(论文速读)interPDN:直接逐步概率分布模型的时间序列预测
论文题目:Time Series Forecasting via Direct Per-Step Probability Distribution Modeling(直接逐步概率分布模型的时间序列预测)
会议:AAAI2026
摘要:基于深度神经网络的时间序列预测模型最近在捕获复杂的时间依赖性方面表现出了卓越的能力。然而,对于这些模型来说,解释与它们的预测相关的不确定性是具有挑战性的,因为它们在每个时间步直接输出标量值。为了解决这一挑战,我们提出了一种新的模型,称为交错双分支概率分布网络(interPDN),它直接构建每步离散概率分布,而不是标量。每个时间步的回归输出是通过计算预测分布在预定义支持集上的期望得到的。为了减轻预测异常,引入了一种双分支结构,该结构具有交错的支持集,并通过粗时间尺度分支进行长期趋势预测。另一个分支的输出被视为辅助信号,对当前分支的预测施加自监督一致性约束。在多个真实数据集上的大量实验证明了interPDN的优越性能。
代码- https://github.com/leonardokong486/interPDN
告别标量预测:用概率分布直接建模时间序列的每一步
引言:时间序列预测的"置信度盲区"
想象你是一名电网调度员,模型告诉你明天下午3点的用电量是 8500 万千瓦时。但它没有告诉你:这个数字有多可信?误差是±50万还是±500万?
这正是当前绝大多数深度学习时间序列预测(TSF)模型的通病——它们在每个时间步直接输出一个标量值,对预测的不确定性几乎一无所知。
AAAI 2026 这篇论文提出了一个全新的解决思路:不直接预测数值,而是预测每个时间步上的完整概率分布,再从分布中计算期望作为最终预测值。这个模型被命名为 interPDN(interleaved dual-branch Probability Distribution Network)。
一、现有方法的三大痛点
痛点 1:标量输出,不确定性全无
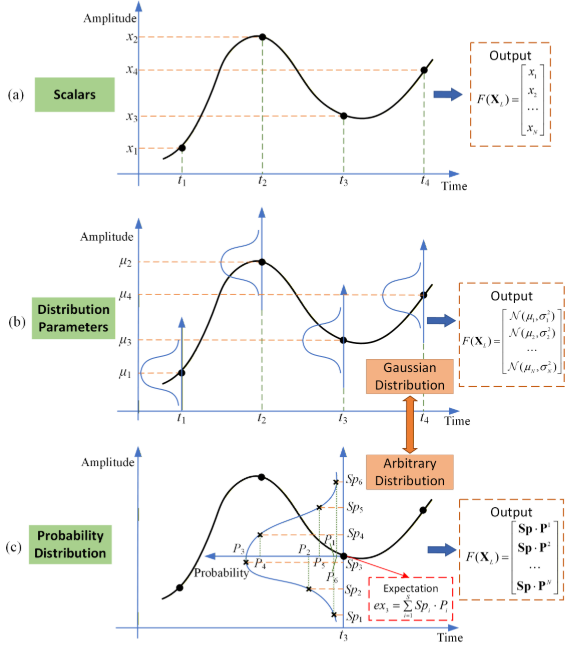
【此处配图:论文 Figure 1,展示三种建模方式的对比图】:不同的逐步时间序列建模方法:(a)标量估计;(b)概率分布参数预测;(c)通过离散概率分布预测期望
如 Figure 1(a) 所示,主流 TSF 模型(PatchTST、iTransformer、DLinear 等)的输出层是一个简单的线性投影头,每步只给出一个点估计值。用户无从知晓这个预测值是"把握十足"还是"随机猜测"。
虽然 AdaPTS 和 LangTime 尝试输出高斯分布参数(均值+方差),提供了图 Figure 1(b) 中的置信区间,但它们强制假设预测误差服从高斯分布,在实际的非高斯、重尾时序数据上存在明显的先验偏差。
痛点 2:单支路离散分布建模存在量化误差
将连续值离散化为有限个支撑点,不可避免地引入量化误差。更严重的是,当真实值恰好落在两个相邻支撑点的正中间时,模型会陷入"边界效应"(boundary effect)——两个支撑点的概率几乎相等,模型无法做出高置信度的预测,导致预测结果不稳定。
痛点 3:参数增多却难以学到长期趋势
多分支结构的参数量成倍增加,但时序数据集的规模相当有限。若缺乏有效的正则化约束,模型极易过拟合训练集的局部细节,在长期预测任务中丧失捕捉跨周期宏观趋势的能力。
二、interPDN 的核心设计
interPDN 的整体架构可以用一句话概括:四个轻量级骨干分支,两种时间尺度,两组交错支撑集,三种自监督一致性损失。
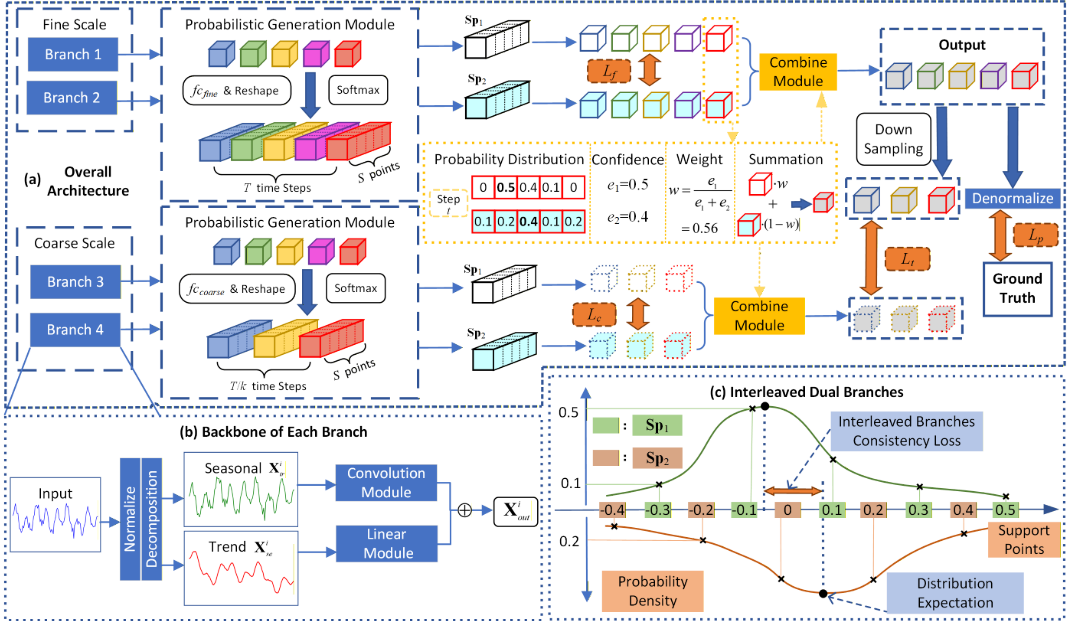
【此处配图:论文 Figure 2,展示整体模型架构、骨干结构和交错双支路设计】:(a)直接逐步概率分布预测的整体模型架构;(b)各分支主干结构;(c)双支路设计对应于交错支撑组。
2.1 骨干分支:季节-趋势分解
每个骨干分支的输入处理流程如下:
- 通道独立:将多元时序
拆分为 C 条独立单通道序列,避免通道间的干扰。
- RevIN 归一化:对每条序列做可逆实例归一化,以应对分布偏移问题。
- 季节流:先进行 Patching(分块),再依次经过线性层和一维卷积聚合相邻 Patch 信息,最后通过 ResNet 结构送入 MLP 解码器,得到季节分量预测
。
- 趋势流:直接用两个无激活函数的线性块对趋势分量建模(带均值池化和层归一化),得到
。
- 两路结果拼接:
这一骨干设计与 xPatch 相似,兼顾了轻量化和对季节/趋势的显式分离建模。
2.2 概率生成模块:从骨干输出到离散分布
传统方法在这里加一个线性投影头直接输出标量。interPDN 则用一个全连接层将 的维度从 2T 扩展到
,再 reshape 成
,其中 S 是支撑集的大小。
每个时间步上对 S 个支撑点做 Softmax,得到该步的离散概率分布;最终预测值是支撑集与概率分布的点积(即期望):
非均匀支撑集:等概率区间划分
一个关键设计细节:归一化后的时序数据近似服从正态分布,若对支撑集均匀划分,数据密集区域的支撑点会太稀疏。论文利用正态分布 CDF 的逆函数,将区间 [-B, B] 划分为 (S-1) 个等概率子区间,支撑点密集分布在数据集中的区域,从而最大程度减少量化误差。
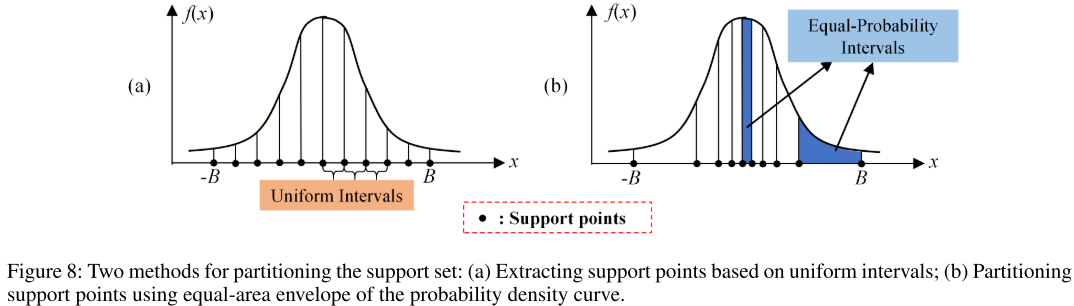
【此处配图:论文 Figure 8,对比均匀区间与等概率区间两种支撑集划分方式】
实验(Table 8)显示,非均匀支撑集在 ETTh1 数据集上的 MSE 平均降低 1.32%,ETTh2 上降低 0.51%。
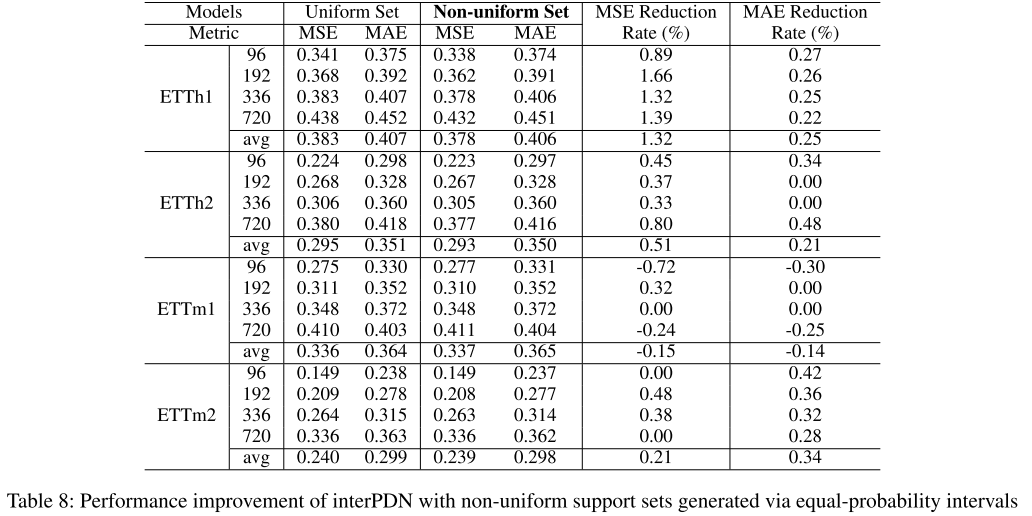
【此处配表:论文 Table 8,均匀 vs 非均匀支撑集的性能对比】
2.3 交错双支路:对抗量化误差的核心机制
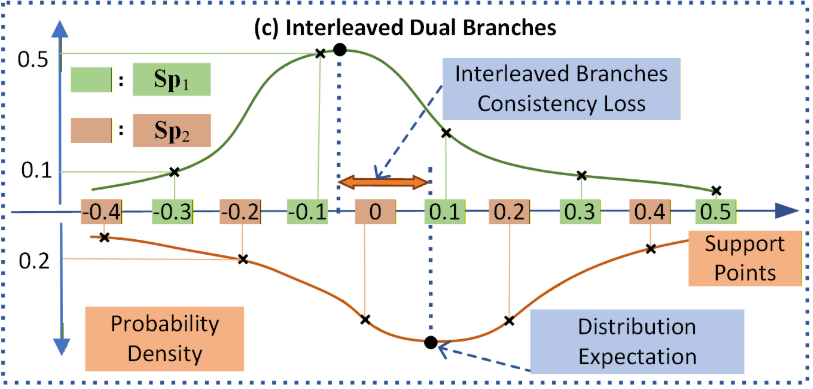
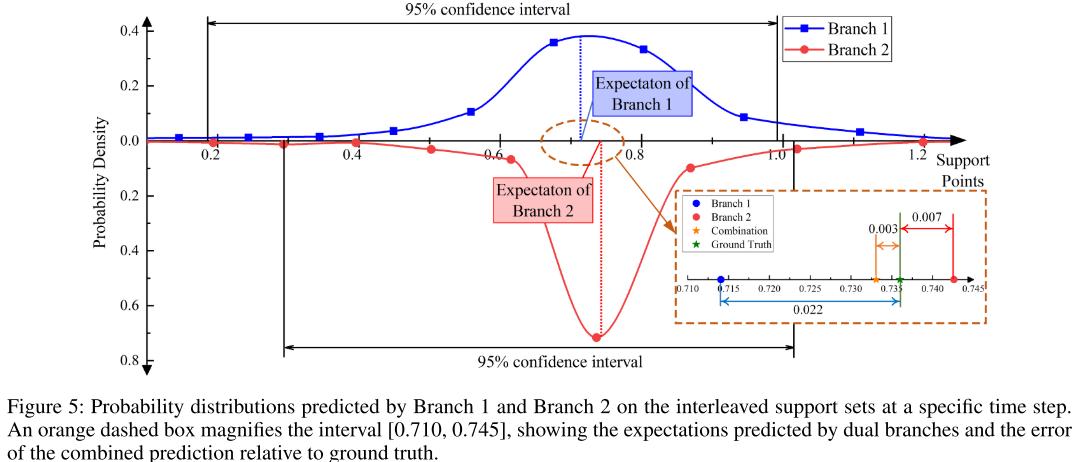
【此处配图:论文 Figure 2(c),展示两组交错支撑集的示意图,以及 Figure 5,展示双支路概率分布可视化案例】
核心思想:构造两个支撑集 和
,使
的每个支撑点恰好落在
相邻两点的中间。当真实值落在
的边界处时,它必然接近
的某个支撑点,从而消除量化模糊。
论文给出了一个直观的可视化案例(Figure 5):在 Electricity 数据集的某一时间步,Branch 1 在两个相邻支撑点(0.676 和 0.803)之间犹豫不决,最大概率仅 0.358,置信度极低,预测误差达 0.022;而 Branch 2 在支撑点 0.736 处以 0.716 的高置信度输出,误差仅 0.007。经过基于最大置信度的加权融合后,最终预测值距真实值仅 0.003。
加权融合策略:不采用简单平均,而是依据每个时间步各支路预测分布的最大概率值(即置信度)计算融合权重:
这一设计保证了"谁更确定,谁主导"的融合逻辑,比简单求和更具鲁棒性。
2.4 双时间尺度:捕捉长期趋势的自监督约束
在细粒度时间尺度(fine scale)的双支路之外,论文在粗粒度时间尺度(coarse scale)上复制了相同的双支路结构(共4个骨干分支,参数不共享)。粗尺度分支的概率生成模块输出维度为 (k 为下采样因子),生成低分辨率的预测序列
。
粗尺度输出不直接参与最终预测,仅作为自监督信号,通过跨尺度一致性损失约束细粒度分支,引导模型关注长期趋势而非局部细节。
论文在 Figure 6 中通过可视化直观展示了这一设计的效果:
- ETTh1(T=192):TimesNet 只能拟合前 80 步,xPatch 无法捕捉上升幅度,iTransformer 甚至预测出与真实趋势相反的方向;而 interPDN 的 MSE 仅为 0.112,峰值拟合精度显著更高。
- Weather(T=336):interPDN 的 MSE 分别比 TimesNet、xPatch 和 iTransformer 低 44.01%、38.06% 和 39.42%。
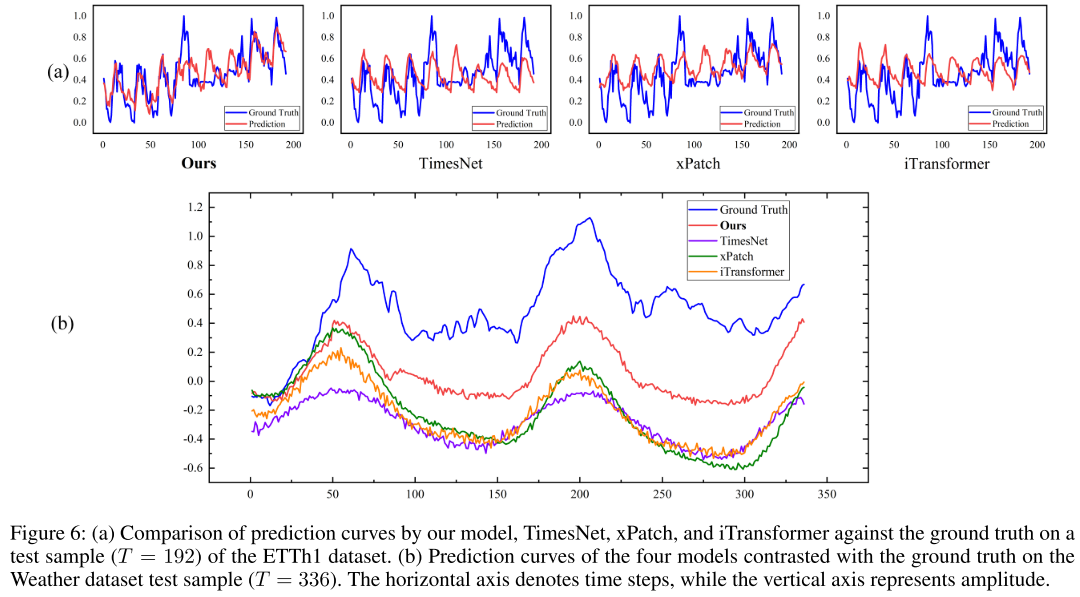
【此处配图:论文 Figure 6,对比四个模型在 ETTh1 和 Weather 数据集上的预测曲线可视化】
2.5 损失函数:四项联合优化
各项含义:
:预测值与真实值之间的主损失,采用 xPatch 的时间步衰减加权 MAE——越靠近历史窗口的时间步权重越高,越远的权重衰减越快,缓解长序列预测中常见的"方向错误"和"模式失真"问题。
:细粒度尺度内,两个交错支路输出之间的 MSE 一致性损失。
:粗粒度尺度内,两个交错支路输出之间的 MSE 一致性损失。
:跨尺度一致性损失,将细粒度预测下采样后与粗粒度预测对齐(均使用 MSE)。
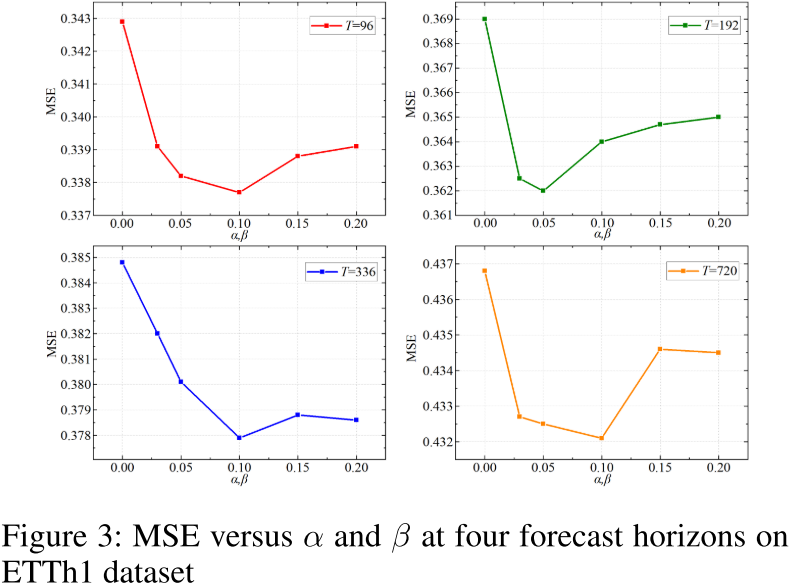
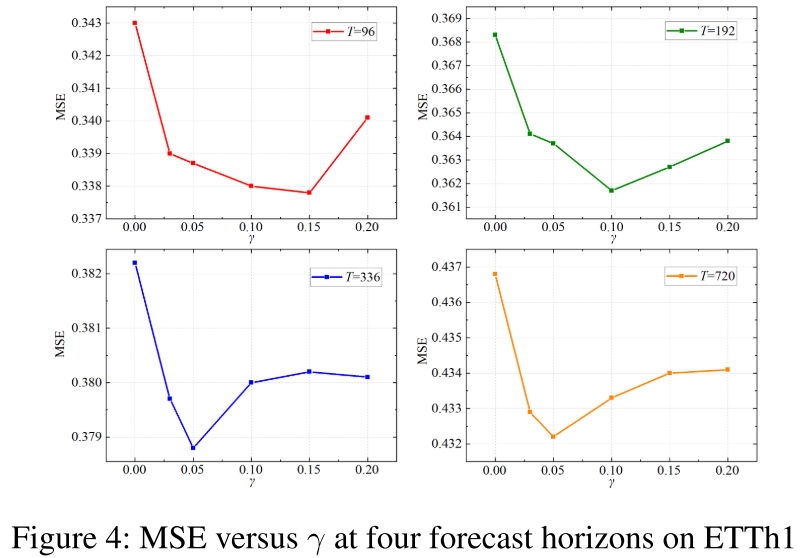
【此处配图:论文 Figure 3 和 Figure 4,分别展示 MSE 随 α/β 和 γ 变化的曲线,验证各损失权重的影响】
超参数搜索实验(Figure 3, 4)证明:当 或
时,MSE 均达到最高值,说明三类一致性损失缺一不可。
三、实验结果
3.1 数据集与基线模型
论文在 9 个真实世界数据集上进行测试,涵盖电力变压器监控(ETTh1/h2/m1/m2)、电力、天气、交通、汇率和疾病数据(预测长度从 96 到 720 步不等,Illness 数据集为 24–60 步),并与 9 个 SOTA 基线对比:
| 基线模型 | 发表年份 | 特点 |
|---|---|---|
| xPatch | 2025 | 与 interPDN 骨干相似,最近邻基线 |
| RAFT | 2025 | 检索增强多尺度融合 |
| AMD | 2025 | 自适应多尺度分解 |
| MOMENT | 2024 | 时序基础模型(Foundation Model) |
| TimeMixer | 2024 | 可分解多尺度混合 |
| iTransformer | 2024 | 倒置 Transformer |
| TimesNet | 2023 | 时序转 2D 图像 |
| PatchTST | 2023 | Patch 分块 Transformer |
| DLinear | 2023 | 纯线性分解模型 |
3.2 主要结果
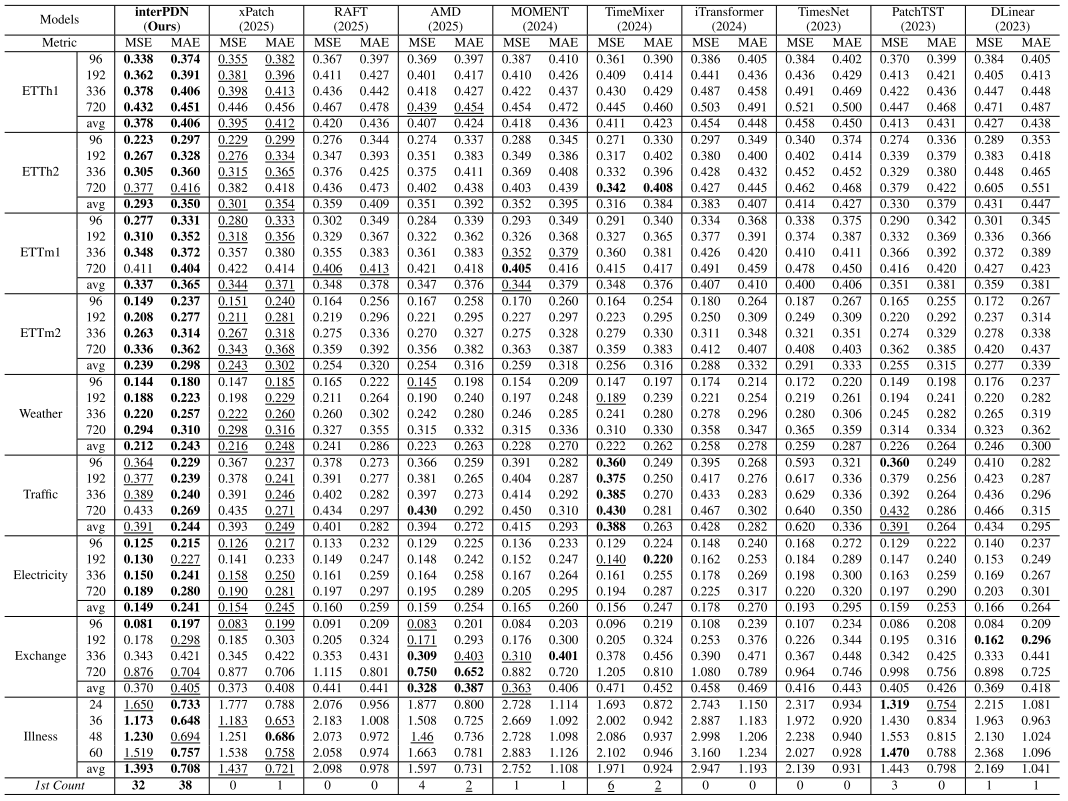
【此处配表:论文 Table 1,9 个数据集上的完整 MSE/MAE 结果对比表】
在 45 个预测任务中:
- MSE 第一:32 个任务(71.11%)
- MAE 第一:38 个任务(84.44%)
- 在未夺冠的任务中,MSE 第二的有 8 个,MAE 第二的有 6 个
关键性能提升幅度(以平均值计):
| 对比基线 | MSE 降低 | MAE 降低 |
|---|---|---|
| xPatch | 2.44% | 1.51% |
| iTransformer | 35.15% | 20.27% |
| PatchTST | 5.31% | 7.15% |
| RAFT | — | 13.96% |
| AMD | — | 4.54% |
| MOMENT | — | 15.65% |
值得注意的是,MOMENT 是专门在大规模跨域数据上预训练的时序基础模型,而 interPDN 仅凭从头训练的轻量级架构即大幅超越,说明针对性的架构设计在数据量有限的场景下具有显著优势。
3.3 消融实验
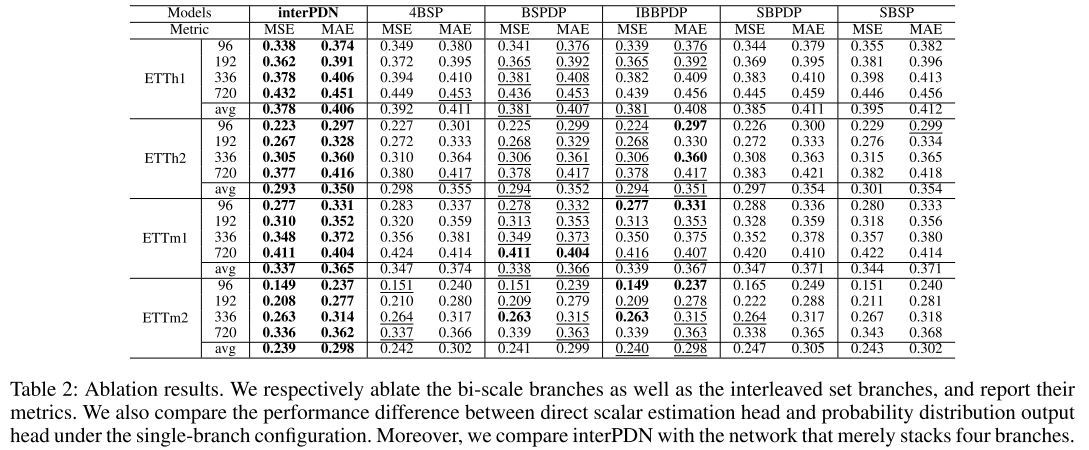
【此处配表:论文 Table 2,消融实验结果表(4个ETT数据集)】
论文对以下五种配置逐一消融:
| 配置简称 | 描述 |
|---|---|
| SBSP | 单支路 + 标量输出头 |
| SBPDP | 单支路 + 概率分布输出头 |
| IBBPDP | 交错双支路 + 概率分布输出头(无粗尺度) |
| BSPDP | 单支路 + 概率分布输出头 + 粗尺度约束 |
| 4BSP | 四支路 + 标量输出头(简单平均融合) |
| interPDN | 完整模型 |
关键发现:
-
概率分布头 vs 标量头:单独使用概率分布头(SBPDP)只在 65% 的任务上优于 SBSP,提升有限甚至偶有退化——说明概率分布建模的优势需要配套的架构设计才能充分发挥。
-
交错双支路的关键性:IBBPDP 在所有任务的 MSE 和 MAE 上均优于 SBSP 和 SBPDP,说明交错结构有效解决了量化误差问题。
-
粗尺度约束的必要性:BSPDP(单支路 + 粗尺度)同样带来显著提升,说明跨尺度自监督约束对长期趋势捕捉至关重要。
-
参数增加≠性能提升:4BSP(四支路标量预测)在 45% 的任务上甚至不如单支路 SBSP,充分证明 interPDN 的性能提升来自概率分布建模机制本身,而非参数量的堆砌。
3.4 不确定性量化评估
论文额外使用 CRPS(Continuous Ranked Probability Score)评估概率预测质量,与四个专门的概率预测模型对比:
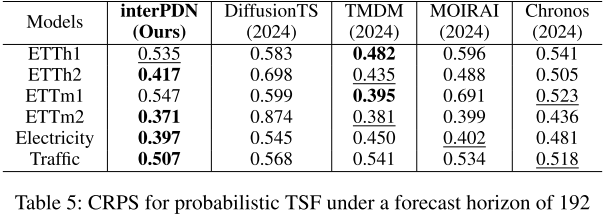
【此处配表:论文 Table 5,CRPS 对比表(预测长度 192)】
interPDN 在 6 个数据集中的 4 个上优于专用概率预测模型,且:
- 平均 CRPS 比 DiffusionTS 低 39.40%
- 平均 CRPS 比 MOIRAI 低 12.11%
- 平均 CRPS 比 Chronos 低 8.29%
- 仅比 TMDM 高 3.24%
这说明 interPDN 虽然主要面向确定性预测任务设计,但其概率建模能力同样具有实际价值。
3.5 计算效率

【此处配表:论文 Table 9,计算效率对比表】
四支路架构看似"重",实际上因骨干轻量(仅 MLP + 一维卷积),interPDN 的计算效率远超同类模型:
- 每轮训练时间(1.251s)是 TimesNet(12.610s)的 1/10,是 PatchTST(8.418s)的 1/6.7
- 参数量(2.96M)低于 TimesNet(3.24M)和 PatchTST(3.16M)
- 内存占用(11.29MB)与 TimesNet/PatchTST 相当,仅略高于 xPatch 和 DLinear
3.6 框架泛化性:interPDN + DLinear
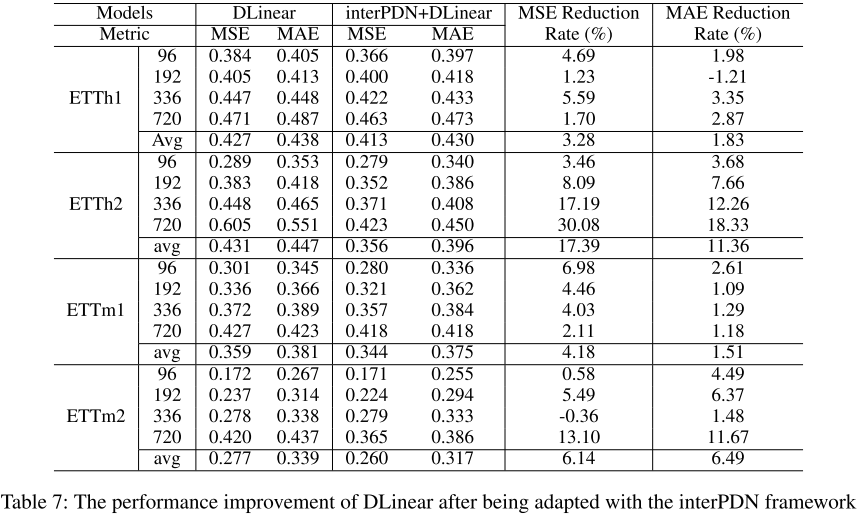
【此处配表:论文 Table 7,DLinear 与 interPDN+DLinear 的性能对比表】
将 interPDN 的概率分布框架嫁接到最简单的 DLinear 骨干上,结果同样令人印象深刻:
- 4 个 ETT 数据集上平均 MSE 降低均超过 3%
- ETTh2 数据集上 MSE 和 MAE 均降低超过 10%(MSE 降低 17.39%,MAE 降低 11.36%)
这验证了 interPDN 框架具有良好的通用性,不依赖特定骨干架构。
四、方法总结与启示
interPDN 的核心贡献可以归纳为以下三个层次:
第一层:范式转变——将时序预测从"点估计"转变为"分布估计",且不依赖高斯等先验假设,直接建模任意形态的离散概率分布。
第二层:工程设计——交错双支路 + 等概率非均匀支撑集,系统性地解决了离散化带来的量化误差和边界效应问题。
第三层:正则化体系——三种一致性损失(细尺度内、粗尺度内、跨尺度)构成完整的自监督约束体系,使四倍参数量的多支路模型能够在小规模时序数据集上稳定训练并保持泛化能力。
从更宏观的视角看,interPDN 的工作揭示了一个重要的设计哲学:在数据规模受限的领域,精心设计的归纳偏置(inductive bias)和结构性约束,往往比盲目堆叠参数更有效。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)