ICLR 2026|告别“刷题”陷阱,MathForge双轨框架让大模型专攻难题,数学推理飙升4.5%
ICLR 2026|告别“刷题”陷阱,MathForge双轨框架让大模型专攻难题,数学推理飙升4.5%
刷了上万道题,模型却在真正难啃的骨头上频频翻车。这就像是个疯狂刷驾考题库的学员,倒车入库练得滚瓜烂熟,一上路遇到个斜车位就彻底懵了。大模型的数学推理训练,正陷入同样的陷阱。
当前主流方案GRPO,其运作逻辑是在同一道题生成的多个答案间做相对比较,谁好谁坏,一目了然,然后据此调整模型参数。听起来很合理,但这里有个隐秘的bug。论文通过理论分析揭示,GRPO的更新强度天然更偏向中等难度题。对于太简单的题,模型每次都能答对,组内答案差异极小,算法觉得“没啥可学的”,更新信号微弱;对于极难的题,模型每次都错得离谱,答案五花八门却全无正确样本,算法同样陷入迷茫,信号混乱。
真正最有训练价值的,是那些**“难而可学”的题目**——模型有时能做对,有时会做错,恰好暴露了能力的边界。但在GRPO的机制下,这类题得到的训练信号反而被压低。模型最该花精力去攻克的那部分短板,就这样被算法“悄无声息”地忽略了。
算法层面的“偏食”已经够糟,数据层面的“惰性”更是雪上加霜。常见的数学推理数据增强,要么是从头生成新题,要么是对原题做简单重述。前者在生成高难度竞赛题时,答案正确性很难保证,容易引入错误信号;后者虽然增加了题目表述的多样性,但换汤不换药,内在的推理难度几乎原地踏步。
把“小明有3个苹果”改成“小明拥有3个水果,这些水果是苹果”,这能提升什么推理能力?这种浅层重述,只是让模型习惯了同一逻辑的不同表面表达,却从未触及真正的挑战。模型看似在“刷题”,实则是在舒适区里反复横跳。当它面对一个需要更深层推理、更复杂链条的变体时,立刻就原形毕露。真正能逼出模型潜力的,不是更多的题,而是更难、但答案依然可靠的题。
二、 双轨锻造:MathForge如何从算法与数据两端“围剿”难题?

如果只把问题归结为“难题练得少”,解决方案很容易滑向简单的加权采样。但MathForge团队发现,问题远比这更隐蔽——算法本身就在系统性地压制难题的训练信号。因此,MathForge的应对策略也分成了两条清晰的路径:DGPO负责修正“怎么学”的偏差,MQR负责解决“学什么”的瓶颈。这不是修修补补,而是对训练逻辑的一次系统性重构。
算法重塑:DGPO的平衡与重加权策略,如何让“难而可学”样本获得最高训练权重
GRPO的一个反直觉缺陷,在此被理论分析彻底揭示:不同难度题目的更新强度天然失衡,中等难度题占据最大更新幅度,而真正需要大量训练的难题,反而因为组内回答方差小,获得的梯度信号微弱。
DGPO的修正分两步走,逻辑精准。
第一步是DGAE,负责“拉平”。 它用平均绝对偏差(MAD)替代GRPO的标准差归一化。论文定理证明,在不依赖二值正确性奖励的情况下,DGAE能让每道题的更新幅度趋于相等。难题不再因方差小而被边缘化,简单题也不再占据过多训练预算。所有题目在更新强度上被拉到同一起跑线。
第二步是DQW,负责“重加权”。 更新幅度平衡后,DQW根据题目的平均正确率估算难度,对正确率低但并非完全无法答对的题目赋予更高权重。这正是“难而可学”样本的精准定义——它们恰好处于模型能力的边界地带,每一次有效学习都能带来最大幅度的能力跃升。
核心洞察:DGPO不是简单“给难题更高权重”,而是先修正GRPO内在的更新偏差,再按难度重新分配资源。DGAE和DQW是互补关系,缺一不可——只加权不拉平,难题仍被算法压制;只拉平不加权,则无法聚焦最有价值的样本。
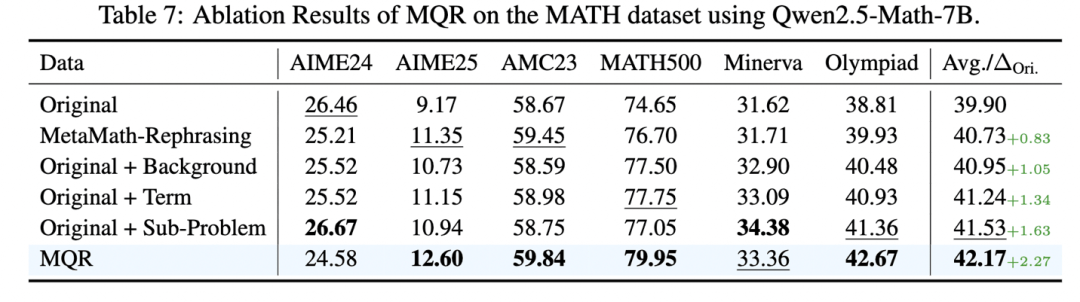
数据深改:从背景干扰到子问题拆解,MQR如何系统化地“制造”高价值难题
DGPO解决了“怎么学”,MQR回答的是“学什么”。传统浅层重述只是换了个说法,题目本质难度不变——这解释了为何单纯增加数据量收效甚微。MQR从三个维度系统性地提升题目难度,同时严格保持原始标准答案不变,这是其设计上的关键约束。
Background策略注入看似相关实则干扰的背景信息,迫使模型在复杂叙述中剥离冗余、抓住真正的数学条件,考验信息筛选能力。
Term策略引入新的抽象术语替代核心概念,模型不能只靠熟悉的表面表达作答,必须真正理解定义和结构,这逼迫模型进行深层语义理解而非模式匹配。
Sub-Problem策略把原题中的关键数值条件改造为需先独立求解的小问题,直接拉长推理链条。实验数据显示,这种改写对推理难度的提升最为显著。
三种策略组合使用效果最优,且改写后的数据在控制总训练量后依然优于原始数据。这意味着MQR真正创造出了更高价值的训练样本,而非简单的数据堆砌。
三、 性能跃迁:专攻难题的训练范式,带来了怎样的质变与启示?
如果仅把 MathForge 理解为“多刷难题”,就完全低估了它的价值。它真正的贡献,在于揭示了一条反直觉的规律:训练时承受的“认知压力”越大,测试时展现的“推理韧性”越强。 这不是简单的分数堆砌,而是模型底层推理机制的重塑。
全面提分:超4.5%的平均性能提升与跨模型普适性验证
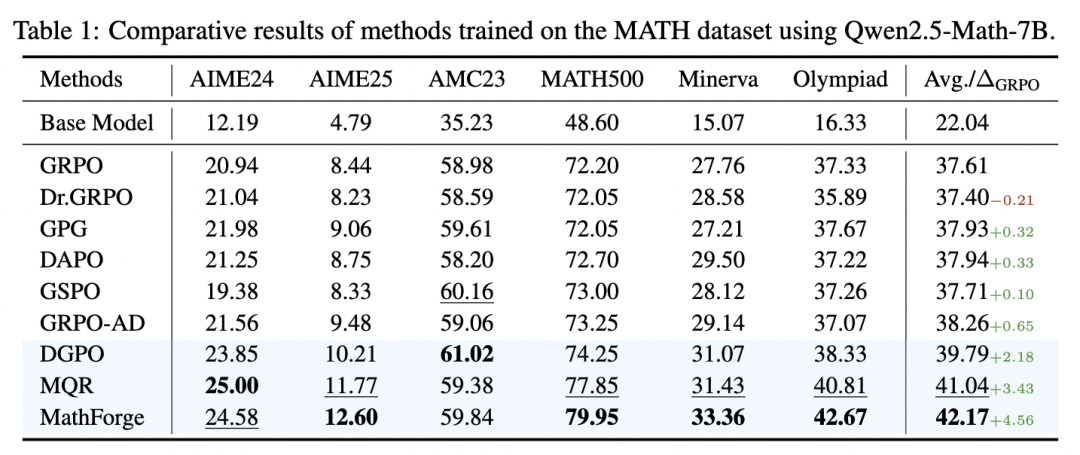
实验数据给出了最直接的答案。在核心基准上,MathForge 相比标准 GRPO 平均性能跃升超过 4.5%。这不是微弱的波动——在数学推理领域,每 1 个百分点的提升都来之不易,4.5% 意味着范式级的代差。
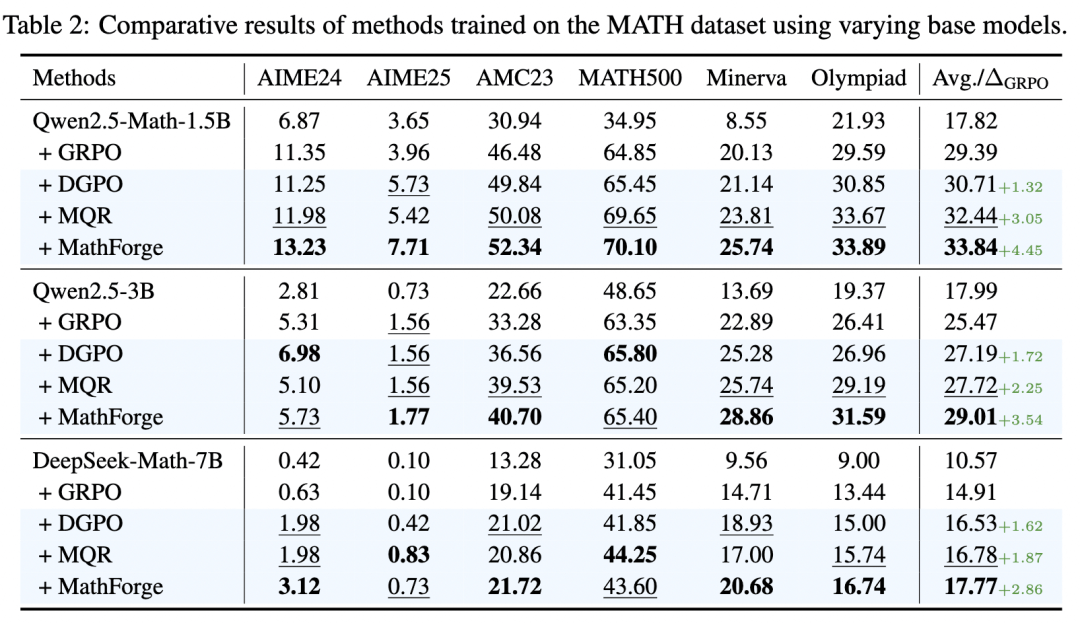
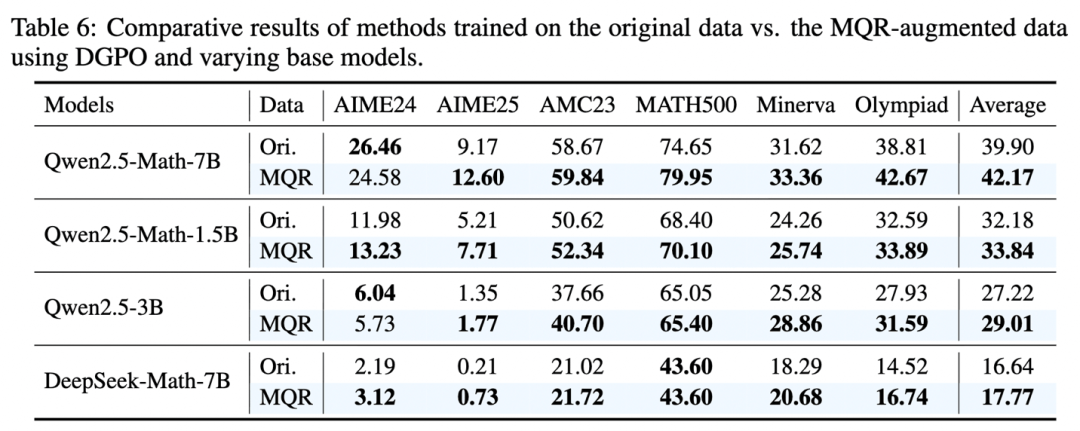
更关键的是跨模型普适性验证。研究团队测试了不同规模的模型,从较小参数模型到 7B 级别,MathForge 均能稳定带来约 3 到 4.5 个点的显著增益。这证明“难题优先”并非某个模型的“特供调参”,而更接近一种通用的后训练规律。
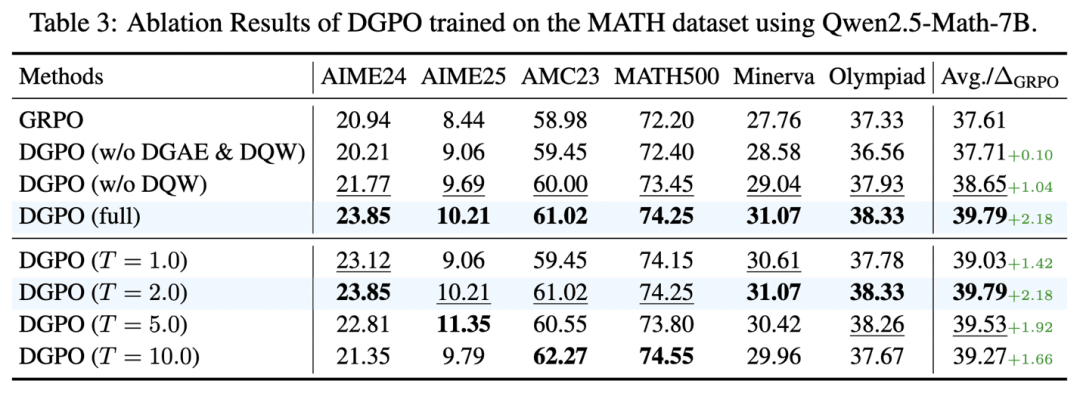
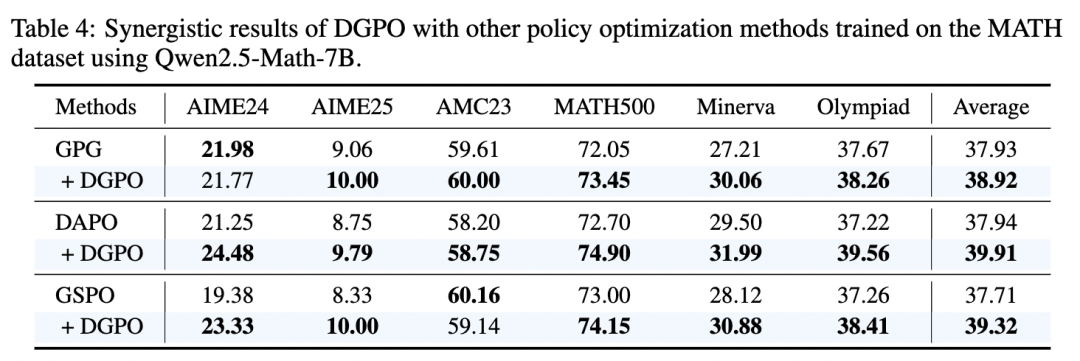
消融实验进一步揭示了 DGPO 内部的双重机制是缺一不可的互补关系:DGAE 负责拉平更新幅度,避免中等难度题垄断训练信号;DQW 则将火力精准聚焦于“难而可学”的边界地带。单独使用任一组件,效果都会大打折扣。这种结构化的增益,使 DGPO 甚至可以作为一种“即插即用”的增强模块,与多种现有强化学习方法结合,持续带来额外收益。
能力泛化与效率革命:多模态任务同样有效,推理路径竟变得更简短高效

如果仅停留在数学文本任务上,还不足以展现 MathForge 的全部潜力。其能力泛化边界,在跨模态任务中得到了有力验证。
当 DGPO 被直接迁移到多模态数学推理场景——面对图像与文本交织的复杂输入时,依然取得了超过 2 个点的稳定提升。这有力地证明,锁定“难而可学”样本进行重点攻坚,并非特定数据下的偶然,而是一种更底层的认知能力激发机制。
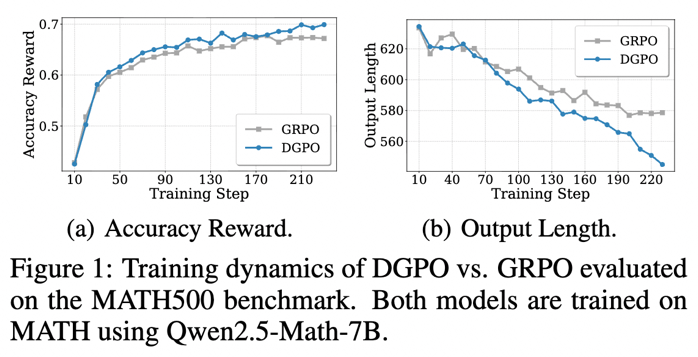
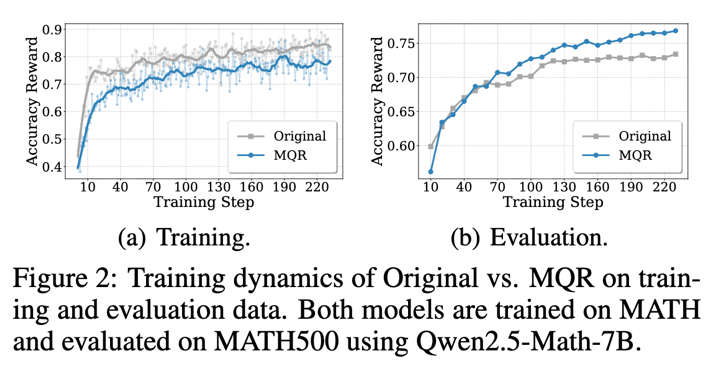
最令人意外的,是随之而来的效率革命。传统观念中,攻克难题往往意味着更长的推理链条。但训练动态数据显示,采用 DGPO 的模型不仅准确率更高,其生成的推理路径反而更加简短。
这颠覆了“更长即更好”的直觉。模型并非通过堆砌冗长步骤来碰运气,而是在高难度训练中被迫学会了更高效的推理捷径——它找到了问题的本质,而非在表面绕弯。与此同时,MQR 改写后的数据呈现出典型的“Train Harder, Test Better”现象:训练时准确率更低、挣扎更剧烈,但测试时的泛化能力却实现了反超。
本质洞察:MathForge 的价值不在于“题海战术”,而在于精准识别了高价值学习区间。它证明了,真正的推理能力跃迁,发生在模型“将将够不着、但跳一跳就能够到”的边界上。不是刷得越多越好,而是刷得越准越好。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)