门槛回归怎么做:SPSSAU软件操作步骤与结果解读
一、门槛回归所属模块
门槛回归在SPSSAU中属于【计量经济研究】模块。
二、方法概述
门槛回归主要用于判断某个解释关系是否会随着门槛变量的不同区间而发生变化。它适合研究“同一个变量在不同水平下作用强弱不同”的场景,常见于经济、管理、区域研究和面板数据分析中。
三、变量设置规则
1. 总体要求
门槛回归共需要设置6类变量,分别是因变量(Y)、自变量(X)【可选】、门槛变量、核心解释变量、个体id【可选】、时间【可选】。其中因变量、门槛变量、核心解释变量为必填;自变量、个体id、时间为可选。
2. 具体设置
(1)因变量(Y)
● 只能放入1个变量,且为必填。
● 用于放入被解释结果,是门槛回归中需要重点分析的结果变量。
(2)自变量(X)【可选】
● 最多可放入20个变量,可以不放。
● 用于加入控制变量,帮助在控制其他影响因素后,更清楚地识别核心解释变量的门槛效应。
(3)门槛变量
● 只能放入1个变量,且为必填。
● 用于划分不同区间,是判断关系是否发生分段变化的关键变量。
(4)核心解释变量
● 只能放入1个变量,且为必填。
● 用于考察其在不同门槛区间内对因变量的影响是否存在差异。
(5)个体id【可选】
● 最多可放入1个变量,可以不放。
● 当研究对象属于面板数据时,可用于识别不同个体。
(6)时间【可选】
● 最多可放入1个变量,可以不放。
● 当研究对象具有时间维度时,可与个体id一起用于面板数据分析。
四、参数设置及解释说明
1. 模型
● 可选为单一门槛、双重门槛、三重门槛,默认是单一门槛。
● 含义是设置需要检验几个门槛区间。
● 如果研究刚开始,通常建议先从单一门槛入手,结果更稳定,也更容易解释;只有在理论和数据都支持的情况下,再进一步尝试双重或三重门槛。
2. 网格搜索
● 可选为自动、100次、200次、300次,默认是自动。
● 含义是通过遍历方式寻找最佳门槛值。
● 如果希望在效率和精度之间平衡,自动设置通常就够用;如果更重视搜索的细致程度,可以提高搜索次数,但计算时间也会相应增加。
3. Bootstrap次数
● 可选为自动、100次、200次、300次,默认是自动。
● 含义是通过重复抽样检验结果是否稳定。
● 当研究更强调结果稳健性时,可以适当增加抽样次数;如果只是先做初步筛查,自动设置通常更省时。
五、分析结果表格及其解读
SPSSAU完成门槛回归后,通常会输出门槛模型基本信息、门槛估计值、门槛模型检验、门槛模型比较、门槛模型结果、简化格式结果表以及样本缺失情况汇总;如果面板数据格式不满足要求,还会先输出数据格式排查表。
1. 表1:数据格式排查

该表格在面板数据格式存在疑点时输出,用于检查个体id、样本个数、不同时间或日期项个数以及整体检查结果。
● 个体ID:表示每个研究对象的识别编号,作用是区分不同个体。
● 样本个数:表示该个体对应的数据条数,作用是帮助判断是否存在重复记录。
● 不同时间或日期项个数:表示该个体覆盖的时间点数量,作用是判断时间维度是否充分。
● 检查:用于直接给出格式是否正常的判断。如果提示正常,说明数据结构基本可用于后续面板门槛分析;如果提示有重复项或时间项过少,则应先整理数据再继续分析。
2. 表2:门槛模型基本信息

该表格用于概览本次分析采用的模型设定,包含门槛模型、网格搜索次数、Bootstrap抽样次数、数据类型和分析样本量等信息。
● 门槛模型:表示当前采用的是单一、双重还是三重门槛模型,作用是明确后续结果对应的分析结构。
● 网格搜索次数:表示寻找最佳门槛值时的搜索次数,次数越充分,通常越有助于更细致地定位门槛位置。
● Bootstrap抽样次数:表示重复抽样检验所使用的次数,次数越多,稳定性判断通常越充分。
● 数据类型:表示本次分析属于面板数据还是截面数据,作用是帮助理解结果适用的研究场景。
● 分析样本量:表示实际进入模型分析的有效样本数量,样本越充分,结论通常越稳定。
3. 表3:门槛估计值

该表格用于展示门槛值及其区间范围,包含模型、门槛值Threshold、Bootstrap 95%下限、Bootstrap 95%上限等指标。
● 门槛值Threshold:是区分不同作用区间的核心界点。它的作用是告诉研究者关系从哪里开始发生分段变化。
● Bootstrap 95%下限、Bootstrap 95%上限:用于显示门槛值的区间范围。区间越集中,通常说明门槛值定位越稳定;如果区间较宽,说明门槛位置仍需谨慎解读。
4. 表4:门槛模型检验
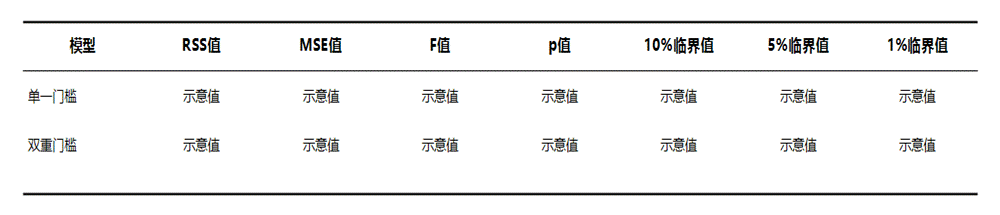
该表格用于判断是否存在门槛效应,以及是否需要从单一门槛继续扩展到更复杂的门槛结构,包含RSS值、MSE值、F值、p值以及不同水平的临界值等指标。
● RSS值:用于反映模型残差整体大小。一般越小,说明模型拟合偏差越小。
● MSE值:用于反映平均误差水平。一般越小,说明模型拟合更好。
● F值:用于检验门槛效应是否存在,通常数值越大,说明门槛效应证据越强。
● p值:是判断门槛效应是否显著的关键指标。通常当p值小于0.05时,说明对应门槛效应较明显。
● 10%临界值、5%临界值、1%临界值:用于和检验结果对照判断显著性水平。若检验统计量达到更严格水平,说明结果通常更有说服力。
5. 表5:门槛模型比较

该表格用于比较不同门槛模型的拟合表现,包含RSS值、MSE值、R方、AIC值、BIC值等指标。
● RSS值、MSE值:主要用于比较误差大小,一般越小越好。
● R方:用于衡量模型对结果变量的解释程度,数值越高通常说明解释效果越好。
● AIC值、BIC值:用于综合比较模型优劣,通常数值越小,代表模型整体表现更优。
实际判断时,不能只看单一指标,通常需要结合显著性检验和模型比较结果一起确定最终采用哪一种门槛结构。
6. 表6:门槛模型结果

该表格是核心结果表,用于展示不同门槛区间下核心解释变量及其他变量的影响结果,包含Coef、Std. Err、t、p、95% CI等指标。
● Coef:表示变量影响方向和影响强弱。它的作用是判断变量在不同区间内是正向影响还是负向影响。
● Std. Err:用于反映估计结果的稳定性,一般越小说明估计越稳定。
● t值:用于辅助判断系数是否具有统计意义,通常绝对值越大,说明变量更可能具有解释价值。
● p值:是判断变量是否显著的关键指标。一般当p值小于0.05时,说明该变量在对应区间内影响较明显。
● 95% CI:用于显示系数估计区间。若区间较集中,通常说明估计更稳定;若区间跨越较大,则需谨慎解释。
● R方:用于衡量模型整体解释效果,数值越高通常说明拟合效果越好。
● 调整R方或R方(within):用于补充评价模型表现。截面数据通常关注调整R方,面板数据通常还会关注组内解释效果。
7. 表7:门槛模型结果-简化格式

该表格用于用更紧凑的形式展示核心结论,包含各变量估计值、R方、调整R方或R方(within)、样本量和整体检验结果等内容,适合快速汇报结论。
● 估计值:用于快速查看变量影响方向和显著性标记。
● 样本量:用于判断本次分析的样本基础是否充分。
● 整体检验结果:用于判断整体模型是否显著,通常重点关注对应p值是否小于0.05。
8. 表8:样本缺失情况汇总

该表格用于展示有效样本、排除无效样本和总样本的数量及占比。
● 有效样本:表示真正进入模型分析的数据量,占比越高,通常说明数据可用性越好。
● 排除无效样本:表示因缺失等原因未进入分析的数据量。若占比较高,需要关注数据完整性问题。
● 总计:表示原始总样本量,用于和有效样本进行对照。
六、分析结果图表及其解读
SPSSAU完成门槛回归后,还会输出门槛折线图,用于辅助判断门槛值位置及不同候选门槛下的统计量变化趋势。
门槛折线图
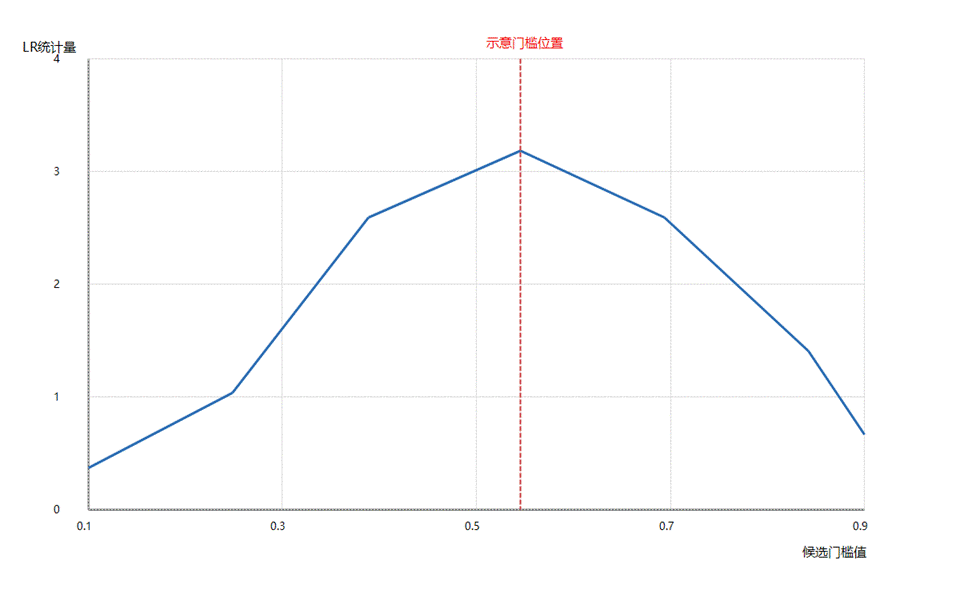
该图表本质上是折线图,用于展示候选门槛值变化时,对应统计量如何波动。
● 如果曲线在某一位置附近出现明显拐点或对应统计量达到更有代表性的变化位置,通常说明该位置更值得关注。
● 如果不同候选门槛附近的曲线变化很平缓,说明门槛位置区分度可能不强,结果解释时要更谨慎。
● 实际判断时,图表更适合作为辅助工具,应结合门槛估计值表和门槛模型检验表一起看,不能只凭图形单独下结论。
以上就是SPSSAU门槛回归的相关内容,更深入教程可查看SPSSAU帮助手册、教学视频、疑难解惑等资料。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)