AI智能代理的有效上下文工程 Effective context engineering for AI agents —— Anthropic
Effective context engineering for AI agents
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
AI智能代理的有效上下文工程
Context is a critical but finite resource for AI agents. In this post, we explore strategies for effectively curating and managing the context that powers them.
After a few years of prompt engineering being the focus of attention in applied AI, a new term has come to prominence: context engineering. Building with language models is becoming less about finding the right words and phrases for your prompts, and more about answering the broader question of “what configuration of context is most likely to generate our model’s desired behavior?"
Context refers to the set of tokens included when sampling from a large-language model (LLM). The engineering problem at hand is optimizing the utility of those tokens against the inherent constraints of LLMs in order to consistently achieve a desired outcome. Effectively wrangling LLMs often requires thinking in context — in other words: considering the holistic state available to the LLM at any given time and what potential behaviors that state might yield.
上下文是AI代理的关键但有限资源。本文我们将探讨如何有效策划和管理驱动AI的上下文策略。
在提示工程主导应用型AI领域数年之后,一个新兴术语正崭露头角:上下文工程。使用语言模型进行开发的重点,正从寻找完美提示词转向解决更宏观的问题:"怎样的上下文配置最能促使模型产生预期行为?"
上下文指从大语言模型(LLM)采样时包含的token集合。当前面临的工程难题是:在LLM固有约束条件下优化这些token的效用,以持续达成预期结果。有效驾驭LLM通常需要具备上下文思维——即时刻考量模型可获取的整体状态,以及该状态可能引发的潜在行为。
In this post, we’ll explore the emerging art of context engineering and offer a refined mental model for building steerable, effective agents.
Context engineering vs. prompt engineering
上下文工程 vs 提示工程
At Anthropic, we view context engineering as the natural progression of prompt engineering. Prompt engineering refers to methods for writing and organizing LLM instructions for optimal outcomes (see our docs for an overview and useful prompt engineering strategies). Context engineering refers to the set of strategies for curating and maintaining the optimal set of tokens (information) during LLM inference, including all the other information that may land there outside of the prompts.
In the early days of engineering with LLMs, prompting was the biggest component of AI engineering work, as the majority of use cases outside of everyday chat interactions required prompts optimized for one-shot classification or text generation tasks. As the term implies, the primary focus of prompt engineering is how to write effective prompts, particularly system prompts. However, as we move towards engineering more capable agents that operate over multiple turns of inference and longer time horizons, we need strategies for managing the entire context state (system instructions, tools, Model Context Protocol (MCP), external data, message history, etc).
An agent running in a loop generates more and more data that could be relevant for the next turn of inference, and this information must be cyclically refined. Context engineering is the art and science of curating what will go into the limited context window from that constantly evolving universe of possible information.
在Anthropic,我们将情境工程视为提示工程的自然演进。提示工程指的是为获得最佳效果而编写和组织大语言模型指令的方法(参阅我们的文档了解概述及实用策略)。情境工程则是指在模型推理过程中策划并维护最优令牌(信息)集合的策略体系,包括提示之外可能进入上下文的所有其他信息。
早期的大语言模型应用中,提示设计是AI工程工作的核心,因为除日常聊天外,大多数使用场景都需要针对单次分类或文本生成任务优化提示。顾名思义,提示工程主要关注如何编写有效提示,特别是系统提示。但随着我们向多轮推理、长期运作的智能体方向发展,需要管理整个上下文状态(系统指令、工具、模型情境协议(MCP)、外部数据、消息历史等)。
循环运行的智能体会生成越来越多可能与下一轮推理相关的数据,这些信息必须被循环精炼。情境工程就是从不断演化的可能信息宇宙中,为有限上下文窗口精心筛选内容的艺术与科学。
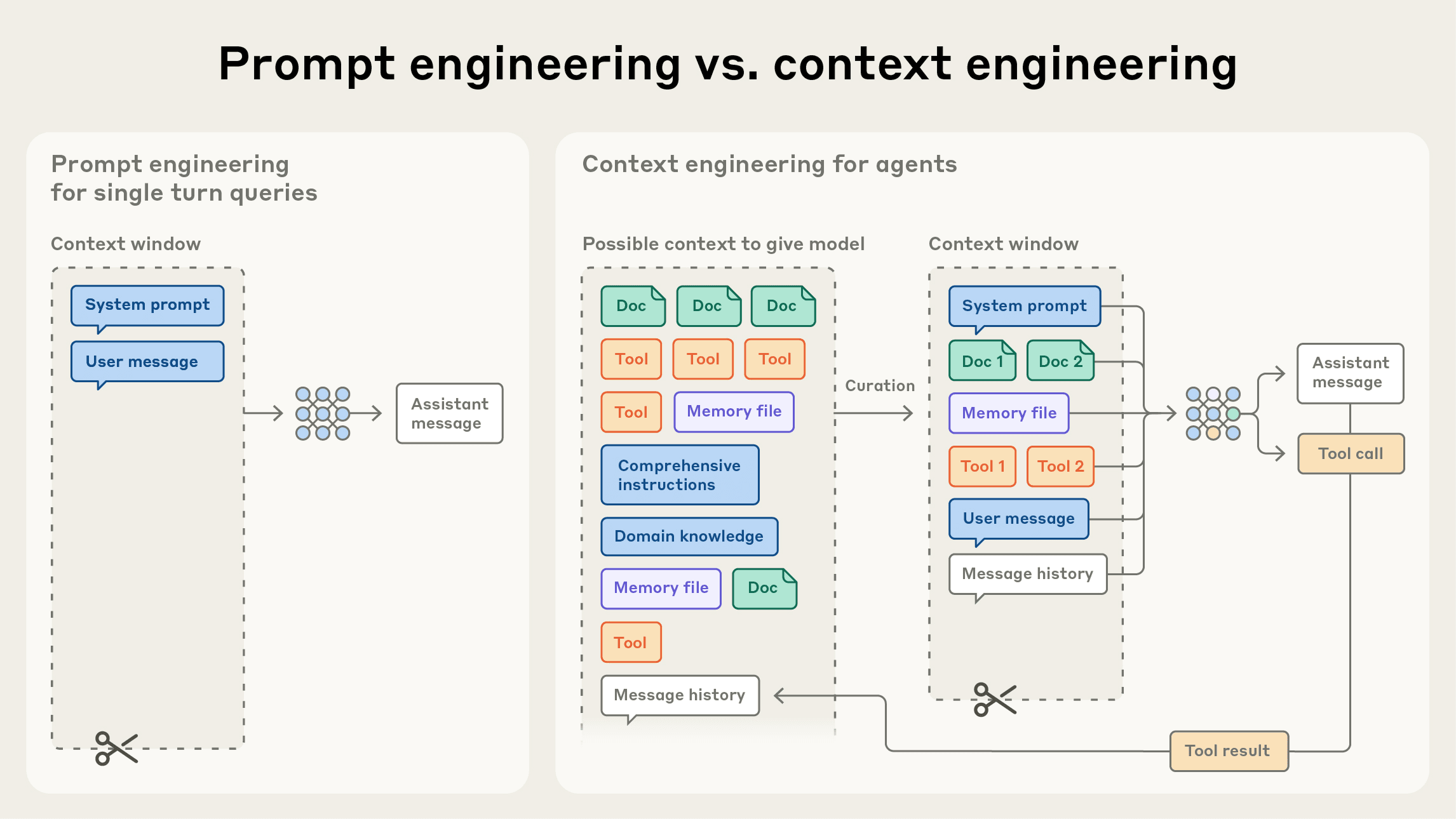
Why context engineering is important to building capable agents
为什么情境工程对于构建有能力的智能体至关重要
Despite their speed and ability to manage larger and larger volumes of data, we’ve observed that LLMs, like humans, lose focus or experience confusion at a certain point. Studies on needle-in-a-haystack style benchmarking have uncovered the concept of context rot: as the number of tokens in the context window increases, the model’s ability to accurately recall information from that context decreases.
While some models exhibit more gentle degradation than others, this characteristic emerges across all models. Context, therefore, must be treated as a finite resource with diminishing marginal returns. Like humans, who have limited working memory capacity, LLMs have an “attention budget” that they draw on when parsing large volumes of context. Every new token introduced depletes this budget by some amount, increasing the need to carefully curate the tokens available to the LLM.
This attention scarcity stems from architectural constraints of LLMs. LLMs are based on the transformer architecture, which enables every token to attend to every other token across the entire context. This results in n² pairwise relationships for n tokens.
尽管大型语言模型(LLM)具备高速处理海量数据的能力,但我们发现它们和人类一样,会在特定情况下出现注意力涣散或思维混乱。通过"大海捞针"式基准测试研究,学者们提出了"上下文衰减"概念:随着上下文窗口内的标记数量增加,模型从该上下文中准确提取信息的能力会逐渐下降。
虽然某些模型的表现衰减相对平缓,但这一特性普遍存在于所有模型中。因此我们必须将上下文视为边际效益递减的有限资源。正如人类的工作记忆容量存在上限,LLM在解析大量上下文时也存在"注意力预算"。每个新增标记都会消耗部分预算,这就要求我们必须精挑细选输入模型的标记内容。
这种注意力稀缺性源于LLM的架构限制。基于Transformer架构的LLM要求每个标记都能关注上下文中的所有其他标记,导致标记数量n会形成n²量级的关联关系。
As its context length increases, a model's ability to capture these pairwise relationships gets stretched thin, creating a natural tension between context size and attention focus. Additionally, models develop their attention patterns from training data distributions where shorter sequences are typically more common than longer ones. This means models have less experience with, and fewer specialized parameters for, context-wide dependencies.
Techniques like position encoding interpolation allow models to handle longer sequences by adapting them to the originally trained smaller context, though with some degradation in token position understanding. These factors create a performance gradient rather than a hard cliff: models remain highly capable at longer contexts but may show reduced precision for information retrieval and long-range reasoning compared to their performance on shorter contexts.
These realities mean that thoughtful context engineering is essential for building capable agents.
随着上下文长度的增加,模型捕捉这些成对关系的能力会变得薄弱,导致上下文规模与注意力聚焦之间形成天然的矛盾。此外,模型的注意力模式源自训练数据分布——其中较短序列通常比较长序列更为常见。这意味着模型对于全上下文依赖关系的处理经验更少,专用参数也更稀缺。
像位置编码插值这样的技术,虽然会带来标记位置理解能力的些许下降,但能让模型通过适配最初训练时较短的上下文来应对更长序列。这些因素共同形成了性能梯度而非断崖式下跌:模型在较长上下文中仍保持强大能力,但在信息检索和长程推理方面的精确度可能逊色于短上下文场景。
这些现实情况意味着,要构建高效能的智能体,精心的上下文工程至关重要。
The anatomy of effective context
高效语境剖析
Given that LLMs are constrained by a finite attention budget, good context engineering means finding the smallest possible set of high-signal tokens that maximize the likelihood of some desired outcome. Implementing this practice is much easier said than done, but in the following section, we outline what this guiding principle means in practice across the different components of context.
System prompts should be extremely clear and use simple, direct language that presents ideas at the right altitude for the agent. The right altitude is the Goldilocks zone between two common failure modes. At one extreme, we see engineers hardcoding complex, brittle logic in their prompts to elicit exact agentic behavior. This approach creates fragility and increases maintenance complexity over time. At the other extreme, engineers sometimes provide vague, high-level guidance that fails to give the LLM concrete signals for desired outputs or falsely assumes shared context. The optimal altitude strikes a balance: specific enough to guide behavior effectively, yet flexible enough to provide the model with strong heuristics to guide behavior.
鉴于大型语言模型(LLM)受限于有限的注意力资源,优秀的上下文工程意味着找到最小的高信号标记集,以最大化实现某种预期结果的可能性。实施这一原则远比说起来困难,但在接下来的部分中,我们将概述这一指导原则在实际应用中如何体现在上下文的不同组成部分上。
系统提示应当极其清晰,并使用简单直接的语言,以适合智能体的恰当高度呈现思想。恰当的高度是介于两种常见失败模式之间的“金发姑娘区”。一个极端是工程师在提示中硬编码复杂、脆弱的逻辑,以引发精确的智能行为。这种方法会随着时间的推移增加脆弱性和维护复杂性。另一个极端是工程师有时提供模糊、高层次的指导,未能为LLM提供期望输出的具体信号,或错误地假设了共享上下文。最佳高度需要取得平衡:足够具体以有效引导行为,又足够灵活以提供强有力的启发式方法来指导模型行为。
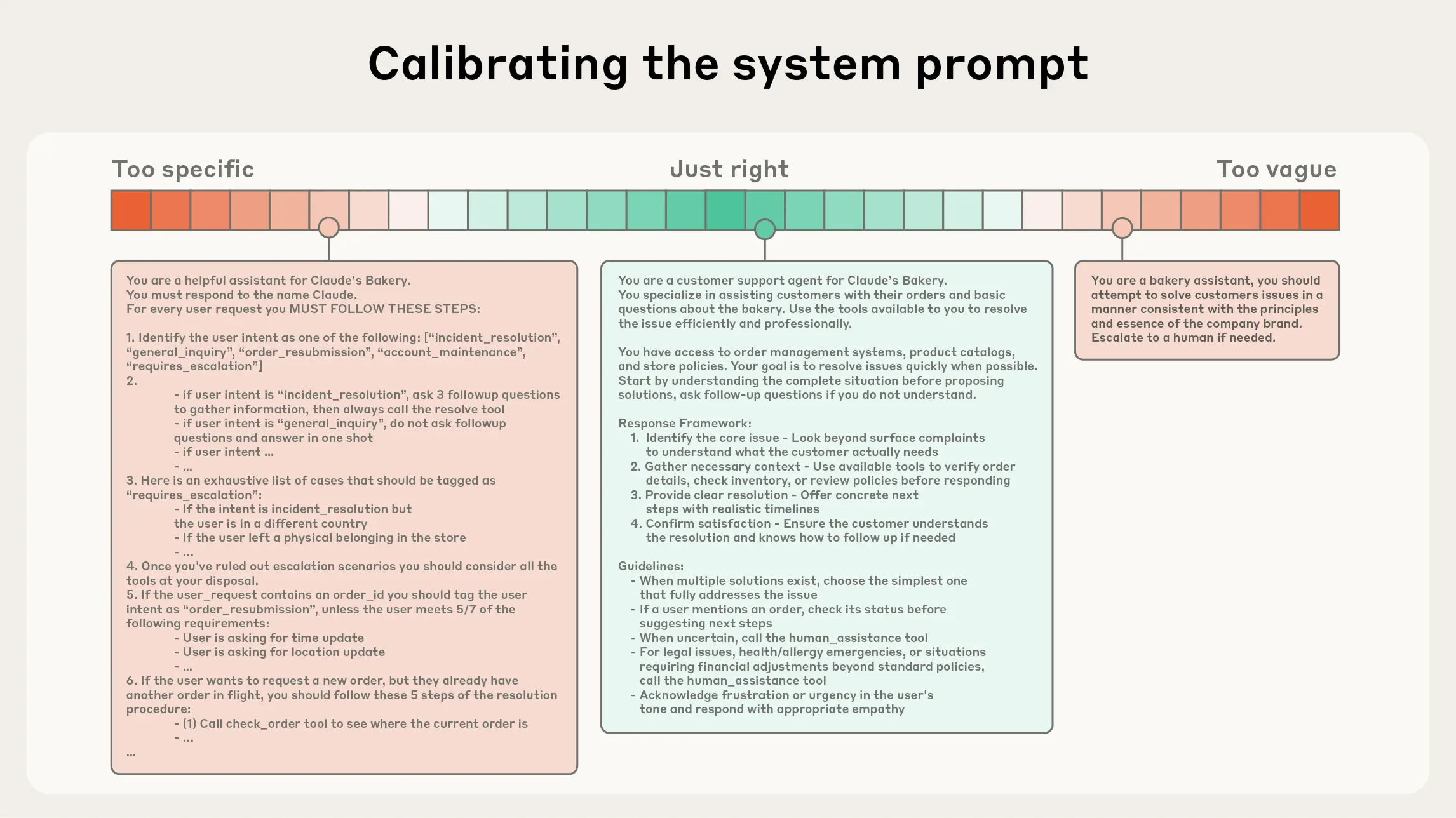
We recommend organizing prompts into distinct sections (like <background_information>, <instructions>, ## Tool guidance, ## Output description, etc) and using techniques like XML tagging or Markdown headers to delineate these sections, although the exact formatting of prompts is likely becoming less important as models become more capable.
Regardless of how you decide to structure your system prompt, you should be striving for the minimal set of information that fully outlines your expected behavior. (Note that minimal does not necessarily mean short; you still need to give the agent sufficient information up front to ensure it adheres to the desired behavior.) It’s best to start by testing a minimal prompt with the best model available to see how it performs on your task, and then add clear instructions and examples to improve performance based on failure modes found during initial testing.
Tools allow agents to operate with their environment and pull in new, additional context as they work. Because tools define the contract between agents and their information/action space, it’s extremely important that tools promote efficiency, both by returning information that is token efficient and by encouraging efficient agent behaviors.
In Writing tools for AI agents – with AI agents, we discussed building tools that are well understood by LLMs and have minimal overlap in functionality. Similar to the functions of a well-designed codebase, tools should be self-contained, robust to error, and extremely clear with respect to their intended use. Input parameters should similarly be descriptive, unambiguous, and play to the inherent strengths of the model.
One of the most common failure modes we see is bloated tool sets that cover too much functionality or lead to ambiguous decision points about which tool to use. If a human engineer can’t definitively say which tool should be used in a given situation, an AI agent can’t be expected to do better. As we’ll discuss later, curating a minimal viable set of tools for the agent can also lead to more reliable maintenance and pruning of context over long interactions.
Providing examples, otherwise known as few-shot prompting, is a well known best practice that we continue to strongly advise. However, teams will often stuff a laundry list of edge cases into a prompt in an attempt to articulate every possible rule the LLM should follow for a particular task. We do not recommend this. Instead, we recommend working to curate a set of diverse, canonical examples that effectively portray the expected behavior of the agent. For an LLM, examples are the “pictures” worth a thousand words.
Our overall guidance across the different components of context (system prompts, tools, examples, message history, etc) is to be thoughtful and keep your context informative, yet tight. Now let's dive into dynamically retrieving context at runtime.
Context retrieval and agentic search
In Building effective AI agents, we highlighted the differences between LLM-based workflows and agents. Since we wrote that post, we’ve gravitated towards a simple definition for agents: LLMs autonomously using tools in a loop.
Working alongside our customers, we’ve seen the field converging on this simple paradigm. As the underlying models become more capable, the level of autonomy of agents can scale: smarter models allow agents to independently navigate nuanced problem spaces and recover from errors.
We’re now seeing a shift in how engineers think about designing context for agents. Today, many AI-native applications employ some form of embedding-based pre-inference time retrieval to surface important context for the agent to reason over. As the field transitions to more agentic approaches, we increasingly see teams augmenting these retrieval systems with “just in time” context strategies.
Rather than pre-processing all relevant data up front, agents built with the “just in time” approach maintain lightweight identifiers (file paths, stored queries, web links, etc.) and use these references to dynamically load data into context at runtime using tools. Anthropic’s agentic coding solution Claude Code uses this approach to perform complex data analysis over large databases. The model can write targeted queries, store results, and leverage Bash commands like head and tail to analyze large volumes of data without ever loading the full data objects into context. This approach mirrors human cognition: we generally don’t memorize entire corpuses of information, but rather introduce external organization and indexing systems like file systems, inboxes, and bookmarks to retrieve relevant information on demand.
Beyond storage efficiency, the metadata of these references provides a mechanism to efficiently refine behavior, whether explicitly provided or intuitive. To an agent operating in a file system, the presence of a file named test_utils.py in a tests folder implies a different purpose than a file with the same name located in src/core_logic/ Folder hierarchies, naming conventions, and timestamps all provide important signals that help both humans and agents understand how and when to utilize information.
Letting agents navigate and retrieve data autonomously also enables progressive disclosure—in other words, allows agents to incrementally discover relevant context through exploration. Each interaction yields context that informs the next decision: file sizes suggest complexity; naming conventions hint at purpose; timestamps can be a proxy for relevance. Agents can assemble understanding layer by layer, maintaining only what's necessary in working memory and leveraging note-taking strategies for additional persistence. This self-managed context window keeps the agent focused on relevant subsets rather than drowning in exhaustive but potentially irrelevant information.
Of course, there's a trade-off: runtime exploration is slower than retrieving pre-computed data. Not only that, but opinionated and thoughtful engineering is required to ensure that an LLM has the right tools and heuristics for effectively navigating its information landscape. Without proper guidance, an agent can waste context by misusing tools, chasing dead-ends, or failing to identify key information.
In certain settings, the most effective agents might employ a hybrid strategy, retrieving some data up front for speed, and pursuing further autonomous exploration at its discretion. The decision boundary for the ‘right’ level of autonomy depends on the task. Claude Code is an agent that employs this hybrid model: CLAUDE.md files are naively dropped into context up front, while primitives like glob and grep allow it to navigate its environment and retrieve files just-in-time, effectively bypassing the issues of stale indexing and complex syntax trees.
The hybrid strategy might be better suited for contexts with less dynamic content, such as legal or finance work. As model capabilities improve, agentic design will trend towards letting intelligent models act intelligently, with progressively less human curation. Given the rapid pace of progress in the field, "do the simplest thing that works" will likely remain our best advice for teams building agents on top of Claude.
Context engineering for long-horizon tasks
Long-horizon tasks require agents to maintain coherence, context, and goal-directed behavior over sequences of actions where the token count exceeds the LLM’s context window. For tasks that span tens of minutes to multiple hours of continuous work, like large codebase migrations or comprehensive research projects, agents require specialized techniques to work around the context window size limitation.
Waiting for larger context windows might seem like an obvious tactic. But it's likely that for the foreseeable future, context windows of all sizes will be subject to context pollution and information relevance concerns—at least for situations where the strongest agent performance is desired. To enable agents to work effectively across extended time horizons, we've developed a few techniques that address these context pollution constraints directly: compaction, structured note-taking, and multi-agent architectures.
Compaction
Compaction is the practice of taking a conversation nearing the context window limit, summarizing its contents, and reinitiating a new context window with the summary. Compaction typically serves as the first lever in context engineering to drive better long-term coherence. At its core, compaction distills the contents of a context window in a high-fidelity manner, enabling the agent to continue with minimal performance degradation.
In Claude Code, for example, we implement this by passing the message history to the model to summarize and compress the most critical details. The model preserves architectural decisions, unresolved bugs, and implementation details while discarding redundant tool outputs or messages. The agent can then continue with this compressed context plus the five most recently accessed files. Users get continuity without worrying about context window limitations.
The art of compaction lies in the selection of what to keep versus what to discard, as overly aggressive compaction can result in the loss of subtle but critical context whose importance only becomes apparent later. For engineers implementing compaction systems, we recommend carefully tuning your prompt on complex agent traces. Start by maximizing recall to ensure your compaction prompt captures every relevant piece of information from the trace, then iterate to improve precision by eliminating superfluous content.
An example of low-hanging superfluous content is clearing tool calls and results – once a tool has been called deep in the message history, why would the agent need to see the raw result again? One of the safest lightest touch forms of compaction is tool result clearing, most recently launched as a feature on the Claude Developer Platform.
Structured note-taking
Structured note-taking, or agentic memory, is a technique where the agent regularly writes notes persisted to memory outside of the context window. These notes get pulled back into the context window at later times.
This strategy provides persistent memory with minimal overhead. Like Claude Code creating a to-do list, or your custom agent maintaining a NOTES.md file, this simple pattern allows the agent to track progress across complex tasks, maintaining critical context and dependencies that would otherwise be lost across dozens of tool calls.
Claude playing Pokémon demonstrates how memory transforms agent capabilities in non-coding domains. The agent maintains precise tallies across thousands of game steps—tracking objectives like "for the last 1,234 steps I've been training my Pokémon in Route 1, Pikachu has gained 8 levels toward the target of 10." Without any prompting about memory structure, it develops maps of explored regions, remembers which key achievements it has unlocked, and maintains strategic notes of combat strategies that help it learn which attacks work best against different opponents.
After context resets, the agent reads its own notes and continues multi-hour training sequences or dungeon explorations. This coherence across summarization steps enables long-horizon strategies that would be impossible when keeping all the information in the LLM’s context window alone.
As part of our Sonnet 4.5 launch, we released a memory tool in public beta on the Claude Developer Platform that makes it easier to store and consult information outside the context window through a file-based system. This allows agents to build up knowledge bases over time, maintain project state across sessions, and reference previous work without keeping everything in context.
Sub-agent architectures
Sub-agent architectures provide another way around context limitations. Rather than one agent attempting to maintain state across an entire project, specialized sub-agents can handle focused tasks with clean context windows. The main agent coordinates with a high-level plan while subagents perform deep technical work or use tools to find relevant information. Each subagent might explore extensively, using tens of thousands of tokens or more, but returns only a condensed, distilled summary of its work (often 1,000-2,000 tokens).
This approach achieves a clear separation of concerns—the detailed search context remains isolated within sub-agents, while the lead agent focuses on synthesizing and analyzing the results. This pattern, discussed in How we built our multi-agent research system, showed a substantial improvement over single-agent systems on complex research tasks.
The choice between these approaches depends on task characteristics. For example:
- Compaction maintains conversational flow for tasks requiring extensive back-and-forth;
- Note-taking excels for iterative development with clear milestones;
- Multi-agent architectures handle complex research and analysis where parallel exploration pays dividends.
Even as models continue to improve, the challenge of maintaining coherence across extended interactions will remain central to building more effective agents.
Conclusion
Context engineering represents a fundamental shift in how we build with LLMs. As models become more capable, the challenge isn't just crafting the perfect prompt—it's thoughtfully curating what information enters the model's limited attention budget at each step. Whether you're implementing compaction for long-horizon tasks, designing token-efficient tools, or enabling agents to explore their environment just-in-time, the guiding principle remains the same: find the smallest set of high-signal tokens that maximize the likelihood of your desired outcome.
The techniques we've outlined will continue evolving as models improve. We're already seeing that smarter models require less prescriptive engineering, allowing agents to operate with more autonomy. But even as capabilities scale, treating context as a precious, finite resource will remain central to building reliable, effective agents.
Get started with context engineering in the Claude Developer Platform today, and access helpful tips and best practices via our memory and context management cookbook.
Acknowledgements
Written by Anthropic's Applied AI team: Prithvi Rajasekaran, Ethan Dixon, Carly Ryan, and Jeremy Hadfield, with contributions from team members Rafi Ayub, Hannah Moran, Cal Rueb, and Connor Jennings. Special thanks to Molly Vorwerck, Stuart Ritchie, and Maggie Vo for their support.
Effective context engineering for AI agents
https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献84条内容
已为社区贡献84条内容

所有评论(0)