FlashAttention 详解:从标准 Attention 到 IO 感知计算
本报告用「问题背景 → 核心算法 → 数学细节 → 工程实现 → 版本演进 → 实践建议」的顺序, 系统梳理 FlashAttention。重点解释它为什么能显著减少显存、提升速度,以及它和普通 Attention 在数学上为何等价。
适合读者:了解 Transformer 基础,希望理解训练/推理加速关键词:Self-Attention、HBM、SRAM、Tiling、Online Softmax核心结论:精确 Attention,不是近似 Attention
执行摘要
先用几句话建立整体图景,后面再逐层展开。
FlashAttention 解决什么问题?
标准 Attention 会显式生成并保存一个 N×N 的注意力矩阵。序列长度 N 变大时, 这张矩阵既占显存,又造成大量 HBM 读写,GPU 很多时间不是在算,而是在搬数据。
FlashAttention 怎么解决?
它把 Q、K、V 切成小块,在 GPU 芯片内的高速 SRAM 中分块完成计算, 并用 Online Softmax 保证分块计算与一次性全量 Softmax 的结果等价。
它是不是近似算法?
不是。FlashAttention 不改变 Attention 的数学定义,输出与标准 Attention 一致, 差别只在计算顺序和内存访问方式。
收益是什么?
训练时显存复杂度从 O(N²) 降到 O(N),速度通常提升数倍。 它已成为现代 LLM 训练和推理系统中的基础组件。
一句话:FlashAttention 的本质是「IO-aware exact attention」: 它意识到 GPU 的内存层级差异,用更聪明的数据搬运方式实现同一个 Attention。
1 标准 Attention 做了什么
理解 FlashAttention 前,先把普通 Self-Attention 的计算路径说清楚。
1.1 输入与公式
Transformer 中的每个 attention head 会接收三个矩阵:Q(Query)、K(Key)、V(Value)。 对于序列长度 N、head dimension d 的情况:
Q, K, V ∈ R^{N×d} S = QKᵀ / √d // S 是 attention score,形状为 N×N P = softmax(S) // P 是 attention probability,形状为 N×N O = PV // O 是输出,形状为 N×d
直观理解:第 i 个 token 的 Query 会和所有 token 的 Key 做相似度计算, 得到「第 i 个 token 应该关注谁」的分数。Softmax 把分数转成概率, 最后用这些概率对所有 token 的 Value 加权求和。
1.2 标准实现的中间矩阵
标准实现通常会显式产生两个 N×N 矩阵:score 矩阵 S 和 probability 矩阵 P。 即使框架内部做了一些融合优化,只要反向传播还需要 P 或 S 的信息, 训练过程仍然倾向于保存大量中间状态。
| 阶段 | 中间结果 | 形状 | 问题 |
|---|---|---|---|
| QKᵀ | score 矩阵 S | N×N | 序列越长,矩阵按平方增长 |
| Softmax | 概率矩阵 P | N×N | 训练反向传播通常需要保存 |
| PV | 输出 O | N×d | 这是最终需要的结果,规模相对小很多 |
当 N=16,384 时,N×N 约为 2.68 亿个元素。若使用 fp16,仅一个矩阵就约 512 MB; 考虑多个 head、batch、训练中间状态和反向传播,显存压力会迅速放大。
2 真正瓶颈:不是算力,而是 IO
FlashAttention 的关键洞察来自 GPU 内存层级。
2.1 GPU 的两类关键内存
HBM / 显存
容量大,通常几十 GB;带宽高但距离计算单元较远。 大模型参数、激活值、大矩阵一般存放在 HBM。
SRAM / 片上缓存
容量小,通常几十 MB;但速度远快于 HBM。 如果数据能留在 SRAM 内反复使用,计算效率会高很多。
Tensor Core
GPU 的矩阵乘专用计算单元。它很快,但需要持续喂数据; 一旦数据搬运跟不上,Tensor Core 就会空转。
2.2 标准 Attention 的 IO 问题
对于标准 Attention,QKᵀ 生成的 S 和 Softmax 生成的 P 都是 N×N。 这些大矩阵通常需要写回 HBM,再从 HBM 读出来参与下一步计算。 这会带来两个后果:
- 显存占用高:N×N 中间矩阵很大,训练时还要为反向传播保留信息。
- 带宽浪费:写出 S、读入 S、写出 P、读入 P,很多时间花在内存传输。
- 算力利用率低:GPU 理论 FLOPS 很高,但没有足够快的数据供应,实际利用率低。
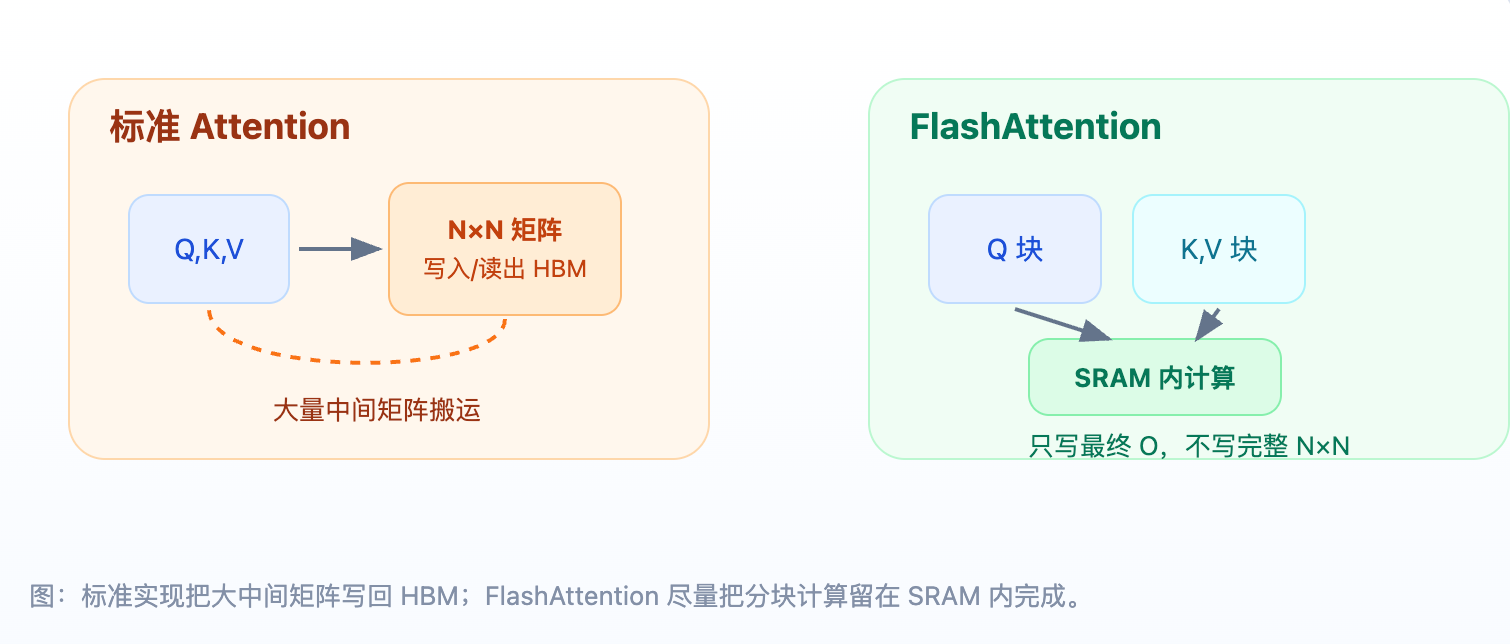
2.3 IO-aware 的含义
「IO-aware」不是指网络 IO,而是指算法设计时明确考虑内存层级之间的数据移动成本。 传统算法复杂度主要看 FLOP 数,但在现代 GPU 上,很多任务的瓶颈已经变成: 数据从 HBM 搬到计算单元的速度不够快。
FlashAttention 的思路是:既然最终只需要 O,而不需要完整的 P, 那就尽量避免把 P 这个 N×N 矩阵物化出来。只要能保证 Softmax 归一化正确, 就可以边算边累积最终输出。
3 FlashAttention 的核心思想
两个关键词:分块计算,以及可增量更新的 Softmax。
3.1 分块:把大矩阵拆成 SRAM 放得下的小块
FlashAttention 不一次性计算完整的 QKᵀ,而是把 Q 按行切块,把 K、V 按列/行块配对加载。 每次只把一小块 Q、K、V 放进 SRAM,计算局部 score,然后把局部结果合并到输出 O 中。
假设 Q 被切成 Q₁, Q₂, ...
K/V 被切成 K₁,V₁, K₂,V₂, ...
对每个 Qᵢ:
依次处理所有 Kⱼ,Vⱼ
计算局部 Sᵢⱼ = QᵢKⱼᵀ / √d
局部 Softmax 信息被合并到该 Qᵢ 对应的输出 Oᵢ3.2 难点:Softmax 不是局部操作
如果只是矩阵乘,分块非常自然。但 Softmax 有一个麻烦点: 对于第 i 行,Softmax 的分母需要这一行所有列的指数和。 换句话说,一个 token 对所有 token 的注意力概率,必须在全局范围内归一化。
softmax(sᵢⱼ) = exp(sᵢⱼ) / Σₖ exp(sᵢₖ)
如果把 K/V 分成很多块,那么处理第一个块时还没有看到后面的 score, 看起来就不能正确计算 Softmax。FlashAttention 的关键就在于: 使用 Online Softmax,一边看到新块,一边更新最大值、归一化分母和输出。
3.3 它到底避免了什么
| 内容 | 标准 Attention | FlashAttention |
|---|---|---|
| 完整 score 矩阵 S | 显式生成,可能写入 HBM | 只在块内短暂存在 |
| 完整 probability 矩阵 P | 训练中常需保存 | 不保存,反向时重算 |
| 最终输出 O | 写回 HBM | 写回 HBM |
| 每行 Softmax 统计量 | 不一定显式保存 | 保存 m 和 l,供 backward 使用 |
4 Online Softmax 详解
这是 FlashAttention 能分块又保持精确的数学基础。
4.1 为什么 Softmax 要减最大值
Softmax 中包含指数函数,若 score 较大,exp(score) 可能溢出。 常规数值稳定写法会对每一行减去该行最大值:
softmax(xᵢ) = exp(xᵢ - m) / Σⱼ exp(xⱼ - m) 其中 m = maxⱼ xⱼ
这个变换不会改变 Softmax 结果,因为分子分母都乘了同一个常数 exp(-m)。 但问题是:分块时,一开始不知道全局最大值 m。
4.2 增量更新最大值和分母
假设已经处理过一些 score,它们的最大值是 m_old,指数和是 l_old:
l_old = Σ exp(x_old - m_old)
现在来了一个新块,其局部最大值是 m_block,局部指数和是 l_block。 新的全局最大值为:
m_new = max(m_old, m_block)
由于基准最大值从 m_old 变成 m_new,旧的指数和必须按比例缩放:
l_new = exp(m_old - m_new) · l_old + exp(m_block - m_new) · l_block
4.3 增量更新输出
Attention 输出不是 Softmax 概率本身,而是概率对 V 的加权和。 FlashAttention 同时维护每行的输出累积值 O。新块到来时:
O_new = [ exp(m_old - m_new) · l_old · O_old + exp(m_block - m_new) · Σ exp(S_block - m_block) · V_block ] / l_new
这就是 Online Softmax 的关键:当新的最大值出现时,旧结果不是作废, 而是按 exp(m_old - m_new) 重新缩放。这样就能在只看一个块的情况下, 逐步得到与全量 Softmax 完全相同的归一化结果。
4.4 用一个小例子理解
假设某一行 score 被切成两块:[1, 2] 和 [3, 4]。 如果先看第一块,最大值是 2;看到第二块后,全局最大值变成 4。 第一块的贡献需要乘上 exp(2-4),才能和第二块放在同一个数值基准下比较。
第一块: m_old = 2 l_old = exp(1-2) + exp(2-2) 第二块: m_block = 4 l_block = exp(3-4) + exp(4-4) 合并: m_new = 4 l_new = exp(2-4) * l_old + exp(4-4) * l_block
5 Forward Pass 计算流程
这一节按真实计算顺序描述 FlashAttention 的前向传播。
5.1 前向传播维护的状态
对于每个 Q 块,FlashAttention 会维护三类状态:
| 状态 | 含义 | 大小 |
|---|---|---|
| m | 每一行当前见过的最大 score,用于数值稳定 | O(N) |
| l | 每一行当前的 Softmax 分母,即归一化因子 | O(N) |
| O | 每一行当前累积的 Attention 输出 | O(Nd) |
5.2 计算步骤
1 选择块大小
根据 SRAM 容量、head dimension、数据类型、寄存器压力等因素决定 Q/K/V 的 block size。
2 加载一个 Q 块
把 Q 的一部分行加载到 SRAM,并初始化该块对应的 m=-∞、l=0、O=0。
3 遍历 K/V 块
每次加载一块 K 和对应的 V,计算局部 score S_block = Q_block K_blockᵀ / √d。
4 局部 Softmax 与合并
在块内计算局部最大值与指数和,然后用 Online Softmax 公式更新 m、l、O。
5 写回最终输出
所有 K/V 块处理完成后,该 Q 块的 O 已经是完整 Attention 输出,写回 HBM。
5.3 伪代码
for each Q_block:
load Q_block into SRAM
O = 0
m = -inf
l = 0
for each K_block, V_block:
load K_block, V_block into SRAM
S = Q_block @ K_block.T / sqrt(d)
m_block = rowmax(S)
P_block = exp(S - m_block)
l_block = rowsum(P_block)
m_new = max(m, m_block)
l_new = exp(m - m_new) * l
+ exp(m_block - m_new) * l_block
O = (
exp(m - m_new) * l * O
+ exp(m_block - m_new) * (P_block @ V_block)
) / l_new
m = m_new
l = l_new
write O, m, l back to HBM注意:伪代码强调数学逻辑,真实 CUDA kernel 会做更多工程优化, 例如 warp 级并行、共享内存布局、寄存器复用、向量化加载、避免 bank conflict 等。
6 Backward Pass 与重计算
FlashAttention 的显存收益不只来自前向,也来自反向传播策略。
6.1 标准反向传播为什么耗显存
训练时不仅要得到输出 O,还要计算 Q、K、V 的梯度。 标准实现中,反向传播往往依赖前向阶段的 Softmax 概率矩阵 P。 如果 P 是 N×N,那么为了 backward 保存 P 就会导致 O(N²) 的激活显存。
6.2 FlashAttention 的选择:少存,必要时重算
FlashAttention 前向不保存完整 P,而只保存:
- 输出 O
- 每一行的最大值 m
- 每一行的归一化因子 l
到 backward 时,再按同样的分块方式重新计算局部 S 和局部 P, 用它们计算 dQ、dK、dV。这样会增加一些重复计算, 但避免了保存 N×N 中间矩阵。
好处
- 训练激活显存从 O(N²) 降到 O(N)
- 更容易训练长序列
- 减少 HBM 读写,整体往往更快
代价
- Backward 中会重算部分 score 和 probability
- FLOP 数略有增加
- kernel 实现更复杂
这是典型的「用计算换显存」策略。但在 Attention 场景下,节省 IO 带来的收益通常超过额外重算成本。
7 复杂度与性能收益
FlashAttention 没有减少数学 FLOP,却显著减少内存 IO。
7.1 时间复杂度没有本质改变
对于完整 dense attention,FlashAttention 仍然需要计算 QKᵀ, 所以主计算量仍是 O(N²d)。它不是稀疏 Attention,也不是低秩近似。
7.2 空间复杂度大幅降低
| 指标 | 标准 Attention | FlashAttention | 解释 |
|---|---|---|---|
| 前向额外显存 | O(N²) | O(N) | 不保存完整 score/probability 矩阵 |
| 训练激活显存 | O(N²) | O(N) | Backward 通过重计算恢复局部 P |
| 数学精确性 | 精确 | 精确 | 没有引入近似 |
| 主要收益来源 | 无 | 减少 HBM IO | 提高 GPU 算力利用率 |
7.3 为什么实际会更快
表面上 FlashAttention 的计算量没有减少,甚至 backward 有重算,为什么还能更快? 原因在于现代 GPU 上矩阵乘很快,但 HBM 访问相对慢。标准 Attention 的大量中间矩阵读写让计算单元等待数据; FlashAttention 让更多中间结果停留在 SRAM/寄存器中,减少等待。
可以把它理解成:不是少做了很多数学题,而是少把草稿纸来回搬进搬出仓库。 计算还在,但数据移动少了,GPU 就能更持续地工作。
7.4 典型收益范围
具体收益取决于 GPU 架构、序列长度、head dimension、batch size、是否 causal mask、是否 dropout 等。 大体上:
- 序列越长,避免 N×N 中间矩阵的收益越明显。
- head dimension 常见为 64/128 时,kernel 优化效果较好。
- 训练场景收益通常更明显,因为 backward 激活显存压力更大。
- 小序列或很小 batch 时,kernel 启动开销和并行度不足可能让收益不明显。
8 版本演进:v1 / v2 / v3
FlashAttention 后续版本主要围绕更高 GPU 利用率与新硬件特性展开。
2022 · FlashAttention v1
v1 提出了核心算法:IO-aware tiling、Online Softmax、反向重计算。 它证明了 Attention 加速不一定要牺牲精度,关键可以是重新组织计算和内存访问。
- 显存复杂度从 O(N²) 降到 O(N)
- 避免完整 attention matrix 写回 HBM
- 支持精确 causal attention 和 non-causal attention
2023 · FlashAttention-2
v2 的重点是提升 GPU 并行效率。它减少非矩阵乘法 FLOP, 优化 warp/thread block 的工作划分,并改进多 query 场景。
- 更好地利用 Tensor Core
- 降低 warp 间同步和通信开销
- 支持 MQA/GQA,更适合现代 LLM 推理和训练
- 在 A100 等 GPU 上可达到更高实际吞吐
2024 · FlashAttention-3
v3 面向 Hopper 架构(如 H100)做深度优化,使用异步数据移动、 warp specialization 和 FP8 等硬件特性进一步提高吞吐。
- 利用 TMA 等机制重叠数据搬运与计算
- 更充分发挥 Hopper Tensor Core
- 在 H100 上相比 v2 继续提升性能
9 工程使用与限制
FlashAttention 很强,但不是所有场景都自动收益最大。
9.1 适合使用的场景
- LLM 预训练、SFT、RLHF 等长序列训练。
- 上下文长度较大,标准 Attention 显存压力明显的模型。
- 使用 causal attention 的 decoder-only 模型,例如 GPT/LLaMA 类模型。
- 需要 MQA/GQA 加速的现代推理或训练系统。
9.2 可能不明显收益的场景
- 序列很短时,N×N 矩阵并不大,kernel 开销可能抵消收益。
- 模型瓶颈在 MLP、通信、数据加载或 CPU 侧时,替换 Attention 不一定显著提升端到端速度。
- 需要显式拿到完整 attention map 做可视化、解释性分析或额外 loss 时,FlashAttention 的优势会被削弱。
- 某些特殊 mask、非常规 attention pattern 或不受支持的数据类型,可能需要退回普通实现。
9.3 常见集成方式
| 方式 | 说明 | 注意点 |
|---|---|---|
| PyTorch SDPA | PyTorch 的 scaled_dot_product_attention 会在合适条件下选择 flash backend | 需关注 PyTorch/CUDA/GPU 版本与 mask/dropout 条件 |
| flash-attn 包 | 直接使用 Tri Dao 团队维护的实现 | 安装编译依赖较多,CUDA 版本要匹配 |
| 框架内置 | Transformers、Megatron、DeepSpeed、vLLM 等常有内置开关 | 检查实际是否启用,不要只看配置名 |
9.4 如何判断是否真的启用
工程中常见误区是「配置里写了 flash attention,但实际因为条件不满足退回普通 attention」。 建议从以下角度确认:
- 查看框架日志或 profiler,确认调用的是 flash attention kernel。
- 用相同 batch/sequence length 对比显存峰值。
- 用 profiler 观察 attention 部分耗时是否下降。
- 确认 mask 类型、dropout、dtype、head dimension 是否满足对应实现的支持范围。
10 相关技术
很多长上下文和推理系统都建立在类似的内存优化思想上。
PagedAttention
vLLM 的核心技术之一。它主要优化推理阶段的 KV Cache 管理, 把 KV Cache 切成页,减少内存碎片,提高多请求并发吞吐。
FlashDecoding
面向自回归推理 decoding 阶段。此时 Q 通常只有当前 token, 但 K/V Cache 很长,需要沿 KV 维度并行化以充分利用 GPU。
Ring Attention
把长序列切分到多张 GPU 上,通过环形通信交换 K/V 块, 将 FlashAttention 的分块思想扩展到多卡超长上下文训练。
Sliding Window Attention
只关注局部窗口内 token,计算复杂度从 O(N²) 降到 O(NW)。 它是稀疏注意力方向,和 FlashAttention 的精确 dense attention 优化不同。
区分两个维度很重要:FlashAttention 主要优化「怎么高效算完整 attention」; 稀疏/滑窗/低秩方法则改变「要算哪些 attention」。前者是精确实现优化,后者是模型结构或近似策略。
11 总结
把所有内容收束成几个最重要的判断。
11.1 核心结论
- FlashAttention 是精确 Attention。 它不改变 softmax(QKᵀ)V 的数学定义,只改变计算顺序和内存访问。
- 它的核心不是减少 FLOP,而是减少 HBM IO。 标准 Attention 的瓶颈常在 N×N 中间矩阵读写,而不是单纯计算量。
- Online Softmax 是分块计算成立的关键。 它允许每处理一个 K/V 块就更新最大值、归一化分母和输出。
- Backward 通过重计算换显存。 不保存完整 P,反向时按块重算局部概率,显著降低训练激活显存。
- 版本演进越来越贴近硬件。 v1 证明算法,v2 优化并行效率,v3 深度利用 H100/Hopper 特性。
11.2 最简心智模型
标准 Attention 像是先把一整张 N×N 大表完整写出来,再逐步处理; FlashAttention 像是拿着一小块草稿纸逐块算,边算边合并结果, 最后只把真正需要的答案写回去。
11.3 阅读建议
如果只想快速理解,重点读第 0、2、3、4、11 章; 如果要做工程集成,重点读第 5、6、8、9 章; 如果要深入 kernel 优化,需要继续阅读 CUDA shared memory、warp scheduling、Tensor Core 和 Hopper TMA 相关资料。
参考方向:FlashAttention (Dao et al., 2022)、FlashAttention-2 (Dao, 2023)、FlashAttention-3 (2024)。 本文为学习报告,重点在解释原理和工程直觉。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)