一个人,一天,用 AI Agent 搭建了一个全功能多模型 AI 聊天平台
文记录了我使用 WorkBuddy(AI 编程 Agent)在一天内从零搭建 MultiChat 的完整过程。 这是一个集聊天、竞技场对比、模型评测、插件系统、技能市场、支付系统于一体的多模型 AI 聚合平台,后端对接了国内外 7 家大模型厂商。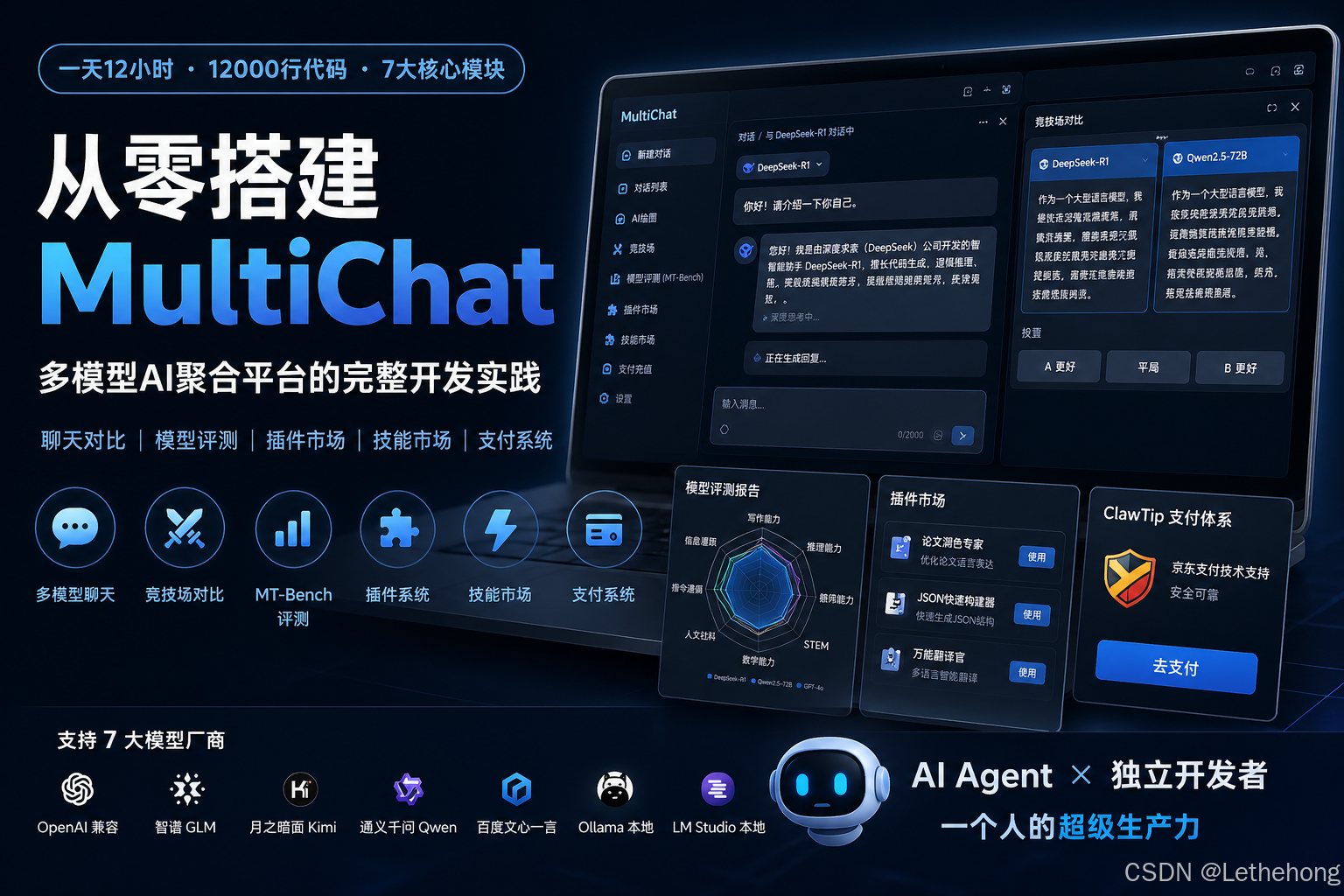
目录
中午(12:00-14:30):AI 绘图 + 插件系统 + 竞技场 + UI 精修
下午(14:30-18:00):MT-Bench 模型评测 + 每日金句
晚上(18:00-21:00):本地模型 + 用户系统 + ClawTip 支付
为什么写这篇文章
作为一名独立开发者,我一直想做一个"大模型聚合器"——一个能同时对接 DeepSeek、Qwen、文心一言、Kimi 等多家模型的统一入口,并且能直观对比不同模型的回答质量。
但面对前端 UI、后端 API、多厂商适配、支付系统这些工作量,我一个人做要多久?答案可能是几个月。
直到我遇到了 WorkBuddy——一个嵌入在 IDE 中的 AI 编程 Agent。它不只是帮你写代码,它理解项目上下文、记忆你的技术偏好、能自主拆解任务并逐步执行。
最终结果:一天时间,产出了约 12000 行代码,7 个核心模块全部可用。
项目概览:MultiChat 是什么
MultiChat 是一个全功能的多模型 AI 聊天平台,技术栈非常精简:
- 前端:纯原生 HTML + CSS + JavaScript(单文件 SPA,无框架依赖)
- 后端:Node.js + Express
- 数据库:IndexedDB(前端,Dexie.js)+ JSON 文件(后端)
- 支付:京东 ClawTip 支付体系(SM4-ECB 加密 + X402 协议)
核心功能模块:
|
模块 |
功能描述 |
|
💬 多模型聊天 |
支持同时管理多个 API 供应商,一键切换模型,流式输出,Markdown 渲染,代码高亮 |
|
🖼️ AI 绘图 |
集成 DALL-E 等绘图模型,支持自定义绘图接口,内置多种尺寸和风格预设 |
|
⚔️ 竞技场 |
同时向 2-3 个模型发送相同问题,并排对比回答,支持投票评分 |
|
📊 模型评测 (MT-Bench) |
8 大能力维度(写作/推理/编码/数学等),16 道内置题目,LLM-as-Judge 自动评分,雷达图可视化 |
|
🔌 插件市场 |
Prompt 类型插件系统,支持触发词匹配、变量表单、导入导出、斜杠命令触发 |
|
⚡ 技能市场 |
类似 ChatGPT GPTs 的技能系统,内置周报生成器、小红书文案写手、万能翻译官等 |
|
💳 充值支付 |
京东 ClawTip 支付体系集成,SM4-ECB 加密,用户注册登录,技能按消息计费 |
支持的模型厂商(后端适配器模式):
OpenAI 兼容 │ 智谱 GLM │ 月之暗面 Kimi │ 通义千问 Qwen
百度文心一言 │ Ollama 本地 │ LM Studio 本地开发过程:一天十二小时
上午(9:00-12:00):基础框架 + 核心聊天
目标:搭建能跑的聊天原型。
上午的工作是最基础的——前端单页应用框架、后端 Express 服务、聊天核心功能。
AI Agent 帮我完成了:
- 前端 SPA 架构:侧边栏(对话列表)+ 主区域(聊天界面)的经典布局,深色/亮色主题切换,完整的 CSS 变量体系
- 后端 API:Provider CRUD、对话 CRUD、
/v1/chat/completions代理接口 - 多模型适配器:基于工厂模式的适配器架构(
BaseAdapter→ 各厂商实现),每种模型的认证、请求格式、SSE 流式解析都做了封装 - 流式聊天:SSE 流式输出 + 实时 Markdown 渲染 + 代码高亮
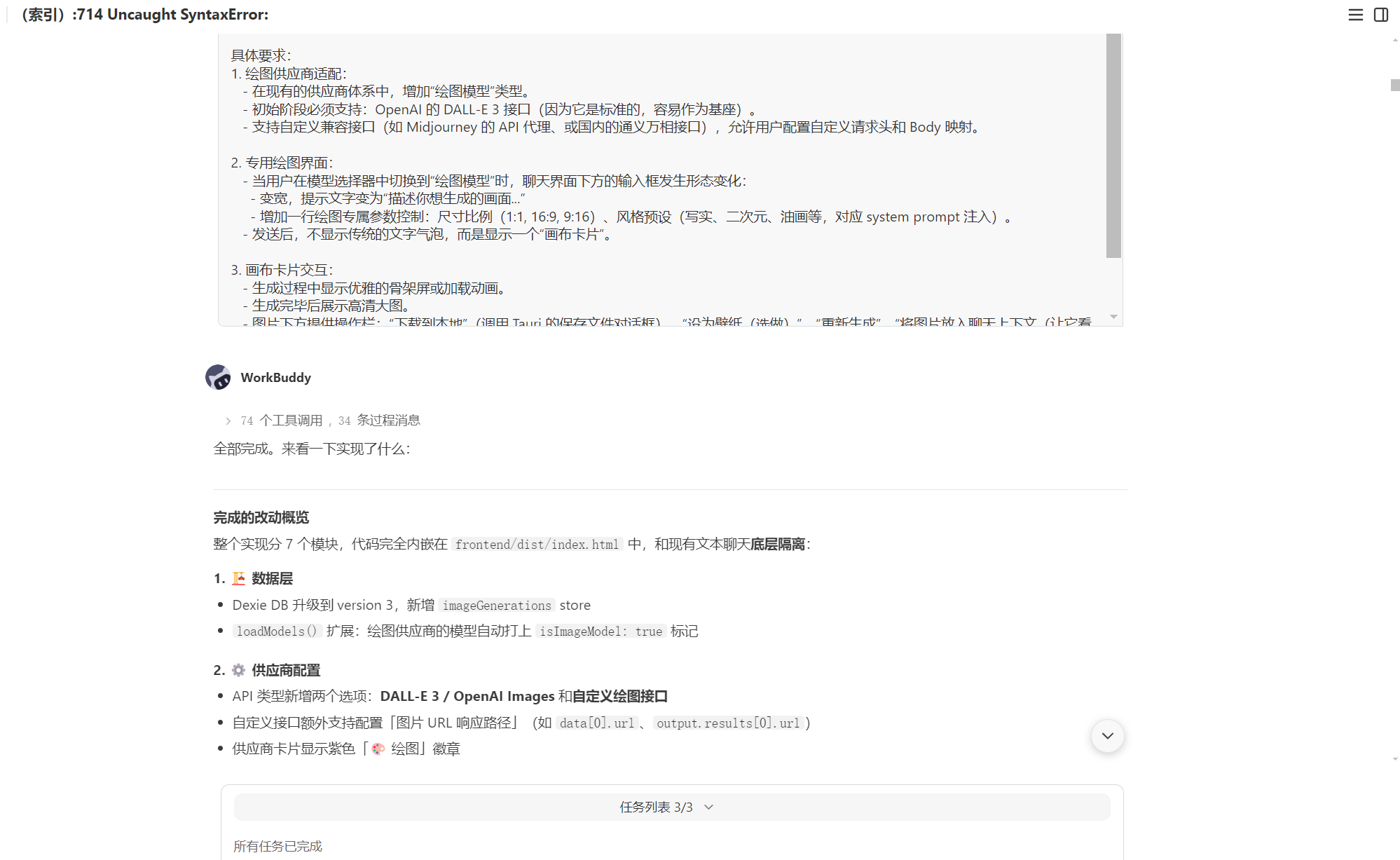
一个有趣的 bug 修复经历:
重构过程中前端出现了一个诡异的错误——所有函数都不可用,包括最基础的 toggleTheme。AI Agent 分析后发现问题根因是:一段代码在重构时被意外复制到了函数外部,导致 await is only valid in async functions 语法错误,整个 <script> 标签的解析直接失败。
问题代码 1 — 孤立的 async 代码块
migrateFromLocalStorage 函数里的一段代码被意外复制到了函数外面,导致裸 await 出现在非 async 上下文中:
// ── 这段代码被意外复制到了 migrateFromLocalStorage 函数外部 ──
// 导致整个 <script> 标签解析失败
const convs = await db.conversations.toArray();
for (const old of convs) {
if (!old.modelId && old.lastModelId) {
await db.conversations.update(old.id, { modelId: old.lastModelId });
}
}
// ── 上面的 await 不在任何 async 函数内 → SyntaxError ──这个错误会直接让整个 <script> 标签解析失败,所以页面上的所有函数都不可用——不只是 toggleTheme,openNewConvDialog、saveLastModel 等全部瘫痪。
问题代码 2 — renderChat 里混入的 HTML 片段
更离谱的是,renderChat 函数里还被混入了一段裸 HTML:
function renderChat(convId) {
// ...正常逻辑...
showRegenBtn();
// ── 下面这段是修复操作时意外混入的 HTML 残留 ──
<button onclick="regenerateMessage()">重新生成</button>
<template id="regen-template">...</template>
await renderModelSelect();
if (sel) { ... }
// ── JS 解析器遇到裸 '<' → Uncaught SyntaxError: Unexpected token '<' ──
}核心原理:
<script>
// JavaScript 解析器是"一招致命"的——
// 只要有一个 SyntaxError,整个 <script> 标签都不会执行
// 所以一个复制粘贴错误 = 全站瘫痪
// 错误 1: await 在非 async 函数里 → SyntaxError
// 错误 2: 裸 < 字符在 JS 里 → SyntaxError
// 两个错误发生在不同轮次的重构中,
// 但效果一样:所有函数全部失效
</script>这就是单文件 SPA(12000+ 行全在一个 HTML)的风险——一处小失误就能让整站瘫痪。AI Agent 的价值在于几秒钟就能定位这类问题,人工排查则需要半天。
中午(12:00-14:30):AI 绘图 + 插件系统 + 竞技场 + UI 精修
目标:扩展核心能力,打造完整的用户体验。
午饭后进入功能密集期,AI Agent 连续完成了多个大型模块:
🎨 AI 绘图集成
- 新增绘图供应商类型(DALL-E 3 + 自定义接口)
- 输入区智能切换:文本模型显示输入框,绘图模型显示尺寸选择 + 风格预设
- 画布卡片:骨架屏加载态 → 大图展示 → 灯箱预览 → 下载/重新生成
🔌 插件市场
这是一个完整的 Prompt 插件系统:
- 内置插件:论文润色专家、JSON 快速构建器等
- 支持触发词匹配、变量表单(用户填写后注入 system prompt)
- 斜杠命令输入:输入
/自动弹出插件列表 - 导入/导出
.plugin.json文件
⚔️ 竞技场
最初是单页面设计,AI Agent 建议并实现了两步式架构:
- Lobby:场次管理列表(创建/重命名/删除/导出)
- Battle:2-3 模型并排对比 + 投票评分
还内置了 6 个快捷模板(代码风格对比、多语言翻译、概念解释等),一键填入。
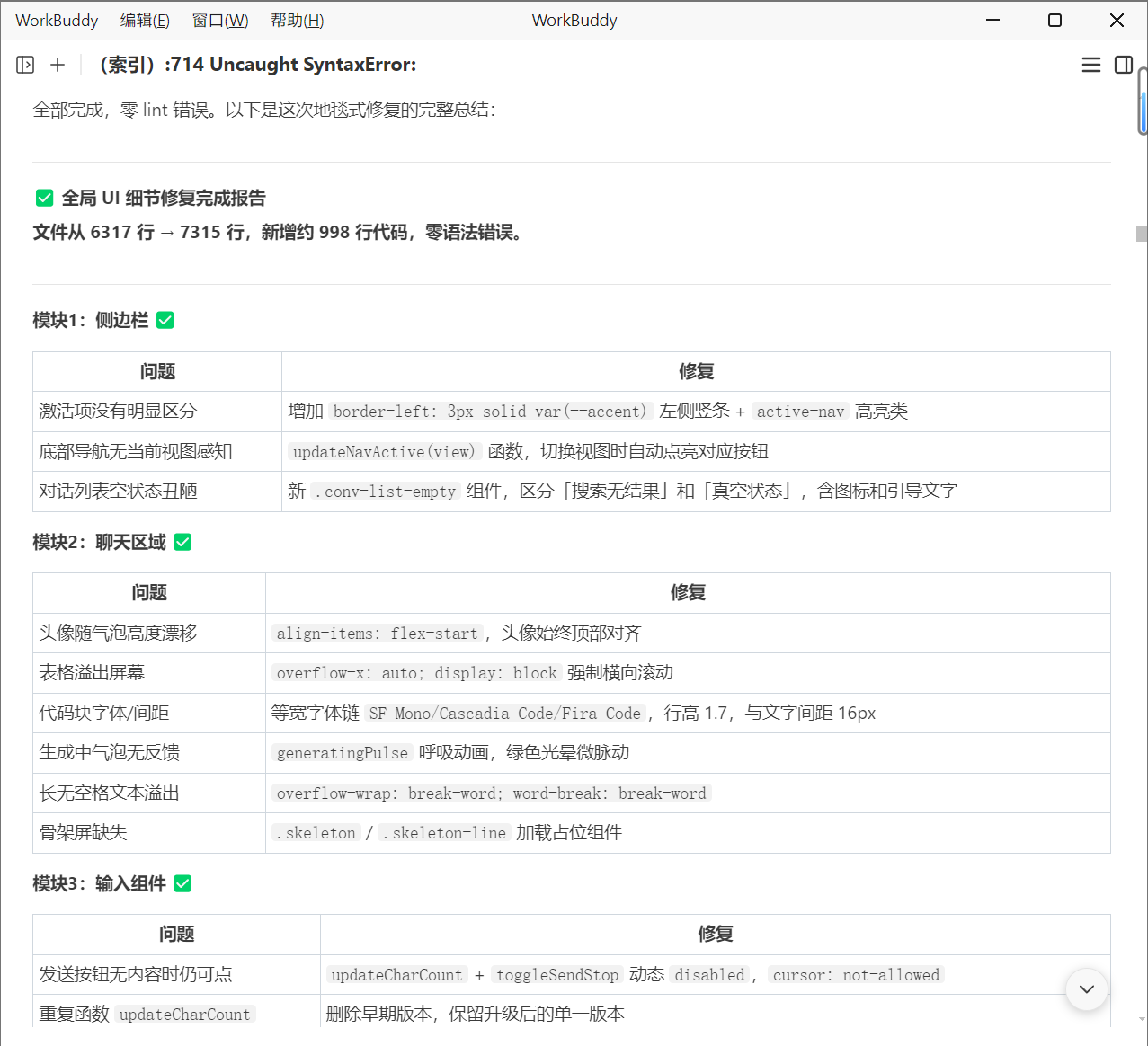
🛠️ UI 地毯式修复
AI Agent 做了一次全面的 UI 精修,涵盖 5 个模块:
- 侧边栏:active 高亮、text-overflow 防溢出、空状态组件
- 聊天区:消息操作栏、骨架屏加载动画、错误卡片替代原生 alert
- 输入区:发送按钮禁用态、字符计数
- 弹窗:关闭动画、统一 header/body/footer 规范
- 专门消灭了所有
window.alert调用,替换为自定义 toast
下午(14:30-18:00):MT-Bench 模型评测 + 每日金句
目标:打造专业的模型评测能力。
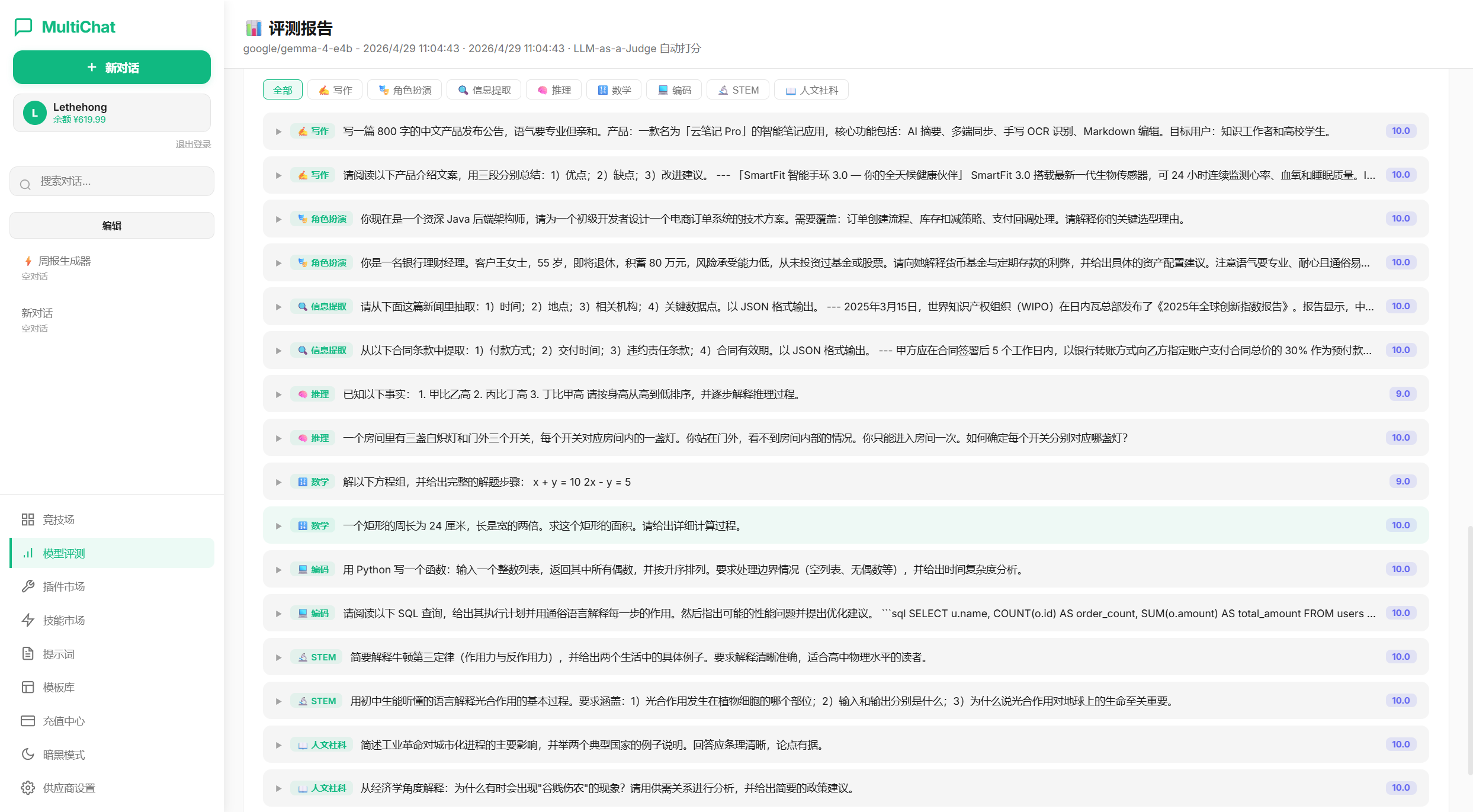
MT-Bench 模型评测模块是最复杂的部分,AI Agent 分三个阶段逐步构建:
阶段 0:数据模型
- 定义了 11 个测试维度(8 个能力维度 + 3 个工程指标)
- 内置 16 道高质量测试题目,涵盖写作、角色扮演、信息提取、推理、数学、编码、STEM、人文社科
- IndexedDB 存储层
阶段 1:页面布局
- 四个页面状态:配置页 → 执行页 → 报告页 → 历史记录
- 模型标签选择、维度多选、打分方式切换
阶段 2:执行引擎
- 多模型并发流式请求(Promise.all)
- 实时采集指标:首包时间、完成时间、吞吐量
- LLM-as-Judge 自动打分:每道题完成后自动调用裁判模型评分,支持降级解析
阶段 3:报告页
- Canvas 雷达图绘制(自适应深色/亮色主题,HiDPI 支持)
- 排名卡片(金银铜三色)
- 维度得分条形图
- 题目详情手风琴(展开查看各模型回答 + 裁判评语 + 手动星级评分)
- JSON/Markdown 双格式导出
除此之外还做了一个每日金句模块——从一言 Hitokoto API 获取名言,支持复制文本和复制为图片(html2canvas)。

晚上(18:00-21:00):本地模型 + 用户系统 + ClawTip 支付
目标:接入本地模型、完善用户体系、集成真实支付。
🖥️ 本地模型接入
新增 Ollama 和 LM Studio 适配器,支持一键拉取本地模型列表。这引出了一个有趣的前后端数据不同步问题——前端 provider 存在 IndexedDB,后端从 JSON 文件读取,导致新添加的本地模型找不到。AI Agent 设计了一个双向同步机制解决了这个问题。
前往LM Studio官网,如果是windows部署,那就直接点下载即可。
命令行则可以直接使用下面的命令即可
Mac / Linux
curl -fsSL https://lmstudio.ai/install.sh | bashpowershell窗户
irm https://lmstudio.ai/install.ps1 | iex
下载Gemma 4 E4B轻量模型
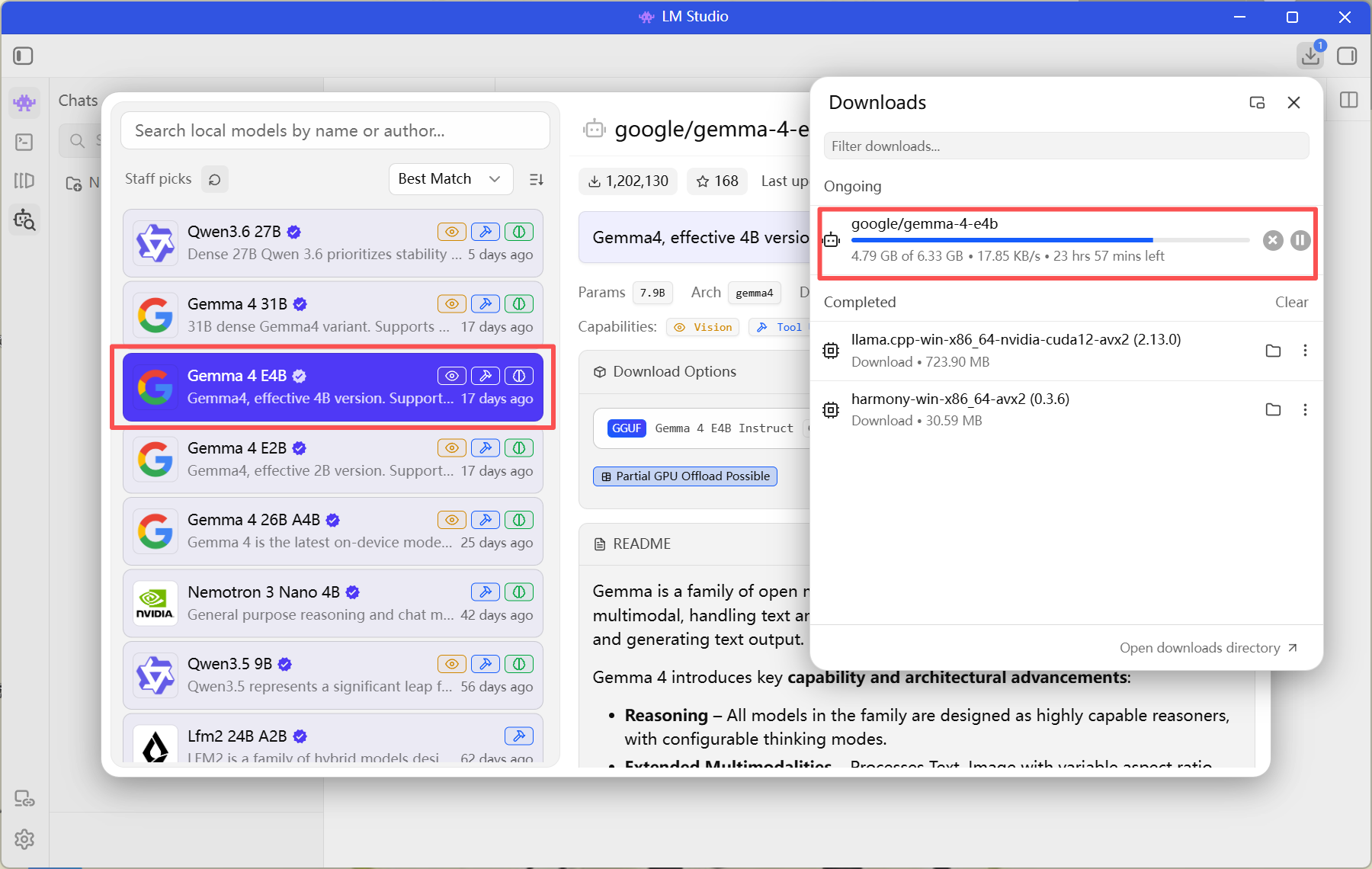
经过漫长的等待,Gemma也是部署完成了
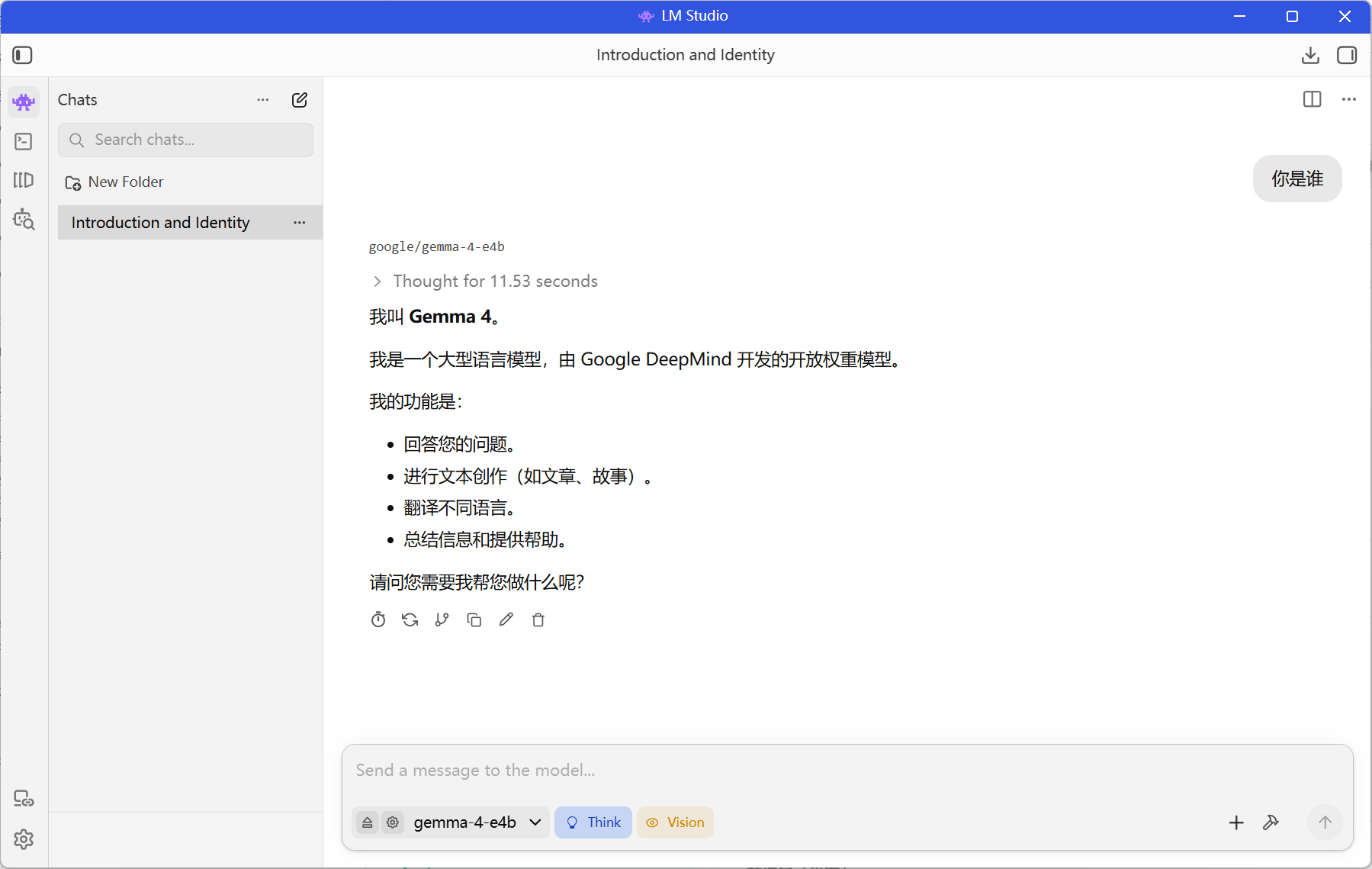
测试成功后,我们就要去开启模型服务了
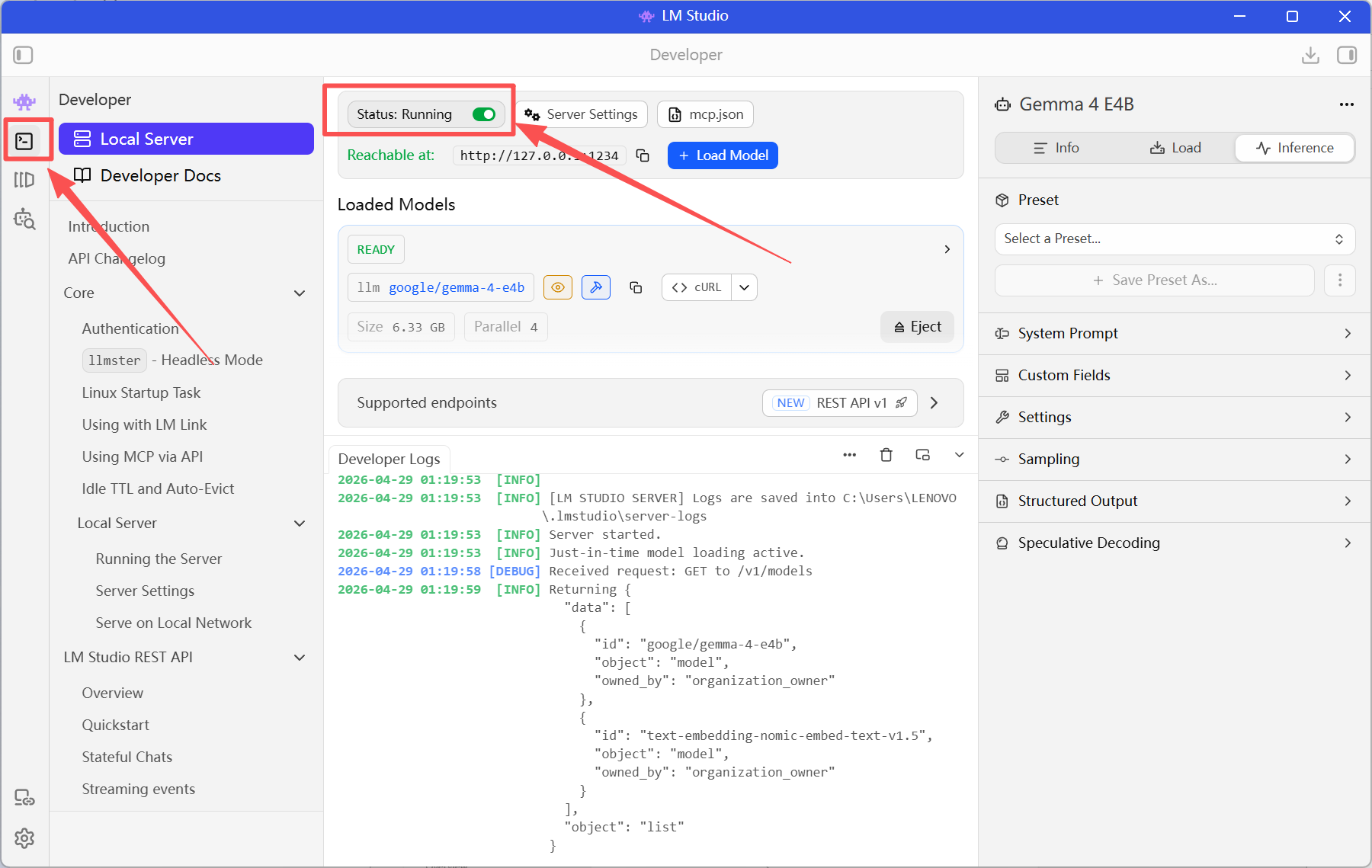
接下来就是前往我们使用workbuddy开发的项目中,接入本地大模型了。
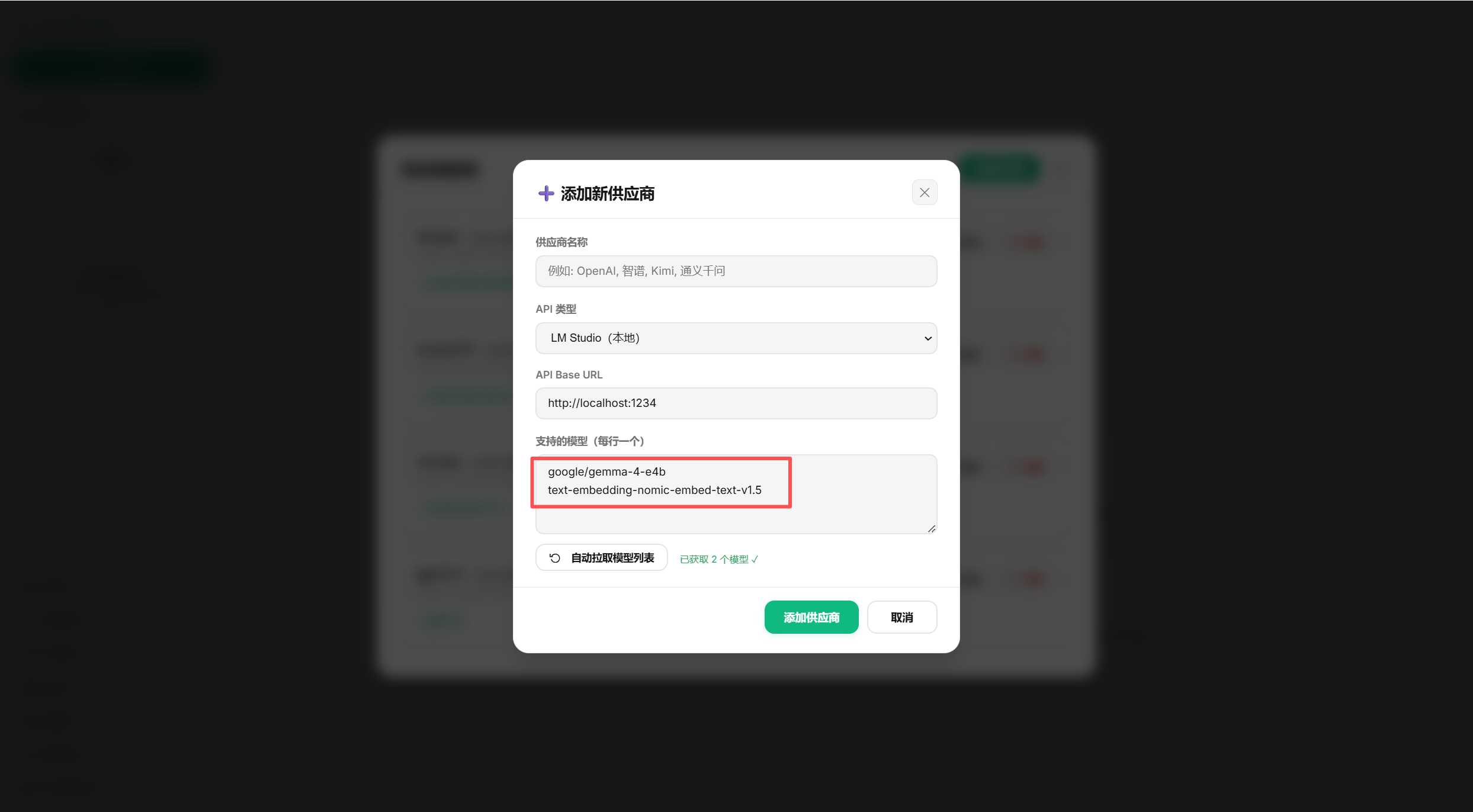
下图可以很清晰的看到,我输入API URL之后,点击了图片中的自动拉取模型列表按钮,就自动获取了我们本地的两个模型。
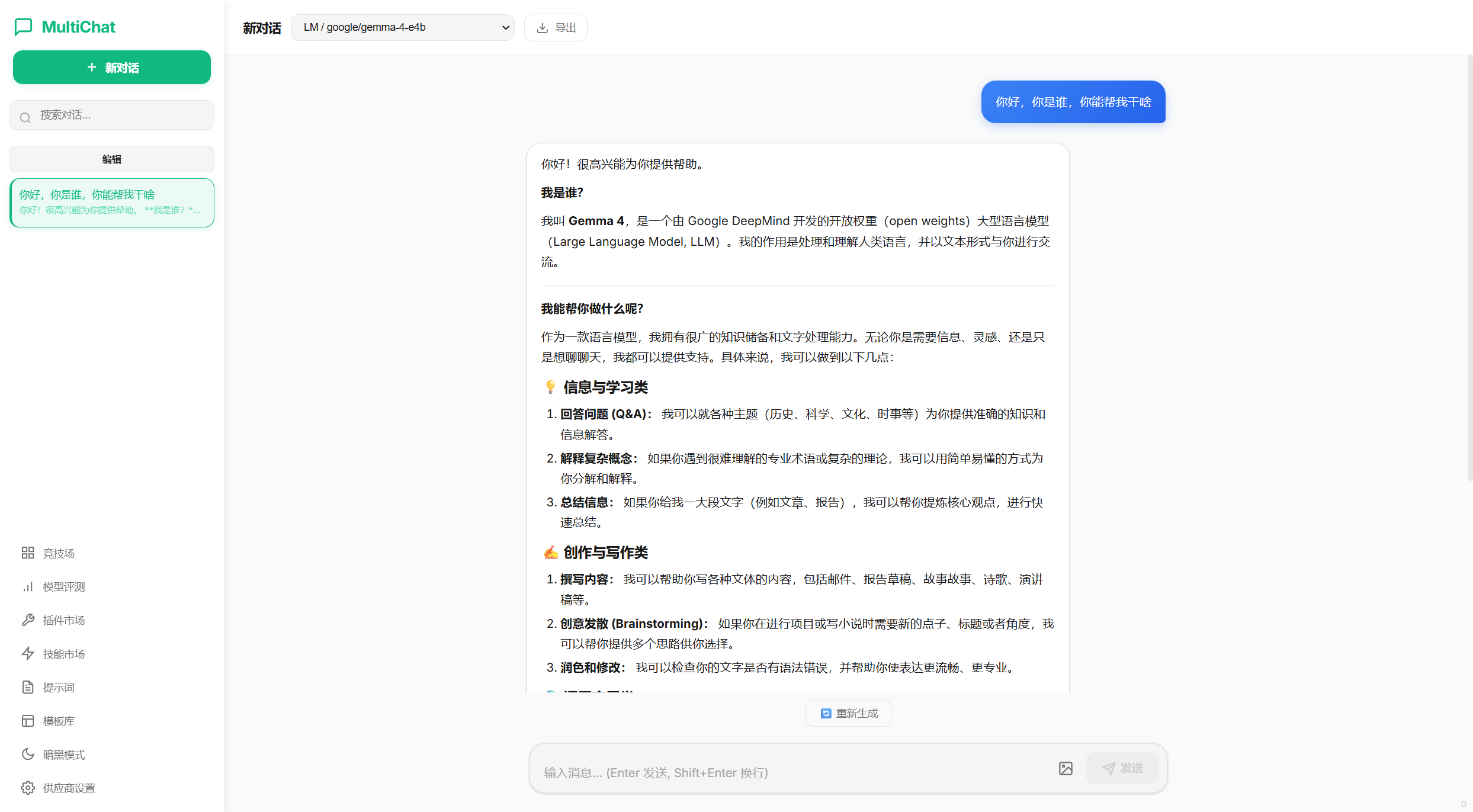
连接成功了,我们接下来尝试模型对话,完美
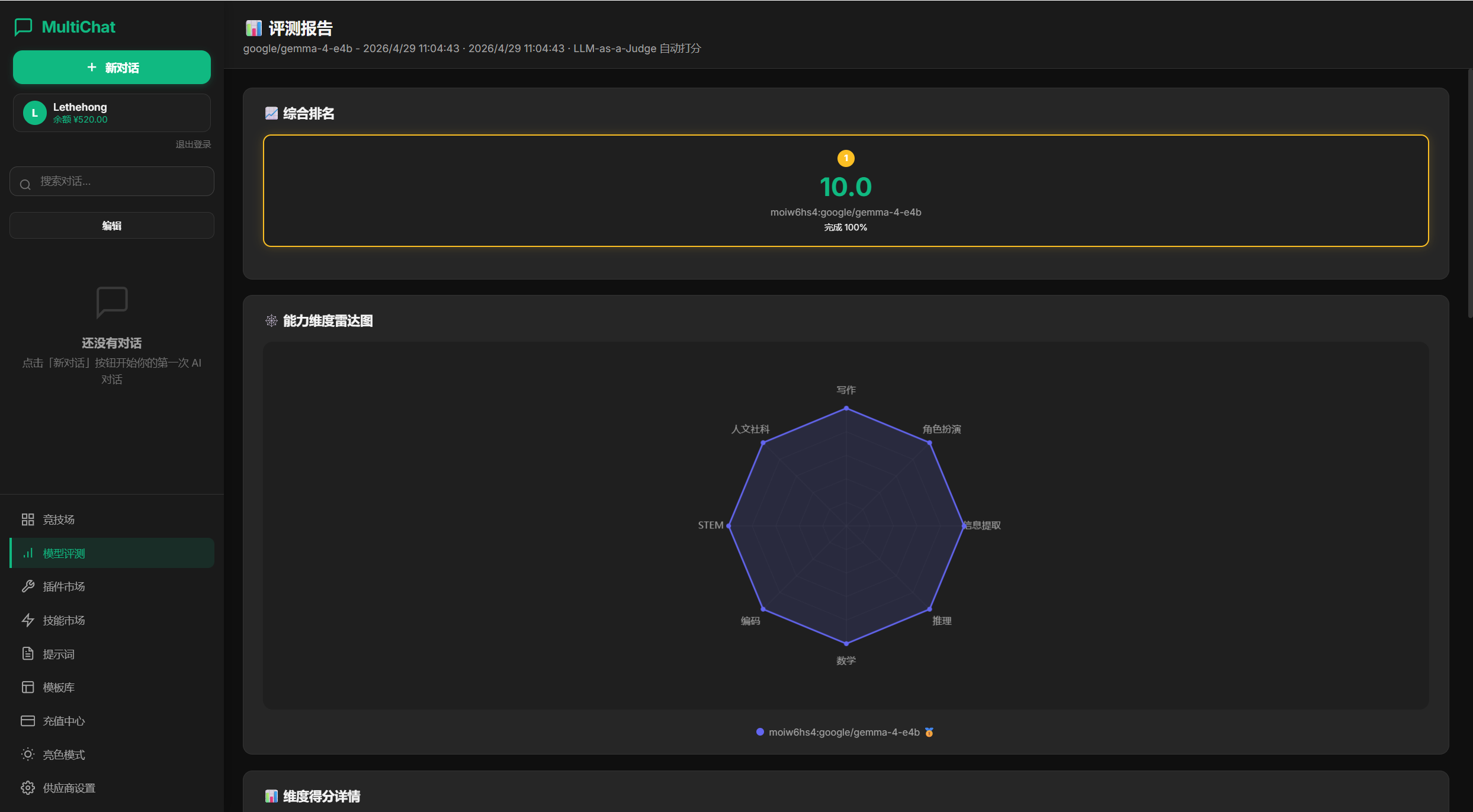
然后我对该模型进行了模型测试,给出的评测报告近乎完美(这是内部测试,并非官方权威报告)
👤 用户登录/注册系统
完整的认证系统:注册(bcrypt 密码哈希)→ 登录(JWT 签发)→ 余额管理 → 充值记录。
💳 ClawTip 支付集成
这是整个项目技术挑战最大的部分:
ClawTip 是京东的 AI 技能支付体系,使用 SM4-ECB 加密 + X402 协议。官方只提供了混淆的 CLI 工具,没有清晰的 API 文档。
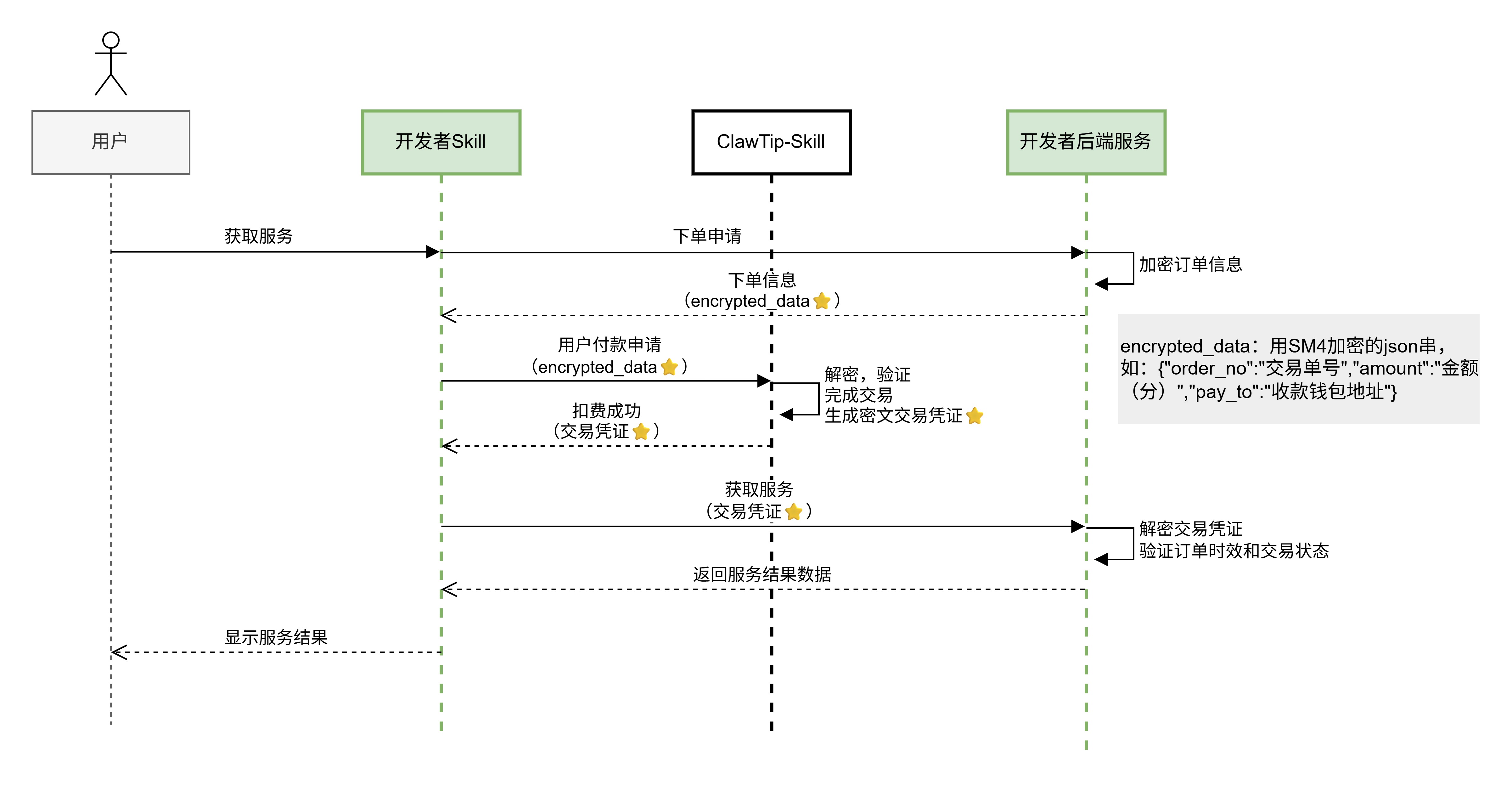
AI Agent 的工作方式令人印象深刻——它通过逆向工程理解了支付流程:
- 读取 CLI 混淆源码,定位
dealPayment函数 - Monkey-patch
https.request拦截 CLI 发出的实际 HTTP 请求 - 将拦截到的请求体和自己代码发出的请求做字段级 A/B 对比
- 发现了多个未文档化的关键参数:
-
skillId必须传"blank"(不是 slug)skillVersion必须传"1.0.1"- SM4 加密模式必须是 ECB(不是文档暗示的 CBC)
- 公钥在
response.resultData中(不是publicKey字段)
最终实现了完整的 HTTP 直调模块(clawtip-direct.js),完全绕过了 CLI 依赖。
AI Agent 开发的真实体验
它不只是"代码补全"
传统的 AI 编程工具是"你问一句,它答一句"。而 WorkBuddy 的工作模式更像是一个结对编程伙伴:
- 理解上下文:它通过
.workbuddy/memory/目录维护项目记忆,每次启动时自动读取,知道项目的技术栈、架构决策、未解决的问题 - 自主拆解任务:你说"加一个模型评测功能",它会自己规划数据模型 → 页面布局 → 执行引擎 → 报告渲染的完整步骤
- 跨会话连续性:上午做的适配器架构,晚上加本地模型时它直接复用
调试能力远超预期
逆向 ClawTip 支付协议的过程特别能体现 AI Agent 的调试能力:
问题现象:ClawTip 后端返回 "商家信息有误"(code: 000001)
AI Agent 的调试路径:
1. 写测试脚本,对比 CLI 和自己代码的请求差异
2. 发现 skillId 参数不对 → 修正后仍然报错
3. 继续 A/B 对比 → 发现 skillVersion 必须是 "1.0.1"
4. 修正后 → 报错变为 "收付款方账户不能相同"
5. 分析代码 → 发现这是账户配置问题,不是代码 bug
6. 进一步测试 → 后端要求升级 clawtip 版本
7. 用不同版本号逐一测试 → 确认 "1.0.1" 是唯一合法值
8. 最终结论:平台端限制,CLI 也被同样拦截,代码层面已完全正确整个过程,它自己写测试脚本、运行测试、分析结果、调整代码,人工只需要看结论。
代码质量可控
我一开始担心 AI 写的单文件 SPA(12000+ 行)会变成一团乱麻。但实际上:
- AI 严格遵守了 CSS 变量体系,所有颜色/间距通过变量控制
- 模块间通过状态变量和函数调用解耦
- 每个
// ── Section Name ──注释清晰分隔代码段 - 出现 bug 时能快速定位并修复
当然也有局限
- 复杂交互调试需要人工验证——AI 写的 UI 逻辑有时在浏览器中表现和预期不同
- 架构决策仍然需要人来把关——比如竞技场的两步式架构是 AI 建议的,但需要人来确认这是更好的设计
- 支付系统最终因为平台端的版本限制被阻塞,这不是代码问题,而是外部依赖
技术架构亮点
适配器模式(后端多模型支持)
┌─────────────┐ ┌──────────────────────────────┐
│ 前端请求 │───→│ Express /v1/chat/completions │
│ model: xxx │ │ ↓ 解析 modelId │
└─────────────┘ │ ↓ 查找 provider 配置 │
│ ↓ createAdapter(provider) │
│ ↓ adapter.buildRequestBody() │
│ ↓ adapter.transformSSEChunk() │
└──────────────────────────────┘
↓
┌──────────────────────────────────┐
│ BaseAdapter (接口) │
│ ├── OpenAIAdapter │
│ ├── ZhipuAdapter (JWT 签名) │
│ ├── QwenAdapter (DashScope) │
│ ├── WenxinAdapter (OAuth 2.0) │
│ ├── MoonshotAdapter │
│ ├── OllamaAdapter (本地) │
│ └── LMStudioAdapter (本地) │
└──────────────────────────────────┘每个适配器负责:认证方式、请求格式转换、SSE 流式解析、响应格式统一为 OpenAI 兼容格式。
ClawTip 支付协议链路
后端 initiatePayment():
│
├─ 1. getSMPublicKey() → 获取 SM2 公钥
│
├─ 2. encrypt(userToken, publicKey) → SM2 加密用户身份
│
├─ 3. 构建 X402 PaymentRequest
│ ├── Accepted: { payTo, amount, network, asset }
│ ├── Authorization: { from: 加密token, to: payTo }
│ ├── Payload + Resource + Extensions
│ └── systemId/systemToken: "jd-clawtip"
│
└─ 4. POST clawtipPay → 返回 authUrl(授权链接)或 payCredential(支付凭证)写在最后
这篇文章不是在鼓吹"AI 可以替代程序员"。恰恰相反,整个过程让我更清楚地认识到:
AI Agent 是一个超级放大器——它放大的是你作为开发者的判断力、架构能力和对产品的理解。你决定了"做什么"和"怎么做",AI 负责把想法变成代码。
那个关于 ClawTip 支付协议逆向的故事就是最好的例子:我知道要对接支付,AI 帮我搞定了"怎么做"——包括逆向混淆代码、A/B 对比调试、参数逐一排除。但决定使用 HTTP 直调而不是 CLI 调用、设计错误处理策略、判断"这是平台限制而不是代码 bug"——这些仍然需要人来完成。
如果你也想用 AI Agent 提升开发效率,我的建议是:
- 先想清楚你要做什么——AI 不擅长替你做产品决策
- 保持代码审查习惯——AI 写的代码质量不错,但不代表不需要 review
- 善用记忆系统——WorkBuddy 的 memory 机制让跨会话连续开发成为可能
- 拥抱迭代——先跑起来,再优化。AI 特别适合快速迭代
最终,一天的成果证明了一件事:一个人 + AI Agent = 一个小团队的生产力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)