读 GBrain 源码:YC CEO 给 agent 造的“长期大脑“是怎么搭起来的
读 GBrain 源码:YC CEO 给 agent 造的"长期大脑"是怎么搭起来的

图 1:GBrain 全景速览 —— 17,888 pages / P@5 49.1% / 34 skills / 12 天写完
文章目录
- 读 GBrain 源码:YC CEO 给 agent 造的"长期大脑"是怎么搭起来的
摘要:GBrain 用 markdown wikilink 当抽取信号、把图谱写进 page、再用 RRF 把三路信号融在一起,做出了一个 zero-LLM 抽取、$0/run 的 agent 长期记忆。
1. 你的 AI agent 为什么记不住事
写过 agent 的人都知道一个尴尬:模型聊到第三十轮就开始装失忆,把第三轮提到的"那位投了我的人"忘得一干二净。
通常的反应是开大上下文窗:Sonnet 4.6 给 200K、Opus 4.7 给 1M。问题是 1M token 既塞不下三年会议纪要、也撑不住每次 query 重读。checkpoint 也不解决 —— 帮你重启 session,下次重启 agent 仍是失忆者。
agent 要的是会越用越聪明的外脑:写得进、搜得回、用得起 —— 每次 retrieval 都跑 Opus 当抽取器烧不起。
Y Combinator CEO Garry Tan 在 12 天里把这套东西写出来了(README L5)。这就是 GBrain,garrytan/gbrain,MIT 协议,截至 2026-05-18 最新版本 v0.35.7.0(commit 1dadd9ed)。它跑在 Garry 自己的 OpenClaw 和 Hermes agent 后面,已累计:
| 数据 | 数值 | 出处 |
|---|---|---|
| 总 page 数 | 17,888 | README L5 |
| 人物 page | 4,383 | README L5 |
| 公司 page | 723 | README L5 |
| 定时任务 | 21 cron jobs | README L5 |
| Skill 数 | 34 个 fat-markdown skills | README L9 / L173 |
| 全新机器装好 brain | 30 分钟 | README L9 |
这不是 toy benchmark,是 YC CEO 真实日常在用的东西,值得拆开看一眼。
2. 大局观:30 秒讲完 GBrain
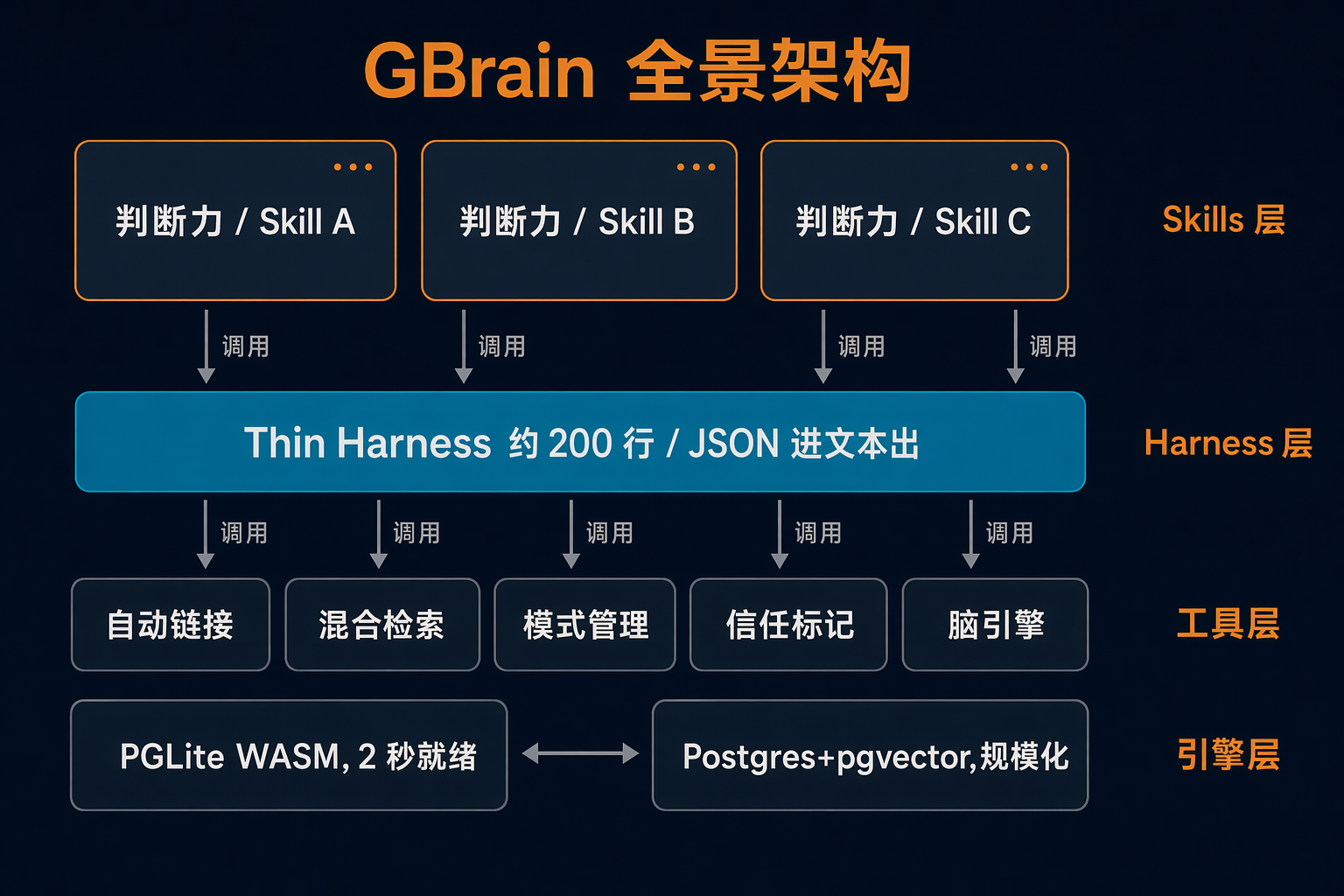
图 2:GBrain 全景架构 —— markdown 输入 → 三路索引 → hybrid search → 34 个 fat skills
GBrain 的设计哲学一句话讲完:“Push intelligence UP into skills. Push execution DOWN into deterministic tooling. Keep the harness THIN.”(docs/ethos/THIN_HARNESS_FAT_SKILLS.md)
工程语言上是三层结构:上层 34 个 markdown fat skill 负责判断力(什么时候搜、搜什么、怎么讲),中层约 200 行 thin CLI harness 只做 JSON 进文本出,下层是 QueryDB / ReadDoc / Search / Timeline 这些确定性工具,没有 LLM 介入。
存储层有两条 axis:brain 一个用户挂多个(work / personal),source 一个 brain 多个 source repo。两条 axis 在 v0.18.0 sources、v0.19.0 mounts 之后定型。
写入路径直白:markdown 写到 page 后系统自动抽 wikilink + frontmatter,节点和边写进 graph,段落 chunk 后写进 vector + BM25。三路索引就这样长出来,不需要单独 LLM 抽取 pipeline。
读取路径上 query 来了并行打两路 ranker:vector 语义和 BM25 关键词;RRF 融合 + 0.7/0.3 加权 cosine 复评后,graph backlink 作为第三路 boost 给已有结果加权放大。
存储后端做了个聪明抽象:BrainEngine 是共享 interface(engine.ts:478,定义贯穿到 L1408),底下挂 PGLite 或 Postgres。PGLite 是 Postgres 17.5 编译的 WASM,2 秒起一个本地 brain;规模化再切 Postgres+pgvector(engine-factory.ts:1-27)。两个 engine 走完全相同的 SQL(tsvector + pgvector HNSW + pg_trgm + recursive CTE),差别只在并发。
核心目标一句话:让"加一颗长期记忆"的边际成本接近零,既不接外部向量库、也不烧每次 retrieval 的 LLM。下面按机制拆开。
3. 自动建链:page 写就长出图谱
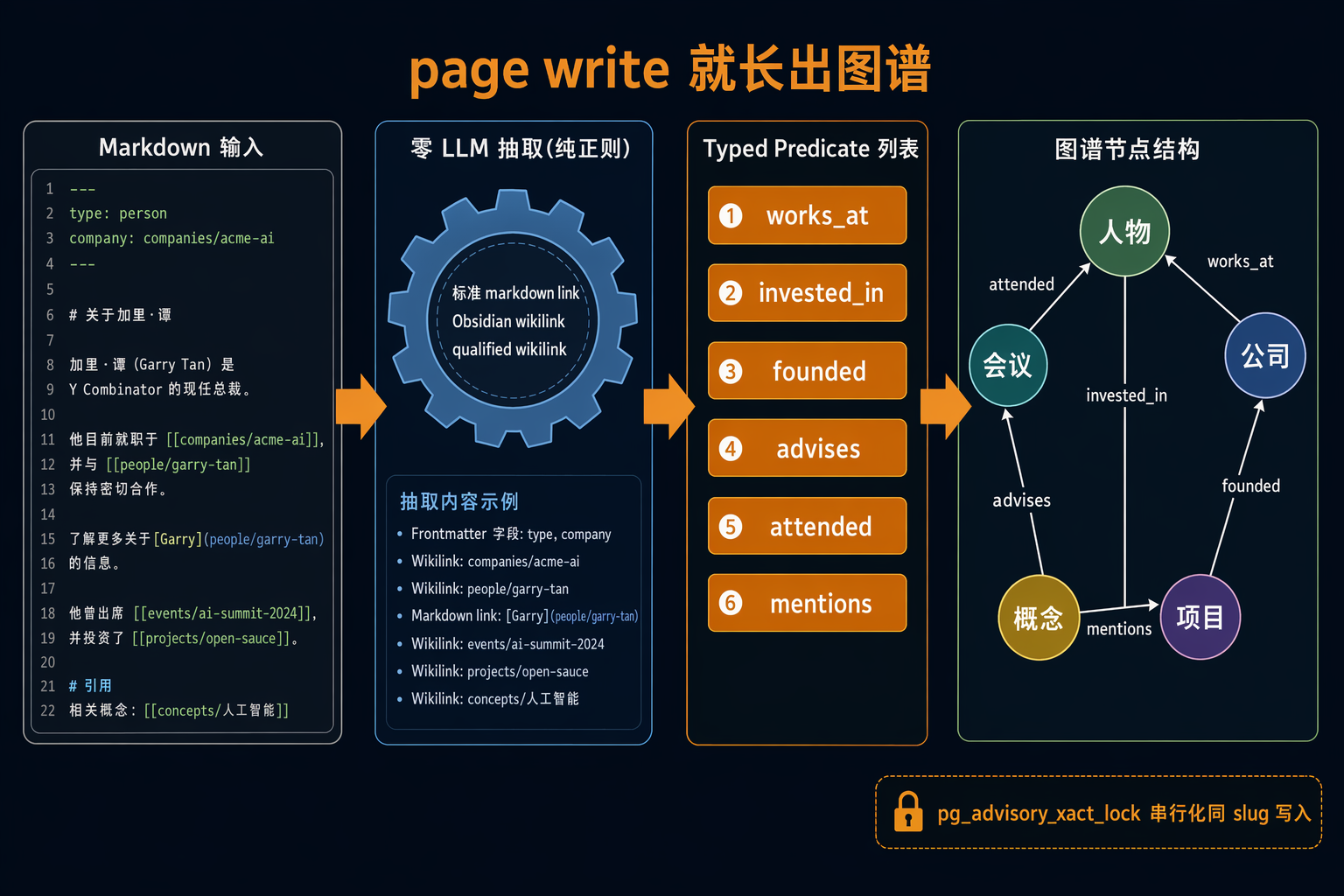
图 3:put_page → 自动抽取 → 图谱自建链路
传统 RAG 的痛点是:vector 搜得到"相似"但搜不到"关系"。"who works at Acme AI?"靠语义相似命中率惨烈。
知识图谱可以解,但代价是要维护一份图谱:写 LLM 抽取 pipeline 持续跑(贵且慢)、手动维护(不可能)、定期 batch 抽取(stale)—— 三条路在 17K 页 / 4K 人的负载下都崩。
GBrain 的回答让人会心一笑:图谱不是另外维护的,是写出来的。
3.1 page write 的 post-hook
put_page 写入后触发 auto-link post-hook:
// src/core/operations.ts:590-618
if (ctx.remote !== false && !trustedWorkspace) {
autoLinks = { skipped: 'remote' };
autoTimeline = { skipped: 'remote' };
} else if (result.parsedPage) {
try {
const enabled = await isAutoLinkEnabled(ctx.engine);
if (enabled) {
autoLinks = await runAutoLink(ctx.engine, slug, result.parsedPage,
ctx.sourceId ? { sourceId: ctx.sourceId } : undefined);
}
} catch (e) {
autoLinks = { error: e instanceof Error ? e.message : String(e) };
}
}
三件事:先判 trust(第 6 章详谈),再判 feature flag,最后调 runAutoLink —— 事务 + 调谐:
// src/core/operations.ts:743-822
async function runAutoLink(engine, slug, parsed, opts) {
const fullContent = parsed.compiled_truth + '\n' + parsed.timeline;
const resolver = makeResolver(engine, { mode: 'live' });
const { candidates, unresolved } = await extractPageLinks(
slug, fullContent, parsed.frontmatter, parsed.type, resolver,
);
// ... reconcile in a transaction with advisory lock
await tx.executeRaw(`SELECT pg_advisory_xact_lock(hashtext($1)::bigint)`,
[`auto_link:${slug}`]);
}
注意 pg_advisory_xact_lock,key 是 auto_link:<slug> 的 hash —— 同一 slug 的 reconcile 在事务级串行化,避开"两 page 同时写、互相踩"的并发坑。
3.2 零 LLM 抽取:正则吃 markdown
最有意思的设计藏在 link-extraction.ts 开头注释里:文件被标记为 “PURE (no DB access)”(第 9 行)。抽取没有任何 LLM 调用,纯正则:
// src/core/link-extraction.ts:46-91
const DIR_PATTERN = '(?:people|companies|meetings|concepts|deal|civic|project|' +
'projects|source|media|yc|tech|finance|personal|openclaw|entities)';
// Markdown link: [Name](people/slug)
const ENTITY_REF_RE = new RegExp(
`\\[([^\\]]+)\\]\\((?:\\.\\.\\/)*(${DIR_PATTERN}\\/[^)\\s]+?)(?:\\.md)?\\)`, 'g');
// Obsidian wikilink: [[people/slug]] or [[people/slug|Display]]
const WIKILINK_RE = new RegExp(
`\\[\\[(${DIR_PATTERN}\\/[^|\\]#]+?)(?:#[^|\\]]*?)?(?:\\|([^\\]]+?))?\\]\\]`, 'g');
// v0.17 qualified wikilink: [[source-id:dir/slug]]
const QUALIFIED_WIKILINK_RE = new RegExp(
`\\[\\[([a-z0-9](?:[a-z0-9-]{0,30}[a-z0-9])?):(${DIR_PATTERN}\\/[^|\\]#]+?)...\\]\\]`, 'g');
三种格式:标准 markdown link 给人看,Obsidian wikilink 适合编辑器 graph view,qualified wikilink(v0.17)跨 source 引用。抽取前 stripCodeBlocks() 把代码块替换成等长空白,避免误抓。
3.3 typed predicates:让边带语义
光抽出"A 链到 B"还不够,得知道是什么关系。GBrain 用 deterministic regex 推 12 种 typed predicate:
// src/core/link-extraction.ts:431-558
const WORKS_AT_RE = /\b(?:CEO of|CTO of|...|engineer at|...)\b/i;
const INVESTED_RE = /\b(?:invested in|invests in|led the (?:seed|Series|...)...)\b/i;
const FOUNDED_RE = /\b(?:founded|co-?founded|founder of|...)\b/i;
const ADVISES_RE = /\b(?:advises|advisor (?:to|at|...)...)\b/i;
export function inferLinkType(pageType, context, globalContext, targetSlug): string {
if ((pageType as string) === 'meeting') return 'attended';
if (FOUNDED_RE.test(context)) return 'founded';
if (INVESTED_RE.test(context)) return 'invested_in';
if (ADVISES_RE.test(context)) return 'advises';
if (WORKS_AT_RE.test(context)) return 'works_at';
if (pageType === 'person' && targetSlug?.startsWith('companies/')
&& PARTNER_ROLE_RE.test(globalContext ?? '')) {
return 'invested_in';
}
return 'mentions';
}
完整名单:attended / works_at / invested_in / founded / advises / mentions / image_of / yc_partner / led_round / discussed_in / related_to / source。兜底是 mentions,不丢信号。
3.4 frontmatter 也是图谱的一部分
v0.13 之后 frontmatter 字段也参与建图:
// src/core/link-extraction.ts:611-631
export const FRONTMATTER_LINK_MAP: FrontmatterFieldMapping[] = [
{ fields: ['company','companies'], pageType:'person', type:'works_at',
direction:'outgoing', dirHint:'companies' },
{ fields: ['founded'], pageType:'person', type:'founded',
direction:'outgoing', dirHint:'companies' },
{ fields: ['key_people'], pageType:'company', type:'works_at',
direction:'incoming', dirHint:'people' },
{ fields: ['investors'], pageType:'company', type:'invested_in',
direction:'incoming', dirHint: ['companies','funds','people'] },
{ fields: ['attendees'], pageType:'meeting', type:'attended',
direction:'incoming', dirHint:'people' },
];
写 person frontmatter company: companies/acme-ai,系统自动建 person --works_at--> acme-ai 边。direction 决定方向,dirHint 限制候选范围。
整套机制串起来:写一篇会议纪要,正文 wikilink 提到三个人、frontmatter 列了 attendees,系统在 save 瞬间就把"这场会有谁参加"的图谱边写好。下次问"上周三关于 deal X 的会有谁"backlink 直接命中。
心智模型:每个写 markdown 的动作都是一次免费 graph 抽取。代价是遵守 wikilink 风格,换来"agent 知道谁是谁"。
4. Hybrid Search:vector + BM25 + graph 怎么 blend
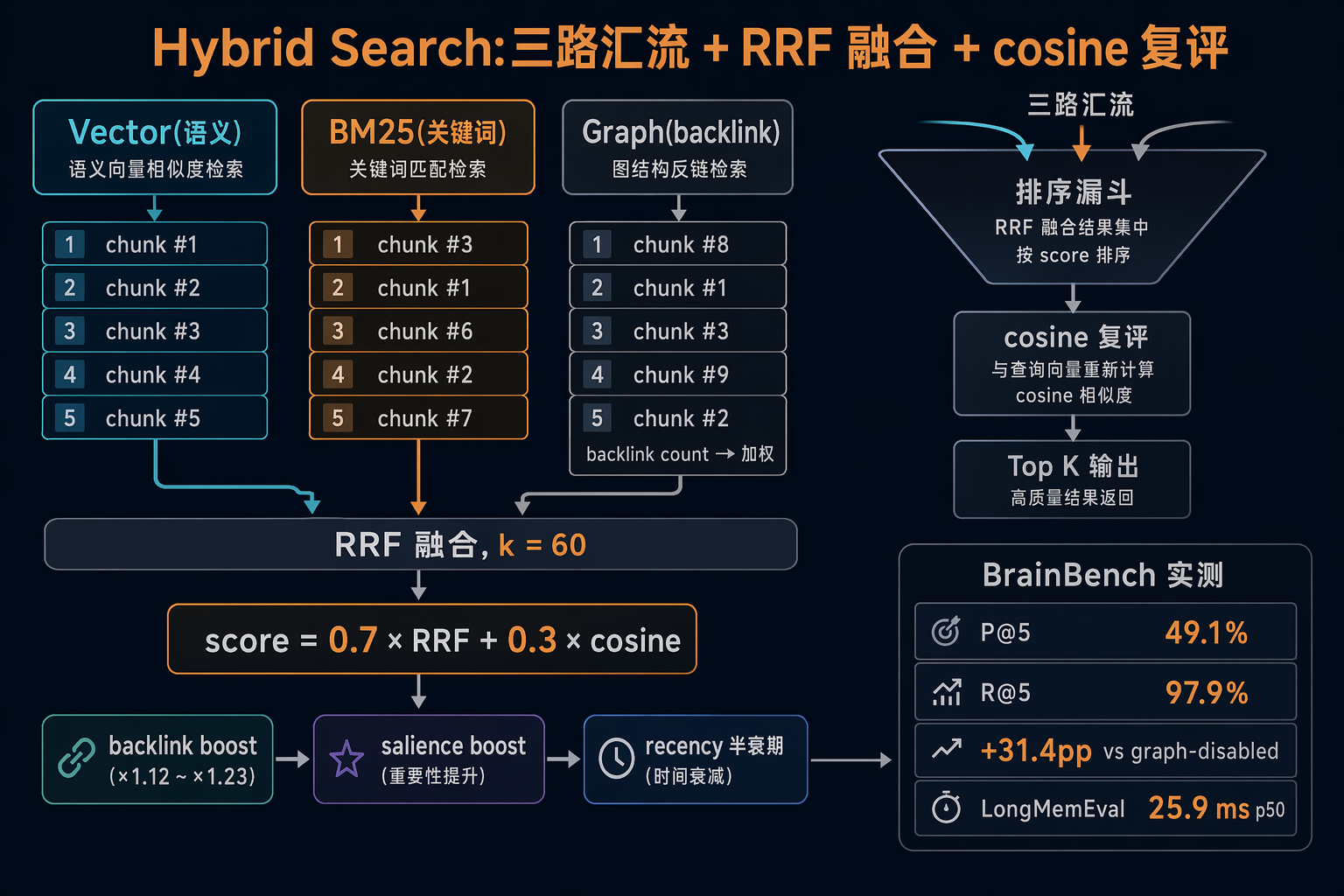
图 4:三路信号汇流 —— RRF 融合 + 0.7/0.3 加权复评 + backlink boost
4.1 RRF 融合
先把口径说清楚:标题里的"vector + BM25 + graph"严格说是两路 ranker(vector + BM25)+ 一路 boost(graph backlink)。前两路出 ranked list 进 RRF 融合,graph 不参与排名生成,而是在 RRF 出来后给已有结果加权放大。下文 4.2 / 4.3 都按这个口径展开。
入口 src/core/search/hybrid.ts 顶部把 pipeline 写清楚:
// src/core/search/hybrid.ts:1-10 / 32-43
// Pipeline: keyword + vector → RRF fusion → normalize → boost → cosine re-score → dedup
// RRF score = sum(1 / (60 + rank_in_list))
const RRF_K = 60; // line 32
const COMPILED_TRUTH_BOOST = 2.0; // line 33
const BACKLINK_BOOST_COEF = 0.05; // line 43
// Backlink boost: score *= (1 + 0.05 * log(1 + count))
// 10 backlinks → factor ~1.12; 100 backlinks → factor ~1.23
RRF(Reciprocal Rank Fusion)公式 1 / (k + rank),k = 60 是领域默认值。升级版 rrfFusionWeighted 给每路一个 per-list effective k:
// src/core/search/hybrid.ts:878-913
export function rrfFusionWeighted(
lists: Array<{ list: SearchResult[]; k: number }>, applyBoost = true,
): SearchResult[] {
for (const { list, k } of lists) {
for (let rank = 0; rank < list.length; rank++) {
const rrfScore = 1 / (k + rank); // per-list effective k
}
}
// normalize to 0-1 by max; boost compiled_truth 2.0x
}
query intent 不同 k 可以动:关键词清晰给 BM25 小 k,paraphrased 给 vector 小 k。
4.2 0.7 RRF + 0.3 cosine
RRF 出来后跑一次 cosine 复评,7:3 加权 blend:
// src/core/search/hybrid.ts:969-1006
const blended = 0.7 * normRrf + 0.3 * cosine;
RRF 给"在多路 ranked list 都靠前"的稳定信号,cosine 给"实际语义距离"。RRF 抑单路噪音,cosine 校准绝对位置;7:3 让 RRF 主导、cosine 当 tie-breaker。
4.3 Backlink boost
Graph 不再单独跑一路 ranking,而是在 RRF 出来后加权:
// src/core/search/hybrid.ts:63-76
export function applyBacklinkBoost(results, counts, floorThreshold): void {
for (const r of results) {
const count = counts.get(r.slug) ?? 0;
if (count > 0) {
r.score *= (1.0 + BACKLINK_BOOST_COEF * Math.log(1 + count));
}
}
}
BACKLINK_BOOST_COEF = 0.05,log scale。10 个 backlink 约 1.12x、100 个 1.23x。加太狠所有 query 都把热门 page 推到首位,丢 query relevance;这一档刚好不压过 query signal。
完整 post-fusion 还有 salience boost(k = 0.15 / 0.30)和 recency boost(half-life decay)。v0.35.6.0 起三阶段共享同一 floorThreshold,一次算完(hybrid.ts:235-295)。
4.4 BrainBench 数字
README L7 的 BrainBench 成绩(240-page Opus-generated rich-prose corpus):
| 指标 | GBrain v0.35.7.0 | graph-disabled variant | 差距 |
|---|---|---|---|
| P@5 | 49.1% | 未单独公布 † | +31.4pp |
| R@5 | 97.9% | — | — |
† README 只给了差值 +31.4pp,没给关掉 graph 那档的绝对值;17.7% 是减出来的、不是实验数据。
R@5 接近 100% 说明 top-5 几乎不漏命中,P@5 49.1% 说明 top-5 大约一半 highly relevant。+31.4pp 是同一 corpus、同一 ranking、只关掉 graph 信号的对比 —— 直接量化了"图谱信号本身的贡献"。LongMemEval 单题 25.9 ms p50(README L13,Apple Silicon),sub-100ms 出结果那一档。
5. Search Mode 三档:成本最大 25× 怎么花

图 5:3×3 cost matrix —— 三档 mode × 三个下游模型
5.1 源码值 vs README 简化值
// src/core/search/mode.ts:123-185
export const MODE_BUNDLES: Record<SearchMode, ModeBundle> = {
conservative: { tokenBudget: 4000, expansion: false, searchLimit: 10,
reranker_enabled: false, ... },
balanced: { tokenBudget: 12000, expansion: false, searchLimit: 25,
reranker_enabled: false, ... },
tokenmax: { tokenBudget: undefined, expansion: true, searchLimit: 50,
reranker_enabled: true,
reranker_model: 'zeroentropyai:zerank-2', ... },
};
export const DEFAULT_SEARCH_MODE: SearchMode = 'balanced';
| Mode | tokenBudget(源码) | tokenBudget(README) | searchLimit | expansion | reranker |
|---|---|---|---|---|---|
| conservative | 4000 | ~4K | 10 | off | off |
| balanced(默认) | 12000 | ~10K | 25 | off | off |
| tokenmax | undefined | ~20K | 50 | on | zerank-2 |
源码精确值、README 用 ~10K / ~20K 近似值便于沟通。两套受众,两组都给。
5.2 三档动了哪些 knob
每档动五个 knob:tokenBudget、searchLimit、expansion、reranker_enabled、reranker_model(v0.35.0 默认 zerank-2)。从 conservative 到 tokenmax:searchLimit 10→50(5×),tokenBudget 4K→无上限,还多两道 LLM 调用,单次 search 拉开 5× 成本。
5.3 配上下游模型变 3×3
GBrain 自己跑 retrieval 不烧 LLM 钱,但召回内容最终要喂模型。配上 Haiku 4.5 / Sonnet 4.6 / Opus 4.7(input price 约 $1/M / $3/M / $5/M)就是 3×3 矩阵:
README L65-69 给了 10K queries/month 单用户量级下完整 9 格月度账单:
| Mode \ 下游模型 | Haiku 4.5($1/M) | Sonnet 4.6($3/M) | Opus 4.7($5/M) |
|---|---|---|---|
conservative(~4K) |
$40/mo(角落 1:最省) | $120/mo | $200/mo |
balanced(~10K,默认) |
$100/mo | $300/mo(默认推荐) | $500/mo |
tokenmax(~20K) |
$200/mo | $600/mo | $1,000/mo(角落 2:最豪华) |
对角线自然组合(README L71 称为 “natural pairings”):conservative+Haiku / balanced+Sonnet / tokenmax+Opus,跨度约 4×。但左下到右上 corner-to-corner —— token 量 ~5× × 单价 ~5× —— 合计 ~25× cost band。同一套 retrieval API,切 mode + model 就让月度账单从 $40 走到 $1,000(heavy / multi-user fleet 再 ×10)。
工程价值远大于"省钱":同一套接口能服务三档 SLA。开发预览 conservative + Haiku、生产 balanced + Sonnet、enterprise tokenmax + Opus,不必写三套 retrieval。
5.4 三件套 CLI
切换不是改代码,是 CLI:gbrain search modes(看可用 mode)、search stats(看实际命中率)、search tune(单 query 试不同 mode)。
13 个 config key 都是 search.* 开头(mode.ts:490-506)。覆盖优先级(mode.ts:272-305):per-call > per-key config > MODE_BUNDLES > balanced。三层 resolution 让你"基础走 balanced,单条 query 临时打开 reranker"。
6. Trust Boundary:一个 flag 把 CLI 和 MCP 分开
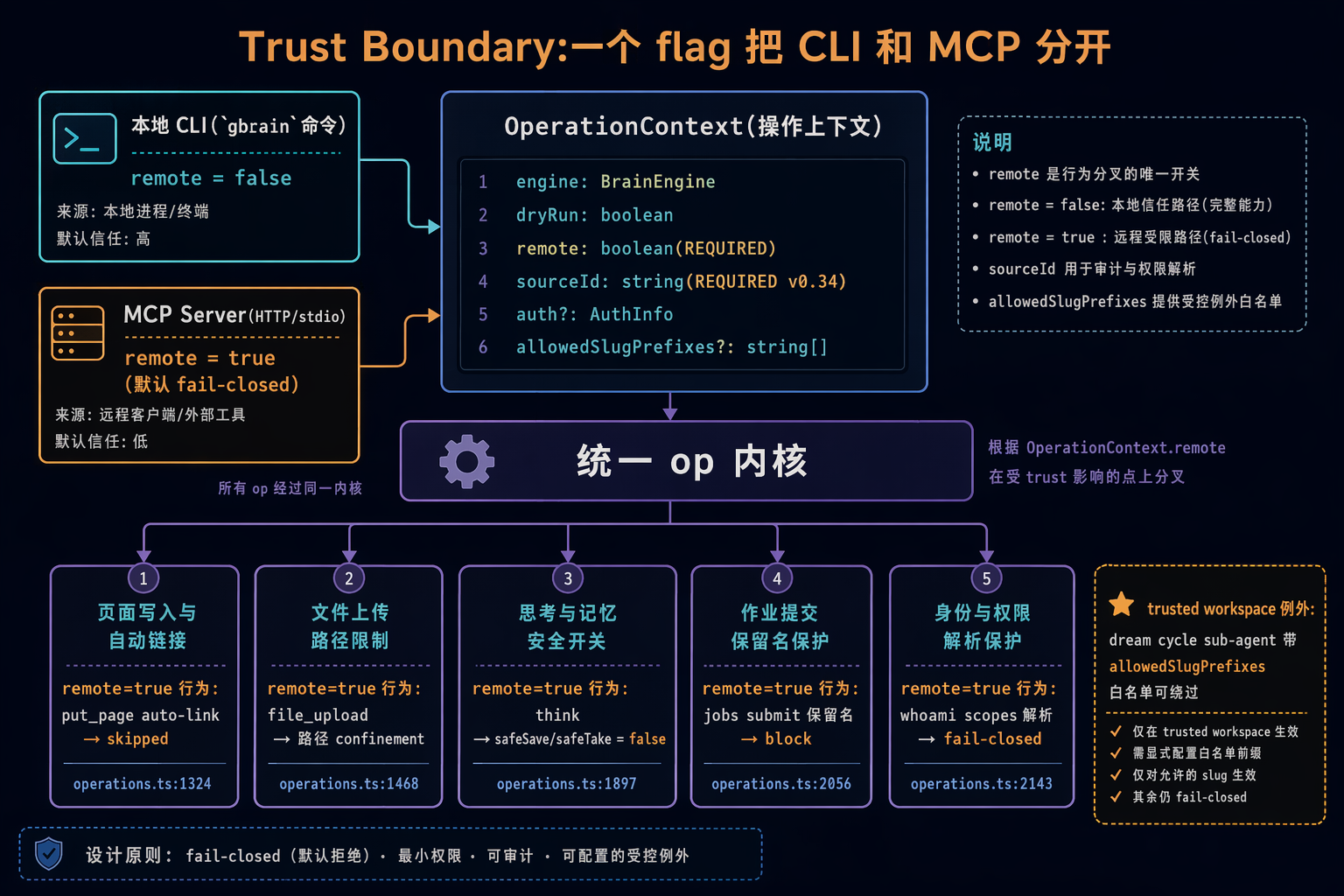
图 6:双入口 → 单 op 内核 → 行为按 trust 分叉
GBrain 有两个入口:本地 CLI(gbrain,可信)和 MCP server(HTTP/stdio,不可信)。同一份 op 内核要在两种 trust level 下表现不一样。朴素做法是包两层 wrapper 各写 sanitize。GBrain 选了更克制的路:加一个 context flag。
6.1 OperationContext.remote
// src/core/operations.ts:269-386
export interface OperationContext {
engine: BrainEngine;
config: GBrainConfig;
logger: Logger;
dryRun: boolean;
auth?: AuthInfo; // OAuth 2.1 info (HTTP MCP)
remote: boolean; // REQUIRED — true=untrusted, false=local CLI
jobId?: number;
subagentId?: number;
viaSubagent?: boolean;
allowedSlugPrefixes?: string[]; // trusted-workspace allow-list
sourceId: string; // REQUIRED v0.34 — tenancy axis
takesHoldersAllowList?: string[];
brainId?: string;
}
remote: boolean 是 REQUIRED,从入口贯穿。cli.ts 设 false,mcp/server.ts 设 true。
6.2 受影响的 op
设了 flag 后 op 内核几处分支自动分叉:
| Op | remote=true 行为 | 代码位置 |
|---|---|---|
put_page 自动建链 |
{ skipped: 'remote' } |
:611-612 |
file_upload |
路径 confinement + 禁 symlink | :92, 1967 |
think save/take |
safeSave / safeTake = false |
:1386-1389 |
jobs submit 保留名 |
block | :2076 |
whoami transport / scopes 解析 |
无 scope fail-closed | :2580-2585 |
think 的分支是个典型例子:
// src/core/operations.ts:1386-1389
const remote = ctx.remote ?? true;
const safeSave = remote ? false : Boolean(p.save);
const safeTake = remote ? false : Boolean(p.take);
注意 ctx.remote ?? true —— 未设定默认按 untrusted。fail-closed:忘了传 flag 系统不会"宽容认为本地",按最严远程模式走。
6.3 trusted workspace 例外
第 3 章那段 auto-link 还有 && !trustedWorkspace。这是给"梦境周期 sub-agent"开的口子(v0.23 dream cycle 的 synthesize + patterns phase),让系统空闲时跑后台 agent 整理记忆。这种 sub-agent 由 brain 自己 spawn,虽 remote=true,但带 allowedSlugPrefixes 白名单,被允许做 auto-link。
设计的克制在于 trust 边界没变成全局 if-else,而是收敛在"哪些 op 在 remote 下表现不一样"这组明确点位。grep ctx.remote 就能列出全部 trust-sensitive op,天然 audit 清单。代价是 trust 维度灌进 OperationContext —— 比两套 wrapper / 两套测试 / 两套 bug,这交易很值。
7. Thin Harness, Fat Skills:34 个 markdown 怎么织起来
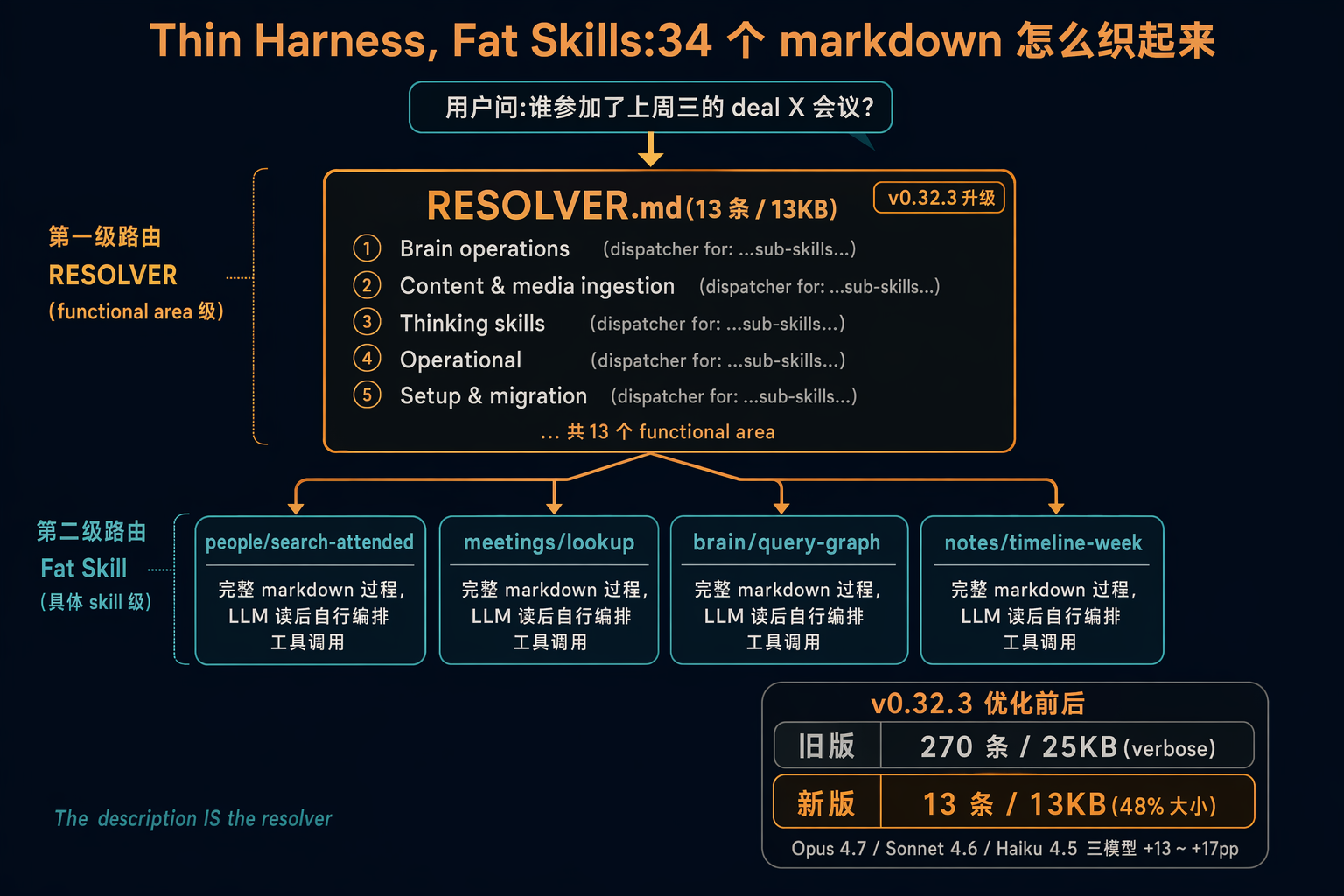
图 7:RESOLVER 二级 dispatch —— functional area → fat skill
GBrain 上层 34 个 skill 全是 markdown,不是 TypeScript class(docs/ethos/THIN_HARNESS_FAT_SKILLS.md L35-46):
“A skill file is a reusable markdown procedure… Markdown is actually code.”
Skill 按 skills/<name>/SKILL.md 存放。Agent 读 markdown 后自己编排工具调用,不需要 runtime code。动机很具体:skill 内容就是 prompt context,prompt 越短模型表现越稳。
7.1 RESOLVER.md
# GBrain Skill Resolver
This is the dispatcher. Skills are the implementation.
**Read the skill file before acting.** If two skills could match, read both.
(skills/RESOLVER.md:1-4)
RESOLVER 是 skill 索引页。Agent 先读 RESOLVER 定位候选,再读对应 fat skill —— 两段 prompt 各只装当前需要的内容,这是 progressive disclosure。
7.2 v0.32.3:functional-area-resolver
skill 多了 RESOLVER 自己也膨胀(skills/functional-area-resolver/SKILL.md:36-57):
“Routing files grow as skills are added. At ~200+ skills this hits 25-30KB. Replace N rows per area with one entry per functional area. Each entry lists all sub-skills in a
(dispatcher for: ...)clause.”
把 N 个 granular trigger-per-row 聚合到 functional area:
# 旧 (270 条 / 25KB)
- "search my notes about X" → notes/search
- "find people who attended Y" → people/search-attended
- ... 270+ rows
# 新 (13 条 / 13KB)
- **Brain & knowledge** (dispatcher for: notes/search, people/*, ...)
- **Communication** (dispatcher for: messaging/*, email/*, ...)
- ... 13 functional areas total
数字面 25KB → 13KB(48%)(README L23)。LLM 读 area description 已能正确路由,不必看每条 granular trigger。Anthropic Agent Skills 同源:“The description IS the resolver.”(docs/ethos/THIN_HARNESS_FAT_SKILLS.md:L62)
7.3 跨模型实测:+13 ~ +17pp
README L23 给了 v0.32.3 实测:BrainBench 上对比 functional-area-resolver vs 25KB verbose 基线,跑 Opus 4.7 / Sonnet 4.6 / Haiku 4.5,全部 +13pp 到 +17pp。
压 prompt 不只省 token,还稳定提升 router 准确率。模型读太多 granular rule 容易 distract,读 high-level area 反而让 routing 更稳,和 retrieval 圈"长 context 塌陷"是同一现象。
迁移做法:几十条 rule 的 dispatcher,先聚成 5-15 个 area 试试。
7.4 设计的代价
一,markdown 没类型系统,skill 写错等运行时暴露。对策是 RESOLVER 那句"Read the skill file before acting" —— LLM 执行前 re-read,等于轻量动态类型检查。
二,skill 之间没显式依赖图。两 skill 都能 match 时让 LLM 都读一遍再选 —— markdown 读 100KB 比跑一次 dependency resolver 还快。
Thin harness 的精髓不在 200 行代码本身,在那 200 行刻意避开 routing / dispatch / state,全部交给 markdown 和 LLM 判断。
8. 5 条可以拿走就用的工程做法
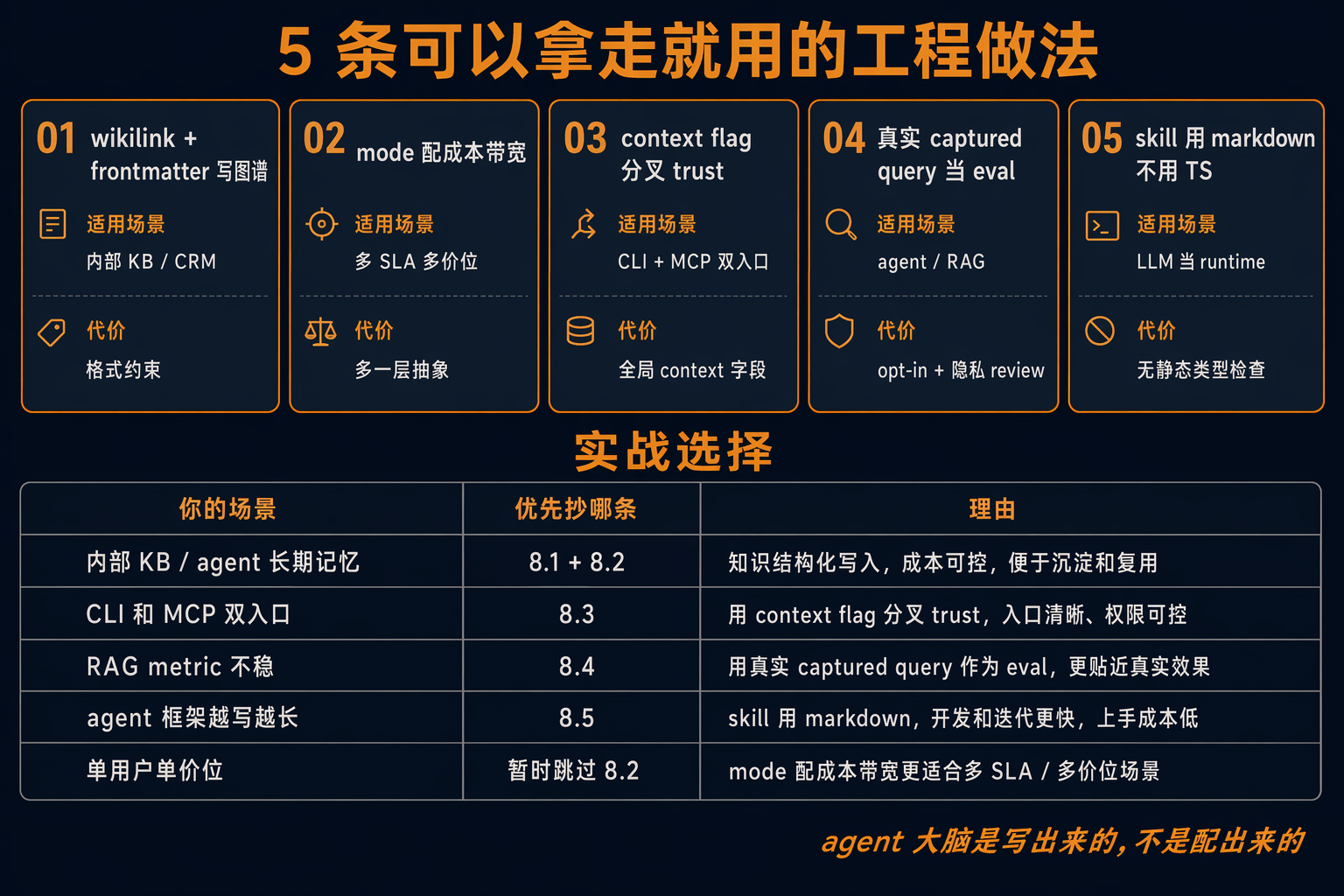
图 8:5 条工程心法 —— 适用场景、代价、决策路径一眼看完
8.1 写 ID/slug 时考虑 graph 抽取
做法:markdown / 文档里强制使用 wikilink([[people/garry-tan]])和 frontmatter typed reference,把 graph 边写在文本里、不另起图谱表。
适用:有结构化关系信息(谁投谁、谁参加哪场会)需要 retrieval 的内部 KB / CRM / 个人知识库。
代价:写作时多一道格式约束。一个 IDE 插件提示 wikilink 拼写就摊平。
反例:用户产生的自由文本(社交评论这种不可能强制格式)。
8.2 配 mode 给成本带宽,不要只给单点
做法:retrieval API 暴露 search(mode='conservative'|'balanced'|'tokenmax'),把 token budget / topk / rerank 这些 knob 收进 mode bundle。
适用:多 SLA、多价位的产品。
代价:多一层 mode 抽象,需要跨 mode 的 stats 和 tune 工具。
反例:单档产品不要做。预期有 enterprise tier,从 day-1 建好 mode 抽象。
8.3 Trust boundary 用 context flag,不要用 wrapper
做法:同一套 op 内核,通过 context flag(remote: boolean)在 op 内部分叉。fail-closed 兜底。
适用:同时有 trusted local(CLI / 自己的服务)和 untrusted remote(MCP / 第三方 API)入口的系统。
代价:trust 维度灌进 OperationContext。但比起两套 wrapper 各写 sanitize,grep ctx.remote 就是天然 audit 清单。
反例:trust 边界横跨完全不同数据模型(admin / user / public 三层),wrapper 更清晰。
8.4 Eval 用真实 captured query,不要用 toy benchmark
做法:v0.25.0 BrainBench-Real(contributor opt-in 收集真实 session capture),v0.28.8 把 LongMemEval 搬进 box(gbrain eval longmemeval)。
适用:retrieval / agent 这类高度依赖真实分布的系统。toy benchmark query 太"干净",和生产分布差距大。
代价:opt-in 流程、隐私 review、数据脱敏。建起来后迭代质量直接和真实用户体验挂钩。
反例:不必等完美 eval 才开发。先用 BrainBench(synthetic Opus-generated)起步,真实 query 多了再替换 —— GBrain 自己就这条路径。
8.5 Skill 用 markdown,不要用 TypeScript
做法:agent 的判断力 layer 用 markdown SKILL.md 写,progressive disclosure(RESOLVER → fat skill)分级加载;不要 TypeScript class hierarchy。
适用:让 LLM 当 runtime 的 agent 系统。Anthropic Agent Skills 同源,Claude Code 内置 skill 也走这条路。
代价:无静态类型检查,出错等运行时。补偿:让 LLM 执行前 re-read skill。
反例:agent 框架只有 < 5 个 skill 时,TypeScript class 直接 import 比 markdown 二级 dispatch 来得清楚 —— progressive disclosure 是规模化才显出价值的设计。
关键证据:functional-area-resolver 实测 25KB → 13KB(48%),三模型 +13 ~ +17pp。压 prompt 不仅省 token,还稳定提升 router 准确率。
8.6 实战决策
| 场景 | 优先抄哪条 | 理由 |
|---|---|---|
| 内部 KB / agent 长期记忆 | 8.1 + 8.2 | 数据结构 + retrieval 双管齐下 |
| CLI 和 MCP 双入口 | 8.3 context flag | 节省一半 wrapper 代码 |
| 在跑 RAG 但 metric 不稳 | 8.4 真实 captured eval | toy benchmark 撑不到生产 |
| Agent 框架越写越长 | 8.5 markdown skill | 跨模型 +13pp 是实证收益 |
| 单用户、单 SLA、单价位 | 跳过 8.2 | mode 抽象有过早引入风险 |
不是每条都该抄,抄"和你今天痛点最重合"那一条。
9. 心智模型 + 总结
整套设计串成一段流水线,按阶段分三段看:
写入 + 自动建链:用户写 markdown,page 落库的 post-hook 里跑零 LLM 的 wikilink + frontmatter 抽取,typed predicate 边推进 graph。
检索 + cost matrix:query 来了并行打 vector + BM25 两路,RRF k=60 融合,0.7/0.3 混 cosine 复评,backlink boost(1 + 0.05·log(1+count))把图谱信号打回 ranking。三档 mode 切 5× 成本带宽,叠下游模型变 25× 弹性。
Trust + Skills:CLI 和 MCP 同一套 op 内核,靠 OperationContext.remote 这个 flag 分叉,fail-closed 兜底。上层 34 个 markdown skill,RESOLVER 二级 dispatch,functional area 把 270 条压成 13 条,跨模型 +13~+17pp。
心智模型只有一句:
agent 大脑是写出来的,不是配出来的。
图谱不是另起维护的数据,是写 markdown 时长出来的。Trust 不是一层防火墙,是 op 内核里一个 boolean。判断力不是一段 TypeScript,是一份 SKILL.md。三个层面共用一种克制——让"加这一层能力"的边际成本接近零。
GBrain 12 天写完跑通 17K 页 / 4K 人 / 21 cron 的真实负载,工程上回答了那个老问题:agent 想要的"长期大脑"要等大模型再进化两代才有?不用,今天的 LLM + 一套写得克制的存储层和 skill 层就够了。把 wikilink、mode bundle、context flag、markdown skill 任何一个抄进自己项目,都已经多养一颗会越睡越聪明的小外脑。
参考
- garrytan/gbrain v0.35.7.0(commit 1dadd9ed),MIT 协议
- README 关键数字:
README.md(L5 / L7 / L9 / L13 / L23 / L65-69 / L108 / L147 / L171 / L280 / L284 / L285 / L289) docs/ethos/THIN_HARNESS_FAT_SKILLS.md(L35-46 / L62 / L83-91)docs/ENGINES.md(L26-91 / L213-224)- 自动建链:
src/core/operations.ts:590-618 / 743-822 - 零 LLM 抽取:
src/core/link-extraction.ts:46-91 / 431-558 / 611-631 - Hybrid search:
src/core/search/hybrid.ts:1-10 / 32-43 / 63-76 / 235-295 / 878-913 / 969-1006 - Search mode:
src/core/search/mode.ts:123-185 / 272-305 / 490-506 - Trust boundary:
src/core/operations.ts:269-386 / 611-612 / 1386-1389 / 1967 / 2076 / 2550 / 2580-2585 - Engine factory:
src/core/engine-factory.ts:1-27、src/core/engine.ts:478-1408(BrainEngine接口) - Skill 系统:
skills/RESOLVER.md:1-4、skills/functional-area-resolver/SKILL.md:36-57

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)