智能路由引擎,重塑推理性能与效率
·
在大模型应用落地的浪潮中,企业正面临一个尴尬的现实:模型能力越来越强,但推理体验却成为用户流失的“隐形杀手”。长达数秒的等待、不稳定的响应速度、居高不下的算力成本,正在侵蚀着 AI 应用的商业价值。
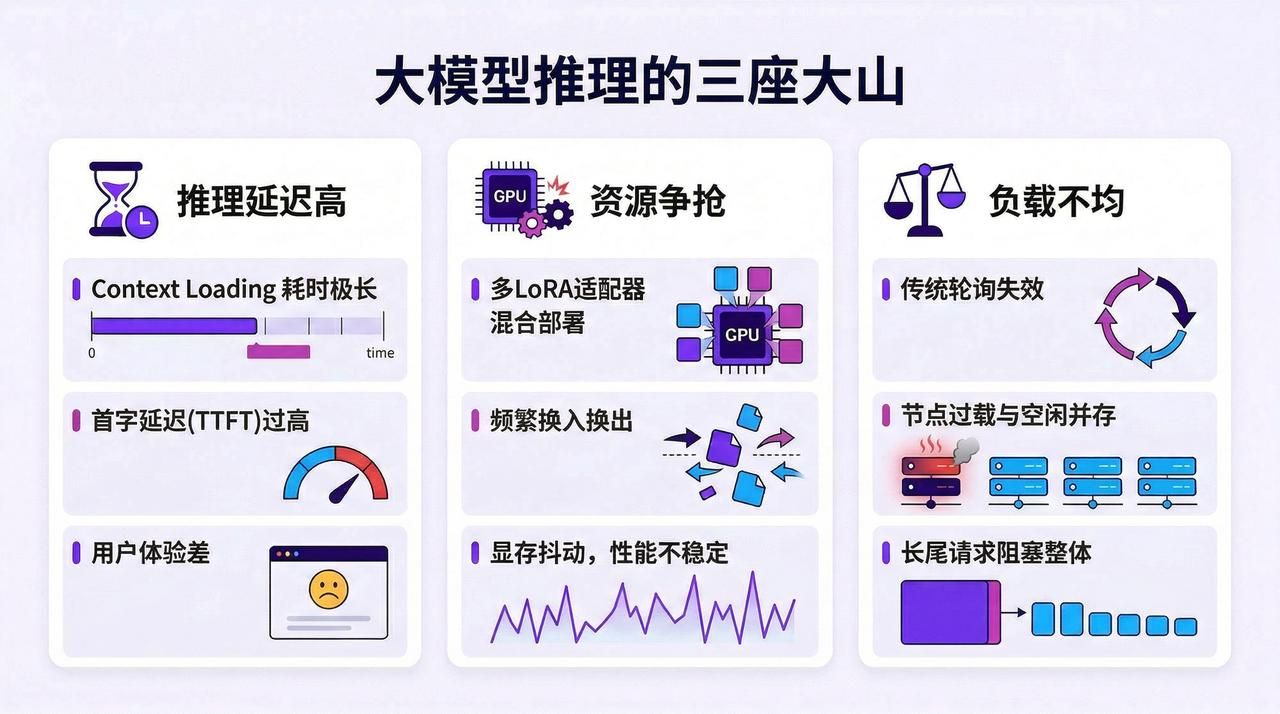
大模型推理的“三座大山”
当企业将大模型部署到生产环境,三个痛点如影随形地出现:
- 推理延迟高,用户体验差:每次请求都要重新加载上下文(Context Loading),这个过程耗时极长,导致首字延迟(TTFT)过高。想象一下,用户在知识库问答系统中提问,等待首字出现的时间长到足以让他们关闭页面,这么差的用户体验自然会影响用户留存、产品口碑,这就是推理高延迟带来的真实代价。
- 资源争抢,性能不稳定:当多个 LoRA 适配器混合部署时,频繁的换入换出会导致显存剧烈抖动。上一秒还流畅的推理服务,下一秒可能因为适配器切换而卡顿,性能的不可预测性让 SLA 承诺变成空谈。
- 负载不均,请求阻塞 :简单的轮询策略完全无法感知长短文本生成的巨大耗时差异,结果就是:一些节点因为处理长文本请求而过载,另一些节点却在空闲等待,长尾请求阻塞了整体吞吐,资源利用率和用户体验双双受损。
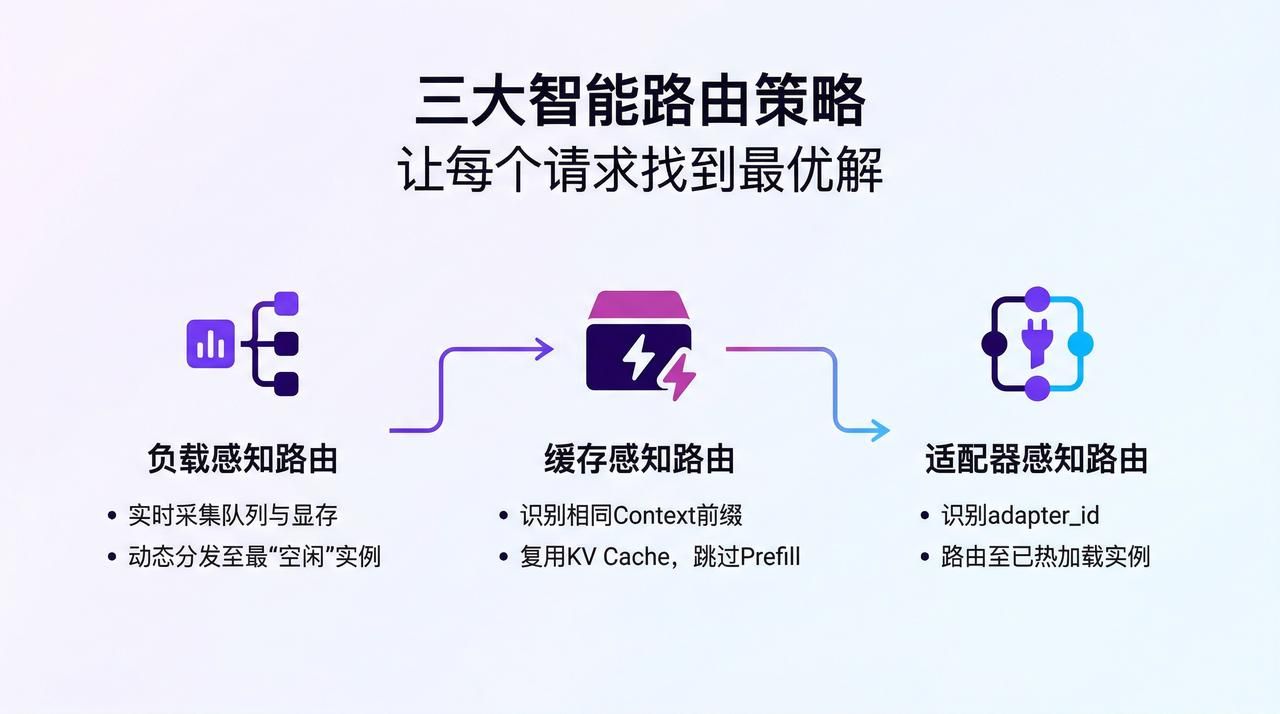
智能路由,让每个请求找到“最优解”
硅基流动的私有化 MaaS 平台内置了网关系统,有效解决上述大模型推理存在的三大问题。该网关系统由三大路由策略协同工作,为每个推理请求找到最优的执行路径,其核心在于将路由决策从“盲目分发”升级为“智能匹配”。
- Load-Aware Routing(负载感知路由):实时采集每个实例的队列长度和显存容量,动态将请求分发到最“空闲”的节点。这不是简单的轮询,而是基于实时状态的精准调度,确保负载始终均衡分布。
- KV-Cache Aware Routing(缓存感知路由):识别具有相同 Context 前缀的请求,将它们路由到已缓存相应 KV Cache 的实例,直接跳过耗时的 Prefill 阶段。对于知识库问答、文档分析等场景,这意味着首字延迟可以从数秒降至毫秒级。
- LoRA Aware Routing(适配器感知路由):解析请求中的 adapter_id,将其路由到已经热加载该 LoRA 权重的实例。避免了频繁的适配器换入换出,消除了显存抖动,让多模型混合部署变得稳定可控。
三个策略协同,构建了一个“懂业务”的智能路由引擎。它不仅知道每个节点的状态,还理解每个请求的特征,从而做出最优的匹配决策。
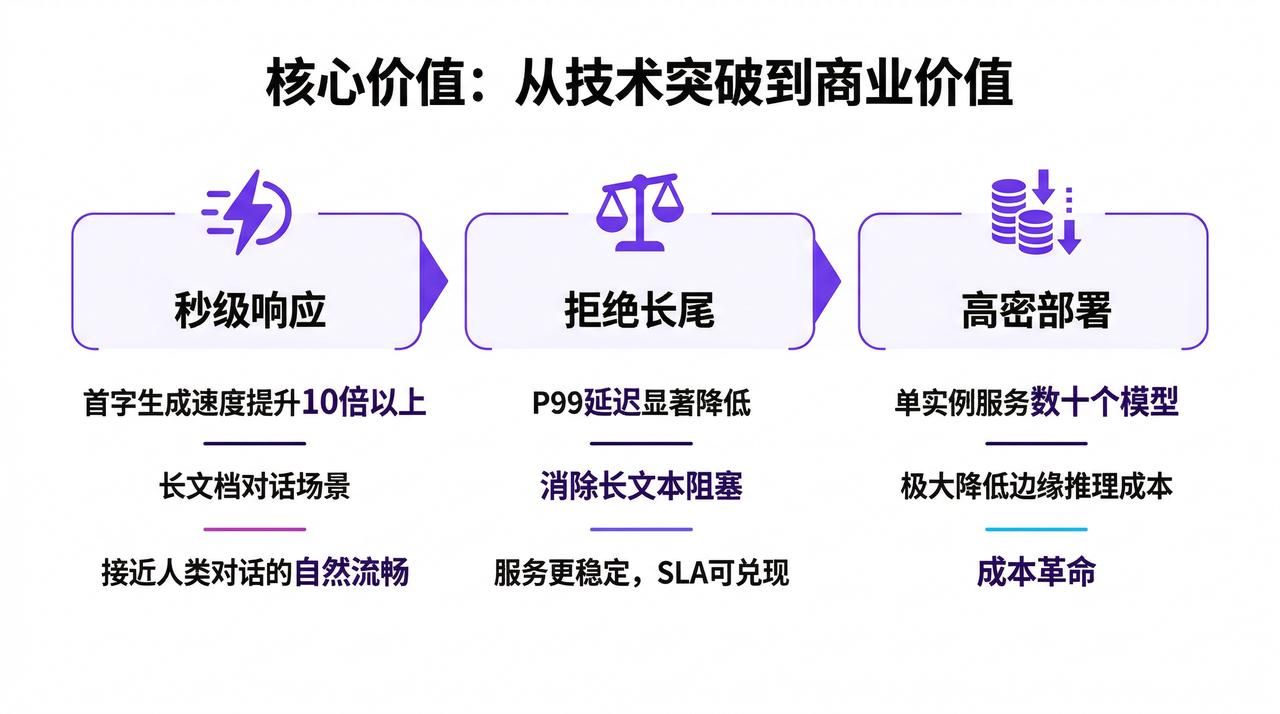
重塑推理体验
智能路由带来的改变,不只是技术指标的优化,更是用户体验和商业模式的重塑。
- 秒级响应:在长文档对话、知识库检索等场景下,首字生成速度提升 10 倍以上。用户不再需要“等待”,AI 应用的交互体验真正接近人类对话的自然流畅。
- 消除长尾效应:长文本请求不再阻塞整体服务,消除因此带来的整体抖动,P99 延迟显著降低。这意味着即使在高峰时段,99% 的用户都能获得稳定的响应速度,SLA 承诺变得可兑现。
- 高密部署:单个推理实例可以同时高效服务数十个微调模型,极大降低了边缘推理和私有化部署的成本门槛。对于需要为不同客户、不同场景定制模型的企业来说,这是真正的成本革命。
大模型时代的竞争,已经从“谁的模型更强”转向“谁能让模型更好用”“谁的推理 ROI 更高”。推理性能和效率不再是技术团队内部的 KPI,而是直接影响用户留存和商业转化的关键变量。
硅基流动私有化 MaaS 内置网关的智能路由引擎,正是面向大模型时代重塑推理性能与效率的利器,是 AI 真正走向规模化落地的关键技术基建。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)