映了上下文稀缺性:
CLAUDE.md懒加载;
-
工具 Schema 延迟加载;
-
子 Agent 只返回摘要;
-
单个工具结果有大小预算。
4. 轮次执行:代理式查询循环
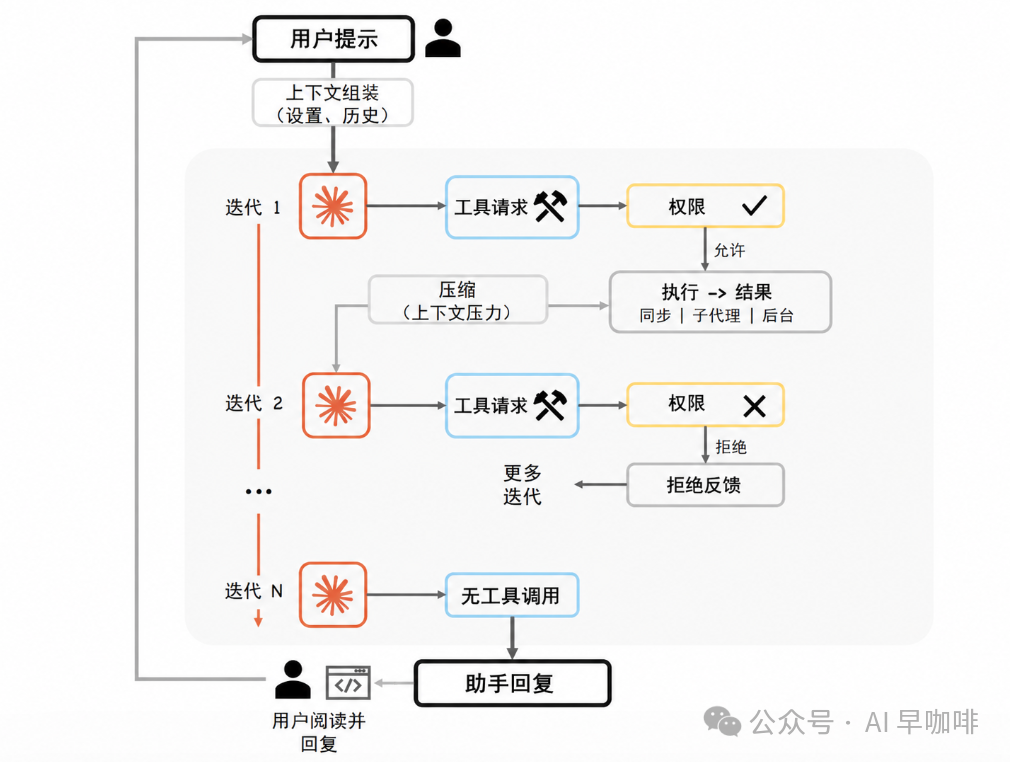
当用户输入“修复 auth.test.ts 中失败的测试”后,输入进入一个反应式循环。Claude Code 选择了简单 while 循环,而不是显式图路由或树搜索。
4.1 查询流水线
单个轮次按固定顺序执行:
- 设置解析
:解析系统提示、用户上下文、权限回调、模型配置等不可变参数。
- 可变状态初始化
:一个
State对象保存消息、工具上下文、压缩跟踪、恢复计数器等。 - 上下文装配
:从最近压缩边界之后获取消息。
- 模型前上下文整形
:依次运行五个压缩/缩减步骤。
- 模型调用
:以流式方式调用 Claude 模型。
- 工具调度
:若响应包含
tool_use,进入工具编排层。 - 权限门控
:每个工具请求通过权限系统。
- 工具执行与结果收集
:结果作为
tool_result加入对话。 - 停止条件
:若模型只产生文本而无工具调用,轮次结束。
queryLoop() 是一个异步生成器,因此 UI 层可以流式接收事件,同时核心循环保持单一同步控制流。
4.2 工具调度与流式执行
当模型返回多个工具调用时,系统可以使用 StreamingToolExecutor 在模型响应仍在流出时就开始执行工具,以减少延迟。备用路径是同步的 runTools()。
工具按是否可并发划分:只读操作可并行,修改状态的操作(如 Shell 命令)会串行执行。若某个 Bash 工具报错,Sibling Abort Controller 会终止其他正在运行的子进程。结果以工具请求顺序输出,保证模型看到的结果顺序稳定。
4.3 模型前上下文整形
五层整形依次执行:
- Budget Reduction
:限制单个工具结果大小,超大内容替换为内容引用。
- Snip
:轻量删除较老历史片段。
- Microcompact
:细粒度、缓存感知压缩。
- Context Collapse
:读时投影,不修改完整历史,只让模型看到折叠视图。
- Auto-Compact
:最后手段,调用模型生成压缩摘要。
这种设计的思想是“惰性降级”:先使用破坏性最小的压缩,再逐步升级。
4.4 恢复机制
查询循环包含多种恢复策略:
-
输出 Token 上限提升;
-
响应式压缩;
-
Prompt 过长处理;
-
流式调用回退;
-
备用模型切换。
4.5 停止条件
循环可因以下原因停止:
-
模型没有工具调用;
-
达到最大轮次;
-
上下文溢出;
-
Hook 阻止继续;
-
用户或系统显式中止。
5. 工具授权与控制边界
Claude Code 在安全架构上组合了逐动作权限评估和可选 OS/命令沙箱。核心原则包括默认拒绝、渐进信任、多层防御和按可逆性加权风险。
当 Claude 想执行 npm test 来复现测试失败时,请求会进入权限流水线。默认行为不是静默允许,而是拒绝或询问。
5.1 权限模式与规则评估
系统存在七类权限模式:
- plan
:模型必须先生成计划,经用户批准后再执行。
- default
:标准交互模式,大多数操作需用户批准。
- acceptEdits
:工作目录内编辑和部分文件系统命令自动批准。
- auto
:启用机器学习分类器评估未快速通过的请求。
- dontAsk
:不询问,但仍执行拒绝规则。
- bypassPermissions
:跳过多数权限提示,但安全关键检查仍保留。
- bubble
:内部模式,用于子 Agent 把权限请求升级到父终端。
规则评估采用“拒绝优先”:即使允许规则更具体,拒绝规则也总是获胜。规则可匹配工具级别,也可匹配工具输入内容,如 Bash(prefix:npm)。
5.2 授权流水线
完整授权过程包括:
- 预过滤
:模型看不到被 blanket deny 的工具。
- PreToolUse Hook
:可拒绝、询问或修改工具输入。
- 规则评估
:默认拒绝规则引擎执行匹配。
- 权限处理器
:根据运行环境走协调器、Swarm Worker、投机分类器或交互式用户对话路径。
当分类器或拒绝规则阻止动作时,系统不会简单终止,而是把拒绝原因反馈给模型。模型可以在下一轮尝试更安全方案。这使权限系统不只是“刹车”,也是行为塑形机制。
5.3 自动模式分类器与 Hook 生命周期
自动模式分类器会加载基础系统提示、外部权限模板,以及 Anthropic 内部用户模板。它根据对话记录和权限模板产生允许、拒绝或人工审批建议。
与权限相关的 Hook 事件包括:
PreToolUse:可返回权限决策、原因和更新后的输入。
PostToolUse:可注入额外上下文,或修改 MCP 工具输出。
PostToolUseFailure:可为错误注入指导信息。
PermissionDenied:可提供重试建议。
PermissionRequest:可异步返回允许或拒绝。
5.4 Shell 沙箱
Shell 沙箱与应用层权限系统互补:权限决定“是否可执行”,沙箱决定“执行时能接触什么”。一个命令可被批准但仍在沙箱中运行,也可被权限系统拒绝而永远不进入沙箱。
论文指出,多层防御依赖层之间相互独立;如果多个层共享同一性能约束,防御可能同时退化。例如有安全研究指出,超过 50 个子命令的复杂命令可能退化为单一通用批准提示,以避免 UI 卡顿。
6. 扩展性:MCP、插件、技能与 Hooks
编程 Agent 必须决定扩展面如何组织:一个统一机制、少数专门机制,还是一组不同上下文成本的分层机制。Claude Code 选择了四类机制。
6.1 四类扩展机制
MCP 服务器
Model Context Protocol 是主要外部工具集成路径。MCP 服务器可来自项目、用户、本地、企业配置,也可由插件或 claude.ai 合并。客户端支持 stdio、SSE、HTTP、WebSocket、SDK、IDE 专用变体等多种传输方式。
插件
插件既是打包格式,也是分发机制。插件 Manifest 支持命令、Agent、技能、Hooks、MCP 服务器、LSP 服务器、输出风格、频道、设置和用户配置等组件。一个插件可以同时扩展多个子系统。
技能
技能由带 YAML Frontmatter 的 SKILL.md 定义。字段可包括显示名、描述、允许工具、参数提示、模型覆盖、执行上下文、相关 Agent、努力等级和 Shell 配置。技能被调用时,SkillTool 会把技能说明注入上下文。
Hooks
源代码定义了 27 类 Hook 事件,覆盖工具授权、会话生命周期、用户交互、子 Agent 协调、上下文管理、工作区事件与通知。Hooks 可以阻止、重写、标注工具调用,也可注入上下文。
6.2 工具池装配
assembleToolPool() 是合并内置工具与 MCP 工具的单一事实来源。装配流程为:
-
枚举基础工具:最多 54 个工具,其中 19 个始终包含,其余受特性开关、环境变量和用户类型影响。
-
模式过滤:简单模式只保留 Bash、Read、Edit 等核心工具。
-
拒绝规则预过滤:被 blanket deny 的工具不进入模型视野。
-
合并 MCP 工具:MCP 工具也接受拒绝规则过滤。
-
去重:内置工具优先于 MCP 工具。
6.3 为什么需要四种机制?
四种机制的差别在于上下文成本和表达能力:
|
机制 |
独特能力 |
上下文成本 |
插入点 |
|---|---|---|---|
|
MCP 服务器 |
外部服务集成 |
高:工具 Schema |
模型可调用工具池 |
|
插件 |
多组件打包与分发 |
中:视组件而定 |
全部注入点 |
|
技能 |
领域指令与元工具调用 |
低:通常只放描述 |
上下文装配 |
|
Hooks |
生命周期拦截与事件自动化 |
默认零成本 |
执行前后 |
这种分层允许低成本扩展广泛存在,而高成本工具 Schema 只在真正需要外部能力时进入上下文。
7. 上下文构造与记忆
Agent 如何管理上下文窗口、如何持久化用户指令,是核心设计选择。Claude Code 采用透明、文件化的记忆体系,并配合渐进式上下文压缩。
7.1 上下文窗口装配
模型调用前,上下文由以下来源装配:
-
系统提示,包括输出风格和附加系统提示。
-
环境信息:Git 状态、内部构建缓存破坏注入等。
CLAUDE.md层级:多级指令文件。
-
路径作用域规则:读到匹配目录中的文件时懒加载。
-
自动记忆:异步预取相关记忆条目。
-
工具元数据:技能描述、MCP 工具名、延迟工具定义。
-
对话历史:受压缩影响。
-
工具结果:文件读取、命令输出、子 Agent 摘要。
-
压缩摘要:替代较旧历史片段。
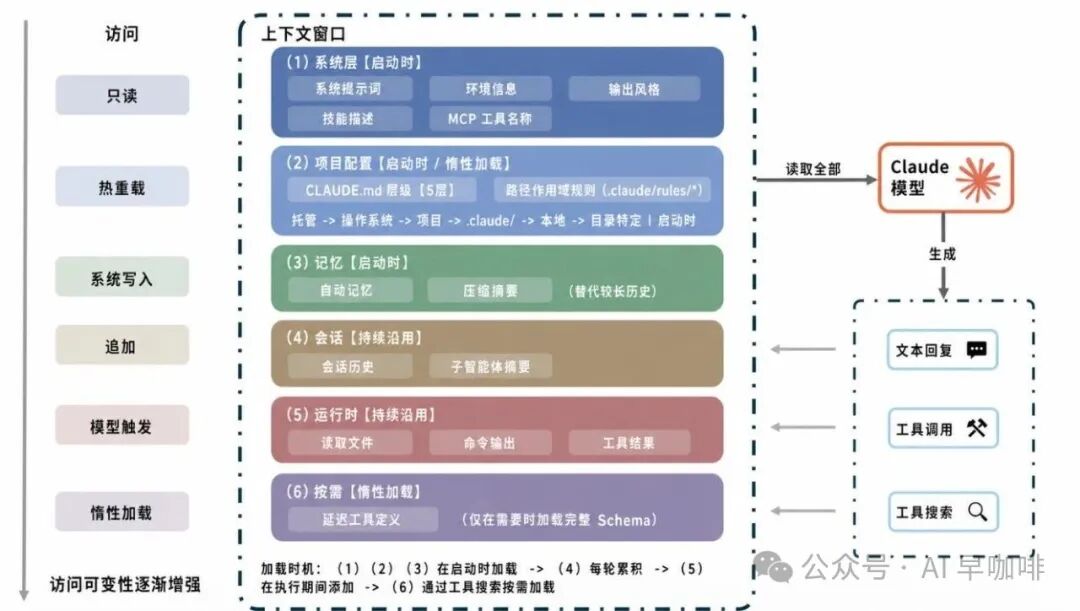
系统提示与用户上下文在 API 请求中结构位置不同:CLAUDE.md 内容作为用户上下文消息,而非系统提示。这意味着它更像指导而非强制规则。
7.2 CLAUDE.md 层级与自动记忆
记忆系统的原则是:Agent 看到的持久上下文应当可被用户检查、编辑、版本控制和删除。因此 Claude Code 使用 Markdown 文件,而不是不透明数据库或向量索引。
CLAUDE.md 有四类记忆:
- 托管记忆
:如 Linux 上
/etc/claude-code/CLAUDE.md,用于 OS 级策略。 - 用户记忆
:如
~/.claude/CLAUDE.md,私人全局指令。 - 项目记忆
:项目根目录中的
CLAUDE.md、.claude/CLAUDE.md和.claude/rules/*.md。 - 本地记忆
:
CLAUDE.local.md,通常被 Git 忽略,用于私人项目指令。
文件按“优先级反向”加载:后加载文件更受模型关注。越接近当前目录的文件优先级越高。嵌套目录下的规则可在读取相关文件时懒加载,因此模型的指令集会随探索代码库而演化。
系统还支持 @include 指令,用于模块化指令文件;循环引用会被检测并避免。
7.3 压缩流水线
五层压缩流水线体现了“上下文是瓶颈”:
-
工具结果预算限制;
-
较旧历史轻量裁剪;
-
缓存感知微压缩;
-
读时历史折叠视图;
-
模型生成的完整摘要。
buildPostCompactMessages() 会产生压缩边界、摘要消息、保留消息、附件和 Hook 结果。设计上尽量追加写入,而不是修改或删除已写入的转录行。
8. 子 Agent 委派与编排
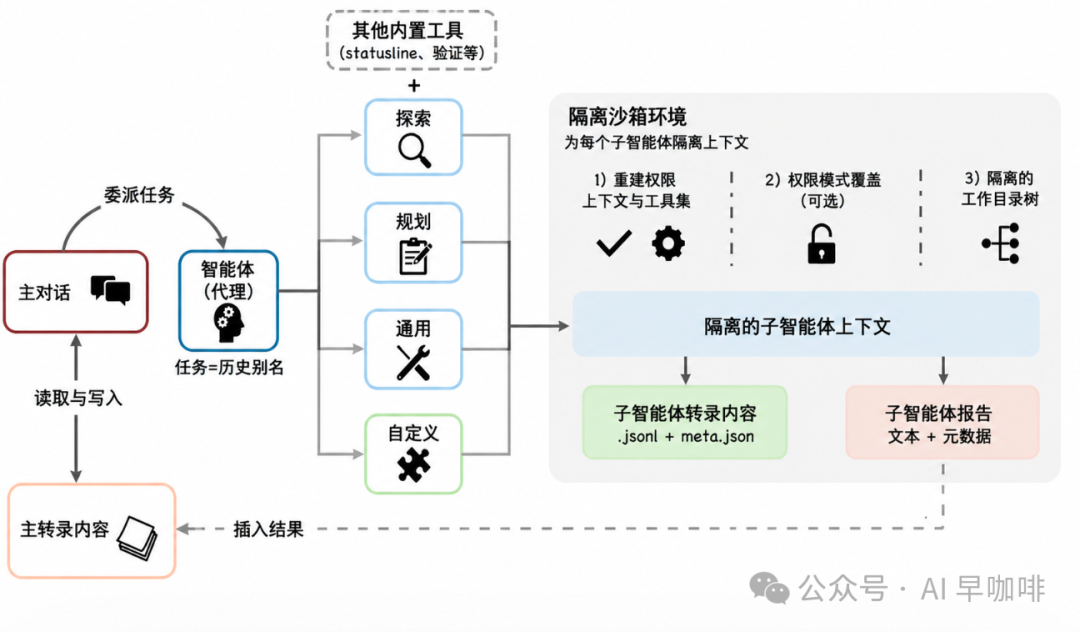
多 Agent 编排是编程 Agent 的关键设计维度。Claude Code 的子 Agent 架构强调隔离边界:子 Agent 在独立上下文中运行,拥有重建后的权限上下文和独立工具集,最后只把摘要返回父对话。
8.1 Agent 工具与委派条件
委派通过 AgentTool 实现,Task 是保留的旧别名。模型调用 Agent 时,会提供委派提示、可选子 Agent 类型、隔离模式、权限覆盖和工作目录等结构化输入。
内置子 Agent 类型包括:
- Explore
:主要用于只读探索,通常禁止写入和编辑工具。
- Plan
:创建结构化计划。
- General-purpose
:通用能力,用户明确要求时使用。
- Claude Code Guide
:用于上手与文档帮助。
- Verification
:运行验证检查,如测试和 Lint。
- Statusline-setup
:配置终端状态栏。
用户也可通过 .claude/agents/*.md 定义自定义子 Agent,插件也可贡献 Agent 定义。每个 Agent 可拥有自己的系统提示、工具白名单/黑名单、模型、努力等级、权限模式、MCP 服务器、Hooks、最大轮次、技能、记忆作用域和隔离模式。
8.2 隔离架构
Claude Code 支持多种隔离方式:
- Worktree
:创建临时 Git Worktree,让子 Agent 在独立仓库副本中修改。
- Remote
:内部用户可在 Claude Code Remote 环境中运行。
- In-process
:默认方式,共享文件系统但隔离会话上下文。
权限覆盖有优先级:若父会话处于 bypassPermissions、acceptEdits 或 auto 等明确用户决策的模式,子 Agent 的权限覆盖不会取代父模式。
8.3 Sidechain 转录
每个子 Agent 写入独立的 .jsonl 和 .meta.json 文件。完整子 Agent 历史用于调试与审计,但不会进入父上下文。父对话只接收最终响应文本与元数据。
这种“摘要返回”模型是上下文节省选择。若把所有子 Agent 历史都共享给父对话,会导致上下文爆炸。
9. 会话持久化与恢复
会话持久化需要在追加日志、结构化数据库、快照和无状态架构之间做选择。Claude Code 采用以追加为主的 JSONL 记录。
9.1 转录模型
系统有三条独立持久化通道:
- 会话转录
:项目作用域,每个会话一个 JSONL 文件,保存用户、助手、附件、系统消息、压缩边界等事件。
- 全局提示历史
:只保存用户提示,存于配置目录的
history.jsonl。 - 子 Agent Sidechain
:每个子 Agent 单独的
.jsonl与.meta.json。
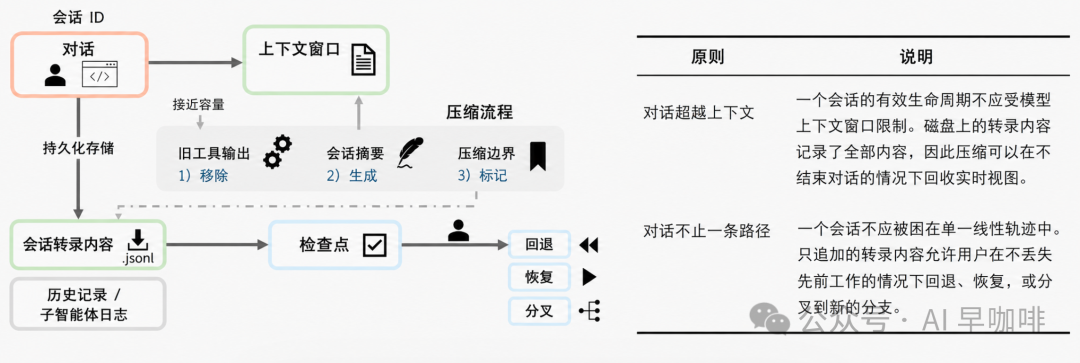
追加式 JSONL 有审计性和简单性优势:人类可读、可版本控制、无需专门数据库即可重建。但它牺牲了复杂查询能力。
9.2 恢复、分叉与不恢复权限
--resume 会通过重放转录重建对话。分叉会从已有会话创建新会话。然而,会话级权限不会被恢复或分叉继承。用户必须在新会话中重新授权。
这是安全保守选择:会话被视为独立信任域。恢复旧授权虽然方便,却可能把陈旧信任带入已变化的上下文。
压缩边界通过记录 headUuid、anchorUuid、tailUuid 来支持读取时修补消息链。旧转录不被重写,压缩只追加边界和摘要事件。
10. 对比分析:Claude Code 与 OpenClaw
OpenClaw 是一个本地优先的 WebSocket 网关,可把 WhatsApp、Telegram、Slack、Discord、Signal 等约二十多个消息表面连接到嵌入式 Agent 运行时,并拥有 macOS、iOS、Android 伴随应用。
Claude Code 是绑定到单个仓库会话的 CLI 编程 Harness;OpenClaw 是面向多通道个人助手的持久控制平面。二者处于 Agent 设计空间的不同区域。
10.1 六个比较维度
|
维度 |
Claude Code |
OpenClaw |
|---|---|---|
|
系统范围 |
CLI/IDE 编程 Harness,会话级短生命周期进程 |
持久 WebSocket 网关守护进程,多通道控制平面 |
|
信任模型 |
逐动作默认拒绝、Hooks、可选 ML 分类器、七种权限模式 |
单个可信操作者,DM 配对与发送者白名单,沙箱可选 |
|
Agent 运行时 |
queryLoop()
异步生成器是系统中心 |
Pi-agent Runner 嵌入网关 RPC 调度中 |
|
扩展架构 |
MCP、插件、技能、Hooks,按上下文成本分层 |
Manifest 优先插件系统,12 类能力,中央注册表 |
|
记忆与上下文 |
CLAUDE.md
层级、五层压缩、LLM 记忆扫描 |
工作区 Bootstrap 文件、长期记忆、每日笔记、可选混合检索 |
|
多 Agent 与路由 |
任务委派子 Agent、Worktree 隔离、摘要返回 |
多 Agent 路由与子 Agent 委派分离,支持通道绑定和嵌套深度 |
10.2 对比揭示了什么
对比产生三点观察:
-
设计问题是稳定的:推理位置、安全姿态、上下文管理、扩展结构等问题并不只属于编程 Agent。
-
两个系统在多个维度做出相反押注:Claude Code 投资逐动作安全评估,OpenClaw 投资边界级身份与访问控制;Claude Code 以 Agent 循环为中心,OpenClaw 以网关控制平面为中心。
-
二者可以组合:OpenClaw 可通过 ACP 承载 Claude Code,把它作为外部编程 Harness。
11. 讨论
论文将前文六个子系统分析综合起来,讨论设计哲学、价值张力、架构权衡和经验预测。
11.1 设计哲学
Claude Code 投资于操作基础设施,而不是复杂决策脚手架。系统绝大多数代码是确定性 Harness:权限门、工具路由、上下文管理、恢复逻辑。LLM 被当作无状态补全端点调用。
这与许多 Agent 框架不同:后者把模型输出路由到显式图节点和类型边中。Claude Code 更倾向于给模型最大决策自由,同时用丰富 Harness 提供执行和安全边界。
随着前沿模型在编程任务上能力趋同,周围操作 Harness 的质量可能成为主要差异化因素。
11.2 价值张力
|
价值组合 |
张力 |
证据或例子 |
|---|---|---|
|
决策权 × 安全 |
审批疲劳 vs. 保护 |
用户批准约 93% 权限提示,安全不能只依赖人类警觉 |
|
安全 × 能力 |
性能 vs. 防御深度 |
复杂命令为避免 UI 卡顿可能跳过逐子命令检查 |
|
适应性 × 安全 |
扩展性 vs. 攻击面 |
Hooks 和 MCP 服务器初始化可能引入预信任攻击面 |
|
能力 × 适应性 |
主动性 vs. 打扰 |
主动助手能增加任务完成,但高频率会降低偏好 |
|
能力 × 可靠性 |
速度 vs. 一致性 |
有界上下文限制全局代码库认知,子 Agent 隔离影响一致性 |
长期能力保存也引入额外张力:AI 工具可能提高短期产出,但增加代码复杂度、削弱理解能力或影响新手成长路径。
11.3 架构权衡
安全 vs. 自主性
权限模式构成从计划模式到绕过权限的渐变谱。随着自主性提高,安全从人工审批转向自动检查与沙箱。
对抗条件下的权限模型
安全研究显示,某些漏洞来自初始化顺序:Hooks、MCP 连接和设置解析可能在用户信任对话前执行。这说明权限图不仅要考虑空间上的检查顺序,也要考虑时间上的初始化顺序。
上下文效率 vs. 透明性
五层压缩提高上下文利用效率,但部分压缩对用户不可见。用户可能难以清楚知道哪些信息被丢弃或摘要化。
简单性 vs. 扩展性
四类扩展机制组合能力强,但也带来交互复杂性:插件 Hook、分类器、懒加载规则、权限处理器分支等可能产生涌现行为。
11.4 经验预测与早期信号
该架构产生可测试预测:由于上下文窗口有限,Agent 生成代码可能更容易出现模式重复、约定违反和局部最优。子 Agent 隔离会加剧这种风险,因为并行 Agent 可能各自重新实现已有方案。
相邻系统的研究显示,AI 工具采用可能伴随代码复杂度增加和技术债持续存在。但 Claude Code 的渐进压缩、摘要隔离和缓存感知机制是否足以缓解这些问题,仍需经验验证。
11.5 局限
源代码分析存在限制:构建目标和 Feature Flag 会导致行为差异;上下文装配函数有缓存,运行时变化可能不立即反映;许多机制可能受内部构建或实验开关影响。
11.6 新兴方向
论文指出几个更广阔方向:
-
更长上下文窗口可能减轻压缩压力;
-
多模态工具将扩大工具面并带来新上下文挑战;
-
权限性质的形式化验证可增强安全保证;
-
Harness 组件可能逐步虚拟化,使会话、Harness、沙箱成为可替换接口;
-
记忆会从上下文副产物变成一等子系统;
-
可观测性需要与离线评估、生成器-评估器分离结合;
-
治理和监管将要求更明确的日志、透明度和人类监督接口;
-
主动式 Agent(如论文提到的 KAIROS)将引入用户在场感知和成本节流问题。
11.7 反复出现的设计选择
三项跨子系统承诺贯穿全文:
- 分层机制优于单体机制
:安全、上下文和扩展都采用多层独立机制。
- 追加式设计偏向审计性而非查询能力
:JSONL 转录、压缩边界、权限不恢复都服务于可审计。
- 确定性 Harness 中的模型判断
:模型保留工具选择和行动顺序自由,Harness 负责执行条件与边界。
12. 未来方向
论文提出六个开放问题。
12.1 静默失败与可观测性-评估鸿沟
生产 Agent 的主要失败模式往往不是崩溃,而是静默错误。可观测性已较普及,但离线评估仍不足。开放问题是:评估脚手架应内置于 Harness,还是作为独立层?现有 Hook 管线是否能承载这种评估而不耗尽上下文?
12.2 持久化:记忆与长期同事关系
系统当前有 CLAUDE.md 静态指令层和 JSONL 会话转录层。两者之间是否需要新的“可积累经验层”?它如何同时承载个人指令、组织上下文和长期工作关系?又如何避免恢复旧权限带来的安全风险?
12.3 Harness 边界演化:在哪里、何时、做什么、与谁协作
未来 Harness 可能沿四个方向扩展:
- 在哪里运行
:会话、Harness、沙箱虚拟化为接口;
- 何时行动
:从反应式转向主动式;
- 作用于什么
:从文本/代码扩展到视觉-语言-动作和物理世界;
- 与谁协作
:从父子 Agent 扩展到角色分化、多 Agent 辩论和图式工作流。
12.4 长时程扩展:从会话到科研项目
当 Agent 工作从单个会话延长到数天、数周甚至科学研究项目时,现有转轮、会话、子 Agent、记忆是否仍足够?这可能需要跨会话记忆、长期协调原语或新的 Harness 层。
12.5 规模化治理与监督
AI 监管将对架构提出外部约束:日志、透明度、人类监督、版权与数据来源等。当前内部可审计的 JSONL 转录是否足以满足外部监管接口?“价值优先于规则”的设计能否转化为合规审查所需的明确规则表达?
12.6 重新审视评估镜头:长期人类能力
如果长期人类能力保存要成为一等设计问题,需要回答两个问题:
-
能否在会话粒度测量理解能力、认知卸载和代码约定漂移?
-
一旦测量存在,架构应如何响应?是通过生成器-评估器分离、理解保护界面,还是由 IDE、组织流程或人类学习机制承担?
13. 相关工作
论文把 AI 编程工具按自治程度分为四类:
|
类别 |
例子 |
模式 |
|---|---|---|
|
内联补全 |
Copilot, Tabnine |
编辑器插件 |
|
聊天集成 |
Cursor, Windsurf, Cody |
IDE 耦合产品 |
|
代理式 CLI |
Claude Code, Codex CLI, Aider |
工具使用循环 |
|
完全自主 |
Devin, SWE-Agent, OpenHands |
沙箱 + 规划 |
Claude Code 的核心循环遵循 ReAct 模式:模型生成推理与工具调用,Harness 执行动作,结果反馈给下一轮。它也与 LangGraph、AutoGen、CrewAI、SWE-Agent、OpenHands、Aider 等系统在安全、上下文、协议和软件架构层面形成对照。
在上下文管理上,常见方法包括简单截断、滑动窗口、RAG、单次摘要和渐进压缩。Claude Code 采用多层渐进压缩。
在安全上,不同系统可使用逐动作审批、分类器自动化、容器沙箱、文件系统沙箱、Git 回滚或会话权限重置。Claude Code 选择把多种机制叠加。
在扩展协议上,MCP 已成为事实标准之一,也带来了工具投毒、跨服务器阴影和 Rug Pull 等新的攻击面。
14. 结论
生产级编程 Agent 可以被理解为对一组反复出现设计问题的回答:推理相对于 Harness 的位置、执行如何组织、安全如何默认、扩展如何划分、上下文如何管理、子 Agent 如何委派、会话如何持久化。
Claude Code 在这个空间中占据了清晰位置:它给予模型广泛的局部自治,同时用密集、确定性的 Harness 包围模型,负责权限、工具路由、上下文压缩、扩展和会话恢复。
OpenClaw 对比进一步说明,同样的设计问题会在不同部署语境中产生不同答案:Claude Code 在 CLI Harness 中投资逐动作安全分类和渐进式上下文压缩;OpenClaw 在多通道网关中投资边界级访问控制和结构化长期记忆。二者甚至可以组合,OpenClaw 可把 Claude Code 作为外部 Harness 承载。
对 Agent 构建者而言,最重要的开放问题也许不是“如何增加更多自治”,而是“如何在长期保存人类能力”。当前架构显著放大短期能力,但对长期人类理解、代码库一致性和开发者成长的显式支持仍然有限。未来系统可以把这一可持续性缺口作为一等设计问题,而不是事后评估指标。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)