第11章 Streaming(中):高级音频应用(1)——项目六:语音克隆、变声器与文本转录器
第11章 Streaming(中):高级音频应用(1)——项目六:语音克隆、变声器与文本转录器
第11章 Streaming(中):高级音频应用
本章是音频的高级应用,首先介绍专业语音大模型ElevenLabs,并与Gradio结合实现语音克隆、语音变声器与文本转录器。然后介绍Python实时通信库FastRTC,内容包括WebRTC协议、FastRTC的内置功能与自定义路由、核心特性Stream的构造参数及运行方式、配置连接TURN服务器等。接着介绍如何通过Twilio连接TURN服务器,内容包括STUN、ICE与Twillo关系、Twilio的网络穿透服务。最后通过实现AI通话——通过Twilio接入Stream拨打和接听智能电话,内容主要有通过Ngrok获取URL与配置TwiML App,并使用Twilio实现电话外呼与接入。本章内容有较高的实用价值,读者可灵活应用于生活或生产中。
11.1 ElevenLabs:高级智能语音技术
为了拓展语音应用范围,引入ElevenLabs智能语音技术,作为更专业的语音、音频和音乐工具,不仅能无缝替换之前的语音转换工具,还能实现更丰富的语音功能,产生更逼真的语音甚至优美的音乐。更多ElevenLabs内容请参阅:🖇️链接11-1。
11.1.1 核心功能、实现产品与可用模型
ElevenLabs是一家专注于AI语音技术的公司,ElevenLabs AI模型能够生成高度自然、富有表现力的人声,适用于有声书、视频配音、虚拟助手、游戏角色对话等场景。ElevenLabs的核心功能包括:
- 文本转语音(TTS)、语音转文本(STT)、文本转对话(TTD)等,支持多种语言和声音风格(如自然、激昂、柔和等),可调节语速、语调、停顿等参数。
- 声音变声器、声音隔离器、声音重新混合器、声音代理及其他声音类(如声音库,声音克隆、声音设计及声音付费),上传少量样本音频即可实现。
- 音乐、配音、音效、声音文本强制对齐等。
- 多语言支持,包括英语、中文、法语、德语、西班牙语等70+语言。
- 流式语音生成,低延迟,适合交互式应用(如聊天机器人)。
实现上述功能的产品众多,官方归类为ElevenCreative,涵盖了从帐户创建到语音克隆、语音合成和配音的所有内容,大致分类如下:
- 演示区(Playground):文本与语音互转、变声器、音效、图像与视频、模板等。
- 产品(Product):工作室、音乐、配音、文稿转写、字幕生成等。
- 语音(Voices):语音库、语音克隆、语音设计等。
- 音频工具(Audio Tools):音频原声、配音工作室、人声分离、AI语音分类器。
在官网页面,普通用户可通过ElevenCreative,普通用户可在页面点选配置来实现自己的音频需求,而开发者可通过调用ElevenAPI,在代码中引入上述功能。
ElevenLabs的可用模型包括三类:文本转语音、语音转文本和音乐。其中文本转语音类模型典型代表有:
(1)Eleven v3(ID:eleven_v3):最新最先进的语音合成模型,能生成自然逼真的语音,具有丰富的情感表现力,并支持跨70多种语言的上下文理解,适用于角色对话、有声书制作和情感化对话。
(2)Eleven Multilingual v2(ID:eleven_multilingual_v2):是最先进的、具备情感感知能力和和跨语言上下文理解能力的语音合成模型。该模型在所有支持的语言中都能保持一致的语音质量和个性,同时保留发言者的独特特征和口音。它支持29种语言,推荐作为多数场景的首选方案。
(3)Eleven Flash v2.5(ID:eleven_flash_v2_5):超低延迟,支持32种语言,响应速度更快,字符单价降低50%。
(4)Eleven Turbo v2.5 (ID:eleven_turbo_v2_5):质量与延迟的最佳平衡,特别适合对实时性要求高的开发场景,支持32种语言。
语音转文本类模型有:
(1)Scribe v2(ID:scribe_v2):是Eleven最先进的语音识别模型,专为90多种语言的精准转录而设计。它提供单词级时间戳的精准转录、多人音频的说话人分割技术、增强上下文理解的动态音频标记等高级功能,适用于转录服务、会议记录、内容分析和多语言识别。
(2)Scribe v2 Realtime(ID:scribe_v2_realtime),是Eleven最快最精准的实时语音识别模型,以超低150毫秒延迟,实现90多种语言的顶尖识别准确率,支持流式传输、VAD及多种音频格式。
音乐类模型有:
(1)Eleven Music(ID:music_v1):是一款文本生成音乐模型,可通过自然语言提示词生成任意风格的专业级音乐。该模型能理解创作意图,并根据目标生成具有上下文感知的完整音频。支持自然语言与专业音乐术语输入,提供以下尖端特性:①对流派、风格与结构的完整控制。②人声演唱或纯乐器演奏版本。③多语言支持(包括英语、西班牙语、德语、日语等)。④可编辑整曲或特定段落的音效与歌词。
此外还有人性化、富有表现力的语音设计模型eleven_ttv_v3(Text to Voice),多语言语音转换器模型eleven_multilingual_sts_v2(Speech to Speech),仅限英语的语音转换模型eleven_english_sts_v2,以及具有实验功能并减少沉默时幻觉的scribe_v1_experimental。
11.1.2 文本转语音API:文件处理和流式处理
ElevenLabs API提供简洁接口,可访问最先进的音频模型与智能产品。下面分别以文本转语音、语音转文本及音乐模型的API为例讲解ElevenLabs API用法。
文件处理。官方提供Python和TypeScript两种语言版本的操作,本书以Python为例,讲述使用文本转语音API。首先申请ELEVENLABS_API_KEY,并安装elevenlabs,若需通过扬声器播放音频,可能会提示安装MPV(🖇️链接11-2)或ffmpeg。准备完成后发起首个请求,如代码11-1所示:
from dotenv import load_dotenv
from elevenlabs.client import ElevenLabs
from elevenlabs.play import play
import os
import uuid
load_dotenv()
client = ElevenLabs(
api_key=os.getenv("ELEVENLABS_API_KEY"),
)
voice_id = "JBFqnCBsd6RMkjVDRZzb"
def text_to_speech_file(text: str, voice_id) -> str:
response = client.text_to_speech.convert(
voice_id=voice_id, # Adam pre-made voice
output_format="mp3_22050_32", text=text,
model_id="eleven_multilingual_v2", # most lifelike model
voice_settings=VoiceSettings(
stability=0.0, # 最大创造力/变化性(0最不稳定,1最稳定)
similarity_boost=1.0, # 最大化与原始语音的相似度
style=0.0, # 情感表达强度(0最低,1最高)
use_speaker_boost=True, # 启用说话者增强功能
speed=1.0 # 正常语速(0.5慢速,2.0快速)
)
)
# option 1: uncomment the line below to play the audio back
# play(response)
# option 2: Generating a unique file name for the output MP3 file
save_file_path = f"{uuid.uuid4()}.mp3"
with open(save_file_path, "wb") as f:
for chunk in response:
if chunk:
f.write(chunk)
print(f"{save_file_path}: A new audio file was saved successfully!")
return save_file_path
本例将文本转语音(TTS)生成的语音写入文件保存,详细解析如下:
- 先通过load_dotenv在控制台或.env文件获取ELEVENLABS_API_KEY,然后创建ElevenLabs客户端。方法search()可列出所有符合条件的声音,方便用户选择;方法settings.get()可获取voice_id对应的语音设置。
- 定义函数text_to_speech_file,首先调用语音转文本的可生成完整语音的转换函数convert,并设置转换文本、voice_id、model_id及输出格式(MP3格式,22050Hz采样率,32kbps比特率),以及通过VoiceSettings可选的定制输出语音,完全掌控情感、节奏与表达。
- 获取模型eleven_multilingual_v2的响应。有两种处理方式:①使用函数play()直接播放转换后的音频(当前未使用,仅作为选项展示);②写入文件,先使用UUID生成唯一文件名,再以"wb" 模式写入二进制,最后流式处理生成器response(分块写入避免内存溢出)。
补充说明:可用的MP3格式包括低质量低带宽的mp3_22050_32(常用于网络传输流)、标准的CD音质mp3_44100_128(常用于广播)、无损PCM的pcm_16000(常用于训练语音克隆)、最高质量的高清pcm_24000(常用于产品级应用)。自定义设置可以构建个性化语音,也可以访问ElevenLabs语音实验室🖇️链接11-3,尝试不同的语音、语言和音频设置。
流式处理。ElevenLabs API支持特定端点的实时音频流式传输,其通过HTTP分块传输编码直接返回原始音频字节,使得客户端能够在音频生成时逐步处理或播放,官方Python库和Node库均包含简化处理连续音频流的实用工具。
文本转语音、语音变声器及语音分离器等API均支持流式传输。TTS API请求的音频流有两种处理方式:流式播放或手动处理音频字节,如代码11-2所示:
import os
from typing import IO
from io import BytesIO
from dotenv import load_dotenv
from elevenlabs.client import ElevenLabs
from elevenlabs import stream
from elevenlabs import VoiceSettings
load_dotenv()
ELEVENLABS_API_KEY = os.getenv("ELEVENLABS_API_KEY")
client = ElevenLabs(api_key=ELEVENLABS_API_KEY)
def text_to_speech_stream(text: str, voice_id) -> IO[bytes]:
if not voice_id:
voice_id = "pNInz6obpgDQGcFmaJgB" # Adam pre-made voice
response = client.text_to_speech.stream(voice_id=voice_id,
output_format="mp3_22050_32",
text=text,
model_id="eleven_turbo_v2_5", # use the turbo model for low latency
voice_settings=VoiceSettings(stability=0.0, similarity_boost=1.0,
style=0.0, use_speaker_boost=True, speed=1.0))
# option 1: play the streamed audio locally
# stream(response)
# option 2: process the audio bytes manually
audio_stream = BytesIO()
for chunk in response:
if chunk:
audio_stream.write(chunk)
audio_stream.seek(0)
return audio_stream
text_to_speech_stream("This is Kobe Bean Bryant.")
示例实现了流式文本转语音服务,它与代码10-33基本相同,只讲解不同点:
- 代码改写:在定义text_to_speech_stream时,返回二进制流接口IO[bytes];在生成流式回复时,由convert()改为stream();模型选用低延迟的turbo系列大模型;在播放音频时,由play()改为stream();使用内存处理流数据而不是文件。
- 处理流数据:使用BytesIO创建内存中的字节流对象(类似文件),以便在内存中存储音频数据,避免磁盘I/O;分块接收并流式写入,避免大内存占用;最后使用seek(0)将流指针重置到开头,便于后续读取,并返回内存流。
- 疑难点讲解:函数text_to_speech_stream要求返回IO[bytes],实际返回BytesIO。两者的区别是,IO[bytes]是类似Int、String的抽象基型,表示二进制流,通过统一接口read()可转化为字节流BytesIO;BytesIO是IO的子类,是可直接实例化的具体类型。标注为IO[bytes],未来可以改成其他类型的流(如临时文件,字节流等)。
11.1.3 语音转文本API与音乐API
语音转文本API。展示如何使用语STT API,如代码11-3所示:
import requests
from elevenlabs.client import ElevenLabs
client = ElevenLabs()
audio_url = ("https://storage.googleapis.com/eleven-public-cdn/audio/marketing/nicole.mp3"
)
response = requests.get(audio_url)
audio_data = BytesIO(response.content)
transcription = client.speech_to_text.convert(
file=audio_data,
model_id="scribe_v2",
tag_audio_events=True,
language_code="eng",
diarize=True, # Whether to annotate who is speaking
)
print(transcription)
本例使用ElevenLabs完整实现语音转文字(STT)服务,详解如下:
- 处理流程:首先创建客户端,不传API_KEY时,会自动从环境变量读取;然后从URL下载示例MP3音频文件;接着使用response.content获取二进制响应内容,并使用BytesIO避免保存临时文件;最后使用的Scribe v2模型进行转录。
- STT核心调用:speech_to_text.convert(),它返回转录文本、时间戳、置信度等信息的对象。开启tag_audio_events后,会在转录中标记非语音事件,比如笑声、鼓掌等。language_code设置支持的语言代码,如果为None自动检测语言。开启diarize时,将说话人分离,识别谁在什么时候说话,输出通常为对话格式。
Eleven Music生成音乐音轨。目前仅支持付费用户,如代码11-4所示:
from elevenlabs.client import ElevenLabs
from elevenlabs.play import play
elevenlabs = ElevenLabs()
track = elevenlabs.music.compose(
prompt="Create an intense, fast-paced electronic track for a high-adrenaline video game scene. Use driving synth arpeggios, punchy drums, distorted bass, glitch effects, and aggressive rhythmic textures. The tempo should be fast, 130–150 bpm, with rising tension, quick transitions, and dynamic energy bursts.",
music_length_ms=10000)
play(track)
# Save the track to a file
with open("path/to/music.mp3", "wb") as f:
for chunk in track:
f.write(chunk)
这段代码是一个ElevenLabs AI音乐生成的完整示例,包含了播放和保存两个核心功能。功能讲解如下:
- AI音乐生成:基于文本描述生成10秒电子音乐,track是返回的音频流对象(可迭代的二进制数据)。
- 两种处理方式:①实时播放,使用play()函数直接播放;②文件保存,以二进制写入模式打开MP3文件,遍历音频流的数据块并将每个数据块写入文件。
注意:track是一个生成器(generator),需要迭代获取所有数据。
生成作曲方案并转为音频。作曲方案是JSON形式的音乐生成描述框架,能够以更精细的参数控制生成指定音乐,随后可配合Eleven Music生成音乐。
由ElevenLabs API,即可使用compose()直接生成作曲,也可先通过composition_plan()生成作曲方案再由方案生成作曲。但通过作曲方案,可以对每个生成段落进行更精细控制,从而生成更复杂的音乐。通过该API,可以从一个提示词生成作曲方案,如代码11-5所示:
from elevenlabs.client import ElevenLabs
from elevenlabs import play
elevenlabs = ElevenLabs()
composition_plan = elevenlabs.music.composition_plan.create(
prompt="Create an intense, fast-paced electronic track for a high-adrenaline video game scene. Use driving synth arpeggios, punchy drums, distorted bass, glitch effects, and aggressive rhythmic textures. The tempo should be fast, 130–150 bpm, with rising tension, quick transitions, and dynamic energy bursts.",
music_length_ms=10000)
print(composition_plan)
composition = elevenlabs.music.compose(
composition_plan=composition_plan,
)
play(composition)
这段代码展示了ElevenLabs AI生成分离式音乐的完整流程,分两阶段实现:①第一阶段由composition_plan创建作曲方案,生成音乐的结构描述(不产生音频);②第二阶段基于作曲方案执行compose() 作曲,实际生成音频并播放。
11.2 项目六:语音克隆、变声器与文本转录器
ElevenLabs关于语音的产品主要有变声器、人声分离、配音(Dubbing)、语音库、语音克隆、语音设计及语音混音等,其中语音库🖇️链接11-4囊括了各类人声语音,可通过语音 ID调用。本节通过项目语音克隆、变声器与文本转录器讲述语音克隆、变声器及TTS的用法,其他产品应用可参考本项目的实现。
11.2.1 语音克隆、变声器、文本转录器的介绍与代码实现
语音克隆技术在ElevenLabs有两种选择:即时语音克隆(Instant Voice Cloning,IVC)和专业语音克隆(Professional Voice Cloning,PVC),详述如下:
- IVC:IVC通过较短的语音样本近乎即时地创建克隆语音。IVC不会训练或创建定制AI模型,而是依托训练数据的先验知识进行智能推测,而非基于目标声音进行精确训练。IVC对大多数声音都能取得出色效果,但其最大局限在于:当需要克隆具有独特口音或特质的声音,且AI在训练过程中未曾接触过类似语音样本时,效果可能受限。此时,采用PVC进行显式训练的定制模型将是最优选择。
- PVC:PVC是面向Creator+订阅用户的专属功能。该技术通过海量语音数据训练专属模型,打造与原声难辨真伪的超逼真声音模型。由于定制模型需要精细调优和训练,PVC的制作周期会比IVC稍长。具体耗时受排队人数等多重因素影响,较难给出精确预估,参考时效如下:英语约3小时,多语种约6小时。
通过API创建PVC的流程远比创建即时语音克隆复杂,这是因为专业语音克隆更为精密,需要更多数据和精细调校才能生成高质量的克隆效果,通过PVC创建的语音克隆可在Voice Library分享,并在他人使用时获得奖励。目前,只能共享专业语音克隆,即时语音克隆和使用语音设计创建的语音不可共享。
语音变声器(Voice Changer)基于语音转语音技术(Speech-to-Speech),可以在保留情感、语调与演绎风格的前提下,将源语音转换为目标克隆语音的音色。该技术可完美补充文本转语音(TTS)功能,既能修正发音错误,又能注入用户渴望展现的特殊表现力。尤其在模拟声音的微妙特质与独特习惯方面表现卓越,让语音更具情感张力与人性温度。其核心特性包括:
- 精准捕捉气声细节。
- 真实还原声音中叹息、欢笑与哽咽等情感。
- 音调与情绪识别能力显著提升。
- 精准复现原始语速与节奏。
- 完整保留源语言特征与口音特质。
音频数据可通过两种方式上传:直接上传与通过麦克风实时录制。音频文件大小不超过50MB,且时长均不可超过5分钟。若素材超过5分钟,建议将其分段处理并分别生成。若文件体积过大,可考虑压缩或转换为MP3格式。
本项目将ElevenLabs的语音克隆、变声器、文本转录器与Gradio界面结合,在网页实现一个有趣应用:用户可以克隆自己的声音,将别人的声音变成他人或自己的声音,用自己的声音朗读文本。
IVC的代码实现。项目的IVC实现代码如代码11-6所示:
def instant_voice_clone(clone_voice_name, clone_audio_1, clone_audio_2, clone_audio_3, current_choices):
if not (clone_audio_1 and clone_audio_2 and clone_audio_3):
return "Please read the three paragraphs!", gr.update(), gr.update()
if not clone_voice_name:
return "Please input clone voice name!", gr.update(), gr.update()
if clone_voice_name in current_choices:
return "Voice name already exists!", gr.update(), gr.update()
voice = client.voices.ivc.create(name=clone_voice_name,
files=[BytesIO(open(clone_audio_1, "rb").read()),
BytesIO(open(clone_audio_2, "rb").read()),
BytesIO(open(clone_audio_3, "rb").read())])
voice_map[clone_voice_name] = voice.voice_id
new_choices = list(dict.fromkeys(current_choices + [clone_voice_name]))
msg = f"voice id:{voice.voice_id}, voice name:{clone_voice_name}"
return (msg,
gr.update(choices=new_choices, value=clone_voice_name),
gr.update(choices=new_choices, value=clone_voice_name))
函数instant_voice_clone()用于创建即时语音克隆,逻辑如下:
(1)检查输入信息。包括是否提供了所有三个音频文件,是否提供了克隆语音名称和检查语音名称是否已存在。
(2)调用API创建即时语音克隆。将三个音频以二进制方式读取并包装为BytesIO对象,连同语音名称一同传递给client.voices.ivc.create()方法。
(3)存储创建的语音信息。将语音名称和ID保存到voice_map字典中,并将新创建的语音名称添加到当前列表中。其中dict.fromkeys()去重,确保名称唯一。
(4)返回结果。构建并返回成功消息,同时返回两个更新后的Gradio下拉菜单组件(都使用新的语音选项列表,并默认选中新创建的语音)。
文件形式实现语音变声器。项目中的语音变声器实现如代码11-7所示:
def voice_changer(voice_name, audio_path):
if not audio_path:
return None
with open(audio_path, "rb") as f:
audio_bytes = f.read()
voice_id = voice_map.get(voice_name) or "JBFqnCBsd6RMkjVDRZzb"
response = client.speech_to_speech.convert(voice_id=voice_id,
audio=audio_bytes, model_id="eleven_multilingual_sts_v2",
output_format="mp3_44100_128")
save_file_path = f"{uuid.uuid4()}.mp3"
with open(save_file_path, "wb") as f:
for chunk in response:
if chunk:
f.write(chunk)
return save_file_path
voice_changer()函数用于实现语音转换(变声)功能,详细解析如下:
(1)检查并读取音频文件。首先检查是否提供了音频文件,然后以二进制读取模式打开音频文件,将整个文件内容读入audio_bytes变量。
(2)获取目标语音的ID。从voice_map字典中根据语音名称查找对应的语音ID,如果找不到,使用预设的默认语音ID。
(3)调用语音转换API。使用client.speech_to_speech.convert()方法,传入目标语音ID与源音频二进制数据,指定模型ID为 “eleven_multilingual_sts_v2”(多语言语音转换模型),指定输出格式为 “mp3_44100_128”(MP3格式,44.1kHz采样率,128kbps码率),返回一个流式响应(chunked response)。
(4)保存语音为文件。首先生成文件名,使用uuid.uuid4()生成唯一标识符并保存为MP3格式;然后保存转换后的音频,以二进制写入模式打开输出文件,遍历每个数据块并写入文件,以流式处理方式保存大型音频文件;最后返回生成的音频文件路径,后续使用(如播放或下载)。
流式传输的文本转录器。文本转录器通过TTS实现,项目中实现如代码11-8所示:
from typing import IO
def transcribe_text(voice_name, text) -> IO[bytes]:
voice_id = voice_map.get(voice_name) or "pNInz6obpgDQGcFmaJgB" if not text:
return
response = client.text_to_speech.stream(voice_id=voice_id,
output_format="mp3_22050_32", text=text,
model_id="eleven_turbo_v2_5",
# Optional voice settings that allow you to customize the output
voice_settings=VoiceSettings(stability=0.0, similarity_boost=1.0,
style=0.0, use_speaker_boost=True, speed=1.0))
for chunk in response:
if chunk:
yield chunk
函数transcribe_text()用于实现文本到语音的转换(语音合成)。这是一个生成器函数,逐块返回音频数据。他与语音变声器函数实现类似,下面只讲不同点:
(1)调用文本转语音API。使用client.text_to_speech.convert()方法,传入要转换的文本内容并指定使用eleven_turbo_v2_5模型(可实现低延迟的流式传输),添加可选参数VoiceSettings进行语音设置,最后返回的是一个流式响应。
(2)流式返回音频数据。使用yield逐块返回音频数据,每次返回一个音频数据块(chunk),不会一次性加载整个音频文件到内存,适合处理大文本或流式传输。返回的音频数据可以实时播放或保存。
说明:①此处的流式传输实现方式与官方代码稍有不同,都可实现流式传输;②官方实现的流式传输,音频播放效果不尽如人意,在不强制要求流式传输时,可改为文件传输形式;③当使用文件传输时,可使用效果更好的eleven_v3模型。
11.2.2 构建Gradio界面与运行
构建Gradio界面。在设计Gradio界面时,在可折叠框输入ELEVENLABS_API_KEY,创建客户端后便可隐藏。由于要共享VOICE_ID,因此使用三个标签页分别实现语音克隆、语音变声器和文本转录器。后两者代码与语音克隆部分类似,因此只展示语音克隆的Gradio界面代码,如代码11-9所示:
with gr.Blocks() as block:
gr.Markdown("Voice clone by ivc, voice changer with file, text transcriber by stream.")
with gr.Accordion("ElevenLabs Client", open=True):
api_key = gr.Textbox(label="API Key", type="password"
placeholder="Paste your ElevenLabs API key here")
create_client_btn = gr.Button("Create ElevenLabs Client")
client_status = gr.Textbox(label="Client status", interactive=False)
with gr.Tab("Voice Clone"):
gr.HTML("""<h1 style='text-align: center;'> Voice Clone </h1>...""")
with gr.Row():
with gr.Column():
clone_name = gr.Textbox(label="Input name of clone voice",
placeholder="Please enter the name of the cloned voice")
input_text = gr.Textbox(label="Read text",
placeholder="Please read the three paragraphs in the example or record yourself in three paragraphs.")
with gr.Column():
clone_audio_1 = gr.Audio(label="Read the first paragraph:",
sources=["microphone"], type="filepath")
clone_audio_2 = gr.Audio(label="Read the second paragraph:",
sources=["microphone"], type="filepath")
clone_audio_3 = gr.Audio(label="Read the third paragraph:",
sources=["microphone"], type="filepath")
output_text = gr.Textbox(label="Clone voice id and name")
clone_button = gr.Button("Clone")
gr.Examples([["小明 - 明快,清朗,中音", """1. 生活描述。2. 抒情散文。3. 科技资讯。"""],
["John - Bright, Clear, Midrange", """1. Daily Conversation. 2. Inspirational Quote. 3. News Briefing"""]],
example_labels=[["中文训练文本"], ["English training text"]],
inputs=[clone_name, input_text])
...
create_client_btn.click(
fn=creat_elevenlabs_client,
inputs=[api_key],
outputs=[client_status, voice_name, voice_name2],
)
clone_button.click(fn=instant_voice_clone,
inputs=[clone_name, clone_audio_1, clone_audio_2, clone_audio_3, gr.State(voice_list)],
outputs=[output_text, voice_name, voice_name2])
block.launch()
示例是基于Gradio构建的Web界面代码,主要用于ElevenLabs语音克隆功能,用户可以通过录制三段语音样本,快速创建个性化的语音克隆。详细解析如下:
- ElevenLabs客户端配置:输入ElevenLabs的API密钥后,触发客户端创建并显示创建结果,同时自动刷新两个下拉框。
- 语音克隆标签页:左列包括克隆语音名称和需要朗读的参考文本,右列为三个音频录制组件(分别录制三段不同的语音样本),都支持麦克风输入并保存为文件路径。
- 示例数据:提供了包含语音名称和阅读文本的中英文两种示例,每种示例包含三段不同的文本(日常对话、散文、科技资讯),用户点击示例后自动填充到界面中。
- 语音克隆:点击"Clone"按钮触发,输入克隆语音名称、三段音频和当前语音列表状态,克隆成功后输出提示并更新两个下拉框。
程序特点说明:①多步骤流程,先创建客户端,才可以进行语音克隆等其他操作;②状态管理,使用gr.State保存voice_list,方便在各个标签页间共享;③实时更新,语音克隆后,自动更新语音可选下拉框;④用户友好,提供示例和说明文本。
操作说明及运行界面。在安装elevenlabs库并获得ELEVENLABS_API_KEY后,启动应用目录中的app.py,输入正确秘钥并单击创建客户端,如图11-1所示: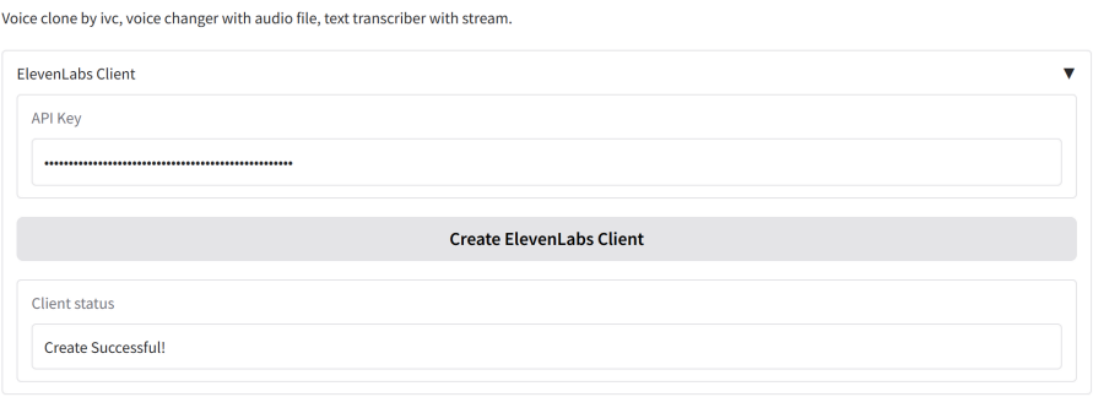
创建客户端成功后,可在语音变声器和文本转录器页面的下拉框中选择10个可用的语音,即使没有充值,也可直接使用语音变声器和文本转录器。但如果希望克隆语音,需要将ElevenLabs账户升级为Creator+。详细操作如下:
(1)克隆语音:首先点击示例中的中文或英文文本,会自动填入语音名称和阅读文本,此时需修改语音名称和简短描述;然后在右边三个语音输入框录制或上传语音文件;最后单击按钮“Clone”,片刻即可看到创建的语音ID和名称,如图11-2所示: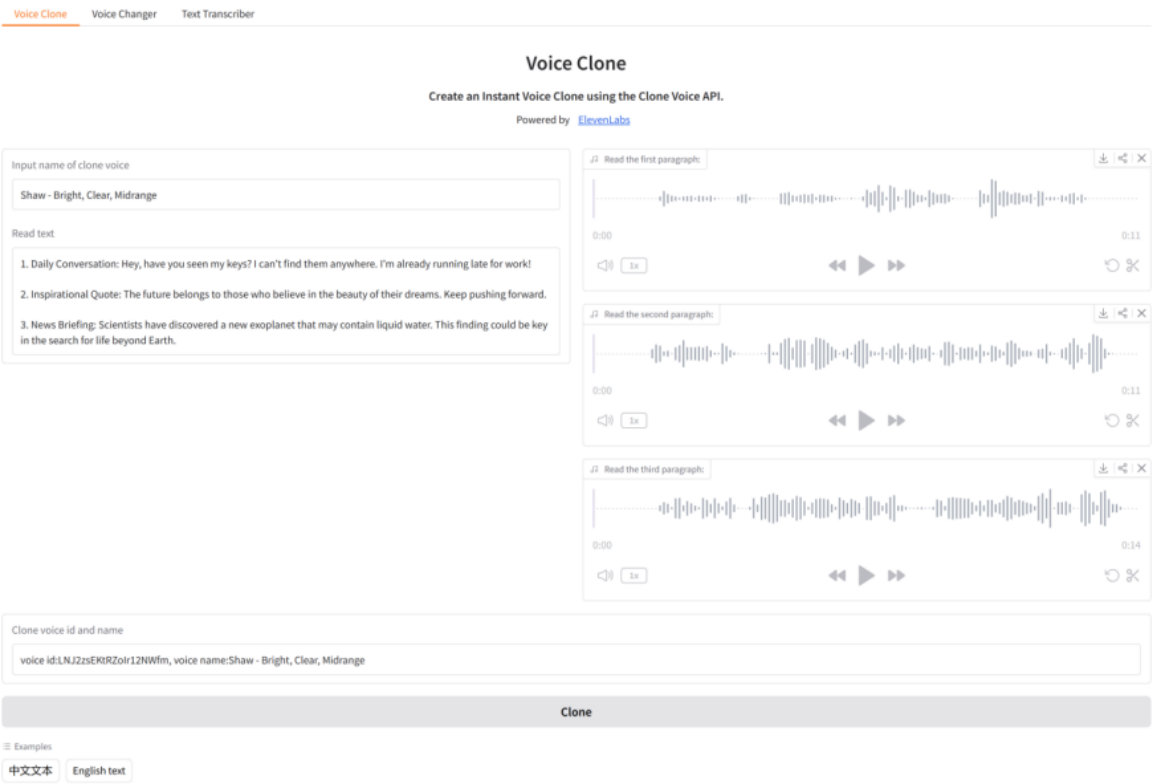
(2)语音变声器:首先选择语音,在克隆语音后,会在下拉框同步显示创建的语音;然后录制或上传语音文件,或使用示例音频文件,时长不超过5分钟且大小不得超过50MB;最后单击按钮“Change”,变声成功后会自动播放,如图11-3所示: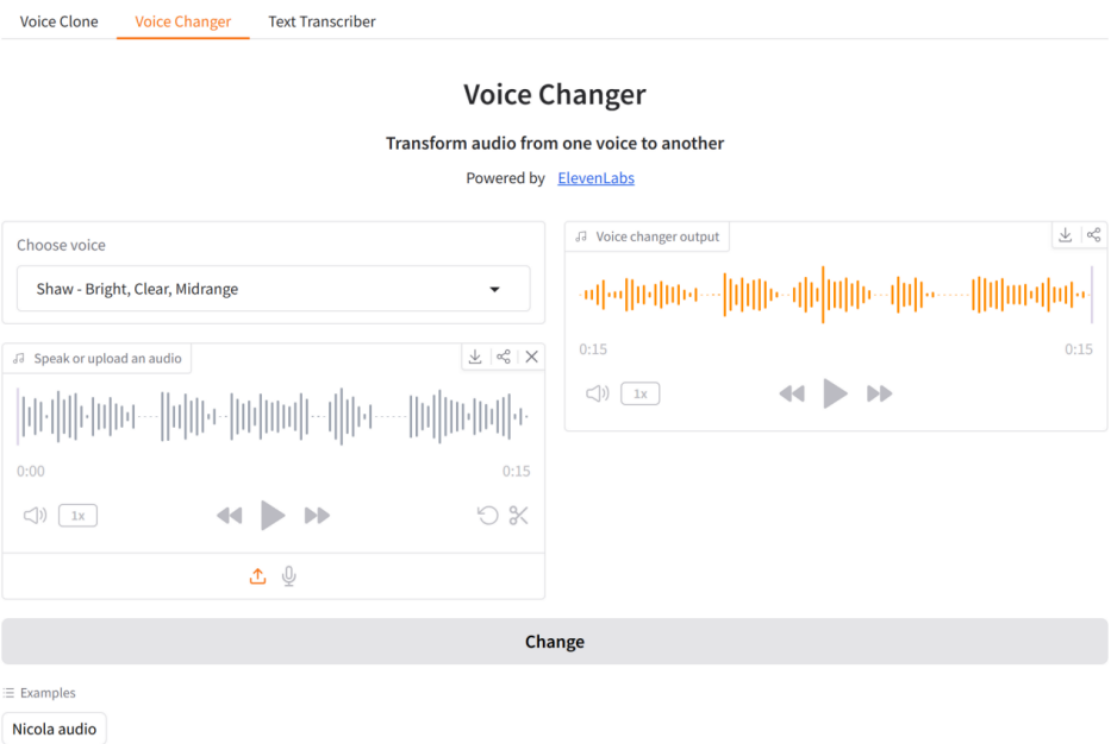
(3)文本转录器:首先选择语音,然后输入一段文本或使用示例中的中英文文本,最后单击“Transcribe”,稍等就可播放转录音频。如图11-4所示: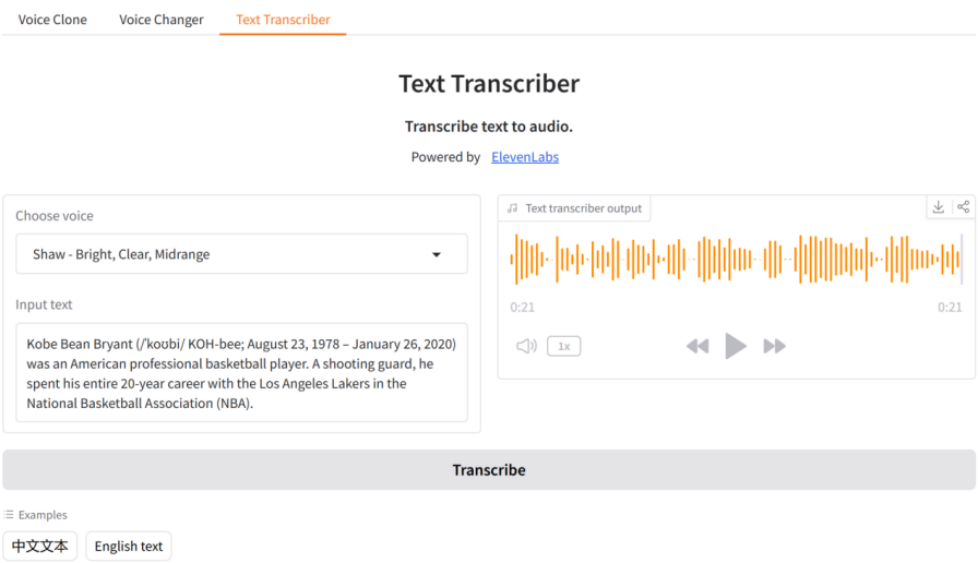
此外,ElevenLabs的产品还有声效(Sound effects)、人声分离器、杜比音效、语音混音等,其应用可结合参考本项目代码与官网资料实现。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)