LangChain - AI应用开发利器(二)
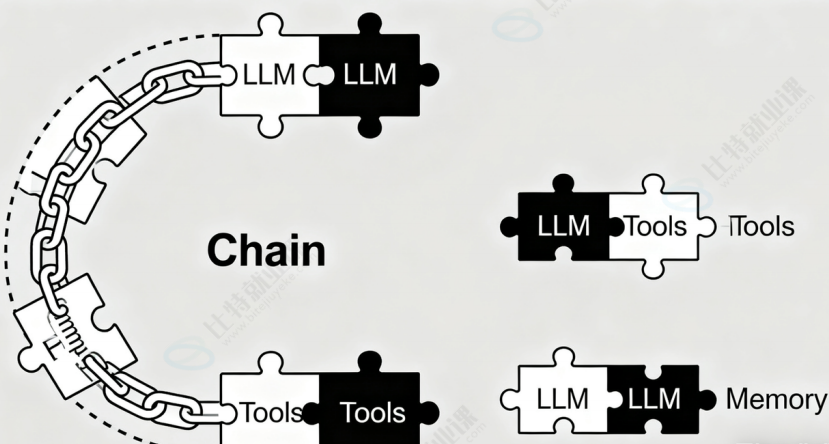
1. 引出LangChain相关概念
1.1. Runnable接口
Runnable接口时使用LangChain Components(组件)的基础。
概念说明:
Components(组件):用来帮助当我们在构建应用程序时,提供了一系列的核心构建块,
例如语⾔模型、输出解析器、检索器、编译的 LangGraph 图等。
Runnable定义了一个标准接口,允许Runnable的相关组件:
- Invoked(调用):当个输入转化为输出
- Batched(批处理):多个输入转化为输出
- Streamed(流式处理):多个输入被有效的转化为输出
- Inspected(检查):可以访问有关的Runnable的输入和输出
- Composed(组合):可以醋和多个Runnable,以使用LCEL协同工作以创建复杂的管道
因此,我们定义的聊天模型,输出解析器都是Runnable接口的实例,他们都使用了Invoked(调用)的能力
1.2. LangChain Expression Language
LangChain Expression Language(LCEL):采用声明性方法,从现有Runnable 对象构建新的 Runnable 对象。通过LCEL 构建出的新的Runnable 对象,被称为,表示可运行序列。RunnableSequence 就是一种链,chain 的类型就是RunnableSequence。如下所示:
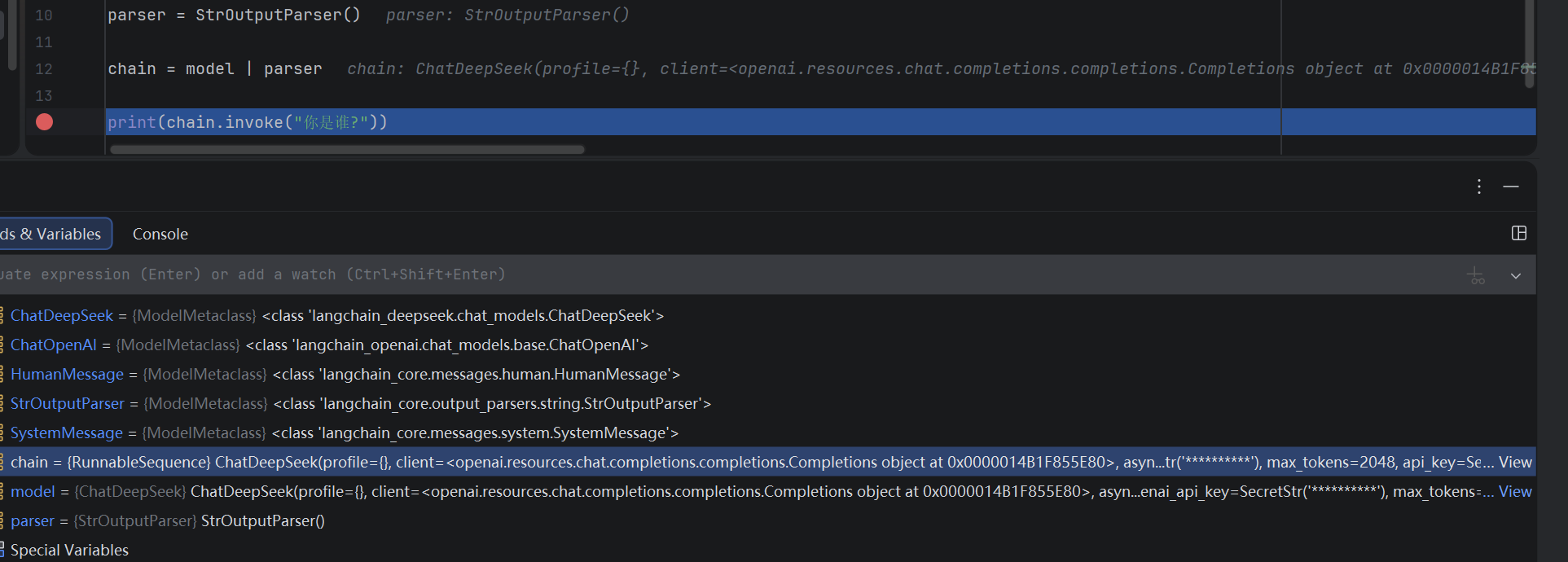
重要的是,RunnableSequence也是Runnable 接口的实例,它实现了完整的Runnable 接口,因此它可以用与任何其他Runnable 相同的姿势使用。
2. 定义聊天模型
2.1. 通过API定义聊天模型
2.1.1. 方式1:ChatOpenAI
class langchain_openai.chat_models.base.ChatOpenAI 是 LangChain为OpenAI 旗下的聊天模型提供的具体实现类,其继承了 class langchain_openai.chat_models.base.BaseChatOpenAI,并且BaseChatOpenAI实现了标准的Runnable接口。
ChatOpenAI 常用初始化参数说明
| 参数名 | 参数描述 |
| model | 使用的模型名称 |
|
temperature |
采样温度,温度值越⾼,AI 回答越天⻢⾏空;温度越低,回答越保守靠谱
|
|
max_tokens |
要生成的最大令牌数 |
|
timeout |
请求超时时间 |
|
max_retries |
最大重试次数 |
|
openai_api_key / api_key
|
OpenAI API密钥。如果未传入,将从环境变量中读取 OPENAI_API_KEY 。 |
|
base_url |
API 请求的基本URL。 |
|
organization |
OpenAI组织,如果不传入,将从env var OPENAI_ORG_ID中去读 |
代码实例:
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="gpt-5-mini",
temperature=0 ,
max_tokens=None ,
timeout=None ,
max_retries=2 ,
# api_key ="...",
#base_url="...",
#organization ="...",
#other params ..
)若使用其它与OpenAI兼容的大模型,例如DeepSeek,则可以使用以下定义方式:
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="deepseek-chat",
base_url="https://api.deepseek.com/v1",
openai_api_key=OPENAI_API_KEY
}参数说明:
base_url:出于与OpenAI 兼容考虑,要将base_url 设置为
https://api.deepseek.com/v1 来使用,但注意,此处v1 与模型版本无关。
openai_api_key:需要单独申请DeepSeek 的API Key,然后重新进行环境变量配置。
◦DeepSeek API Key 申请地址:https://platform.deepseek.com/api_keys。
2.1.2. invoke()调用
在介绍方式2之前,需要先了解一下关于Runnable 接口中的invoke()调用。该方法是将单个的输入转化为对应的输出。例如对于聊天模型,就是根据用户的输入进行回答。
invoke()方法的定义:
abstractmethod invoke(
input : Input ,
config : RunnableConfig | None = None ,
**kwargs :Any ,
) → Output
参数说明:
- input:输入一个Runnable实例
- config:出入的Runnable实例的配置参数,默认为空
返回值:
- 返回一个Runnable实例
class langchain_core.runnables.config.RunnableConfig常用的参数说明:
| 参数名 | 参数描述 |
|
configurable |
通过.configurable_fields()在此Runnable 或子Runnable 上配置的属性的运行时值。 |
|
run_id |
针对次调用与运行的跟踪器的唯一标识符。如果未提供,将生成新的UUID。 |
|
run_name |
此调用的跟踪器运行的名称。默认为类的名称。 |
|
metadat |
此次调用和任何子调用的元数据。键是字符串,值是JSON。 类型:dict [str,Any] |
|
...... |
2.1.3. 方式2:init_chat_model
上面的ChatOpenAI 用于明确创建OpenAI 聊天模型的实例。而init_chat_model ()是一个工厂函数,它可以初始化多种支持的聊天模型(如OpenAI、Anthropic、FireworksAI 等),不仅仅是 OpenAI 的聊天模型。
init_chat_model()函数定义:
langchain.chat_models.base.init_chat_model(
model : str ,
*,
model_provider : str | None = None ,
configurable_fields : Literal[None] = None ,
config_prefix : str | None = None ,
**kwargs :Any ,
) → BaseChatModel
init_chat_model()常用的参数说明:
| 参数名 | 参数描述 |
| model | 要使用的模型名称 |
| model_provider | 模型提供方。如果没指定会从model推断 |
|
configurable_fields |
设置那些模型参数是可以配置的。若该参数配置为:
|
|
config_prefix |
|
|
temperature |
采样温度,温度值越高,AI回答越天马行空;温度越低,回答越保守靠谱。 |
|
max_tokens |
生成的最大令牌数 |
|
timeout |
请求超时时间 |
| max_retries | 最大的重试次数 |
|
openai_api_key /api_key |
OpenAI API密钥。如果未传入,将从环境变量中读取OPENAI_API_KEY 。 |
|
base_url |
API 请求的基本URL。 |
| ... |
init_chat_model()返回值说明
函数返回一个与指定的model_name和mode_provider相对应的BaseChatModel(如ChatOpenAI, ChatAnthropic)。注意要是模型可配置,则返回一个聊天模型模拟器,该模拟器在传入配置后,在运行的时候才会初始化底层模型。
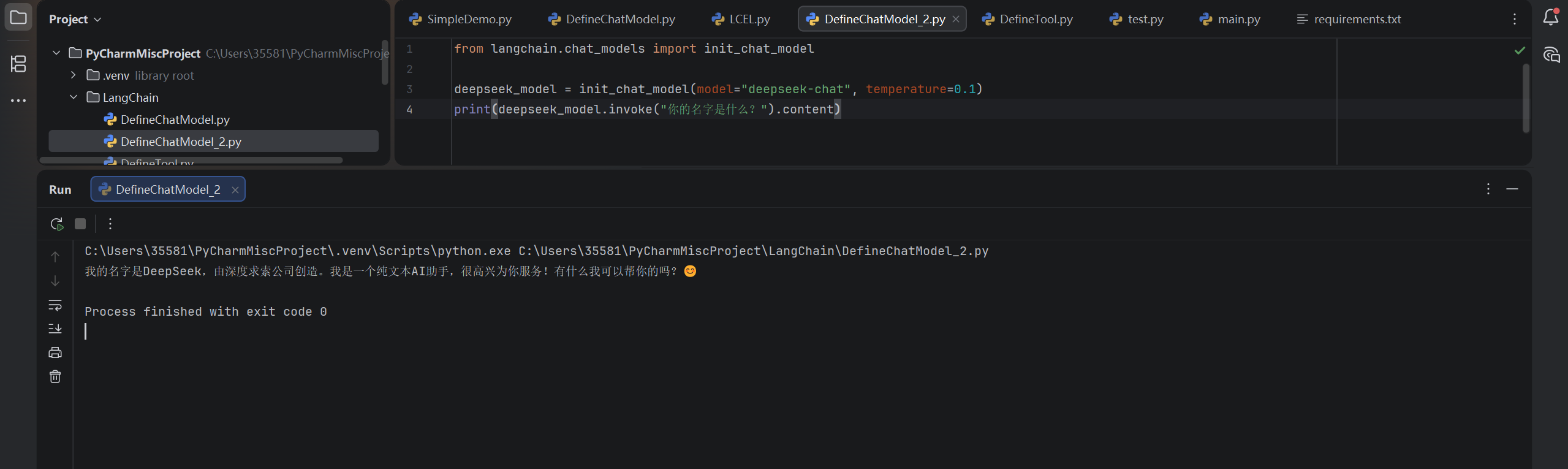
示例1:基本用法
from langchain.chat_models import init_chat_model
deepseek_model = init_chat_model(model="deepseek-chat", temperature=0.1)
print(deepseek_model.invoke("你的名字是什么?").content)运行结果:
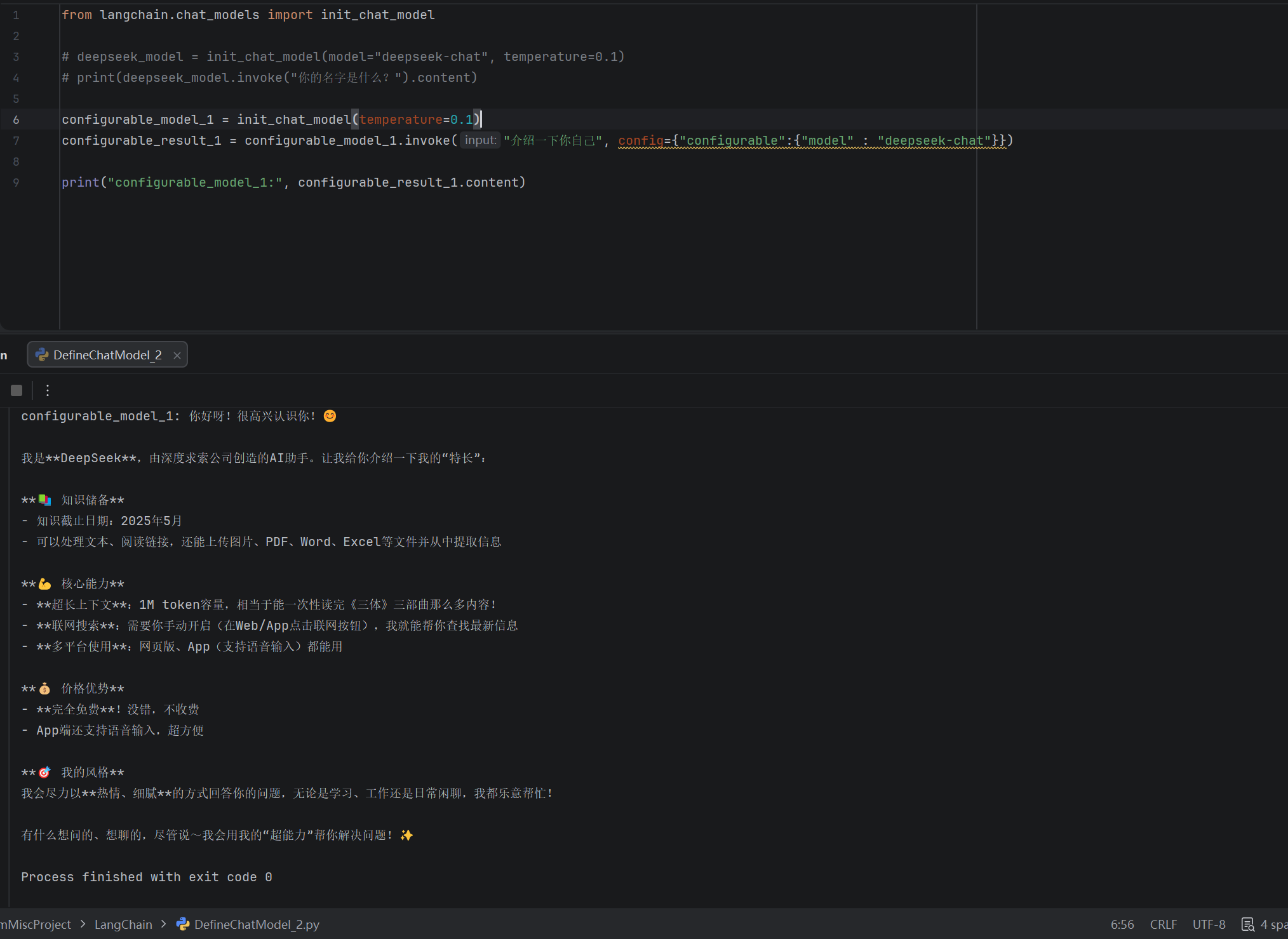
示例2:创建可配置模型
from langchain.chat_models import init_chat_model
configurable_model_1 = init_chat_model(temperature=0.1)
configurable_result_1 = configurable_model_1.invoke("介绍一下你自己", config={"configurable":{"model" : "deepseek-chat"}})
print("configurable_model_1:", configurable_result_1.content)运行结果:
示例3:具有默认值的可配置模型
# 可配置的模型选择器
configurable_model_2 = init_chat_model(
model="deepseek-v4-pro",
temperature=0.1,
configurable_fields=("model", "model_provider", "max_tokens", "temperature"),
config_prefix="first"
)
configurable_result_2 = configurable_model_2.invoke("写一篇的文章",
config={
"configurable":{
"first_temperature":1.0,
"first_max_tokens": 1024,
}
},
)
configurable_result_3 = configurable_model_2.invoke("写一篇的文章",
config={
"configurable":{
"first_temperature":0.3,
"first_max_tokens": 2048,
}
},
)
print(configurable_result_2.content)
print(configurable_result_3.content)我们对于configurable_result_2 和 configurable_result_3 设置了不同的max_tokens和temperature,所以所打印的结果也不同
2.2 通过本地部署的LLM定义聊天模型
2.2.1. ChatOllama
若想使用ChatOllama,需要先安装Ollama 包:
pip install -U langchain_ollama
class langchain_ollama.chat_models.base.ChatOllama是LangChain 为通过Ollama 部署的聊天模型提供的具体实现类。ChatOllama 同样也实现了标准的Runnable 接口。
ChatOllama常用初始化参数说明:
| 参数名 | 参数描述 |
| model |
要使用的Ollama 模型的名称 |
| temperature | 采样温度,温度值越高,AI回答越天马行空;温度越低,回答越保守靠谱。 |
|
timeout |
请求超时时间 |
|
base_url |
API 请求的基本URL。 |
|
num_ctx |
设置用于生成下一个令牌的上下文窗口的大小。(默认值:2048) |
|
num_gpu |
要使用的GPU 数量。在macOS 上,默认为1 表示启用金属支持,默认为0 表示禁用。 |
| ... |
示例:
from langchain_ollama import ChatOllama
ollama_model = ChatOllama(model="deepseek-r1:70b",
base_url='http://192.168.100.220:11434 ')
result = ollama_model .invoke("what 's your name?")
print(result)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)