分组回归怎么做:SPSSAU操作步骤与结果解读
一、分组回归所属模块
分组回归在SPSSAU中属于计量经济研究模块。
二、方法概述
分组回归主要用于比较同一组解释变量在不同分组样本中的作用是否一致,适合分析不同群体之间影响路径是否存在差异。实际研究中,当样本天然分为不同类别,且希望判断各组回归结果是否有明显区别时,这一方法会非常实用。
三、变量设置规则
分组回归需要设置3类变量,分别是1个因变量、1个分组变量,以及至少1个解释变量。前两类为必填项,解释变量也必须设置,且可一次放入多项。
1. 因变量设置
(1)因变量仅可放入1个,且为必填项。
(2)该变量需为定量数据,用来作为被解释对象,也就是回归模型中希望被预测或被说明的结果变量。
2. 分组项设置
(1)分组项仅可放入1个,且为必填项。
(2)该变量需为定类数据,用来区分不同样本群体,例如地区、性别、企业类型等。分组回归的核心就是在这些不同组别中分别建立回归模型,再进行比较。
3. 解释变量设置
(1)解释变量至少放入1个,最多可放入100个。
(2)解释变量既可以是定量变量,也可以是定类变量,用于解释因变量的变化。若放入多个解释变量,系统会在整体样本与各分组样本中同步输出对应回归结果,便于横向比较。
四、分析结果表格及其解读
分组回归分析后,SPSSAU会输出分组回归模型表,以及回归系数差异检验表,用来同时查看整体模型结果、各组模型结果以及组间系数差异是否显著。
1. 表1:分组回归模型
该表格的作用是同时展示整体样本与各分组样本的回归结果,包含常数项、各解释变量的回归系数、标准误、t值、p值、标准化回归系数,以及样本量、R²、调整R²、F值等核心信息。
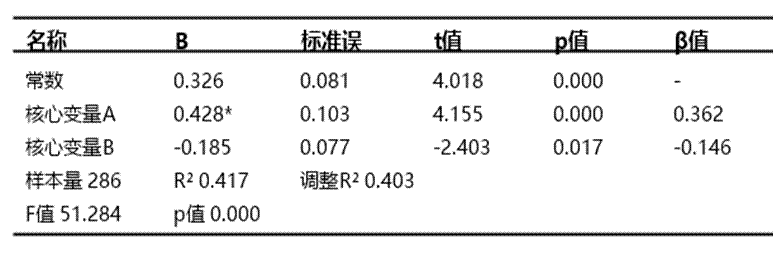
● B值:表示解释变量对因变量的实际影响方向和影响大小。数值为正,通常说明正向影响;数值为负,通常说明负向影响。绝对值越大,代表影响幅度越明显,但仍需结合显著性一起判断。
● 标准误:反映回归系数估计的稳定程度。标准误越小,说明估计越稳定;如果标准误较大,通常意味着该系数波动较明显,解读时要更谨慎。
● t值:用于判断某个回归系数是否偏离零足够明显。一般来说,绝对值越大,说明该变量越可能对因变量产生真实影响,但最终仍以p值判断是否显著。
● p值:用于判断解释变量的影响是否具有统计意义。通常p值小于0.05,说明该变量影响显著;若小于0.01,说明显著性更强;若大于等于0.05,则通常认为影响不显著。
● β值:即标准化回归系数,用于比较不同解释变量影响力大小。绝对值越大,说明该变量在模型中的相对影响越强,更适合做变量间的重要性比较。
● 样本量:表示整体样本和各组样本分别纳入多少观测值。样本量过小,结果稳定性往往较弱,因此在解释各分组结果时需要先确认各组样本是否足够。
● R²:表示模型对因变量变动的解释程度。数值越接近1,说明模型解释力越强;若数值较低,说明模型对结果的解释有限。不同研究场景对高低没有统一标准,应结合领域特点判断。
● 调整R²:是在考虑解释变量数量后,对R²做出的修正,更适合比较不同复杂程度的模型。通常数值越高越好;如果加入新变量后该指标没有提升,说明新变量未必带来有效解释。
● F值及其对应p值:用于判断整个回归模型是否整体成立。若对应p值小于0.05,说明模型整体显著,当前解释变量组合对因变量具有解释意义;若不显著,则说明整体模型解释效果不足。
2. 表2:回归系数差异检验
该表格的作用是进一步比较不同分组之间同一解释变量的回归系数是否存在显著差异,包含比较的组别、两组回归系数、系数差值、t值和p值等指标。

● 项1、项2:表示参与比较的两个组别。通过逐组配对比较,可以直观看到哪些群体之间存在差异。
● 回归系数b1与回归系数b2:分别表示两个组别中同一解释变量对应的非标准化回归系数。它们能帮助判断同一变量在不同群体中的影响方向和影响大小是否一致。
● 差值:表示两个组别回归系数之间的直接差异。数值越远离0,通常意味着组间差别越明显,但仍需结合显著性判断。
● t值:用于检验组间回归系数差异是否足够明显。绝对值越大,通常越容易达到显著水平。
● p值:是判断组间差异是否显著的核心指标。通常p值小于0.05,说明两个组别在该解释变量上的回归系数存在显著差异;若大于等于0.05,则说明差异不明显。
五、结尾
以上就是SPSSAU分组回归方法的相关内容,更深入教程可查看SPSSAU帮助手册、教学视频、疑难解惑等资料。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)