面板模型怎么做:SPSSAU软件操作步骤与结果解读
一、面板模型所属模块
面板模型在SPSSAU中属于【计量经济研究】模块。
二、方法概述
面板模型主要用于同时分析个体差异和时间变化对结果变量的影响,常见于企业、地区、行业等连续多年数据研究。它适合处理同一对象被重复观测的数据,比普通回归更适合识别动态变化中的稳定关系。
三、变量设置规则
面板模型需要设置4类变量,分别为1个因变量Y、1个或多个自变量X、1个个体ID和1个时间变量。除自变量X可放入多项外,其余变量都只能各放1项,且这4类变量都需要填写。
(1)因变量Y
因变量只能放入1项,属于必填项,用来表示最终要解释或预测的结果。
(2)自变量X
自变量最多可放入100项,至少放入1项,属于必填项,用来解释因变量变化的影响因素。
(3)个体ID
个体ID只能放入1项,属于必填项,用来区分不同研究对象,比如企业编号、地区编号、用户编号等。
(4)时间
时间变量只能放入1项,属于必填项,用来标识每个对象在不同时间点上的观测记录。
四、参数设置及解释说明
1. 固定效应相关设置
(1)时间固定
勾选后,系统会建立时间固定效应模型,更适合控制不同时间点共同发生的外部影响。如果研究中存在年份政策变化、宏观环境波动等时间冲击,通常可以考虑开启。
(2)双向固定
勾选后,系统会建立个体和时间双向固定效应模型,适合同时控制对象差异和时间差异都较明显的场景。如果既担心不同个体先天差异,又担心不同年份环境变化,这一选项更有参考价值。
2. 单位根检验设置
(1)LLC检验和IPS检验
该选项用于进行面板单位根检验。勾选后,系统只输出单位根检验结果,不再继续输出面板模型结果。
(2)检验范围
单位根检验可选择仅对被解释变量进行,也可选择针对全部变量进行。若只是先快速判断因变量是否平稳,可用默认设置;若希望更完整地检查建模变量情况,可选择全部变量。
3. 稳健标准误设置
Robust法:勾选后,模型会使用稳健标准误,作用是尽量减轻异方差对结果稳定性的影响。若数据波动较大、不同对象误差差异明显,通常更建议开启。
五、分析结果表格及其解读
根据参数设置和数据情况,SPSSAU在面板模型分析后可能输出单位根检验表、模型选择表、模型结果汇总表、中间过程表、Hausman检验表、样本缺失汇总表以及数据格式排查表。
1. 表1:面板单位根LLC(levinlin)检验
该表用于判断变量是否存在单位根,包含项目名称、统计量(Zbar)和p值等指标。
● 统计量(Zbar):用于反映变量平稳性检验结果,通常需要结合p值一起判断,不能单独解读。
● p值:用于判断是否拒绝“数据具有单位根”的原假设。一般p值小于0.05,说明更倾向于认为数据平稳;若不小于0.05,则说明变量可能仍存在单位根,需要进一步处理。
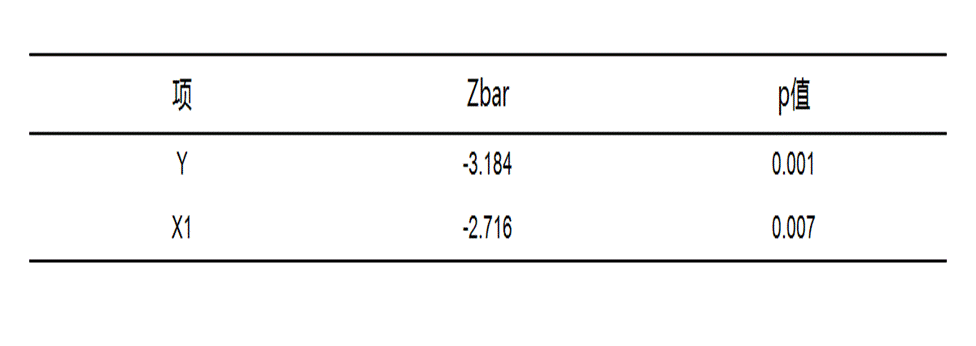
2. 表2:面板单位根IPS检验
该表同样用于检验变量平稳性,和LLC检验一起使用时,可以让平稳性判断更稳妥。表中同样包含项目名称、统计量(Zbar)和p值。
● 统计量(Zbar):反映IPS检验下的统计结果,主要配合p值判断变量是否通过平稳性检验。
● p值:一般小于0.05时,可认为变量通过平稳性检验;若结果不显著,说明数据稳定性仍需关注。

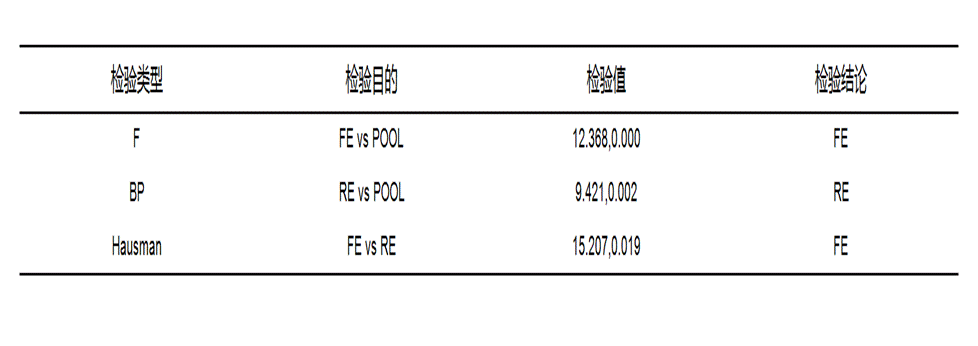
3. 表3:检验结果汇总
该表用于帮助选择更合适的面板模型,包含F检验、BP检验和Hausman检验三类结果。
● F检验:用于比较FE模型与POOL模型。一般p值小于0.05,更倾向选择FE模型;若不显著,则POOL模型也可能适用。
● BP检验:用于比较RE模型与POOL模型。一般p值小于0.05,更倾向选择RE模型;若不显著,则说明POOL模型可能已经足够。
● Hausman检验:用于比较FE模型与RE模型。一般p值小于0.05,更倾向选择FE模型;若不显著,则通常更支持RE模型。
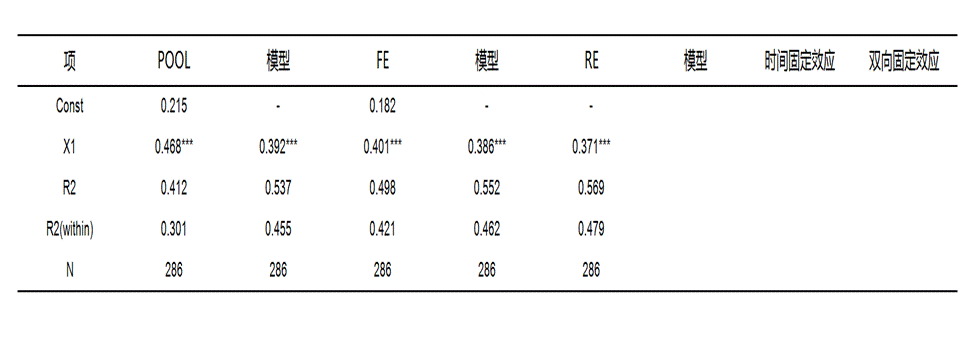
4. 表4:面板模型结果汇总
该表用于集中展示不同模型下各变量的回归结果,包含各项回归系数、显著性标记、t值、R²、R²(within)、样本量和整体检验结果。
● 回归系数:表示自变量对因变量的影响方向和影响强弱。系数为正,说明同向变化;系数为负,说明反向变化。
● 显著性标记:用于辅助判断变量影响是否稳定。一般标记越明显,说明结果越稳定,研究中越值得重点解读。
● t值:用于检验单个变量是否具有统计意义,通常需要结合显著性或p值一起看。
● R²:表示模型对结果变量整体解释程度,数值越大,说明解释能力越强。
● R²(within):更适合观察模型对个体内部随时间变化部分的解释能力,数值越高,说明对面板数据动态变化的解释越充分。
● 样本量:表示进入分析的有效样本规模,样本量越充分,通常结果越稳。
● 整体检验结果:用于判断模型整体是否成立。一般p值小于0.05,说明模型整体具有统计意义。
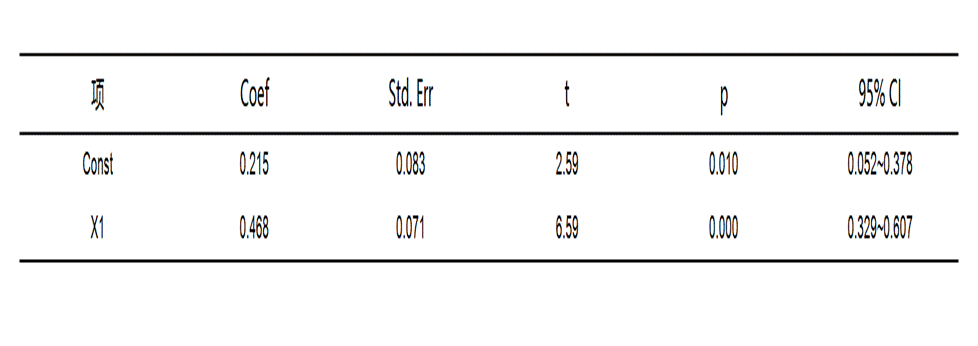
5. 表5:POOL模型中间过程值
该表用于查看POOL模型的详细估计结果,包含Coef、Std. Err、t、p以及区间信息。
● Coef:即回归系数,用于判断影响方向和大小。
● Std. Err:即标准误,用于反映估计结果的稳定程度,一般越小越说明估计更稳定。
● t:用于检验该变量是否显著,通常绝对值越大,说明越可能显著。
● p:一般小于0.05时,说明该变量影响较稳定,具有统计意义。
● 区间信息:用于辅助判断系数估计是否稳定,区间越集中,通常说明估计越稳。
6. 表6:FE模型中间过程值
该表用于查看个体固定效应模型的详细结果,核心指标与POOL模型中间过程值一致,但更适合解释控制个体差异后的影响关系。
● Coef:反映在控制个体固定差异后,自变量对因变量的影响方向和幅度。
● Std. Err、t、p:共同用于判断估计是否稳定、变量是否显著。一般p值小于0.05时,可认为变量影响成立。
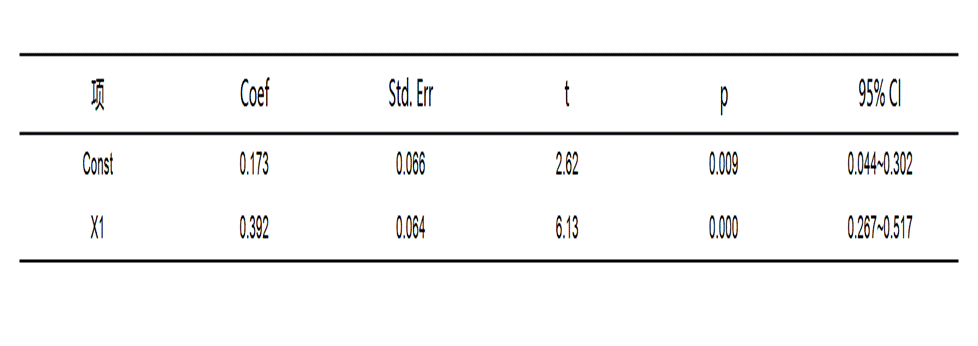
7. 表7:RE模型中间过程值
该表用于查看随机效应模型的详细结果,适合在Hausman检验支持RE模型时重点解读。
● Coef:用于判断自变量影响方向和大小。
● Std. Err、t、p:用于判断变量影响是否稳定,其中p值一般小于0.05可认为结果显著。

8. 表8:时间固定模型中间过程值
该表在勾选时间固定后出现,用于查看控制时间共同冲击后的详细估计结果。
● Coef:表示控制时间差异后变量的净影响。
● Std. Err、t、p:用于判断在时间固定条件下,变量是否依然稳定显著。

9. 表9:双向固定模型中间过程值
该表在勾选双向固定后出现,用于查看同时控制个体差异和时间差异后的结果。
● Coef:代表在双重控制条件下的变量影响,更适合要求较严格的面板研究场景。
● Std. Err、t、p:用于判断变量在更严格控制条件下是否仍显著,若仍显著,通常说明结果更稳健。

10. 表10:Hausman检验中间过程值
该表用于展示FE模型与RE模型差异的详细比较过程,包含两类模型回归系数、差值、标准误和Hausman统计量。
● FE系数b与RE系数B:用于观察两类模型估计结果是否接近。
● 差值b-B:差值越明显,通常说明两类模型结果差异越大。
● Hausman统计量与p值:用于最终决定应优先选择FE还是RE。一般p值小于0.05时,优先选择FE模型;否则可优先考虑RE模型。

11. 表11:样本缺失情况汇总
该表用于查看最终进入模型的有效样本情况,包含有效样本、排除无效样本和总样本。
● 有效样本:表示真正进入建模的数据量,占比越高,说明数据可用性越好。
● 排除无效样本:表示因缺失或不符合要求而被剔除的数据量,占比过高时需要特别关注数据质量。

12. 表12:数据格式排查
该表在数据结构不符合面板要求时出现,用于检查个体ID、样本个数、不同时间项个数及异常情况。
● 样本个数:用于判断某个个体是否存在重复记录。若明显多于实际时间项数量,通常要检查重复值。
● 不同时间项个数:用于判断该个体是否具备足够时间维度。若时间项过少,往往不适合直接进行面板分析。
● 检查结果:系统会直接提示是否正常、是否有重复项、是否时间项过少,便于快速定位数据整理问题。

以上就是SPSSAU面板模型的相关内容,更深入教程可查看SPSSAU帮助手册、教学视频、疑难解惑等资料。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)