【大模型-VLA】A Pragmatic VLA Foundation Model
摘要
视觉-语言-动作(VLA)基础模型在机器人操作领域具有巨大潜力,我们期望它能够在各种任务和平台上实现良好的泛化能力,同时确保成本效益(例如,适应所需的数据量和GPU运行时间)。为此,我们开发了LingBot-VLA模型,该模型基于来自9种常用双臂机器人配置的约20,000小时真实世界数据。通过对3个机器人平台进行系统评估,每个平台完成100个任务,每个任务包含130个训练后迭代,我们的模型在性能上明显优于竞争对手,展现了其强大的性能和广泛的泛化能力。此外,我们还构建了一个高效的代码库,在8GPU训练配置下,其吞吐量可达每秒261个样本,相比现有的VLA相关代码库,速度提升了1.5至2.8倍(具体倍数取决于所使用的VLM基础模型)。上述特性确保了我们的模型非常适合实际应用。为了推进机器人学习领域的发展,我们提供代码、基础模型和基准数据的开放访问,重点是实现更具挑战性的任务并推广合理的评估标准。
1 Introduction
视觉-语言-动作(VLA)基础模型[5, 6, 27]已成为一种很有前景的方法,它使机器人能够根据自然语言指令执行各种操作任务。通过大规模预训练,这些模型能够获得可泛化的技能,并能快速适应不同的任务和机器人平台。尽管取得了显著进展,但目前仍然缺乏关于真实机器人性能如何随预训练数据集规模不断扩大而扩展的全面实证研究。此外,该领域也缺乏能够高效地对海量数据进行扩展性评估的高度优化训练代码库。因此,一个需要在实际环境中研究的基本问题是:VLA模型如何才能真正应对海量真实世界机器人数据?
理解VLA模型的扩展性对于机器人学习至关重要,尤其是在庞大且多样化的真实世界数据集上。本文系统地实证研究了VLA预训练过程中成功率如何随数据量和多样性而变化。通过将预训练数据从3000小时扩展到20000小时,我们证明了后续训练的成功率持续且显著地提高。值得注意的是,即使达到20000小时,这种扩展性也没有出现饱和迹象,表明VLA的性能会持续受益于数据量的增加。这些结果首次提供了真实世界机器人学习中良好扩展性的实证证据,为未来的VLA开发和大规模数据管理提供了重要的见解。
尽管规模分析揭示了良好的性能趋势,但要将这些见解转化为可靠、可部署的系统,需要在真实的机器人平台上进行大规模的严格评估。得益于 GM-100 [29] 提供的 100 个精心设计的任务,我们得以在 3 个机器人平台上进行系统评估,每个机器人每个任务每个实例均进行了 130 次测试。通过强调任务多样性和多平台一致性,我们的评估框架为可靠的 VLA 基准测试提供了一系列新的标准。
本文提出了一种实用的VLA基础模型LingBot-VLA,该模型基于来自9个机器人平台的约20,000小时的真实世界操作数据进行训练。我们在综合基准测试中进行了系统评估,结果表明,与现有方法相比,LingBot-VLA实现了最先进的性能和卓越的泛化能力。除了模型性能之外,我们还强调大规模机器人学习需要极高的计算效率。为此,我们开发了一个优化的代码库,在8 GPU集群上实现了每秒261个样本的吞吐量。这种效率的提升显著缩短了训练周期,降低了计算开销,从而降低了总体成本。凭借卓越的性能、广泛的泛化能力和高效的计算效率,LingBot-VLA非常适合实际的机器人应用。为了促进社区发展,我们开放了代码、基础模型和基准测试数据,重点在于支持更具挑战性的任务并推广合理的评估标准。
2 Related Work
2.1 Vision-Language-Action Models
Foundation VLA.
视觉-语言-动作基础模型通常采用强大的预训练视觉-语言模型[2, 3]作为语义骨干,并结合基于扩散的动作头( diffusion-based action head)。近期的VLA基础模型[4–7, 13, 26, 27, 32, 33]在更大规模、更多样化的数据集上进行预训练后,展现出更强的多任务执行能力和更优异的多具身适应性。与以往VLA基础模型使用的数据集不同,我们的模型在一个包含约20,000小时多具身数据的庞大语料库上进行了预训练。这个大规模数据集以其高度的行为多样性为特征,显著增强了模型在各种机器人操作任务中的泛化能力。
Spatial VLA.
虽然传统的视觉语言架构(VLA)模型在语义理解方面表现出色,但它们在处理复杂空间操作所需的精确几何推理和深度感知方面往往存在不足。为了解决这个问题,一些研究[9, 11, 14, 21, 23, 25, 32]将空间表征整合到了VLA框架中( To address this, several works [9, 11, 14, 21, 23, 25, 32] have integrated spatial representations into the VLA framework. )。一些研究[9, 26, 32]致力于增强具身场景下VLA的空间感知能力,从而提升VLA在下游任务中的空间操作能力。另一些研究则在VLA训练阶段显式或隐式地融入了深度信息。空间强制[14]采用了一种简化的对齐策略,强制将VLA视觉嵌入与空间表征相结合,从而显著提高了模型的空间理解能力。
2.2 Evaluation on Robot Policy
目前机器人策略的评估方法主要分为两类:基于仿真的方法[8, 15, 17, 19, 20]和基于真实世界情境的方法[1, 31]。基于仿真的基准测试提供了一种快速便捷的策略性能评估手段,能够以极低的成本在广泛多样的交互场景中进行大规模并行测试。尽管仿真环境通常采用理想化的物理模型,但其结果往往无法完全反映真实物理世界的复杂性。另一种基于真实世界的评估方法的效率通常受限于对大量硬件并行性的需求。因此,以往的大多数虚拟策略评估(VLA)研究仅限于比较少数几种方法在少数几个任务上的性能。为了更全面地评估策略在真实世界中的性能,本文在三个不同的机器人平台上进行了评估,每个平台执行了100个任务。此外,我们还深入分析了主流VLA模型如何适应真实世界场景中的各种挑战。
2.3 Efficient VLA Training
VLA模型的快速迭代促进了专用训练基础设施的发展。近年来,社区涌现出多个设计精良的开源代码库,每个代码库都针对不同的研究重点。例如,OpenPI [6] 代码库提供了一个通用框架,支持使用JAX和PyTorch训练π系列模型。StarVLA [22] 引入了一个模块化且用户友好的代码库,专门针对VLA和VLM的协同训练进行了优化,从而促进了语义知识向机器人控制的迁移。此外,Dexbotic [30] 被设计为一个统一高效的解决方案,旨在简化VLA的开发生命周期,专注于标准化从数据摄取到模型部署的流程。尽管取得了这些进展,但由于数据I/O瓶颈和通信开销,在多节点集群上训练大规模VLA模型仍然是一个巨大的挑战。为了弥合这一差距,我们提出了LingBot-VLA,这是一个专为大规模VLA训练而设计的高性能开源代码库。与现有框架不同,我们的代码库在数据加载、分布式训练策略和算子级加速方面实现了系统性优化。这些改进全面提升了训练吞吐量和可扩展性,为社区探索机器人基础模型的扩展极限提供了更高效的基础。
3 Pre-training Dataset
3.1 Data Collection

3.2 数据标注
为了获得精确的语言指令,我们执行以下标注:(1)视频片段。由机器人从多个视角拍摄的视频,由人工标注员根据预定义的原子动作进行联合分解。此外,为了减少视频中的冗余信息,在此阶段会去除视频开头和结尾的静态帧。(2)指令标注。在获得包含机器人完整运动轨迹和每个原子动作的视频片段后,我们使用 Qwen3-VL-235B-A22B [2] 对任务和子任务指令进行精确标注,如图 1 所示。

4 Model Training
4.1 Architecture
为了充分利用训练有素的视觉语言表征,LingBot-VLA 将预训练的视觉语言模型(VLM,例如 Qwen2.5VL [2])与一个名为“动作专家”的初始化动作生成模块集成在一起。这些组件通过类似于 BAGEL [10] 的混合 Transformer (MoT) 架构进行组织,其中视觉语言和动作模态通过不同的 Transformer 路径进行处理,并通过共享的自注意力机制耦合,以实现逐层统一的序列建模。该 MoT 框架确保来自 VLM 的高维语义先验在所有层级提供连续的指导,同时通过保持模态特定的处理来减轻跨模态干扰。LingBot-VLA 的架构如图 1 所示。多视图操作图像和相关的任务指令通过 VLM 进行统一编码,以建立用于后续动作生成的多模态条件。同时,机器人的本体感觉序列,特别是初始状态和动作块,被输入到动作专家中,用于预测动作生成。我们采用流匹配[16]进行连续动作建模,这有助于实现流畅的机器人控制,确保在复杂任务和各种机器人上实现高精度执行。
在 LingBot-VLA 中,VLM 和动作专家通过共享的自注意力机制进行交互,从而实现统一的分层表示。因此,时间戳 t 的联合建模序列被表示为观察条件 Ot 和动作块 At 的拼接。具体而言,观察上下文定义如下:
其中 T 表示动作块长度,即预测轨迹的时间范围,在我们的预训练阶段设置为 50。
因此,训练目标是通过条件流匹配来刻画条件分布 p(At|Ot)。对于一个流时间步 s ∈ [0, 1],我们通过在正态噪声 ϵ ∼ N(0, 1) 和真实动作 At 之间进行线性插值来定义一条概率路径,从而得到中间动作 At,s = sAt + (1 − s)ϵ。At,s 的条件分布可以表示为:
其中目标速度由线性概率路径导出的理想矢量场 At − ϵ 给出。
沿用 π0 [6] 的方法,我们实现了分块因果注意力机制来建模联合序列 [Ot,At]。该序列可以划分为三个不同的功能块:[I1 t , I2 t , I3 t , Tt]、[st] 和 [at, at+1, . . . , at+T−1]。在这些块之间应用因果掩码,使得每个块中的标记只能关注自身以及前面块中的标记。反之,同一块内的所有标记都采用双向注意力机制,可以相互关注。这种配置确保动作专家能够利用所有可用的观察知识,同时防止未来动作标记的信息泄露到当前的观察表示中。
为了在操作环境中明确捕捉空间感知,并进一步增强机器人的执行鲁棒性,我们采用了一种受近期工作[12, 28]启发的
方法。具体来说,我们应用了对应于三视图操作图像的可学习查询[Q1
t ,Q2 t ,Q3 t ]。为了整合深度信息,这些查询由视觉学习模型(VLM)处理,然后与来自LingBot-Depth[24]的深度标记[D1 t ,D2 t ,D3 t ]对齐。我们通过最小化蒸馏损失Ldistill来对齐VLM可学习查询和LingBot-Depth标记:
其中 Proj(·) 是一个投影层,它应用交叉注意力机制进行维度对齐。这种集成将几何信息注入到 LingBot-VLA 模型中,使其能够精确感知复杂的操控任务。
4.2 Training Efficiency Optimization
鉴于动作数据本质上是高频的,建立一个包含分布式训练和算子优化的高效流水线至关重要。我们的优化方法结构如下:
分布式策略:虽然 VLA 模型通常参数数量适中,但在 GPU 内存占用和训练吞吐量之间取得最佳平衡仍然至关重要。我们采用完全分片数据并行 (Fully Sharded Data Parallel (FSDP),FSDP)——一种高效的 PyTorch 实现的零冗余优化器 (Zero Redundancy Optimizer,ZeRO)——来分片优化器状态、模型参数和梯度,从而最大限度地减少内存占用。借鉴 VeOmni [18] 中提出的混合分片数据并行 (HSDP) 方法,我们专门为动作专家模块构建了特定的“分片组”。该策略有效地缓解了过度参数分片带来的通信开销。此外,我们实现了混合精度策略:在 torch.float32 中进行归约以确保数值稳定性,同时使用 torch.bfloat16 进行存储和通信。
算子级优化:我们架构中视觉、语言和动作的多模态融合本质上是一个稀疏注意力过程。为了解决这个问题,我们利用 FlexAttention 来优化计算。此外,我们还应用算子融合(通过 torch.compile)来降低内核启动开销并最大化内存带宽利用率。
这段描述阐述了一种用于大规模模型训练的高效内存优化策略,其核心思想是结合FSDP的全局内存节省与HSDP的局部通信优化,针对模型结构特点进行定制化分片。具体理解如下:
-
基础:采用FSDP以节省内存
- 目标:解决训练超大模型时GPU内存不足的问题。
- 原理:FSDP是ZeRO优化器的一种PyTorch实现。它在训练过程中,将优化器状态、模型参数和梯度这三部分数据分片保存到各个GPU上,而非在每个GPU上保存完整副本。每个GPU只负责更新和存储自己分片对应的部分,从而大幅降低单卡内存占用。
-
优化:引入HSDP以降低通信成本
- 问题:FSDP的“完全分片”在每次计算前需要从其他GPU收集(All-Gather)完整参数,计算后又要分散(Reduce-Scatter)梯度,这引入了显著的通信开销。
- 解决方案:借鉴HSDP思想,为“动作专家模块”创建独立的“分片组”。
- 如何工作:在这个特定的分片组内,参数、梯度等仅在组内的GPU之间进行分片和通信。组外的GPU不参与这些数据的交换。这相当于在全局FSDP框架下,为特定模块设置了一个通信范围更小的“子FSDP”区域。
- 效果:由于通信被限制在更小的设备组内,跨所有GPU的全局通信量减少,从而有效缓解了因过度分片带来的通信瓶颈,提升了训练效率。
总结来说,这是一种混合分片策略:全局上使用FSDP来最大化内存节省,局部上对通信敏感的专家模块使用HSDP来最小化通信开销,实现了内存与通信效率的最佳平衡。
5 Experiments
评估指标
我们使用两个指标来评估模型性能,这两个指标分别衡量任务完成情况和部分完成情况。
- 成功率 (SR):模型在 3 分钟时限内完成所有任务步骤的试验比例。该主要指标反映了模型在实际应用中的可行性。
- 进度评分 (PS):通过跟踪模型在各个子任务检查点的进度来衡量部分任务完成情况:例如,在 6 步“叠碗”任务中,如果模型完成了步骤 1-4 但在步骤 5 失败,则得分为 4/6 ≈ 0.67。该诊断指标可以突出显示失败模式,并奖励部分成功。
终止标准:试验在以下情况下结束:(1) 连续三个子任务失败,或 (2) 发生安全关键事件(例如碰撞)。进度评分基于终止前完成的子任务。我们报告了 100 个任务的总体成功率和进度评分,并按机器人类型对每个平台的指标进行分层,以评估跨平台泛化能力。
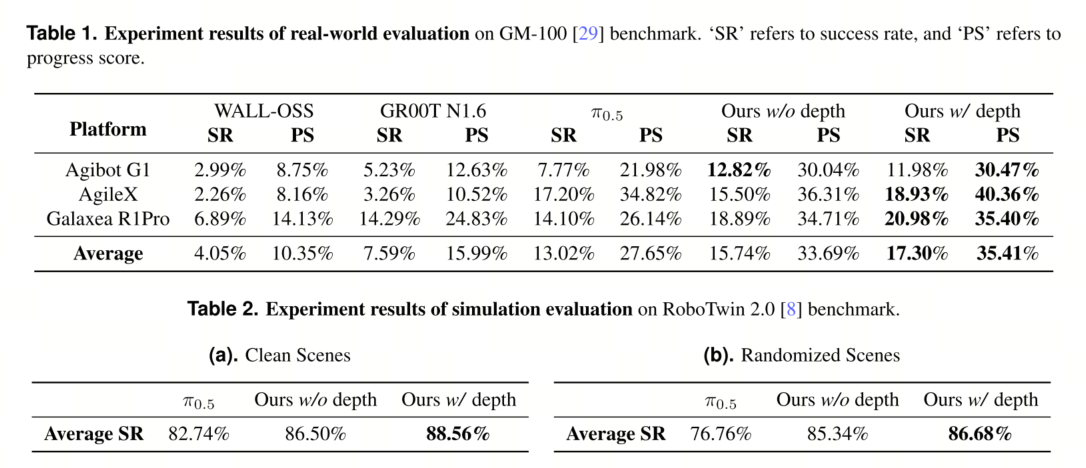
5.2 实际基准测试对比
如表1所示,我们将我们提出的两种LingBot-VLA变体与三个强大的基线模型在三个平台上进行了比较。
在所有平台上,不包含深度信息的LingBot-VLA在空间分辨率(SR)和性能评分(PS)指标上均显著优于WALL-OSS和GR00T N1.6。通过整合基于深度的空间信息,包含深度信息的LingBot-VLA在三个平台上的SR平均提升了4.28%,PS平均提升了7.76%(相对于π0.5)。值得注意的是,GR00T N1.6在Agibot G1和AgileX平台上的表现一般,但在Galaxea R1Pro平台上,其SR和PS与π0.5相当。这是因为GR00T N1.6在预训练过程中大量使用了Galaxea R1Pro数据,表明预训练可以显著提升模型在结构相似性较高的下游任务上的性能。完整的详细测试结果见附录表S1-S6。 5.3 仿真基准测试对比
表 2 中,我们评估了模型在 RoboTwin 2.0 套件中 50 个代表性操作任务上的仿真性能。每个模型均从预训练检查点出发,并在 RoboTwin 数据集上进行进一步微调。为了评估多任务泛化能力,我们使用 2500 个来自干净场景的演示数据(每个任务 50 个)和 25000 个来自高度随机场景的演示数据(每个任务 500 个)训练所有模型。随机化因素包括不同的背景、桌面杂物、桌面高度扰动和不同的光照条件。与 π0.5 基线模型相比,LingBot-VLA 在 RoboTwin 2.0 多任务设置中表现出显著的进步。具体而言,不考虑深度信息的 LingBot-VLA 在干净环境中的绝对成功率提高了 3.76% 以上,在随机场景中提高了 8.58% 以上。通过采用可学习的基于查询的对齐方式,LingBot-VLA 能够有效地从 LingBot-Depth 模型中提取丰富的空间先验信息,并整合了深度信息。在干净配置和随机配置下,该方法分别比基线模型提升了 5.82% 和 9.92%。详细结果请参见附录表 S7。
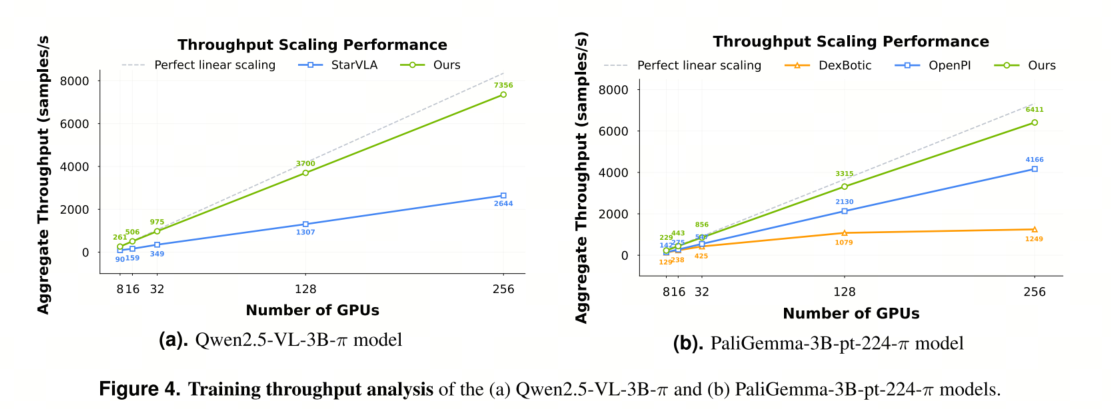
训练吞吐量分析
为了全面评估不同框架下 VLA 模型的训练效率,我们选择了三个开源代码库(即 StarVLA、Dexbotic 和 OpenPI)作为基准进行比较。为了确保公平比较,所有实验均在 Libero 数据集上进行,并使用标准化的 π 型模型架构。
考虑到不同代码库中 VLM 实现的差异,我们在自己的代码库中复现了 Qwen2.5-VL-3B-π 和 PaliGemma-3B-pt-224-π 模型,以便与基准模型进行直接对比。关于训练配置,所有实验的本地批大小均标准化为 32。
值得注意的是,StarVLA 和 Dexbotic 默认使用 ZeRO 进行分布式训练,而我们的代码库采用的是类似的 FSDP2 策略。相比之下,OpenPI 使用 DDP,其通信开销更低。我们采用样本吞吐量(样本/秒)作为主要评估指标。图 4a 和 4b 分别展示了我们的代码库与 Qwen2.5-VL-3B-π 和 PaliGemma-3B-pt-224-π 模型基线方法的训练效率对比。结果表明,我们的代码库在两种模型配置下均实现了最快的训练速度。此外,图中还详细展示了在 8、16、32、128 和 256 个 GPU 配置下的训练吞吐量,以及理论线性扩展极限。数据表明,我们的解决方案不仅提供了卓越的吞吐量,而且随着 GPU 数量的增加,其扩展效率也表现出色,与理论极限高度吻合。
5.5 Ablation Studies
5.5.1 Scaling Experiments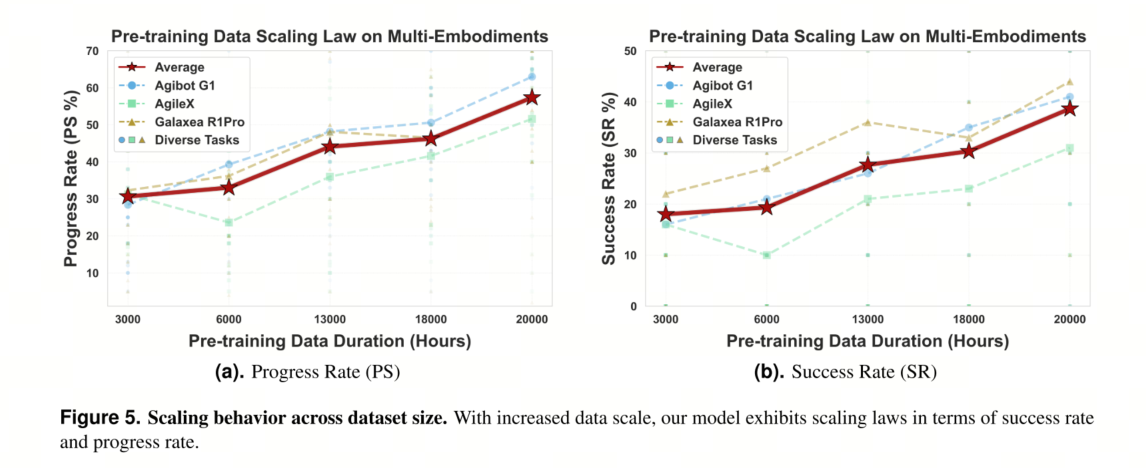
为了评估预训练数据的扩展规律,我们从基准数据集中选取了 25 个具有代表性的任务子集进行实验。如图 5a 和 5b 所示,随着预训练数据时长从 3,000 小时增加到 20,000 小时,进度率和成功率均呈现持续上升的趋势。这表明,扩展真实世界的预训练数据有助于提高模型在各种下游任务和实例中的泛化能力和性能。此外,三个实例(即 Agibot G1、AgileX 和 Galaxea R1Pro)的个体趋势与整体性能基本一致,表明观察到的扩展规律具有鲁棒性,并非特定于某个平台。这些结果验证了我们提出的扩展方法在增强通用策略能力方面的有效性。
5.5.2 数据高效分析
遵循大规模真实世界基准测试协议,我们从GM-100数据集中选取了八个具有代表性的任务,在Agibot G1平台上进行了数据高效的训练后实验。如图6所示,在每个任务仅使用80个演示数据的情况下,LingBot-VLA在进度率和成功率方面均优于使用全部130个演示数据的π0.5。值得注意的是,随着训练后数据量的增加,LingBot-VLA与π0.5之间的性能差距显著扩大,展现出卓越的数据效率和可扩展性。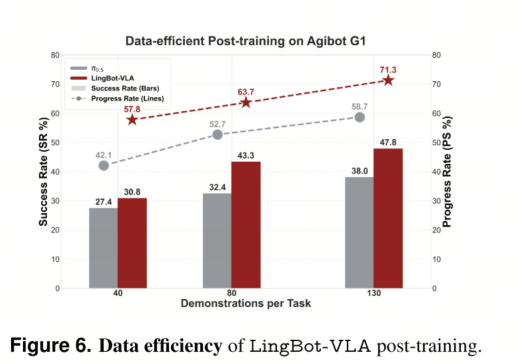
6 结论
我们提出了 LingBot-VLA,这是一个基础模型,它通过大规模真实世界数据和优化的代码库实现了卓越的泛化能力和训练效率。我们在 100 个任务上的全面评估表明,我们的模型明显优于竞争对手,展现了其强大的性能和广泛的泛化能力。为了促进开放科学,我们公开了代码、模型和基准测试数据。未来的研究将着重于通过整合单臂和移动机器人数据来扩展模型的通用性,从而为在不受约束的环境中实现更多样化和移动的操作能力铺平道路。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)