day17_机器学习概述
写在前面
本篇内容会大致讲解一下机器学习的相关概念类知识,让大家在后续学习相关内容时不至于面对一些词汇感到很陌生。
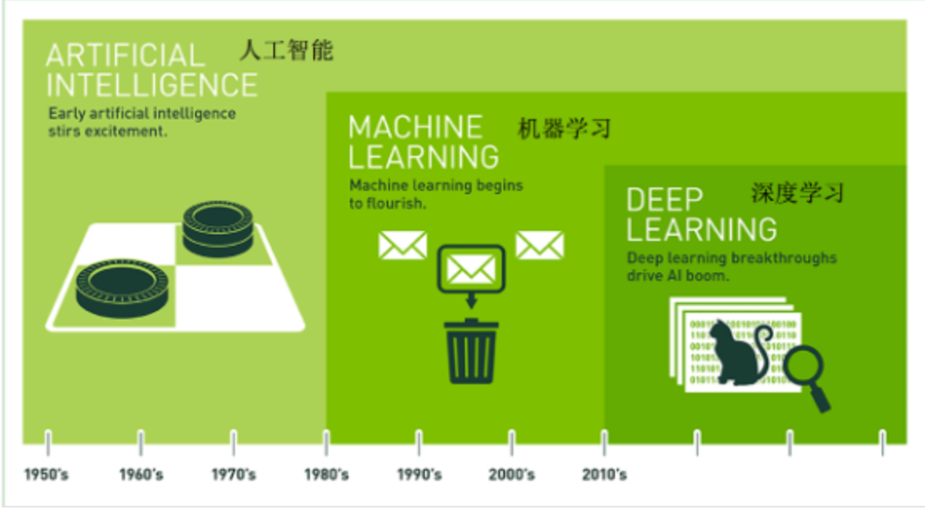
一、人工智能三大概念
- 人工智能(Artificial Intelligence):模仿人的大脑,让计算机像人一样思考、学习、决策与解决问题。
- 机器学习(Machine Learning):让计算机拥有自动学习的能力,无需经过人的显式编程。
- 深度学习(Deep Learning):深度神经网络,大脑仿生,设计多层神经元模拟万事万物。
二、机器学习
我们以这个数据作为我们学习机器学习的示例数据集,我们希望通过这些特征,预测新的用户的月薪。
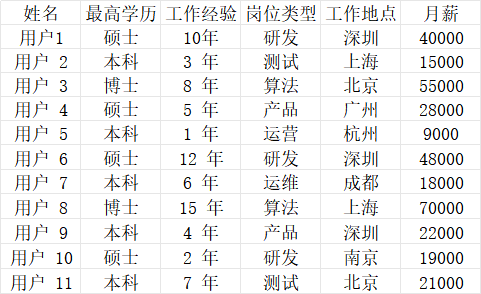
1.常用术语
- 样本(sample):每一行数据,就是一个样本。
- 特征(feature):每一列数据,就是一个特征。
- 标签/目标(label/target):需要预测的数据,在示例中,月薪是需要预测的数据
- 数据集(dataset):分为训练集(training set)与测试集(testing set)。其中训练集用来训练模型,测试集用来测试模型的效果。
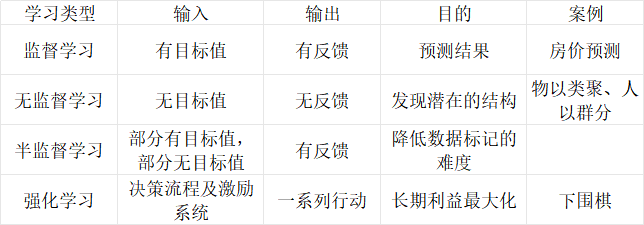
2.算法分类
- 监督学习
输入的数据必须有目标值,根据目标值是否连续,分为两类问题。
(1)分类问题:分类问题的特点是目标值是不连续的分类。比如说下面的案例,我们要预测用户的薪资返回是高、中还是低,这个就不是一个连续的数字,属于一个分类问题。
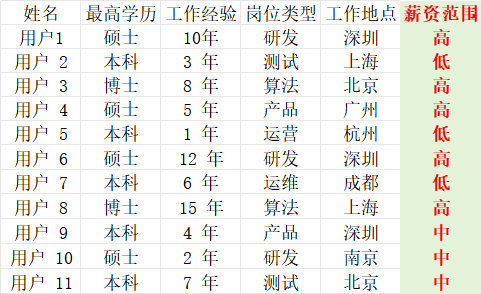
(2)回归问题:回归问题的特点是目标值是连续的数字,比如说我们示例案例中,预测用户的薪资,薪资就是一个连续的数字。
- 无监督学习
无监督学习的特点就是,输入的数据集是没有目标值的。模型根据样本之间的相似性,对样本集进行聚类,以发现事物内部结构与相互关系。
- 半监督学习
半监督学习的特点是,部分样本有目标值,部分样本没有目标值。
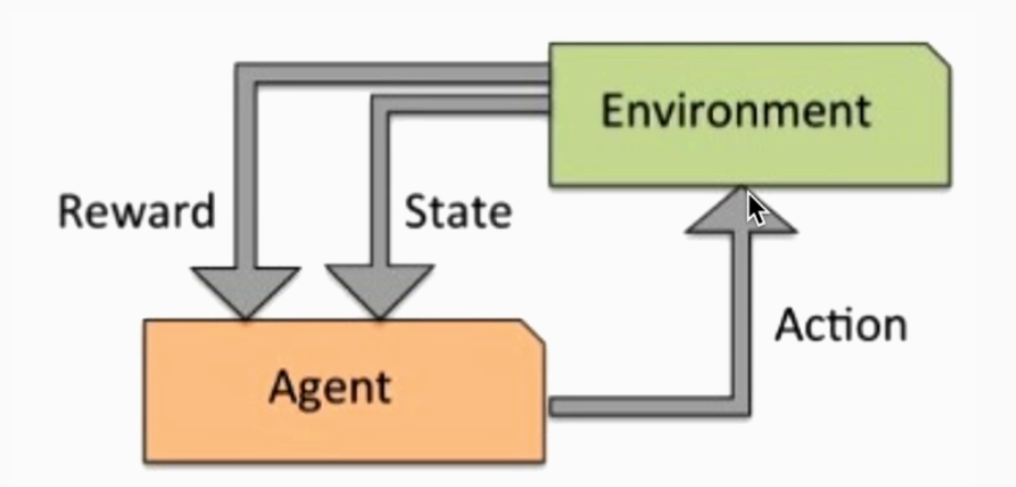
- 强化学习
强化学习主要由四个要素构成,他们分别为Agent、环境状态、行动与奖励。
总的来说,Agent根据环境状态进行行动,以获得最多的累计奖励,这个就是强化学习。
- 总的对比
3.建模流程概述
只介绍概念,不在这一篇细讲
- 获取数据
- 数据预处理
缺失值处理、异常值处理等
- 特征工程
特征提取、特征预处理、特征降维
- 模型训练
线性回归、逻辑回归、决策树、GBDT等
- 模型评估
回归评测指标、分类评测指标、聚类评测指标
三、特征工程概念入门
- 特征提取
从原始数据提取任务所需的相关特征
- 特征预处理
- 特征降维
保证数据的主要信息保留
- 特征选择
选择重要的特征训练
- 特征组合
多个特征合并一个特征
四、模型相关概念
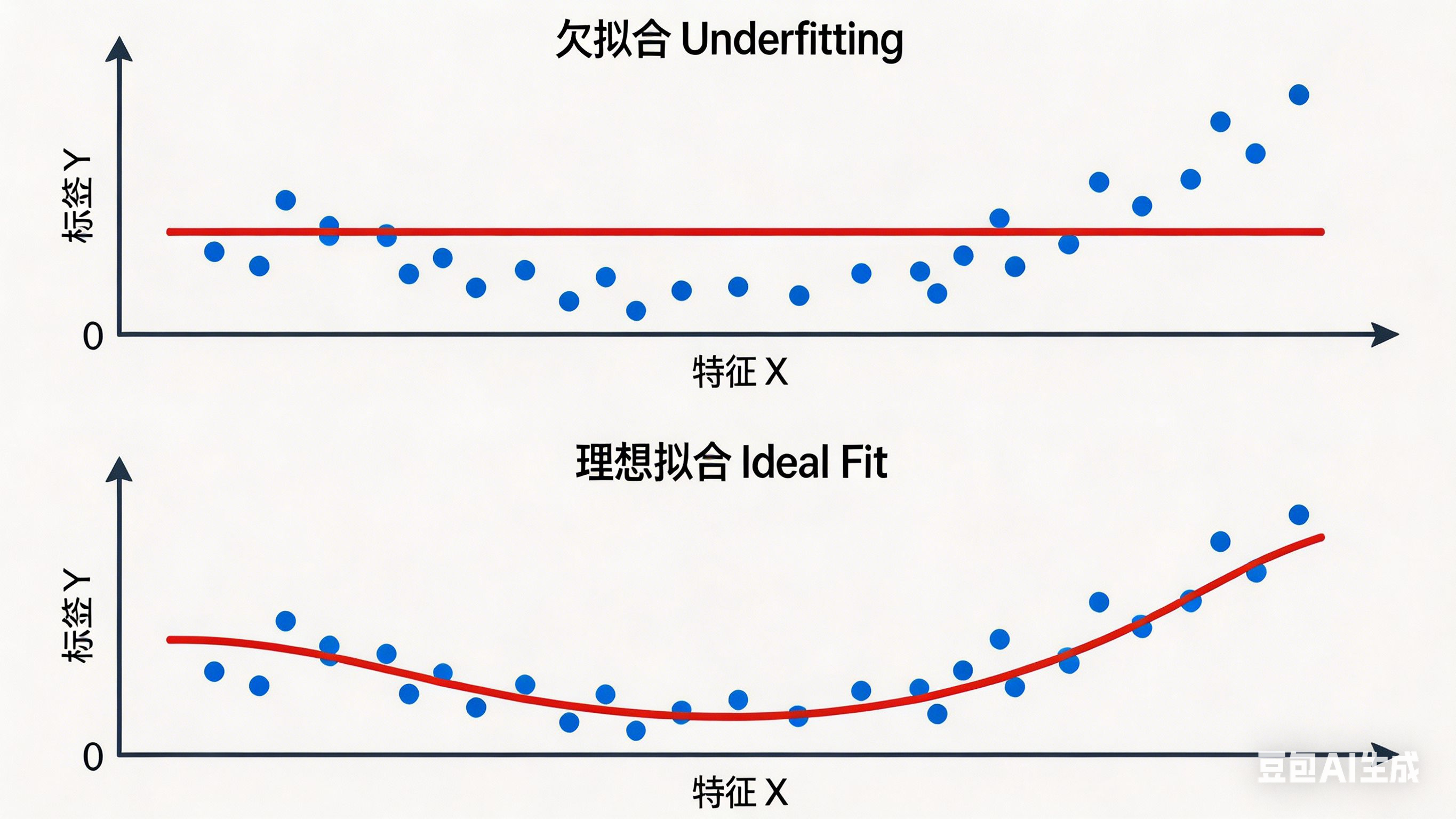
1.模型拟合的几种结果
- 拟合(fitting):用在机器学习领域,用来表示模型对样本点的拟合情况
- 欠拟合(under-fitting)
模型在训练数据集表现差,在测试数据集表现差。潜在的原因可能是模型过于简单。
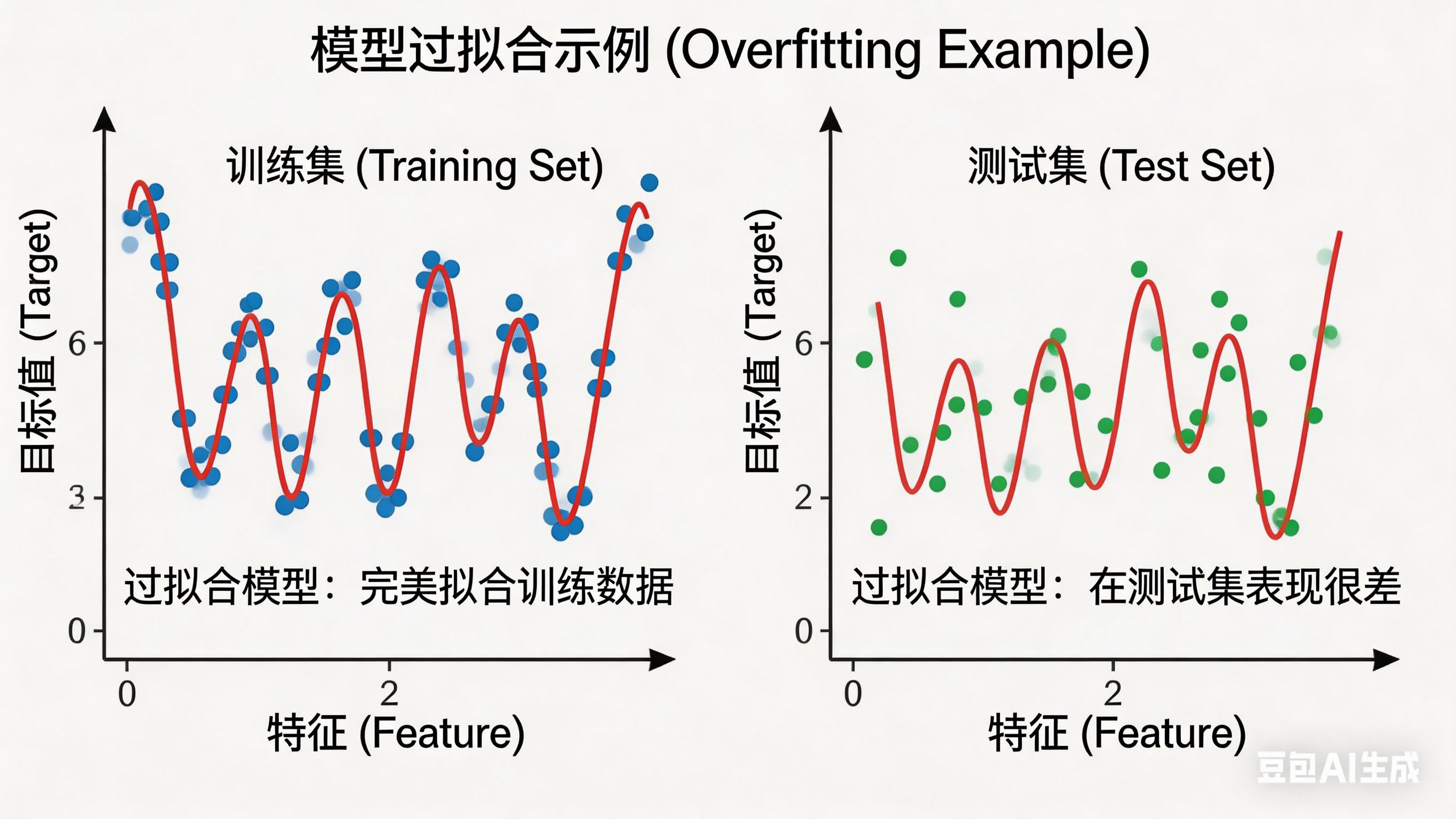
- 过拟合(over-fitting)
模型在训练数据集表现好,在测试数据集表现差。潜在的原因可能是模型过于复杂,数据质量差,训练样本不足等。
2.泛化能力
泛化能力指的就是模型在新数据集(非训练数据)上的表现好坏能力。
如果说一个模型训练好后,面对各类数据输入都能达到一个令人满意的准确率,我们可以说这个模型的泛化能力优秀。
3.奥卡姆剃刀原则
给定两个具有相同泛化误差的模型,此时,较简单的模型比较复杂的模型更可取。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)