小白必看:轻松掌握大模型、Function Calling、MCP、Agent,让AI真正帮你干活!
全程大白话,不用懂代码
看完你就明白:大模型、Function Calling、MCP、Agent到底是什么,以及怎么让AI真正帮你干活、解决问题。
你有没有过这种体验?
你问AI:“苹果怎么样?”
它知道你想买手机,还是想吃水果。
但你让它:“帮我订一张明天去北京最便宜的机票。”
它要么编一个不存在的航班,要么说“我无法完成这个操作”。
为什么AI既能听懂“苹果”,又显得这么“蠢”?
真相是:你用的还只是一个“会聊天的大模型”,而别人已经组装出了“会干活的Agent”。
今天这篇文章,我帮你把背后的门道彻底讲透。
读完你不仅能看懂,还能自己上手,让AI变成你的得力助手。
一、先搞懂大模型的底层逻辑
它到底怎么读懂你的话?
大模型的工作流程,就三步:
用户输入 → 模型计算 → 输出结果。
1.1 你的话怎么变成模型能懂的数字?
你打进去的文字叫Prompt。
模型不认汉字,要做两步转化:
1️⃣ 分词(Token化)
“我想吃苹果” → “我 / 想 / 吃 / 苹果”
每个最小单位叫一个Token。
2️⃣ 向量化
给每个Token打上一堆“属性标签”。
比如“苹果”的向量有两坨:
[水果,红色,甜,3块钱一斤]
[手机,数码,5000块钱一台]
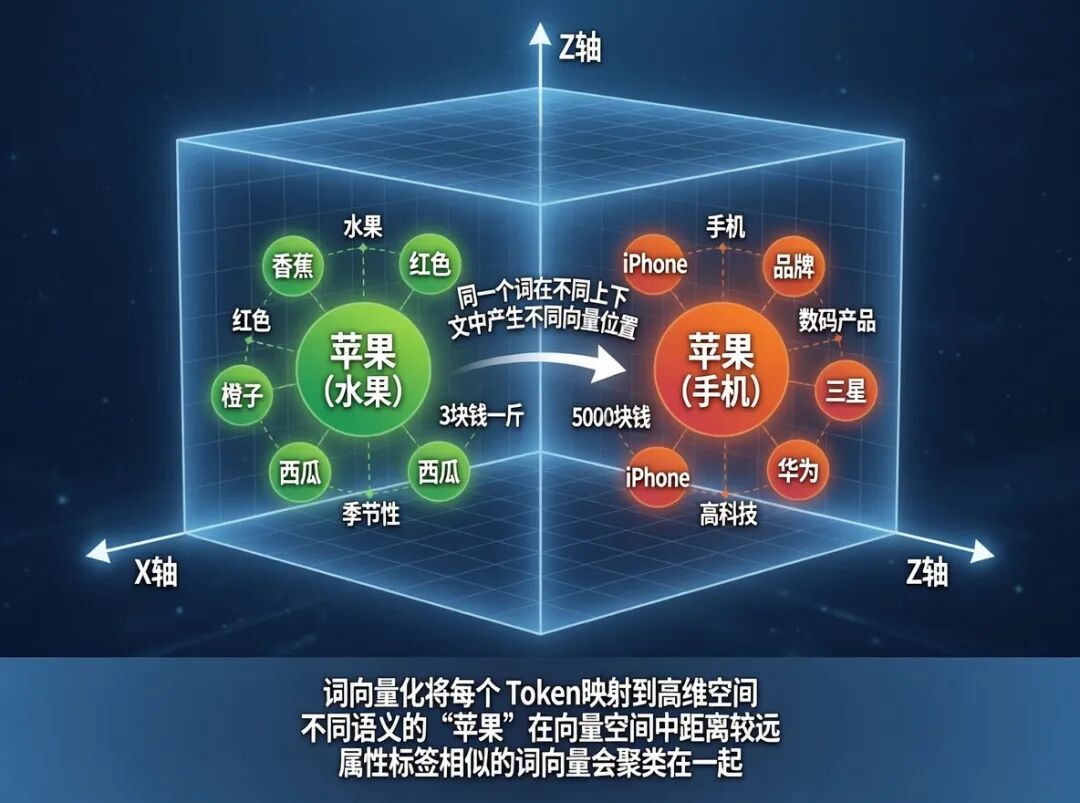
属性越接近的词,“距离”越近。
大模型就是靠这个理解词义的。
1.2 大模型怎么“思考”?
Transformer层 + 注意力机制
模型有几十到上百层,每一层像一个加工车间:
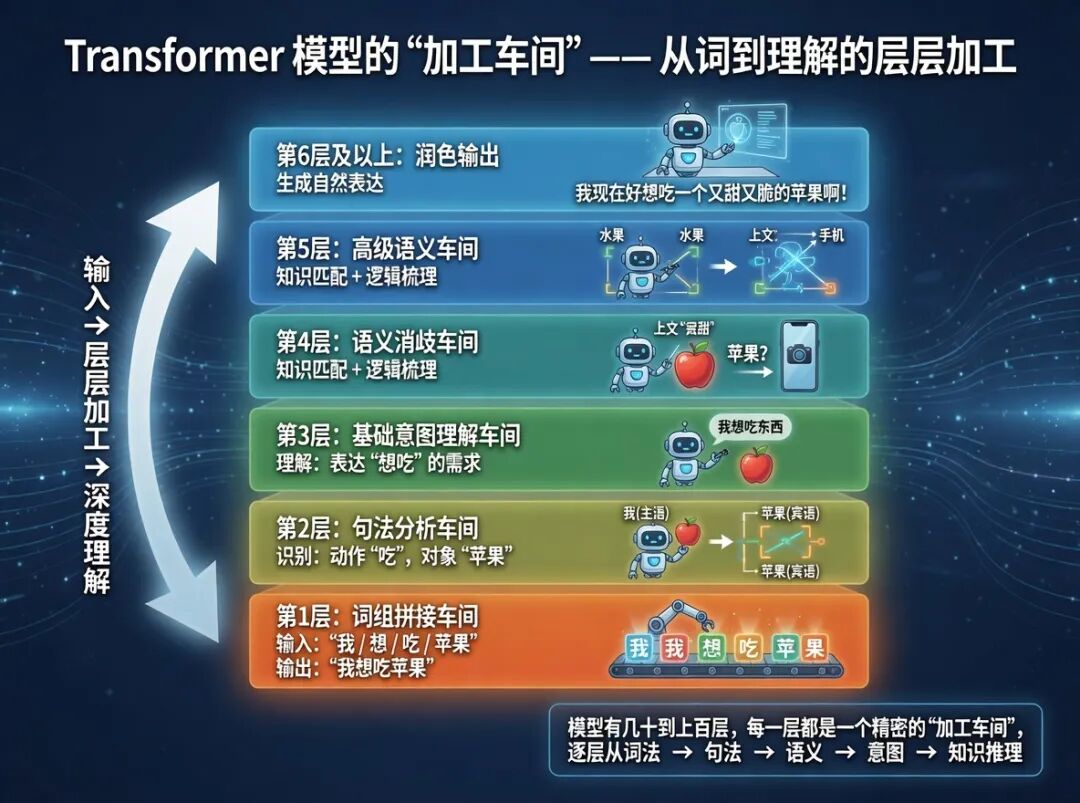
第1层:拼出词组(“我/想/吃/苹果” → “我想吃苹果”)
第2层:找出主谓宾(动作“吃”,对象“苹果”)
第3层:理解基础意图(表达想吃的需求)
第4层:消歧(上文有“拍照”→苹果是手机;有“很甜”→苹果是水果)
第5层以上:匹配知识、梳理逻辑、润色表达
层数越多,模型越“聪明”。
👉 最核心的“自注意力机制”是什么?
就是让模型分辨“苹果是手机还是水果”的那个魔法。
它靠三个东西:
Query:当前词“苹果”的属性
Key:上下文其他词,比如“拍照好看”或“很甜”
Value:匹配度权重
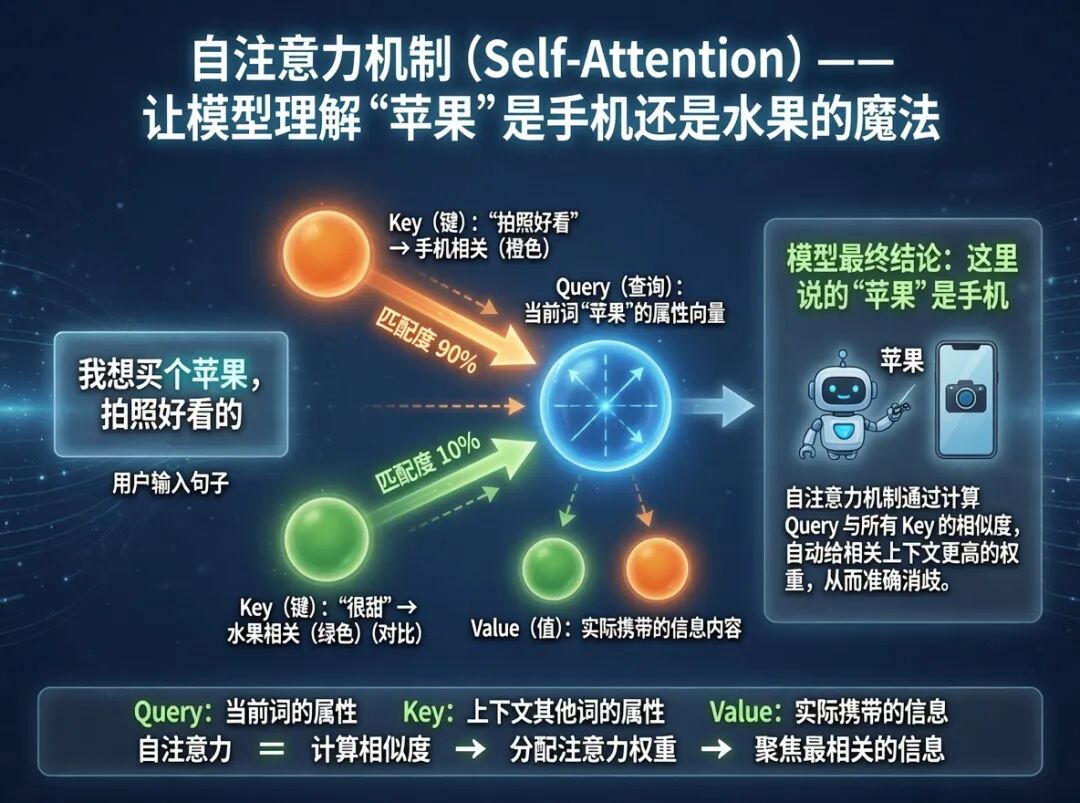
你说“我想买个苹果,拍照好看的”:
苹果 vs 拍照 → 匹配度90%,权重给“苹果手机”
苹果 vs 甜 → 匹配度10%,权重给“水果苹果”
结果:模型知道你说的是手机。
1.3 大模型怎么输出答案?
一个字一个字“猜概率”
大模型本质上是个概率预测机。
你说“我想吃”,它会算:
下一个字是“饭”的概率30%
是“苹果”的概率20%
是“火锅”的概率15%
然后选概率最高的组合,输出给你。
1.4 划重点:大模型天生有三个解决不了的毛病
别怪它蠢,这是设计上的硬伤。
不能自主思考、决策
它只会猜概率,没有判断力。
“我有10万块买哪只股票能赚钱?” → 只能给通用建议,不可能真告诉你买哪只。
不能自己拆解复杂目标
“组织一场10个人的部门团建” → 只能给个通用模板,不会拆成“统计人数→查场地→做预算→发通知”这些步骤。
只能输出文字,没有“手”
“帮我买10斤红富士寄到家” → 只会讲怎么挑苹果,不会真的打开淘宝下单。
只靠大模型,永远只能“聊天”,不能“干活”。
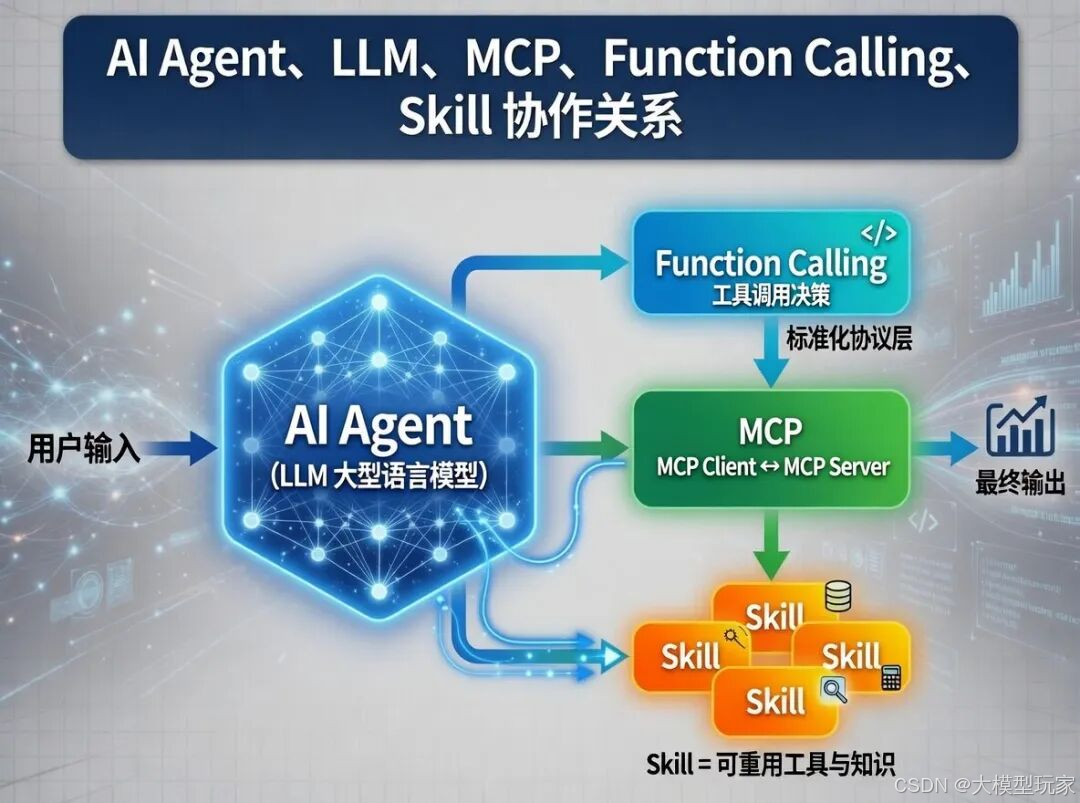
二、Function Calling
给大模型配个“跑腿小弟”
既然大模型只会动嘴,那就给它配个跑腿的——Function Calling(函数调用)。
2.1 什么是Function Calling?
大模型 = 老板:负责说“我要干什么”
函数 = 跑腿小弟:负责真的去干
例子:
你问“明天北京天气怎么样?”
➡️ 老板(大模型)对小弟说:“调用查天气API,参数‘北京’”
➡️ 小弟拿去查,返回“晴,25°C”
➡️ 老板整理成人话告诉你。
你问“帮我订明天去北京最便宜的机票”
➡️ 老板说:“调用订票API,参数‘明天、北京、最便宜’”
➡️ 小弟执行完,把订单号给你。
✅ 你自己就能给大模型写“小弟”
这个小弟能干什么,完全由你定义。
你可以写:查天气、查订单、操作Excel、甚至控制智能家电。
只需要告诉大模型:函数叫什么、做什么用、需要什么参数。
大模型会在合适的时候自动调用它。
2.2 Function Calling 的先天缺陷
这么好用,但有两个问题:
默认只能串行干活,一次干一个
你让它“同时查北京、上海、广州的天气”
只能先查北京 → 等结果 → 再查上海 → 等结果 → 再查广州。
效率很低。
虽然有部分大模型做了并行扩展,但不是通用标准。
不通用,没有统一标准
OpenAI的FC、Anthropic的FC、通义的FC,参数格式都不一样。
你为OpenAI写的函数,换到通义就得重写一遍。
适配成本很高。
三、MCP
给所有大模型的小弟定个“统一规矩”
为了解决“不通用”的问题,Anthropic(开发Claude的那家公司)牵头搞了一个统一协议——MCP(模型上下文协议)。
3.1 MCP是什么?—— “统一插座标准”
以前不同品牌家电的插头不一样。
现在统一了:不管格力空调还是美的冰箱,插到同一个国标插座上就能用。
MCP就是大模型和工具之间的“统一插座”。
你按MCP标准写一次工具,所有支持MCP的大模型(Claude、GPT、通义等)都能直接用,不用每个模型适配一遍。
MCP分两部分:
MCP服务端:你写的各种工具
MCP客户端:每个大模型那边的适配层
3.2 MCP vs Function Calling 一张表看懂
| 对比项 | Function Calling | MCP |
|---|---|---|
| 作用 | 让大模型调用外部工具 | 让大模型调用外部工具 |
| 通用性 | ❌ 不通用,各厂商各自为战 | ✅ 通用,一次编写所有模型都能用 |
| 复杂度 | 简单,适合单工具 | 复杂,支持多工具并行、跨模型 |
| 缺点 | 适配成本高 | 会多占一点Token |
| 一句话 | 各自为战的“手” | 标准化的“万能插座” |
MCP = 标准化 + 升级版的Function Calling
四、Agent Skills
给大模型装个“专业大脑”
MCP解决了“手”的问题,能干活了。
但还有一个问题:大模型的专业知识不够用。
比如你要做个法律AI,总不能把整本民法典都塞进每次对话的prompt里吧?
这就需要Agent Skills。
4.1 什么是Agent Skills?
你可以理解为可插拔的专业知识库。
把某个领域的专业知识、经验、回答逻辑整理成一个独立模块。
大模型需要时加载进来,不用时就放一边,不占上下文空间。
法律Skill:民法典条文、司法案例
医学Skill:疾病、药品知识
电商Skill:产品规则、售后话术
4.2 Skill的“三级加载”:为什么装50个也不怕?
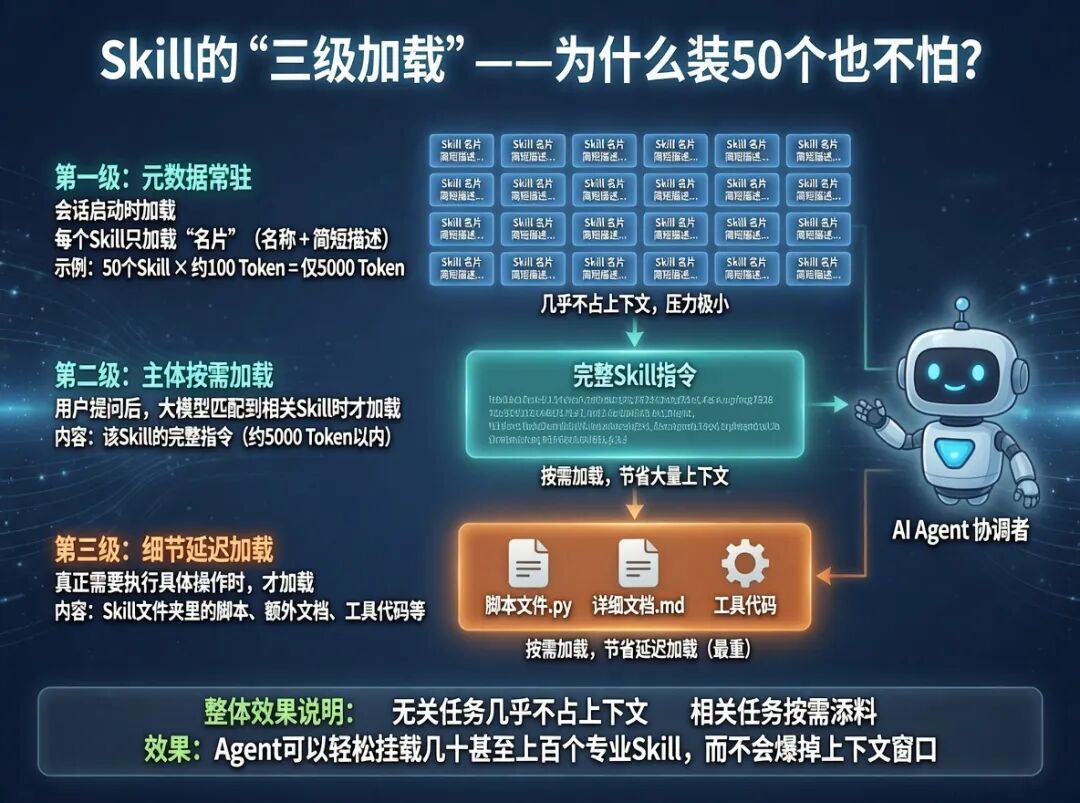
大模型不是一次性把所有Skill都读进去,而是分三步按需加载:
第一级(元数据常驻)
会话启动时,只加载每个Skill的“名片”(名称+描述),每个约100 Token。50个Skill也只占5000 Token,毫无压力。
第二级(主体按需)
用户提问后,大模型匹配到相关Skill,才加载该Skill的完整指令(约5000 Token内)。
第三级(细节延迟)
需要执行具体操作时,才调用Skill文件夹里的脚本或额外文档。
效果:无关任务几乎不占上下文,相关任务按需添料。这就是Agent能挂载几十个专业大脑而不爆上下文的秘密。
4.3 一个Skill文件夹长什么样?
my-skill/
├── SKILL.md # 核心文件,包含元数据和主体指令
├── script.py # 可执行脚本(第三级调用)
└── reference.md # 额外资料(按需读取)
SKILL.md结构:
---
name: 法律咨询
description: 回答民法典相关问题,提供法律建议
---
这里是详细的指令、示例、引用链接...
Agent会自动扫描包含SKILL.md的文件夹,把它识别为一个可用技能。
4.4 Skill 和 MCP 的区别(别搞混)
MCP = 手:调用外部系统,查数据、发指令(工具)
Skill = 专业大脑:存储领域知识、回答逻辑(知识库)
👉 电商客服AI的例子:
- MCP:查订单、查物流
- 电商Skill:产品知识、售后规则
两者配合,才是真客服。
五、Agent
把大脑、手、专业知识拼起来,就是能帮你干活的AI
现在我们把前面所有东西拼在一起:
大模型 = 大脑:理解意图、做决策、规划步骤
MCP = 手:调用工具、查数据、操作外部系统
Skills = 专业知识:提供领域知识和回答逻辑
这个完整的整体,就是现在最火的Agent(智能体)。
普通大模型只会和你聊天
Agent会帮你干活
几个真实的例子
🥟 饺子馆老板的Agent
用户问:“今天排队要多久?”
Agent用MCP查排队数据 → 用餐饮Skill回复 → “周末大概40分钟,扫码取号”
老板不用管。
✍️ 内容生产Agent
你吩咐:“写一篇AI Agent的公众号文章”
Agent爬取新闻 → 用写作模板生成文章 → 调用公众号工具推送草稿箱
全程不用你动手。
📅 个人助理Agent
你说:“订明天去北京最便宜的机票,同步日历,设闹钟”
Agent拆成三个任务并行执行 → 最后告诉你“搞定”
这就是Agent和普通大模型的本质区别。
六、多智能体协作
一个AI团队,比单个AI强10倍
如果一个Agent已经很能干了,那把多个不同能力的Agent组合起来呢?
这就是多智能体协作,相当于给你搭了一个AI团队。
举个例子:做一个自媒体内容团队
内容策划Agent:想选题、做大纲
文案写作Agent:写文章
排版发布Agent:排版、发公众号
数据统计Agent:跟踪阅读量、做复盘
你只说一句:“这周写两篇AI文章,目标阅读1万。”
团队自动分工执行,你完全不用管过程。
6.1 为什么需要多Agent协作?
单Agent有三个硬伤:串行阻塞、知识耦合、脆弱(一挂全挂)。
多Agent团队则能做到:并行干活(效率↑300%+)、容错(可用性99.9%+)、无限扩展(加Agent就行)。
6.2 多智能体协作架构图
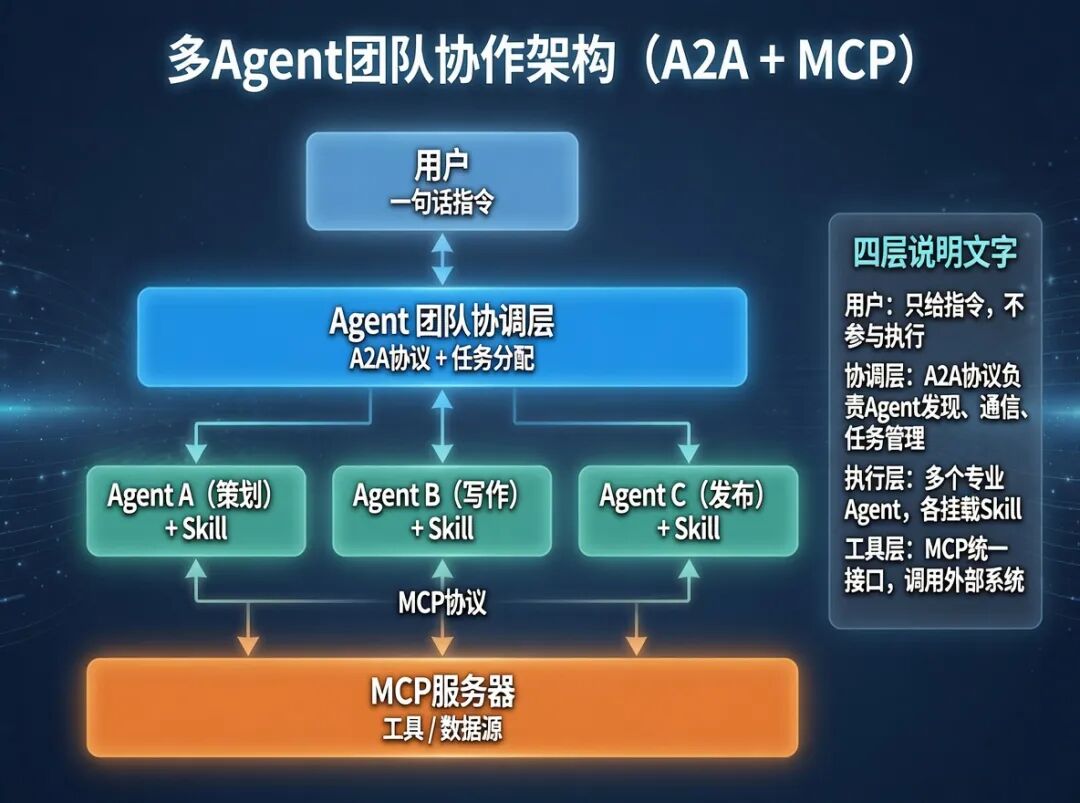
图中四层说明:
用户:只给指令,不参与执行
协调层:A2A协议负责Agent发现、通信、任务管理
执行层:多个专业Agent,各挂Skill
工具层:MCP统一接口,调用外部系统
6.3 多Agent协作的“通用语言”:A2A协议
要让不同厂商的Agent协作,需要统一通信标准——这就是A2A协议(Agent-to-Agent)。
一句话定位:MCP是连工具的“USB-C”,A2A是Agent之间的“蓝牙”。
A2A定义了三个核心构件:
Agent Card(名片):JSON格式,描述Agent的能力、地址、认证方式。Agent之间靠它相互发现。
Message(消息):单轮通信,可承载文本、文件、结构化数据。
Task(任务):有状态的长任务管理,支持进度跟踪和结果交付。
目前A2A已获50+家技术伙伴支持,被Linux基金会托管。
6.4 三种协作模式
| 模式 | 特点 | 适用场景 |
|---|---|---|
| 层级式 | 一个主Agent分配任务 | 有明确指挥链 |
| 平等式 | 所有Agent地位平等 | 去中心化协作 |
| 混合式 | 两者结合 | 最常见 |
核心机制:分工 + 通信 + 冲突解决
分工:拆解任务,分配给最合适的专业Agent(如ChatDev模拟软件公司团队)
通信:A2A协议(Agent Card发现 + Message即时沟通 + Task长任务追踪)
冲突解决:优先级裁决、协商机制
6.5 单Agent vs 多Agent
| 维度 | 单Agent | 多Agent系统 |
|---|---|---|
| 任务复杂度 | 低(≤3步) | 高(>5步) |
| 处理模式 | 串行 | 并行,效率↑300%+ |
| 容错性 | 低(一挂全挂) | 高(可用性99.9%+) |
| 能力扩展 | 靠更新模型 | 加个新Agent就行 |
| 开发成本 | 低 | 较高 |
| 响应延迟 | 低 | 较高(10%-30%协调开销) |
写在最后
大模型发展到今天,早就不是只能用来聊天的玩具了。
这一路走来:
Function Calling(配跑腿小弟)
MCP(统一插座)
Skills(装专业大脑)
Agent(完整员工)
多Agent协作(团队干活)
本质就是让AI从“会动嘴”变成“会干活”再到“会协作”。
以前,你要做一个能干活的AI,得懂代码、懂模型、懂服务器,成本几十万。
现在,有了MCP和Skill标准,不用懂代码,拖拖拽拽就能搭出自己的Agent。
未来1-2年,每个小商家、小团队、普通人,
都可以拥有自己的专属Agent团队,让AI替你分担繁琐重复劳动。
这不是炒作“红利”,而是正在发生的技术普及。越早理解,越早上手。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献73条内容
已为社区贡献73条内容

所有评论(0)