字节面试官:“你的 Deep Research 跑了 20 步,模型记不住第 3 步找到的结论了,怎么办?“ 我:“加大 Context?“ 他翻了翻白眼。。。
上周有个学员面字节,做的正好是 Deep Research 方向。面试官问:“你说你的 Agent 支持深度研究,跑了 20 步,但问题是,到了第 15 步,模型还记得第 3 步找到的关键结论吗?怎么验证的?出现过’忘记’的情况吗?”
他说:“我把 Context 窗口开得比较大,32k,应该够了。”
面试官皱眉:“32k 听起来不少,但 20 步每步平均 1000 个 token,就已经 20k 了,还要留 Prompt 和工具结果,很快就满了。而且就算没满,模型对 20k 之前的内容注意力也会衰减。你的解法本质上是靠’更大的窗口’撑着,不是真正解决了问题。”
追问:“那如果任务需要 50 步呢?”
没有答案。
今天把这个问题彻底解决。这就是 IterResearch 框架要做的事情——用演进报告替换线性历史记录,把上下文从"越来越长的对话"变成"越来越好的研究报告"。
一、ReAct 的上下文问题:从线性积累到认知过载
先把问题说清楚。
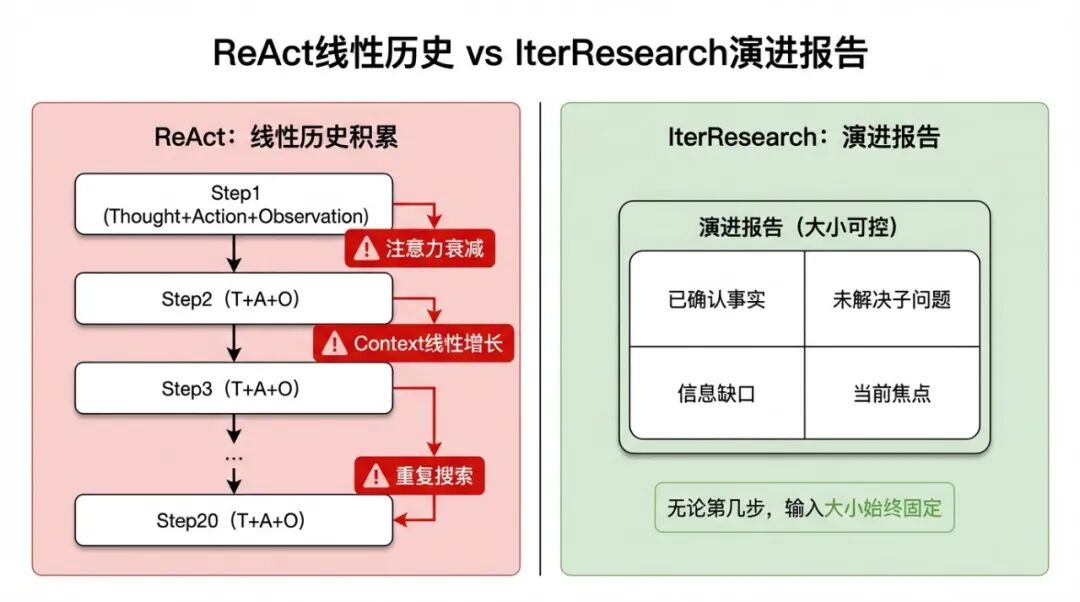
ReAct 的工作方式是把每一步的 Thought → Action → Observation 追加到上下文里,形成一个线性的历史记录。模型每次推理都要读这整段历史,从里面提取当前需要的信息,然后决定下一步。
这个机制在任务步骤少的时候(5-8步)没有问题,历史不长,模型能处理。但当步骤数超过15步时,问题开始集中出现:
问题一:Context 越来越长,注意力越来越稀薄。
Transformer 的注意力机制是全局的,但在超长序列里,对早期 token 的有效注意力会下降。第 3 步找到的一个关键事实——“A 公司 2024 年的净利润是 12 亿”——到了第 20 步,可能已经淹没在大量中间步骤的噪声里,模型即使没有"忘记"这个 token,实际上它对这个事实的利用率已经很低了。这会导致一个很常见的现象:模型在后续步骤里重新搜索了已经找到的信息,因为它"感觉"自己还不确定。
问题二:搜索结果大量重复,但 Context 不断增大。
线性历史里有大量"冗余"信息——同一个事实被不同来源重复提及,对话历史里有大量"我接下来要……"这类推理过程文字。这些内容对推理没有额外帮助,但持续占据 Context 空间。
问题三:上下文满了,只能截断,但截断会丢信息。
当 Context 快满时,ReAct 只能把最老的历史截掉。但最老的历史里往往有最初的任务定义、关键的背景信息、早期发现的核心结论。一截断,模型开始在没有全局背景的情况下推理,更容易绕圈子。
这三个问题加在一起,决定了 ReAct 不能无限扩展。它是一个线性积累的架构,而真正的深度研究是一个需要非线性、迭代式理解的过程。
ReAct 线性历史 vs IterResearch 演进报告的根本差异
二、IterResearch 的核心思想:用"演进报告"替换"线性历史"
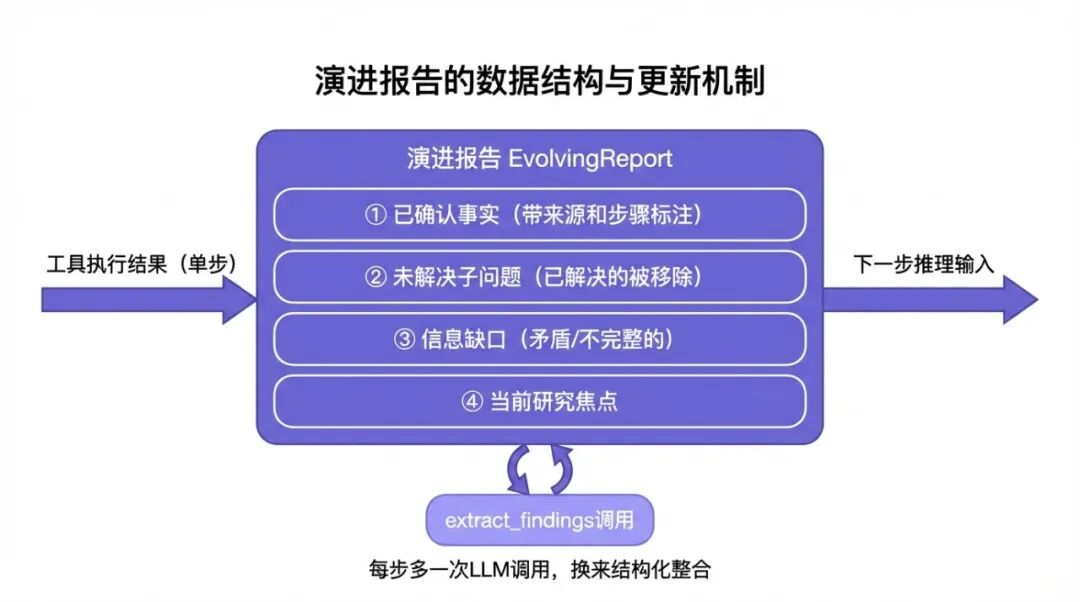
IterResearch 的核心洞察只有一句话:与其保留每一步的原始对话记录,不如维护一份随研究推进而不断更新的结构化报告。
在 IterResearch 里,Agent 的工作空间不是一个越来越长的对话历史,而是一个固定结构的"演进报告(Evolving Report)",它包含:
-
已确认的事实(Confirmed Facts)
:每一步新发现的、经过来源确认的信息
-
尚未解决的子问题(Open Questions)
:还没找到答案的待研究问题
-
信息缺口(Information Gaps)
:发现了有某个方向的信息但还不完整
-
当前研究方向(Current Focus)
:下一步要研究的具体问题
每次 Agent 完成一步搜索后,不是把 Observation 追加到历史里,而是把新发现的信息整合更新到演进报告里——确认了的事实加进 Confirmed Facts,发现了新问题加进 Open Questions,发现某个信息缺口加进 Information Gaps。
然后下一步的推理输入,不是完整的历史记录,而是当前版本的演进报告加上这一步的原始工具结果。
这个改变带来了一个根本性的性质变化:上下文的大小不再随步骤数增长,而是始终保持在报告的大小(相对固定)加上当前步骤的工具结果(单步大小)。
不管研究进行了 10 步还是 50 步,模型每次推理的输入规模都是可控的。
class EvolvingReport: """演进报告:Deep Research Agent 的中央记忆""" def __init__(self): self.confirmed_facts: list[dict] = [] # 已确认的事实 self.open_questions: list[str] = [] # 待解决的子问题 self.information_gaps: list[str] = [] # 信息缺口 self.current_focus: str = "" # 当前研究焦点 self.research_steps: int = 0 # 已执行步骤数 def update(self, new_findings: dict): """整合一步的新发现,更新报告""" # 追加已确认事实(带来源标注) for fact in new_findings.get("facts", []): self.confirmed_facts.append({ "content": fact["content"], "source": fact["source"], "step": self.research_steps }) # 更新待解决问题(已解决的从列表移除) resolved = new_findings.get("resolved_questions", []) self.open_questions = [q for q in self.open_questions if q not in resolved] # 追加新发现的子问题 self.open_questions.extend(new_findings.get("new_questions", [])) # 更新当前研究焦点 if new_findings.get("next_focus"): self.current_focus = new_findings["next_focus"] self.research_steps += 1 def to_prompt_context(self) -> str: """把报告转成 Prompt 上下文(固定大小)""" facts_str = "\n".join([ f"- {f['content']} [来源: {f['source']}]" for f in self.confirmed_facts[-20:] # 最多保留最近20条事实 ]) questions_str = "\n".join([f"- {q}" for q in self.open_questions[:10]]) return f"""## 当前研究状态(第{self.research_steps}步) ### 已确认的事实 {facts_str} ### 尚未解决的子问题 {questions_str} ### 当前研究焦点 {self.current_focus} """
关键代码注意两点:confirmed_facts 只保留最近 20 条,不是无限追加;open_questions 已解决的会被移除,而不是保留历史。这确保了报告大小始终可控。
IterResearch 演进报告的数据结构和更新机制
三、用演进报告驱动推理循环
有了演进报告,整个 IterResearch 的执行循环比 ReAct 稍复杂,但逻辑更清晰:
async def iter_research(query: str, tools: ToolSet, max_steps: int = 30) -> str: """IterResearch 主循环""" report = EvolvingReport() report.current_focus = query # 初始焦点就是原始问题 report.open_questions = [query] for step in range(max_steps): # 1. 构建当前步骤的输入:报告快照 + 当前焦点 context = report.to_prompt_context() # 2. 让模型决定下一步行动 action = await llm.decide_action( context=context, available_tools=tools.list(), system_prompt=ITER_RESEARCH_SYSTEM_PROMPT ) # 3. 终止检测:模型判断研究已充分 if action.type == "finish": break # 4. 执行工具调用 observation = await tools.execute(action) # 5. 整合发现,更新演进报告(关键步骤) new_findings = await llm.extract_findings( action=action, observation=observation, current_report=context ) report.update(new_findings) # 6. 检查是否还有未解决的问题 if not report.open_questions: break # 所有子问题都已解决 # 7. 基于演进报告生成最终答案 return await llm.synthesize_report(report)
注意第5步——extract_findings 是 IterResearch 相对于 ReAct 多出来的一个 LLM 调用。它的任务是把原始工具结果解析成结构化的新发现(哪些是已确认事实,哪些是新发现的子问题,下一步焦点是什么)。
这个额外的 LLM 调用有成本,但它换来了上下文的可控性——与其让模型在 20k 的历史记录里自己找信息,不如用一次额外调用把关键信息结构化出来,后续每步的推理输入都更干净、更可靠。
在我们的实际测试里,IterResearch 和 ReAct 对比:在 10 步以内的任务上,ReAct 因为没有额外调用,速度更快,成本更低;在 15 步以上的任务上,IterResearch 的准确率明显高于 ReAct,而且不会出现 ReAct 的"后期绕圈子"现象,总 token 消耗反而更少(因为避免了大量重复搜索)。
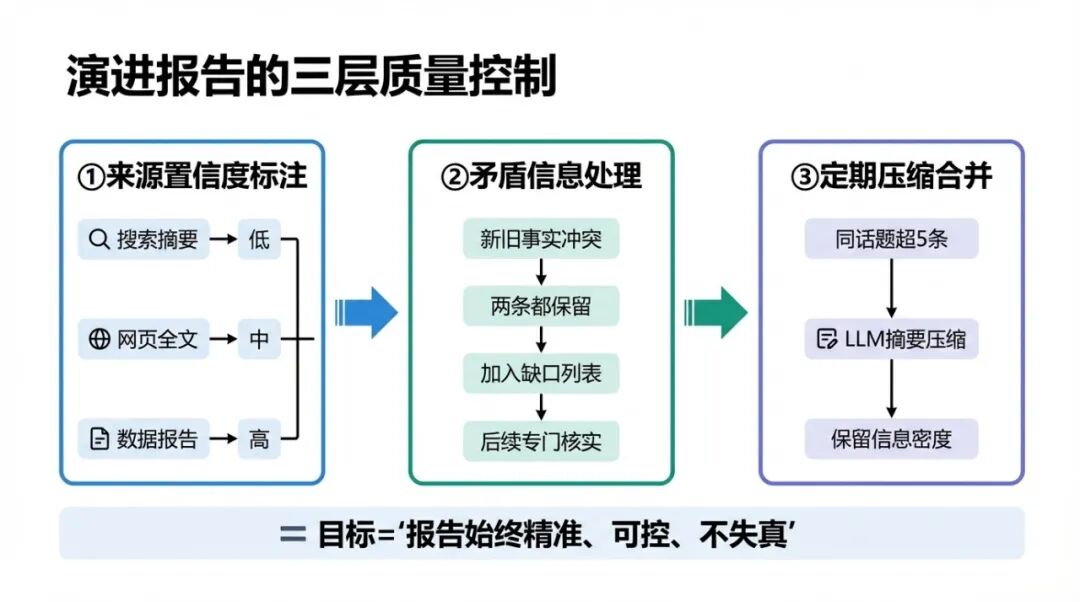
四、报告更新的质量控制:防止"噪声进,噪声出"
演进报告的质量直接决定研究结果的质量。如果把错误的信息加进了 Confirmed Facts,后续的推理会在错误的基础上继续往前走,越走越偏。
需要在 extract_findings 这一步做几个质量控制:
控制一:事实需要标注置信度和来源。
不是所有工具返回的内容都是同等可信的。搜索摘要的可信度低于网页全文,网页全文的可信度低于有明确数据来源的报告。在加入 Confirmed Facts 时,标注来源类型和置信度(高/中/低),后续综合报告时低置信度的事实要标注不确定性。
控制二:矛盾信息的处理机制。
当新发现的事实和已有 Confirmed Facts 矛盾时,不是简单地用新的覆盖旧的,而是两条都保留,同时在 Information Gaps 里记录"这两个来源对X事实的描述存在矛盾,需要进一步核实"。让模型在后续步骤里专门核实矛盾,而不是悄悄让一个版本消失。
控制三:防止 Confirmed Facts 无限增长。
演进报告的价值在于大小可控。如果 Confirmed Facts 无限追加,很快又变成了另一种形式的线性历史。处理方式是定期做压缩——对同一话题的多条事实做摘要合并,把"小米 2024Q1 营收 598 亿"和"小米 2024Q1 同比增长 18.8%“合并成"小米 2024Q1 营收 598 亿(同比+18.8%)”,保留信息密度,减少冗余。
演进报告的质量控制机制
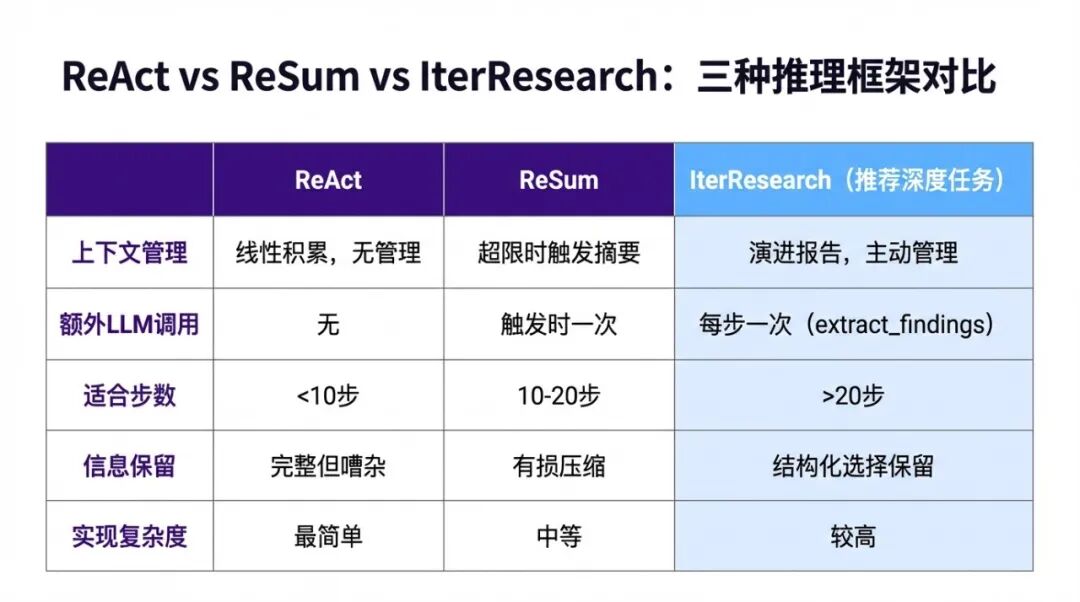
五、IterResearch vs ReSum:两种上下文管理策略的区别
前面几篇提到过 ReSum,这里专门做一个对比,因为面试里经常被问到。
两种方案解决的是同一个问题(上下文膨胀),但思路完全不同。
ReSum(动态摘要模式): 维持 ReAct 的线性历史结构,但在上下文即将溢出时,触发一次 LLM 摘要调用,把最老的一段历史压缩成摘要,腾出空间继续添加新内容。
优点:改动最小,在现有 ReAct 框架上加一个摘要触发机制就够了,实现成本低。
缺点:摘要是有损压缩,如果摘要质量不好,关键细节可能被压掉。而且摘要触发时机是被动的(Context 快满才触发),不是主动管理,在高频摘要的情况下,多次压缩会导致信息越来越失真。
IterResearch(演进报告模式): 从一开始就不采用线性历史,而是用结构化报告作为工作空间,主动管理"哪些信息需要保留、以什么形式保留"。
优点:信息的留存是主动选择的,不是被动压缩的。结构化报告让模型每次都能清楚地看到当前研究状态,不需要从大量历史里"找"信息。
缺点:需要额外的 extract_findings 调用,每步多一次 LLM 调用;报告结构需要精心设计,否则结构化过度会丢失重要细节。
实际工程中的选择建议:
| 场景 | 推荐方案 |
|---|---|
| 任务步数 < 10,快速验证 | ReAct(最简单) |
| 任务步数 10-20,平衡速度和质量 | ReSum(轻量改造) |
| 任务步数 > 20,深度研究 | IterResearch(最稳定) |
| 对准确率要求极高,接受成本 | Research-Synthesis(并行验证) |
面试怎么答 IterResearch 和上下文管理?
如果面试官问"你的 Deep Research Agent 步数多了怎么处理上下文膨胀",或者问"ReAct 和 IterResearch 的区别":
先讲问题本质(20秒)。 “ReAct 的线性历史机制在步数超过 15 步后会出现两个问题:一是 Context 线性增长,很快接近窗口上限;二是模型对早期信息的注意力衰减,导致重复搜索和推理质量下降。这不是靠加大 Context 能解决的,是架构层的问题。”
再讲 IterResearch 的核心思路(30秒)。 “IterResearch 的解法是用演进报告替换线性历史。每步的工具结果不是追加到历史里,而是结构化地整合进报告——已确认的事实、未解决的子问题、信息缺口。下一步的输入是当前报告快照加上这一步的原始工具结果,大小始终可控,不随步数增长。”
然后讲实现细节(30秒)。 “关键是 extract_findings 这一步——每步执行后,用 LLM 把原始观察结果解析成结构化新发现,更新演进报告。代价是每步多一次 LLM 调用,但换来了上下文可控和推理质量稳定。我们在实测里,15步以上任务 IterResearch 的准确率比 ReAct 高 18 个百分点,总 token 消耗反而更少。”
最后说选型逻辑(15秒)。 “短任务用 ReAct,中等任务用 ReSum,深度研究用 IterResearch。不是 IterResearch 一定最好,是根据任务复杂度选合适的方案。”
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献159条内容
已为社区贡献159条内容

所有评论(0)