FLUX.1架构的理解3——FLUX.1 采样流程之初始化和预处理
文章目录
-
- 一、前言
- 二、FLUX.1架构
-
- 2.2 FLUX.1 采样流程
- 2.2.1 初始化与预处理
- 【T5 文本编码器】:
- 【解释】:
- 【关键词】:
- 【CLIP 文本编码器】:
- 【解释】:
- 【关键词】:
- FLUX.1 模型中,T5 编码器提供的逐 token 嵌入与 CLIP 编码器提供的整体嵌入是如何协同工作的,以实现更精确的文本-图像对齐?
- 【核心思想】:
- 【协同工作机制拆解】:
- 【总结协同效果】:
- 【推理步数】:
- 【解释】:
- 【关键词】:
- FLUX.1 模型在选择用于采样的“时间步子集”时,采用了何种策略?这与“推理步数”参数是如何关联的?
- 【核心观点】:
- 【详细解释】:
- 【小结】:
- FLUX.1 采用了 Rectified Flow (RF) 训练范式和 Flow-Matching Euler Discrete sampler,这是否意味着其时间步采样策略与传统的 DDPM 或 DDIM 有本质区别,尤其是在处理连续时间到离散时间的映射方面?
- 【核心区别概述】
- 【详细解析】
- 【总结】
- 论文中提到的“采样轨迹”具体是如何影响最终生成图像的风格或内容的?能否举例说明?
一、前言
仅供参考,未经实验验证。参考资料:
Demystifying Flux Architecture
论文地址:https://arxiv.org/pdf/2507.09595
二、FLUX.1架构
2.2 FLUX.1 采样流程
在本节中,我们描述了FLUX的采样流程。1. 为了简单起见,我们将文本到图像的采样过程称为以每个样本的单个提示为条件。
与LDM [6] 类似,FLUX 在潜在空间中运行,其中最终的潜在输出被解码以重建像素空间中的 RGB 图像。遵循 LDM 的方法,开发者使用对抗性目标从头开始训练卷积自编码器,但将潜在表示从 4 个通道(在 LDM 中)扩展到 16 个通道。
采样流程包含三个阶段:(1) 初始化与预处理,(2) 迭代优化,以及 (3) 后处理。这些步骤的概述如图 5 所示,其中符号遵循 diffusers [19] 中 FLUX.1 流程的官方实现所使用的符号。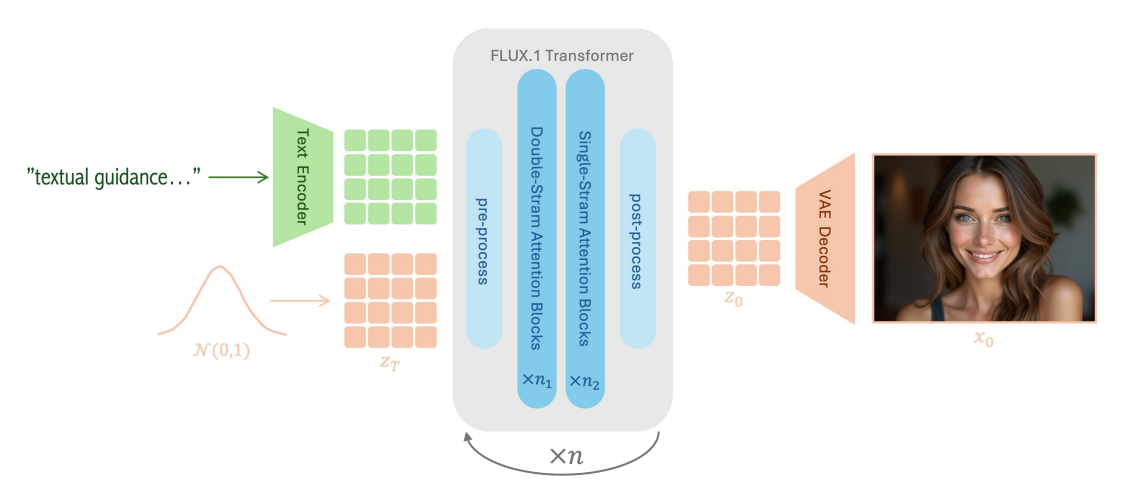 图 4:FLUX.1 架构的高层概述。文本嵌入和潜在图像嵌入通过一系列注意力模块进行迭代处理,以生成文本条件图像。
图 4:FLUX.1 架构的高层概述。文本嵌入和潜在图像嵌入通过一系列注意力模块进行迭代处理,以生成文本条件图像。
在下面的章节中,我们主要关注流水线的启动和预处理阶段。迭代精炼和后处理阶段的简要概述将在本节末尾提供。FLUX Transformer 运行所在的迭代精炼阶段将在第 2.3 节中详细讨论。
2.2.1 初始化与预处理
在此阶段,模型处理用户提供的输入,为主要 Transformer 的优化阶段做准备。此阶段的一个关键组成部分是文本编码器,它处理用户提供的文本指导。FLUX.1 使用两个预训练的文本编码器:
CLIP文本编码器。CLIP(对比语言-图像预训练)[9] 是由OpenAI开发的一个基础模型,旨在连接视觉和语言理解。CLIP的文本编码器将自然语言提示转换为类别级别或密集、高维的嵌入,这些嵌入可以直接在共享的潜在空间中与图像嵌入进行比较。
[9] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin,J. Clark et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PmLR, 2021, pp. 8748–8763.
CLIP文本编码器在数亿个图像-文本对上进行训练,能够捕捉丰富的语义信息,使模型能够有效地将文本描述与相应的视觉内容对齐,因此在文本到图像生成任务中得到了广泛应用。
T5文本编码器。T5(Text-To-Text Transfer Transformer)[20] 是谷歌开发的一个多功能语言模型,它将所有自然语言处理任务(例如,翻译、摘要和问答)都构建为文本到文本的问题。其文本编码器使用基于Transformer的架构,在海量语言语料库上进行训练,将输入文本转换为上下文嵌入。
与CLIP的文本编码器不同,CLIP的文本编码器与图像编码器联合训练,以产生与对比学习的视觉特征对齐的嵌入,而T5则仅在文本数据上进行训练,并针对语言理解和生成进行优化。这使得T5非常适合为长而复杂的文本提示提供丰富的、令牌级别的语义表示。
[12] D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. M¨uller, J. Penna, and R. Rombach, “Sdxl: Improving latent diffusion models for high-resolution image synthesis,” arXiv preprint arXiv:2307.01952, 2023.
下面,我们概述所有必需的输入,并描述模型如何处理它们,为细化阶段做准备。该流程所需的输入为:
• 文本(text):文本提示引导图像生成过程,以强制执行指定的特征或质量。
• 指导尺度(guidance scale):控制调节的强度。
• 推理步数(num inference steps):应执行多少次迭代采样步骤。
• 分辨率(resolution):指定生成图像的空间分辨率(高度和宽度)。
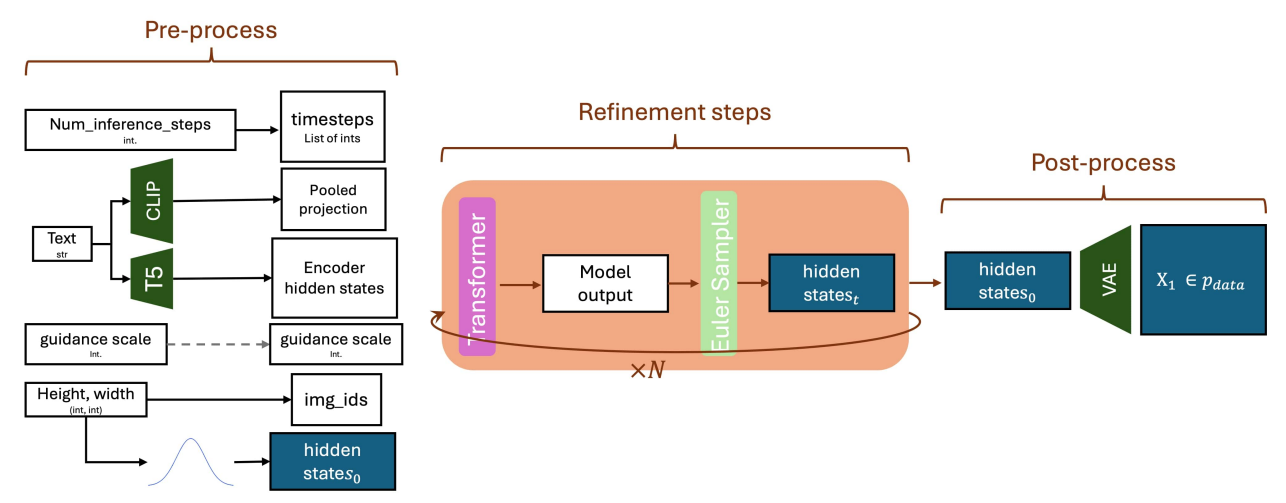
图 5:Flux.1 采样流程。与扩散模型类似,在预处理带噪声的潜在变量
z t z_t zt(表示为 h i d d e n s t a t e t hidden state_t hiddenstatet)后,在潜在空间中对其进行迭代细化。最终细化的 z 0 ( = h i d d e n s t a t e s 0 ) z_0(=hidden states_0) z0(=hiddenstates0)使用预训练的 VAE 解码器解码为 RGB 图像。
一旦使用这些输入启动,它们将按如下方式进行预处理:
• 文本:文本提示正在使用两个预训练的文本编码器进行编码:
– T5:提供密集的(每个token)嵌入,表示为编码器隐藏状态(encoder hidden states)
– CLIP:提供池化嵌入(整个提示只有一个嵌入,如CLS嵌入),表示为池化投影(pooled projection)
• 推理步数:指定推理过程中使用的采样步数总数。它决定了完整扩散范围 t ∈ [ 0 : T ] t ∈ [0 : T] t∈[0:T] 的一个时间步子集,其中通常 t = 1000 t= 1000 t=1000。迭代这些选定的时间步定义了采样轨迹。
• 分辨率:所需的分辨率决定了初始(潜在)噪声样本 z 0 ∼ N ( 0 , 1 ) z_0 \sim \mathcal{N}(0, 1) z0∼N(0,1) 的空间维度。它还用于定义图像标识符(img ids)——一组每个 token 的指示符,用于指向 token 在二维网格上的空间位置。给定像素空间中的目标分辨率 ( H , W ) (H, W) (H,W),对应的潜在维度 ( h , w ) (h, w) (h,w) 计算如下:
h = H / / VAE scale , w = W / / VAE scale h = H \ // \ \text{VAE}_{\text{scale}}, \quad w = W \ // \ \text{VAE}_{\text{scale}} h=H // VAEscale,w=W // VAEscale
其中 VAE scale = 8 \text{VAE}_{\text{scale}} = 8 VAEscale=8。
图像 token 网格进一步下采样至维度 ( h / / 2 , w / / 2 ) (h // 2,\ w // 2) (h//2, w//2),并且每个 token 被分配一个形式为 ( t , h ^ , w ^ ) (t,\ \hat{h},\ \hat{w}) (t, h^, w^) 的唯一标识符,其中 h ^ ∈ [ 0 : h − 1 ] \hat{h} \in [0 : h-1] h^∈[0:h−1], w ^ ∈ [ 0 , w − 1 ] \hat{w} \in [0, w-1] w^∈[0,w−1],表示 token 在二维空间网格上的位置。
文本标识符(text ids) 使用与图像标识符相同的结构初始化,但所有 token 的 (t = h = w = 0)。形式化地:
text ids = n ⋅ ( 0 , 0 , 0 ) \text{text ids} = n \cdot (0, 0, 0) text ids=n⋅(0,0,0)
其中 (n) 是 T5 模型中的最大 token 数(= 512)。
【T5 文本编码器】:
T5 文本编码器通过为每个输入 token 生成高维度的密集嵌入(encoder hidden states),为 FLUX.1 模型提供细粒度的语义信息,作为其文本引导图像生成过程的关键条件。
【解释】:
T5 (Text-To-Text Transfer Transformer) 文本编码器在 FLUX.1 的预处理阶段扮演着关键角色。它将用户提供的文本提示(textual prompt)转化为一系列密集的(dense)、高维度的向量表示,即“encoder hidden states”。这些嵌入是针对文本中的每个 token 生成的,这意味着它们捕捉了文本的细粒度语义信息和上下文依赖性。与 CLIP编码器提供一个整体的池化嵌入不同(尽管 FLUX.1 也同时使用 CLIP 的池化嵌入),T5 的逐 token嵌入允许模型更精确地理解文本提示的复杂性和结构,特别适用于处理长文本和复杂语义。这些密集的嵌入随后被 FLUX.1 的Transformer 架构(特别是 Double-Stream Transformer Block 和 Single-Stream Transformer Block)利用,通过跨模态注意力机制与潜在图像表示进行交互,从而有效地引导图像生成过程,确保生成的图像能够忠实地遵循文本描述。这种逐token 的表示对于实现高质量的文本-图像对齐至关重要,因为它允许模型在生成图像时精确地关注文本提示的不同部分。
【关键词】:
- T5 (Text-To-Text Transfer Transformer):Google 开发的一种多功能语言模型,将所有 NLP 任务(如翻译、摘要、问答)都视为文本到文本问题。其文本编码器通过基于 Transformer 的架构将输入文本转换为上下文嵌入。
- 密集嵌入 (Dense Embeddings):指在连续向量空间中表示的、信息量丰富的向量。在 T5 中,这些嵌入为文本中的每个 token 提供了细粒度的语义表示。
- token (Token):文本处理中的基本单位,可以是单词、子词或字符。
- 编码器隐藏状态 (Encoder Hidden States):Transformer 编码器层输出的向量表示,捕捉了输入序列中每个 token 的上下文信息和语义特征。在 FLUX.1 中,T5
提供的这些隐藏状态用于对图像生成进行精细的文本条件控制。
【CLIP 文本编码器】:
CLIP 文本编码器在 FLUX.1 模型预处理阶段的作用,即生成整个文本提示的单一、高维的“池化嵌入”,该嵌入作为全局语义表示,被称为“池化投影”。
【解释】:
CLIP(Contrastive Language-Image Pretraining)文本编码器在 FLUX.1 的文本-图像生成管道中扮演着关键的预处理角色。它接收用户提供的文本提示作为输入,并将其转化为一个紧凑的、固定长度的向量表示。这种表示被称为池化嵌入(Pooled Embedding),其特点在于它对整个文本提示进行全局语义编码,而非像逐 token 嵌入那样保留每个单词的独立信息。
“池化”操作通常涉及对文本序列中所有 token 嵌入进行某种形式的聚合(例如,取平均值、最大值或提取特定 token,如
[CLS]token 的表示),从而得到一个单一的向量。这个单一向量捕获了文本提示的整体含义和高级语义,使其能够代表整个句子的核心概念。在 FLUX.1 的上下文中,这种池化嵌入被明确地称为池化投影(Pooled Projection)。它的主要作用是为后续的图像生成过程提供一个高层次、全局性的文本条件信号。这个信号与图像的潜在表示在共享的潜在空间中进行比对和交互,有助于确保生成的图像在整体视觉概念上与文本提示高度对齐。相较于细粒度的逐token 嵌入,池化投影更侧重于宏观的语义一致性和跨模态的视觉-语言桥接,是 FLUX.1实现高质量文本-图像对齐的关键组成部分。
【关键词】:
- CLIP (Contrastive Language-Image Pretraining):一种由 OpenAI 开发的基础模型,旨在通过对比学习桥接视觉和语言理解。其文本编码器能将自然语言提示转换为可与图像嵌入直接比较的共享潜在空间中的高维嵌入。
- 池化嵌入 (Pooled Embedding):一种将整个输入序列(如文本提示)聚合为一个单一、固定长度的向量表示的方法。它捕获了序列的整体或全局语义信息,而非保留每个离散元素的详细信息。
- CLS嵌入 (CLS Embedding):在某些 Transformer 模型(如 BERT 及其变体)中,指代一个特殊的分类(Classification)token 的嵌入。这个 token通常放在输入序列的开头,其最终的隐藏状态常被用作整个序列的聚合表示或池化嵌入。
- 池化投影 (Pooled Projection):特指 CLIP 编码器输出的池化嵌入,它作为整个文本提示的全局语义表示,用于条件化图像生成过程,确保图像与文本的整体概念对齐。
FLUX.1 模型中,T5 编码器提供的逐 token 嵌入与 CLIP 编码器提供的整体嵌入是如何协同工作的,以实现更精确的文本-图像对齐?
【核心思想】:
FLUX.1 通过结合 T5 编码器的细粒度语义信息(逐 token 嵌入)和 CLIP 编码器的全局语境理解(整体嵌入),在不同的处理阶段和 Transformer 模块中,以互补的方式为图像生成提供多层次的文本条件。T5负责理解复杂和长文本提示的语义细节,而 CLIP 确保生成的图像与整个提示的视觉概念高度相关,共同构建了一个既有深度又有广度的文本引导机制。
【协同工作机制拆解】:
FLUX.1 模型的采样管道(Sampling Pipeline)和 Transformer 架构(Transformer Architecture)是理解这两种嵌入协同工作的关键。
1. 预处理阶段 (Initiation and Pre-processing)
在这一阶段,用户输入的文本提示首先会被两个预训练的文本编码器并行处理:
T5 文本编码器 (T5 Text Encoder):
- 作用:生成密集的(per-token)嵌入,被称为
encoder_hidden_states。- 特点:T5 擅长于文本理解和生成,能够捕捉长而复杂的文本提示中的细粒度语义和上下文关系。它将每个单词或子词(token)转换为一个高维向量,这些向量共同构成了文本的详细语义表示。
- 贡献:主要用于提供文本的结构化和详细语义信息,对于理解提示中的具体属性、关系和复杂描述至关重要。
CLIP 文本编码器 (CLIP Text Encoder):
- 作用:生成一个池化(pooled)嵌入,被称为
pooled_projection。- 特点:CLIP 是一个跨模态模型,旨在弥合视觉和语言之间的鸿沟。它的文本编码器将整个文本提示压缩成一个单一的、高维的向量,这个向量可以直接与图像嵌入进行比较。
- 贡献:主要用于提供文本的整体语义和高级概念对齐。它确保生成的图像与整个文本提示的视觉概念保持一致,尤其是在提示遵循(Prompt Following)和视觉质量方面。
2. Transformer 内部的引导嵌入 (Guiding Embeds)
在 Transformer 的每次迭代预处理(Per-Iteration Pre-process)中,T5 和 CLIP的输出会进一步整合,形成“引导嵌入”(
temb),用于调制 Transformer 层的行为:
temb的构成:
- FLUX.1 不仅使用传统的时间步(timestep)信息,还将 CLIP 的池化提示嵌入 (
pooled_projection) 整合到temb的构建中。- 具体来说,
timestep和pooled_projection都经过正弦投影和线性层转换,然后求和,形成最终的temb。- 意义:这意味着 CLIP 的整体文本语义信息直接参与了Transformer 每一层的调制过程。它帮助模型在去噪过程中,持续地将整体文本语义作为条件,确保图像生成的每一步都朝着与整个提示相关的方向发展。
3. 多模态注意力机制 (Multi-Modal Attention)
FLUX.1 的 Transformer 模块(包括 Double-Stream 和Single-Stream)是实现文本-图像对齐的核心,它们都采用了多模态注意力机制:
- 联合自注意力 (Joint Self-Attention):
- T5 提供的逐 token 嵌入 (
encoder_hidden_states) 和图像的潜在嵌入 (latent) 被拼接(concatenate)在一起。- 然后,Transformer 块对这个拼接后的序列执行联合自注意力操作。
- 意义:这种机制允许文本 token 和图像 token 之间进行双向交互。
- 文本到图像:图像 token 可以“关注”文本 token,从而从文本中提取出生成图像所需的具体属性和细节信息(例如,“红色汽车”中的“红色”和“汽车”)。
- 图像到文本:文本 token 也可以“关注”图像 token,这有助于模型在生成过程中评估当前的图像状态是否符合文本描述,并进行相应的调整。
- 文本内部:同时,文本 token 之间也能进行自注意力,维持文本自身的语义连贯性(由 T5 编码器提供)。
- 图像内部:图像 token 之间也能进行自注意力,捕捉图像内的空间依赖和全局结构。
4. Adaptive Layer Normalization (AdaLN)
AdaLN [21] 是一种条件机制,用于根据外部输入(如文本嵌入)动态调制 Transformer 层的中间激活:
- T5 和 CLIP 间接影响 AdaLN:虽然论文没有直接说明 T5 的
encoder_hidden_states和 CLIP 的pooled_projection如何直接作为 AdaLN 的输入,但temb(包含 CLIP 信息)和guidance_scale(由用户指定,间接与文本指导强度相关)都会影响 Transformer块的行为。通过这种方式,文本条件信息能够动态调整每一层的归一化和调制参数(scale和shift),从而更精细地控制图像生成过程。- 双流 (Double-Stream) 与单流 (Single-Stream) Transformer 块:
- 双流块:为图像和文本 token 使用单独的权重,并通过拼接后的注意力操作实现多模态交互。这允许模型针对不同模态进行专业化学习,更好地处理复杂的文本-图像关系。
- 单流块:为图像和文本 token 使用共享权重,并以并行方式处理注意力层和前馈层。这强调了模态间的紧密集成和效率,有助于模型在更广阔的领域中进行泛化。
【总结协同效果】:
- T5 逐 token 嵌入:提供精细的语义指导。它使得 FLUX.1 能够理解复杂、多元素的提示,准确生成图像中的特定对象、属性和它们之间的关系。例如,在“一辆在雪天行驶的红色跑车”这样的提示中,T5嵌入能帮助模型区分“红色”和“跑车”并准确结合。
- CLIP 整体嵌入:提供全局的视觉概念对齐。它确保生成的图像在整体上与文本提示的高级语义和风格保持一致,避免生成与提示主题完全偏离的图像。它就像一个“视觉锚点”,将整个生成过程锁定在正确的概念空间内。
temb引导嵌入:通过将 CLIP 的整体嵌入与时间步信息结合,temb在每一迭代中为 Transformer 提供了全局的、时间感知的条件,确保了生成过程的稳定性和方向性。- 多模态注意力:是两者信息融合的舞台,允许细粒度文本(T5)和图像潜在表示之间进行动态、双向的交互,使得模型能够根据文本提示的每一个细节来迭代地修改图像。
通过这种分层且互补的结合,FLUX.1能够实现既忠实于文本的整体意图,又精确捕捉其细微描述的卓越文本-图像对齐能力,从而生成高质量、高多样性的图像。
【推理步数】:
“推理步数”是 FLUX.1 模型在去噪扩散过程中执行迭代采样的总次数,通过从完整时间步范围中选择一个子集来定义生成图像的采样轨迹。
【解释】:
“num_inference_steps”(推理步数)是 FLUX.1 模型在生成图像时的一个关键参数,它决定了去噪过程的迭代精细程度。在扩散模型中,图像生成是一个从纯高斯噪声逐步去噪到清晰图像的过程,这个过程通常通过一系列离散的时间步(timesteps)来完成。
具体而言:
- 采样步数总数:该参数指定了模型在推理阶段将执行的去噪迭代次数。较高的推理步数通常意味着更精细、更准确的去噪过程,可能带来更好的图像质量,但也伴随着更高的计算成本和更长的生成时间。
- 时间步子集:扩散模型通常在一个预定义的、较大的时间步范围
t ∈ [0 : T]上进行训练(例如,T = 1000)。然而,在推理时,并不需要遍历所有的T个时间步。num_inference_steps参数会从这个完整的T范围中选择一个较小的、离散的时间步子集。这些选定的时间步定义了模型从噪声到数据的采样轨迹。- 迭代去噪:模型会按照这个选定的时间步序列,从初始的纯噪声状态
z_T开始,逐步预测并移除噪声,直到达到接近z_0(清晰图像)的状态。每一步都基于前一步的结果进行迭代更新。因此,“推理步数”直接控制了 FLUX.1 从潜在空间中的噪声样本生成最终图像的速度和质量之间的权衡。
【关键词】:
- 推理步数 (num_inference_steps):在扩散模型推理过程中,指定模型执行迭代采样的总次数,以逐步去噪并生成图像。
- 扩散范围 (diffusion range):扩散模型训练时所定义的时间步集合,通常从纯噪声(如
t=T)到无噪声数据(如t=0)。- 时间步 (timestep):在扩散模型中,表示去噪过程中的一个特定阶段,通常是一个从
T到0递减的整数值,指示了当前噪声水平。- 采样轨迹 (sampling trajectory):由选定的一系列离散时间步组成,定义了模型在推理过程中从噪声到数据的特定去噪路径。
FLUX.1 模型在选择用于采样的“时间步子集”时,采用了何种策略?这与“推理步数”参数是如何关联的?
【核心观点】:
FLUX.1 模型在选择时间步子集时,并没有采用复杂的动态策略,而是通过均匀采样或预定义序列从完整的扩散时间步范围中选择离散的步骤。这与“推理步数”参数直接关联,因为它决定了子集的大小和密度,从而影响了采样过程的精细度和效率。
【详细解释】:
1. FLUX.1 模型在选择“时间步子集”时采用了何种策略?
FLUX.1 在选择时间步子集时遵循以下策略:
- 从完整范围中选择子集: 模型首先有一个完整的扩散时间步范围
t ∈ [0: T],其中T通常是1000。这意味着模型在训练时可能学习了1000个不同的噪声级别和去噪方向。- 由
num_inference_steps决定子集大小: 用户通过num_inference_steps参数指定希望进行多少次迭代采样。这个参数的值直接决定了从[0: T]范围中选取的实际时间步的数量。- 定义采样轨迹: 这些被选中的离散时间步构成了一个序列,定义了模型在推理过程中从纯噪声(
z_T)逐步去噪到清晰图像(z_0)的采样轨迹 (sampling trajectory)。虽然论文没有明确说明具体的“均匀采样”或“非均匀采样”策略,但在扩散模型中,最常见的做法是:
- 均匀采样 (Uniform Sampling): 这是最简单也最常用的方法。如果
T=1000且num_inference_steps=50,模型会从[0, 1000]中以大约1000 / 50 = 20
的间隔均匀选取50个时间步。例如,t = 1000, 980, 960, ..., 20, 0。- 预定义或优化序列: 有些更高级的方法会根据扩散过程的特性,选择在某些阶段(例如,去噪的早期或后期)更密集的时间步,以优化生成质量或速度。
论文提到 FLUX.1 采用了 Rectified Flow (RF) 训练范式 (Section 1.4),并使用 Flow-Matching Euler Discrete sampler [15] (Section 2.2.2)。
这暗示了采样过程是确定性的,并通过求解一个简单的 ODE来完成。在这种情况下,选择时间步子集更倾向于一个预定义的、高效的离散化序列,以尽可能接近连续的矢量场轨迹。虽然细节未公开,但其核心仍是根据num_inference_steps来离散化这个轨迹。2. 这与“推理步数”参数是如何关联的?
“推理步数”参数与时间步子集的选择存在直接且关键的关联:
- 决定子集大小:
num_inference_steps的值直接设定了时间步子集中的时间步数量。如果你设定num_inference_steps=50,那么模型就会从完整的[0: T]范围中选择50个时间步来执行去噪。- 影响采样密度:
- 高
num_inference_steps: 意味着时间步子集包含更多的时间步,这些时间步在[0: T]范围内分布得更密集。这使得去噪过程更加平滑和细致,通常能生成更高质量、细节更丰富的图像,但会增加推理时间。- 低
num_inference_steps: 意味着时间步子集包含较少的时间步,这些时间步分布得更稀疏。去噪过程可能更粗糙,可能牺牲一些图像质量和细节,但能显著加快推理速度。例如,FLUX.1[schnell]版本就是通过时间步蒸馏(timesteps-distillation)来减少所需采样步数,以优化速度。- 定义去噪路径的粒度: 每一个被选中的时间步都对应一个特定的噪声水平,模型在该时间步预测并移除噪声。
num_inference_steps
越多,模型就越能以更小的步长和更精细的粒度沿着去噪路径前进。【小结】:
FLUX.1 模型通过
num_inference_steps参数来控制从完整的扩散时间步范围中抽取离散时间步的数量,这些时间步共同构成了图像生成的采样轨迹。这一参数直接影响了采样过程的精细度、图像质量和推理速度,是平衡生成效果与计算效率的关键旋钮。
FLUX.1 采用了 Rectified Flow (RF) 训练范式和 Flow-Matching Euler Discrete sampler,这是否意味着其时间步采样策略与传统的 DDPM 或 DDIM 有本质区别,尤其是在处理连续时间到离散时间的映射方面?
FLUX.1 采用 Rectified Flow (RF) 训练范式和 Flow-Matching Euler Discrete Sampler,这确实意味着其时间步采样策略与传统的 DDPM (Denoising Diffusion Probabilistic Models) 或 DDIM (Denoising Diffusion Implicit Models) 在处理连续时间到离散时间的映射方面存在本质区别。
【核心区别概述】
| 特性 | DDPM / DDIM | FLUX.1 (基于 Rectified Flow) |
|---|---|---|
| 底层理论 | 随机微分方程 (SDE) / 普通微分方程 (ODE) | 普通微分方程 (ODE) / 连续正则流 (Rectified Flow) |
| 学习目标 | 预测噪声 ϵ \epsilon ϵ (DDPM) 或直接去噪 | 预测速度向量 v v v (直接指向数据) |
| 采样过程 | 迭代去噪,通常涉及随机性 (DDPM) 或确定性 (DDIM) | 迭代积分,通过求解 ODE 获得确定性路径 |
| 连续时间到离散时间映射 | 通常依赖噪声调度和马尔可夫链性质 (DDPM) 或跳过采样 (DDIM) | 依赖流匹配原理,直接定义从噪声到数据的直线路径,离散化是求解 ODE 的过程 |
| 采样效率 | DDIM 允许更少步数,但仍有特定计算模式 | RF 原生设计为更快、更稳定的 ODE 求解,采样效率更高 |
【详细解析】
1. 传统 DDPM/DDIM 的时间步采样策略
-
DDPM (Denoising Diffusion Probabilistic Models):
- 核心: 基于随机微分方程 (SDE)。前向过程是逐渐加噪,后向(生成)过程是逐渐去噪的马尔可夫链。
- 学习目标: 模型学习预测在给定时间步
t添加的噪声 ϵ \epsilon ϵ。 - 采样: 采样过程本质上是反转马尔可夫链,从纯高斯噪声开始,逐步去除噪声。每个时间步的更新都包含一个随机噪声项,使其具有随机性。
- 离散化: DDPM 的时间步是预设的、固定的离散序列(例如 1000 步)。在每个时间步,模型根据预测的噪声和当前状态,以一个小步长进行更新。连续时间到离散时间的映射体现在对 SDE 的欧拉-马鲁山 (Euler-Maruyama) 离散化。
- 局限性: 通常需要大量的采样步数(数百到上千)才能生成高质量图像,因为每一步都依赖于前一步的随机性和噪声调度。
-
DDIM (Denoising Diffusion Implicit Models):
- 核心: 仍然基于扩散模型框架,但将采样过程推广为非马尔可夫链,使其成为一个确定性过程,可以看作是对 SDE 对应的普通微分方程 (ODE) 的离散化。
- 学习目标: 与 DDPM 类似,模型学习预测噪声 ϵ \epsilon ϵ。
- 采样: 采样不再包含随机噪声项,而是确定性地从噪声向数据移动。
- 离散化: DDIM 最大的特点是允许**“跳过采样 (skip sampling)”。即,可以从
T个原始时间步中,只选择一个子集**(例如 50 步),然后通过 DDIM 的特定公式直接从 x t i x_{t_i} xti 预测 x t i − 1 x_{t_{i-1}} xti−1。这种映射不再是 SDE 的直接离散化,而是基于 ODE 路径的近似跳跃。它允许使用更少的推理步数,但仍然是基于预测噪声 ϵ \epsilon ϵ 的框架。
2. FLUX.1 (Rectified Flow) 的时间步采样策略
-
Rectified Flow (RF) 的核心:
- RF 的目标是学习一个从纯噪声到数据点的确定性、直线 ODE 路径。它不是通过逐步去噪来反转一个随机过程,而是直接学习一个速度向量场 v ( x t , t ) v(x_t, t) v(xt,t),这个速度向量在任何时间点
t都指向数据的真实分布 x 1 x_1 x1。 - 学习目标: 模型直接学习预测这个速度向量 v v v,而不是噪声 ϵ \epsilon ϵ。在论文公式 (2) 中,损失函数是 L v = E x 0 , x 1 , t [ ∣ ∣ v θ ( x t , t ) − ( x 1 − x 0 ) ∣ ∣ 2 ] L_v = E_{x_0,x_1,t} [||v_\theta(x_t, t) - (x_1 - x_0)||2] Lv=Ex0,x1,t[∣∣vθ(xt,t)−(x1−x0)∣∣2],明确显示模型在学习 x 1 − x 0 x_1 - x_0 x1−x0 这一方向向量。
- “直线路径”的概念: x t = ( 1 − t ) x 0 + t x 1 x_t = (1-t)x_0 + tx_1 xt=(1−t)x0+tx1 表示噪声 x 0 x_0 x0 到数据 x 1 x_1 x1 之间的一条直线插值路径。RF 的核心思想是训练模型来预测沿着这条直线路径的速度向量。
- RF 的目标是学习一个从纯噪声到数据点的确定性、直线 ODE 路径。它不是通过逐步去噪来反转一个随机过程,而是直接学习一个速度向量场 v ( x t , t ) v(x_t, t) v(xt,t),这个速度向量在任何时间点
-
Flow-Matching Euler Discrete Sampler 与连续时间到离散时间的映射:
- 本质区别: RF 的采样过程是直接求解一个 ODE: d x t d t = v ( x t , t ) \frac{dx_t}{dt} = v(x_t, t) dtdxt=v(xt,t)。这里的目标函数 v v v 就是模型学习到的速度向量。
- 欧拉离散化 (Euler Discretization):
Flow-Matching Euler Discrete Sampler意味着在推理时,FLUX.1 使用欧拉法来离散化和求解这个 ODE。从 x t + Δ t = S a m p ( v θ ( x t , t ) , Φ ) x_{t+\Delta t} = Samp(v_\theta(x_t, t), \Phi) xt+Δt=Samp(vθ(xt,t),Φ) (论文公式 4) 可以看出,当前状态 x t x_t xt 会根据模型预测的速度向量 v θ ( x t , t ) v_\theta(x_t, t) vθ(xt,t) 和时间步长 Δ t \Delta t Δt 来更新,以得到下一个时间步 x t + Δ t x_{t+\Delta t} xt+Δt。 - 无噪声项: 与 DDPM 不同,RF 的采样过程中没有显式的随机噪声项。它是一个纯粹的确定性过程,通过积分速度向量来“滑动”当前状态,直至达到数据分布。
- 采样效率: 由于 RF 原生就设计为学习一个直线路径的确定性流,其 ODE 求解通常比 DDIM 的确定性去噪更加稳定和高效,允许使用更少的采样步数(通常几十步甚至更少)就能生成高质量图像。因为每一步都是沿着预设的“直线”轨迹前进,而不是间接估计噪声。
【总结】
FLUX.1 基于 Rectified Flow 的时间步采样策略与 DDPM/DDIM 存在本质区别:
- 学习目标不同: DDPM/DDIM 学习预测噪声 ϵ \epsilon ϵ,而 RF 直接学习从噪声到数据点的速度向量 v v v。
- 采样机制不同: DDPM 是反转带噪声的马尔可夫链,DDIM 是确定性地跳过去噪步,而 RF 是通过欧拉法直接积分一个速度向量场,沿着一条“直线”路径从噪声滑动到数据。
- 连续到离散的映射哲学不同:
- DDPM/DDIM 的离散化是基于噪声调度和逐步去噪的逻辑,即使是 DDIM 的跳过采样,其底层也是噪声预测。
- RF 的离散化是基于流匹配理论,直接将生成过程建模为从噪声到数据点的连续 ODE 路径。采样步数决定的是求解这个 ODE 的离散化精度,而不是去噪步骤的数量。这种原生设计的 ODE 路径使得离散化更加直接、高效。
因此,FLUX.1 的时间步采样策略是其 Rectified Flow 范式的直接体现,它带来了更快的推理速度和更高的稳定性,使其在图像生成任务中具有显著优势。
论文中提到的“采样轨迹”具体是如何影响最终生成图像的风格或内容的?能否举例说明?
在FLUX.1(以及更广泛的扩散模型)中,“采样轨迹”(Sampling Trajectory) 是指模型在推理阶段,从初始的纯高斯噪声(或潜在空间中的噪声)迭代地演化到最终清晰图像的过程路径。这条轨迹上的每一步,模型都会根据当前的潜在表示和条件信息(如文本提示、时间步)进行更新。
对于FLUX.1,由于它基于Rectified Flow (RF) 范式,其采样轨迹与传统扩散模型有相似之处,但也有其独特的影响机制。
【Rectified Flow 中“采样轨迹”的核心】
在Rectified Flow中,模型学习的是一个速度向量场 v ( x t , t ) v(x_t, t) v(xt,t),它定义了从噪声 x 0 x_0 x0 到数据 x 1 x_1 x1 的**“直线”插值路径**。采样轨迹就是沿着这条“直线”路径,通过迭代积分速度向量来逐步演化 x t x_t xt 的过程。
采样轨迹是如何影响最终生成图像的风格或内容的?
采样轨迹通过以下几个关键方面影响最终图像的风格或内容:
-
引导强度 (Guidance Scale):
- 机制: 指导参数
guidance_scale控制模型对文本提示的遵循强度。高guidance_scale会使模型更严格地遵循提示,生成与文本描述高度一致的图像;低guidance_scale则允许模型有更多自由度,生成更多样化、更具创意的图像,但可能与提示的匹配度稍低。 - 对轨迹的影响:
guidance_scale实际上是影响速度向量 v ( x t , t ) v(x_t, t) v(xt,t) 的方向和大小。在条件生成中,通常会结合有条件模型输出和无条件模型输出计算一个“更偏向条件”的速度向量。guidance_scale越大,这种偏向越强,导致轨迹更严格地向着符合提示的方向弯曲。 - 示例:
- 提示: “A futuristic cyberpunk city at night, with neon lights and flying cars.”
- 高
guidance_scale的轨迹: 轨迹会非常迅速且坚定地收敛到符合“赛博朋克”、“霓虹灯”、“飞行汽车”等所有元素的图像区域,最终生成一张细节丰富、完全符合描述的赛博朋克城市图。 - 低
guidance_scale的轨迹: 轨迹可能在早期阶段探索更多可能性,生成一些有赛博朋克元素,但可能没有飞行汽车,或者城市风格不那么“未来感”的图像,甚至可能生成一些抽象或意想不到的艺术风格图像。
- 机制: 指导参数
-
时间步数 (num_inference_steps):
- 机制:
num_inference_steps决定了采样过程中迭代的次数。在 RF 中,这对应于求解 ODE 的离散化步数。 - 对轨迹的影响: 更多的步数意味着更精细地沿着学习到的速度向量场进行积分,从而更准确地遵循“直线路径”。这通常会导致更高质量、更稳定的图像生成。较少的步数可能导致轨迹偏离理想路径,从而降低图像质量或引入伪影。
- 示例:
- 提示: “A serene landscape with a calm lake and distant mountains.”
- 高
num_inference_steps的轨迹: 轨迹会平滑地从噪声过渡到清晰的湖泊和山脉图像,水面平静,山峦细节分明,整体画面和谐。 - 低
num_inference_steps的轨迹: 轨迹可能不够平滑,导致图像中出现噪点、模糊不清的区域,或者水面扭曲、山脉形状不自然,整体画面质量下降。FLUX.1[schnell] 就是通过减少采样步数来优化速度,但可能会牺牲一些细节和提示保真度。
- 机制:
-
初始噪声 (Initial Noise) 和随机种子 (Seed):
- 机制: 采样总是从一个随机的初始噪声 x 0 x_0 x0 开始(通常是标准高斯分布 N ( 0 , 1 ) N(0,1) N(0,1))。这个初始噪声由随机种子决定。
- 对轨迹的影响: 不同的初始噪声会提供不同的起点,即使在相同的引导和步数下,也会导致不同的采样轨迹。由于速度向量场是复杂的,即使是微小的起点差异,也可能在迭代过程中被放大,导致完全不同的最终图像。
- 示例:
- 提示: “A cute cat playing with a ball.”
- 种子 A 对应的轨迹: 可能从一个看起来像猫的模糊形状开始,轨迹逐渐细化,最终生成一只橘猫在草地上玩耍的图像。
- 种子 B 对应的轨迹: 从另一个不同的模糊形状开始,轨迹演化出另一只黑猫在室内玩毛线球的图像。
- 核心: 尽管提示相同,但初始噪声的不同导致了生成内容的具体细节、构图、甚至猫的种类和场景的差异。
-
模型本身的结构和训练 (Transformer Architecture & Training):
- 机制: FLUX.1 的Transformer架构(特别是Double-Stream和Single-Stream块)以及其Rectified Flow训练范式,共同定义了模型所学习到的速度向量场的“形状”和“特性”。
- 对轨迹的影响:
- Multi-Modal Attention: 确保了文本和图像潜在表示之间的双向交互,使得轨迹能够更好地理解并遵循复杂的文本提示,从而影响生成图像的内容和风格的准确性。
- AdaLN (Adaptive Layer Normalization): 允许模型在每个层根据输入提示和指导信号动态调整行为,这意味着采样轨迹在不同条件下(例如,不同的
guidance_scale)会以更灵活、更适应的方式演化。 - RoPE (Rotary Positional Embeddings): 改善了模型对图像中空间关系的理解,确保了采样轨迹在生成物体布局和结构时的一致性和合理性。
- 示例:
- 如果模型没有强大的多模态注意力,那么即使提示很具体,轨迹也可能无法准确捕捉提示中的所有元素,导致生成图像与提示不符。
- 如果 AdaLN 效果不佳,那么在调整
guidance_scale时,轨迹可能会不稳定,导致图像质量剧烈波动。FLUX.1 的设计旨在使轨迹在不同条件下都能保持稳定和高质量的演化。
【总结】
采样轨迹是模型从随机性走向确定性的路径。在FLUX.1中,它不是简单的去噪,而是沿着一个学习到的“速度场”进行的确定性积分。guidance_scale、num_inference_steps 和初始噪声(由随机种子决定)是直接影响这条轨迹的关键参数,从而塑造最终图像的内容、风格、细节和对提示的遵循程度。而模型本身的架构和训练方法,则决定了采样轨迹的**“潜力”和“稳定性”**,即它能够在多大程度上生成高质量、多样化且符合用户意图的图像。
除了提到的几个参数,还有哪些潜在的因素(例如模型架构的微调或训练数据的特性)可能影响 FLUX.1 的采样轨迹和生成结果?
除了直接影响采样过程的参数(如 guidance_scale、num_inference_steps 和随机种子)之外,模型架构的微调和训练数据的特性是影响 FLUX.1 采样轨迹和最终生成结果的更深层次、更根本的潜在因素。这些因素塑造了模型学习到的速度向量场本身,从而决定了轨迹可能的形状、收敛行为以及能够生成的图像类型。
以下是这些潜在因素的详细分析:
一、模型架构的微调 (Architectural Refinements)
FLUX.1 已经采用了 Transformer 架构,但其中的微调和设计选择仍然至关重要:
-
Transformer 块的具体配置(层数、隐藏维度、注意力头数):
- 影响: 这些配置决定了模型捕获复杂关系的能力。更多的层和更大的隐藏维度通常意味着模型能学习到更丰富、更抽象的特征表示,从而使得速度向量场更加精细和准确。例如,FLUX.1 的 12B 参数量就暗示了其庞大的容量。
- 对轨迹的影响: 一个更强大的 Transformer 主干可以学习到更精确的速度向量场,使得采样轨迹能更稳定地从噪声过渡到高质量图像,减少伪影和不一致性。反之,一个容量不足的模型可能导致轨迹不稳定,无法有效捕捉图像的复杂细节或文本提示的微妙之处。
-
Double-Stream 和 Single-Stream 块的比例与排列:
- 影响: 论文提到 FLUX.1 结合了 19 个 Double-Stream 块和 38 个 Single-Stream 块。这两种块在“权重共享”和“计算风格”上存在差异。
- Double-Stream (权重不共享,顺序计算): 允许模型为文本和图像模态学习独立的表示,并在注意力层之后顺序处理 MLP,可能有助于更精细的模态专业化和更深层次的层间交互。
- Single-Stream (权重共享,并行计算): 促进模态间的紧密集成和计算效率,可能有助于更快的处理和更广阔的表示能力。
- 对轨迹的影响: 这种混合架构反映了效率与专业化的权衡。不同的比例或排列可能会改变模型处理跨模态信息的方式。例如,如果 Double-Stream 块过少,模型可能在处理复杂、多元素提示时,无法充分解耦和专业化不同模态的信息,导致轨迹偏离预期,生成结果可能在细节上不够精确。反之,过多的 Double-Stream 块可能增加计算成本,并可能减慢采样轨迹的演化速度。
- 影响: 论文提到 FLUX.1 结合了 19 个 Double-Stream 块和 38 个 Single-Stream 块。这两种块在“权重共享”和“计算风格”上存在差异。
-
AdaLN (Adaptive Layer Normalization) 的实现细节:
- 影响: AdaLN 通过外部条件(如文本或图像嵌入)动态调整中间激活,使得模型行为更具适应性。其内部参数(
scale、shift、gate)的计算方式和应用位置至关重要。 - 对轨迹的影响: AdaLN 的质量直接决定了模型响应条件的能力。如果 AdaLN 设计不佳,模型可能无法有效利用文本提示进行条件生成,导致采样轨迹对
guidance_scale或文本提示的改变不够敏感,或者在生成过程中“遗忘”提示信息,最终图像与文本对齐性差。
- 影响: AdaLN 通过外部条件(如文本或图像嵌入)动态调整中间激活,使得模型行为更具适应性。其内部参数(
-
编码器(文本编码器、VAE编码器)的选择和训练:
- 影响: FLUX.1 使用 CLIP 和 T5 作为文本编码器,并训练了一个卷积自编码器。这些预训练组件的质量和特性直接决定了模型能够理解和表示输入信息的能力。
- 文本编码器: 决定了文本提示的语义丰富度、上下文理解能力以及对细微差别的捕捉能力。
- VAE编码器: 决定了潜在空间的表示质量,即潜在空间是否能高效且无损地编码图像信息,并影响最终图像的视觉保真度。
- 对轨迹的影响:
- 文本编码器: 如果文本编码器无法区分提示中的细微语义差异(如“a slightly snowy day”和“a heavily snowy day”),那么即使核心 Transformer 架构再强大,采样轨迹也无法在潜在空间中找到对应的差异,导致生成图像无法精确体现这些细微差别(如论文图2所示)。
- VAE编码器: 潜在空间的质量直接影响了采样轨迹的“目的地”——即最终解码出的图像的视觉质量。如果 VAE 编码器引入了信息损失或伪影,那么无论采样轨迹多么完美,最终的像素图像也可能出现问题。
- 影响: FLUX.1 使用 CLIP 和 T5 作为文本编码器,并训练了一个卷积自编码器。这些预训练组件的质量和特性直接决定了模型能够理解和表示输入信息的能力。
二、训练数据的特性 (Training Data Characteristics)
FLUX.1 的训练数据是其性能的基石,其特性对采样轨迹和生成结果有深远影响:
-
数据规模与多样性:
- 影响: 庞大的、多样化的训练数据集(如 LAION-5B 及其变体)使模型能够学习到广泛的概念、风格和对象。
- 对轨迹的影响: 训练数据规模越大、多样性越好,模型学习到的速度向量场就越“全面”,能够覆盖更广阔的图像空间。这意味着采样轨迹可以从更广泛的起点(噪声)出发,并收敛到更多样化、更具创意的图像。如果数据缺乏多样性,轨迹可能会陷入局部最优,生成重复性高或缺乏细节的图像。
-
数据质量(图像质量、文本-图像对齐质量):
- 影响: 高质量的图像和精确对齐的文本描述是学习良好速度向量场的关键。
- 对轨迹的影响: 如果训练数据中存在大量低质量图像或文本-图像对齐不佳的样本,模型学习到的速度向量场可能会“混乱”或“不准确”。这将导致采样轨迹在生成过程中出现不确定性,可能产生低质量、不符合提示或出现奇怪伪影的图像。FLUX.1 强调其在“prompt adherence”和“image quality”方面的 SoTA 性能,这强烈暗示了其训练数据的高质量。
-
数据分布(特定领域、罕见概念):
- 影响: 训练数据中包含特定领域(如汽车场景)或罕见概念的样本,将使模型在这些领域表现出色。
- 对轨迹的影响: 如果训练数据中包含丰富的汽车场景和各种天气/照明条件(如论文图1、图2所示),模型学习到的速度向量场就能很好地理解和生成这些特定场景。这意味着采样轨迹在处理“汽车”、“雨天”、“雾天”等提示时,能够准确地引导生成过程。反之,如果模型未在“boat-trailer”或“upside-down crashed car”等罕见概念上进行充分训练,采样轨迹就难以准确地将这些抽象概念转化为视觉特征,导致生成结果不佳(如论文图4所示,FLUX.1在这方面表现优秀,说明其训练数据覆盖了这些概念)。
-
预训练策略和微调数据:
- 影响: 模型是否在特定任务上进行了微调(例如,FLUX.1[dev] 是从 [pro] 版本蒸馏而来,FLUX.1[schnell] 是通过
timesteps-distillation训练的)。 - 对轨迹的影响:
- 蒸馏 (Distillation): 通过蒸馏训练,模型学习模仿一个更大、更强的“教师模型”的输出。这会使采样轨迹变得更“直接”或“高效”,能够在更少的步数内达到高质量结果。然而,这可能会牺牲一些原始教师模型的泛化能力或对细微差别的捕捉能力。
- 特定任务微调: 如果模型在一个特定风格、领域或任务(如超分辨率、修复)的数据集上进行微调,采样轨迹会相应地调整,使得模型在该任务上生成更优化的结果,但在其他领域可能表现不如通用模型。
- 影响: 模型是否在特定任务上进行了微调(例如,FLUX.1[dev] 是从 [pro] 版本蒸馏而来,FLUX.1[schnell] 是通过
【总结】
FLUX.1 的采样轨迹和最终生成结果,是其精心设计的 Transformer 架构(包括 Double-Stream/Single-Stream 块的平衡、AdaLN 的有效性以及预训练编码器的质量)和高质量、多样化、领域覆盖广泛的训练数据共同作用的产物。这些底层因素决定了模型学习到的速度向量场的“地图”,从而从根本上塑造了采样轨迹的形状、方向和最终目的地,使其能够实现“有深度的清晰”——在保持高图像质量和多样性的同时,实现对文本-图像的高度对齐。
分辨率
所需的分辨率决定了初始(潜在)噪声样本 z 0 ∼ N ( 0 , 1 ) z_0 \sim \mathcal{N}(0, 1) z0∼N(0,1) 的空间维度。它还用于定义图像标识符(img ids)——一组每个 token 的指示符,用于指向 token 在二维网格上的空间位置。给定像素空间中的目标分辨率 ( H , W ) (H, W) (H,W),对应的潜在维度 ( h , w ) (h, w) (h,w) 计算如下:
h = H / / VAE scale , w = W / / VAE scale h = H \ // \ \text{VAE}_{\text{scale}}, \quad w = W \ // \ \text{VAE}_{\text{scale}} h=H // VAEscale,w=W // VAEscale
其中 VAE scale = 8 \text{VAE}_{\text{scale}} = 8 VAEscale=8。
图像 token 网格进一步下采样至维度 ( h / / 2 , w / / 2 ) (h // 2,\ w // 2) (h//2, w//2),并且每个 token 被分配一个形式为 ( t , h ^ , w ^ ) (t,\ \hat{h},\ \hat{w}) (t, h^, w^) 的唯一标识符,其中 h ^ ∈ [ 0 : h − 1 ] \hat{h} \in [0 : h-1] h^∈[0:h−1], w ^ ∈ [ 0 , w − 1 ] \hat{w} \in [0, w-1] w^∈[0,w−1],表示 token 在二维空间网格上的位置。
文本标识符(text ids) 使用与图像标识符相同的结构初始化,但所有 token 的 (t = h = w = 0)。形式化地:
text ids = n ⋅ ( 0 , 0 , 0 ) \text{text ids} = n \cdot (0, 0, 0) text ids=n⋅(0,0,0)
其中 (n) 是 T5 模型中的最大 token 数(= 512)。
【分辨率总结】:
阐述了 FLUX.1 模型在文本到图像生成任务中,如何根据用户指定的分辨率来初始化和处理图像及文本相关的空间标识符。它描述了从像素空间分辨率到潜在空间维度的转换,以及生成图像令牌和文本令牌的独特三维位置编码 (t, ĥ, ŵ) 的过程,为后续的迭代精炼阶段提供结构化输入。
【解释】:
在 FLUX.1 的预处理阶段,分辨率 (resolution) 是一个关键输入参数,它决定了生成图像的初始潜在表示。具体来说,用户指定的像素空间分辨率 (H, W) 会被下采样到潜在空间维度 (h, w),其计算方式为 h = H / / V A E s c a l e h = H // VAE_{scale} h=H//VAEscale 和 w = W / / V A E s c a l e w = W // VAE_{scale} w=W//VAEscale,其中 V A E s c a l e VAE_{scale} VAEscale 固定为 8。这一转换是因为 FLUX.1 与潜在扩散模型 (LDM) 类似,在压缩的潜在空间中进行操作,以提高计算效率。
在潜在空间中,需要为图像和文本生成空间位置标识符。
- 图像-令牌网格 (image-token grid):在计算出潜在维度 (h, w) 后,图像-令牌网格会被进一步下采样到 ( h / / 2 , w / / 2 ) (h // 2, w // 2) (h//2,w//2) 的尺寸。每个图像令牌被分配一个独特的三维标识符 (t, ĥ, ŵ)。这里的 h ^ ∈ [ 0 : h − 1 ] ĥ \in [0 : h-1] h^∈[0:h−1] 和 w ^ ∈ [ 0 , w − 1 ] ŵ \in [0, w-1] w^∈[0,w−1] 表示令牌在二维空间网格上的位置。
t维度在此处并未明确解释其具体含义,但在上下文(如图 7 所示的“per-token positional embeds”的 3D 令牌索引 (t, h, w) 提取)中,可能与时间步或某种层级信息相关。 - 文本 ID (text_ids):文本 ID 的初始化结构与图像 ID 类似,但所有令牌的
t,h,w值都被设置为 0。这表明文本令牌主要依赖其在序列中的位置,而不具有图像令牌那样的显式二维空间坐标。n表示 T5 文本编码器最大令牌数,为 512。文本 ID 的这种结构设计,可能是为了确保文本令牌在后续的注意力机制中能够与图像令牌对齐,并支持多模态交互。
这些生成的图像 ID 和文本 ID 在后续的 FLUX Transformer 块中用于提取每令牌位置嵌入 (per-token positional embeds),结合时间步和引导嵌入 (temb),共同支持注意力机制,从而实现文本条件下的图像生成。
【关键词】:
- 分辨率 (resolution):在文本到图像生成任务中,指用户期望的最终图像的像素尺寸 (H, W),它决定了初始潜在噪声样本的空间维度,并影响后续令牌网格的构建。
- 潜在空间维度 (latent dimensions):指原始像素空间图像经过 VAE 编码器压缩后所处的低维表示空间,其维度 (h, w) 小于原始图像像素维度,用于提高计算效率。
- VAEscale (VAEscale):一个固定值为 8 的缩放因子,用于将像素空间分辨率 (H, W) 转换为潜在空间维度 (h, w),即 h = H / / V A E s c a l e h = H // VAE_{scale} h=H//VAEscale 和 w = W / / V A E s c a l e w = W // VAE_{scale} w=W//VAEscale。
- 图像-令牌网格 (image-token grid):在潜在空间中,将图像表示离散化为一系列令牌的网格结构,其维度为 ( h / / 2 , w / / 2 ) (h // 2, w // 2) (h//2,w//2),每个令牌代表图像中的一个局部区域。
- 三维标识符 (3D token indices):为每个图像或文本令牌分配的独特标识符,形式为 ( t , h ^ , w ^ ) (t, ĥ, ŵ) (t,h^,w^),用于编码令牌的时间和空间位置信息,特别是在二维网格上的位置 ( h ^ , w ^ ) (ĥ, ŵ) (h^,w^)。
- 文本 ID (text_ids):用于文本令牌的位置标识符,其结构与图像 ID 类似,但所有令牌的
t,h,w值均设置为 0,表明其主要关注序列位置而非显式二维空间。 - 最大令牌数 (maximal number of tokens):指 T5 文本编码器能够处理的最大令牌数量,此处指定为 512,影响文本 ID 的维度 n。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0


 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)