XivMind开源项目使用手册 V0.7.0
XivMind开源项目使用手册 V0.7.0
1. 产品简介
1.1 什么是 XivMind?
XivMind 是一款开源的现代化 arXiv 论文研究助手,专为科研人员、学生及学术爱好者打造,可高效完成学术论文的发现、管理、阅读与深度分析。它原生支持 Web 部署,本地启动前后端服务后,通过浏览器即可直接使用;同时基于 Electron 技术封装了桌面客户端,安装后无需额外配置,双击即可运行。
项目地址:https://github.com/uwjia/XivMind
Windows 桌面端安装包:https://github.com/uwjia/XivMind/releases/download/v0.7.0/XivMind.Setup.0.7.0.exe
核心特性:
- 📚 卡片式论文浏览
- 🔍 按分类和日期进行高级搜索和筛选
- 🔖 收藏论文以便后续阅读
- 📥 下载 PDF 并跟踪进度
- 📖 PDF 阅读器,支持丰富的标注功能
- 多种标注类型:高亮、下划线、删除线、批注、绘图
- 可自定义标注颜色(黄、绿、蓝、粉、紫)
- 可调节绘图线条粗细
- 直观的编辑和删除标注界面
- 阅读进度自动保存(页码、缩放、视图模式)
- 单页和连续滚动视图模式
- 缩放控制,支持快速预设
- 侧边栏显示缩略图和大纲导航
- 🕸️ 知识图谱可视化
- 发现论文之间的关系
- 识别研究聚类和趋势
- 多种布局选项:力导向、圆形、层级
- 交互式节点探索,支持相似度过滤
- 🤖 AI 助手解答论文相关问题
- 多种 LLM 提供商:OpenAI、Anthropic、GLM(智谱 AI)、Ollama(本地)
- 论文语义搜索
- 基于论文库的问答
- 动态技能系统,支持自定义任务
- 🤖 SubAgents - 用于复杂研究任务的 AI 代理
- 研究助手:文献搜索和分析
- 分析助手:深度论文分析和比较
- 写作助手:学术写作支持
- 动态代理创建,支持自定义工具和技能
- 🧠 长记忆系统,提供个性化 AI 体验
- 核心记忆:用户画像,包含研究兴趣和偏好设置
- 对话记忆:对话历史的语义搜索
- 知识库记忆:笔记和见解的长期存储
- 👥 Team - 多智能体协作系统
- 自动任务复杂度分析
- 智能任务分解为子任务
- 智能体自动选择(研究、分析、写作智能体)
- 并行执行提升效率
- 多智能体结果综合
- 🔀 Workflow - 可视化工作流编辑和执行系统
- 拖拽式节点编辑器
- 多种节点类型:输入、分析、分解、智能体、条件、并行、综合、输出、工具、技能
- 预置模板:快速摘要、论文分析、多智能体协作、自适应工作流
- 实时执行监控
- JSON 格式导入/导出工作流
- 📊 图标彩色风格/极简风格切换
- 🌙 深色/浅色主题切换
- 📱 响应式设计
- 🎨 现代化 UI,流畅动画
1.2 技术架构
2. 快速入门
2.1 程序安装
官方已上架 XivMind Windows 桌面安装程序,下载链接:https://github.com/uwjia/XivMind/releases/download/v0.7.0/XivMind.Setup.0.7.0.exe
用户下载安装程序后,双击文件即可完成一键安装,安装完成后,双击桌面图标便可正常运行 XivMind。
补充说明:受文件体积约束,GitHub 正式发行版仅提供 Windows 11 适配的 CPU 版本。若需使用 GPU 加速的高性能版本,需自行下载源码,依托项目内置构建脚本手动编译部署。GPU加速版在论文的语义搜索方面会有很大的性能提升。
2.2 准备论文摘要数据
历史摘要数据
在侧边栏点击「Data Manager」,即可进入历史摘要数据管理页面,批量下载过往论文摘要。由于 arXiv 官方存在 API 访问频次限制,请合理、合规地进行数据获取与使用。下载后的摘要会持久化存储至本地数据库,脱离网络也可离线查阅,详细操作可参见「5.10 Data Manager」章节。
每日摘要更新
通过侧边栏「Listings」入口,可进入每日摘要更新页面,一键获取当日最新上线的论文摘要。完整使用指引,请查阅「5.2 Listings」相关章节。
3. 开发运行
3.1 环境要求
| 组件 | 最低版本 | 说明 |
|---|---|---|
| Node.js | 18+ | 前端运行环境 |
| Python | 3.10+ | 后端运行环境 |
| Docker | 最新版 | Milvus 模式需要(可选) |
3.2 安装步骤
步骤一:获取代码
git clone https://github.com/uwjia/XivMind.git
cd XivMind
步骤二:配置后端
cd backend
cp .env.example .env
编辑 .env 文件:
# 数据库配置
DATABASE_TYPE=LanceDB # 开发模式使用 SQLite 或者 LanceDB
SQLITE_DB_PATH=./data/xivmind.db
DOWNLOAD_DIR=./downloads
# LLM 配置(可选,也可在界面中配置)
LLM_PROVIDER=openai
LLM_MODEL=gpt-4o-mini
OPENAI_API_KEY=your-api-key
步骤三:启动后端
Windows:
start.bat install # 首次运行,安装依赖
start.bat dev # 开发模式启动
Linux/Mac:
chmod +x start.sh
./start.sh install # 首次运行,安装依赖
./start.sh dev # 开发模式启动
备注:
需要用GPU加速时使用项目根目录下的 requirements-gpu.txt 安装依赖,强烈建议安装,因为在生成嵌入向量时GPU运算相对CPU有很大的提升。
步骤四:启动前端
cd ..
npm install
npm run dev
步骤五:访问应用
打开浏览器访问:http://localhost:5173

4. 界面导航
4.1 侧边栏导航
应用左侧设有固定导航栏,包含以下入口:
| 图标 | 名称 | 功能 | 说明 |
|---|---|---|---|
| 🏠 | Home | 首页 | 浏览按日期、类别的 arXiv 论文 |
| 📋 | Listings | 论文列表 | 浏览当天发布的论文,可按日期查看每天的发布列表 |
| 🔖 | Bookmarks | 收藏管理 | 查看和管理已收藏的论文 |
| ⬇️ | Downloads | 下载管理 | 管理论文 PDF 下载任务,查看下载进度和历史 |
| 👤 | Followed | 关注作者 | 查看关注的作者及其最新论文 |
| 🤖 | Assistant | AI 助手 | 与 AI 助手对话,获取论文相关的智能问答服务 |
| 🔧 | Skills | 技能管理 | 管理和配置 AI 技能模块 |
| 🔗 | SubAgents | 子代理管理 | 配置和管理智能子代理 |
| 👥 | Team | 团队协作 | 多智能体团队协作的流程图 |
| 💾 | Memory | 记忆管理 | 管理 AI 的长期记忆和上下文信息 |
| 📊 | Ranking | 作者排名 | 查看基于 PageRank 算法的作者影响力排名 |
| 📅 | Data Manager | 数据管理 | 管理本地数据库,包括导入、导出、清理等操作 |
单击左上角的按钮可以收缩或展开
4.2 顶部工具栏
顶部工具栏存放了常用的一些全局工具:搜索面板、PDF阅读历史、Note笔记面板、彩色/简约模式切换
| 图标 | 名称 | 功能 | 说明 |
|---|---|---|---|
| 🔍 | Search | 搜索论文 | 打开搜索面板,支持 arXiv API、数据库、语义搜索 |
| 🕐 | History | 阅读历史 | 打开阅读历史面板,查看最近阅读的论文 |
| 📝 | Notes | 笔记面板 | 打开笔记面板,管理论文笔记;显示笔记数量徽章 |
| 🎨 | Icon Style | 图标样式 | 切换图标显示样式(彩色/简约模式) |
5. 侧边栏导航
5.1 Home
首页是历史论文浏览的主界面,展示指定日期、类别的 arXiv 论文列表。
5.1.1 顶部工具栏
顶部工具栏根据当前页面动态显示相关操作按钮:
| 图标 | 名称 | 功能 | 说明 |
|---|---|---|---|
| 📅 | Date | 选择日期 | 打开日期选择器,筛选指定日期的论文(列表视图可用) |
| 📖 | Category | 选择分类 | 打开分类选择器,筛选指定分类的论文(列表视图可用) |
| 📁 | Filter | 分类过滤 | 打开分类抽屉,显示各分类的论文数量(列表视图可用) |
| 📋 | Toggle View | 切换视图 | 切换论文卡片的显示模式(简约视图/详细视图)(列表视图可用) |
| 🔗 | Graph | 切换图谱 | 切换列表视图/知识图谱视图 |
| 📊 | Analysis | AI 分析 | 跳转到当日论文的 AI 分析页面(列表视图可用) |
| 🔄 | Refresh | 刷新论文 | 重新加载论文数据(列表视图可用) |
5.1.2 日期选择
点击顶部日期按钮,弹出日期选择器:

- 选择日期后双击或者单击“Confirm”按钮会自动加载该日论文
- 支持快速跳转到今天、昨天、前7天
- 支持选择从1991年-2026年的任何一天
- 绿色勾勾表示该天的论文已经存储
- 紫色波浪线表示该天的论文已经生成嵌入向量
5.1.3 分类筛选
点击分类按钮,弹出分类选择面板:

- 选择分类后自动加载该日论文
- 左边文本是学科的全称,右边文本是学科的简称
支持的学科分类:
- cs.AI (人工智能)
- cs.CL (计算与语言)
- cs.CV (计算机视觉)
- cs.LG (机器学习)
- cs.RO (机器人)
- … 更多分类
5.1.4 论文卡片
每篇论文以卡片形式展示,单击每一篇论文的序号可以展开/隐藏摘要信息:

卡片信息:
- 论文标题、主类别、序号
- 作者列表
- 摘要预览
- 作者备注(页数、会议等)(如有)
- 期刊引用(如有)
- 论文id、学科分类标签(前三个类别)、发布日期、更新日期(如有)
卡片操作:
- doi 链接:打开论文的唯一标识地址(如有)
- arxiv 链接:打开arxiv链接地址
- pdf 链接:打开arxiv的PDF论文下载地址
- 下载:下载论文 PDF(下载完成后可以单击此处使用本地PDF阅读器打开论文)
- 阅读:使用定义的内置PDF阅读器查看论文
- 收藏:将论文添加到收藏夹
5.1.5 视图切换
首页支持两种视图模式:
- 详细卡片:显示完整摘要
- 简洁卡片:仅显示标题和类别

5.1.6 学科过滤
在工具条单击“Show Categories”图标按钮,页面右侧边显示出一个学科简写的侧边栏,学科过滤可以将每天的论文按照类别进行统计与过滤。
- 单击CS:显示该日期全部的论文
- 单击各个学科的简写:论文列表只会显示该日期和该学科的论文
- 每个学科旁边的数字统计了该天发表该学科的论文数量(最大页数为50项时,每一页只能统计最多50篇的论文,翻页后重新统计。如在设置页面中扩大最大页数为1000,就可以统计当天全部的论文)
5.1.7 知识图谱
知识图谱可视化展示论文之间的语义关系,帮助发现研究趋势和关联。知识图谱依赖于论文的嵌入向量数据,只在数据库为Milvus生产模式时启用,而在数据库为SQLite开发模式时不可用。

界面组成:
- 节点:代表一篇论文
- 边:表示论文间的语义相似度
- 颜色:不同颜色代表不同学科分类
交互操作
| 操作 | 方式 | 效果 |
|---|---|---|
| 查看详情 | 点击节点 | 显示论文基本信息 |
| 拖拽节点 | 鼠标拖拽 | 调整节点位置 |
| 缩放 | 滚轮 | 放大/缩小图谱 |
| 平移 | 拖拽空白区域 | 移动视图 |
布局算法
支持三种布局模式:
- 力导向布局:节点间相互排斥,相似节点靠近
- 圆形布局:节点按相似度排列成圆形
- 层级布局:按层级结构排列节点
相似度过滤
调节相似度阈值滑块,过滤低相似度的边:
- 阈值越高,显示的连接越少
- 阈值越低,显示的连接越多
5.1.8 论文详情
点击论文卡片的标题栏,进入论文详情页。
详情界面

展示信息:
- 论文标题
- 作者列表(带机构信息)
- 完整摘要
- 期刊引用(如有)
- 学科分类
- 发布日期
- arXiv 链接
- PDF 链接
- DOI 链接(如有)
操作按钮
- 收藏/取消收藏:管理收藏状态
- 下载 PDF:启动下载任务
-
- 阅读 PDF:下载成功后可以使用内置的PDF阅读器打开论文
- 官方论文摘要页:跳转到 arXiv 提供的摘要页面
- 官方论文PDF:跳转到 arXiv 提供的PDF页面
- 论文项目地址(如有):跳转到论文提供的项目仓库地址
相关论文
展示与该论文相似的其它论文列表。它是根据论文标题和摘要在后台进行查找出最相似的论文,这个功能需要提前给论文数据构建Embedding向量,具体构建步骤可以查看【数据管理】章节。
展示信息:
- 论文id、标题、相似度
- 鼠标悬浮展示论文的摘要、类别、发表日期
- 单击【相似度】悬停展示论文的完整摘要、类别、发表日期
5.2 Listings
浏览当天发布的论文,可按日期查看每天的发布列表。该页面实质是抓取网页 https://arxiv.org/list/cs/new 的内容并保存到本地数据库。每次都要手动点击第一个图标按钮Fetch,第二次单击时会重新抓取并覆盖和更新数据库内容(第一次抓取失败后往往需要手动单击第二次)。三个标签页分别为New(新发表)、Cross(交叉发表)、Replacement(更新发表)。由于数据库只会保存最新一份的论文摘要,所以每日发布的Replacement论文可能会覆盖旧的论文,这会导致每日的Replacement论文数量会发生变化。在使用方式上,我建议在【5.10 Data Manager】中获取当天和昨天的论文摘要,再返回到本页面获取今天的论文摘要,这样可以减少API的调用,避免触发官方的频率限制。
操作按钮
| 图标 | 名称 | 功能 | 说明 |
|---|---|---|---|
| 📅 | Date Picker | 选择日期 | 选择日期查看历史 listings,默认显示最新 |
| ✕ | Clear Date | 清除日期 | 清除日期筛选,返回显示最新 listings(选择日期后显示) |
| ⬇️ | Fetch | 获取新列表 | 从 arXiv 获取最新的论文列表数据 |
| 📁 | Filter | 分类过滤 | 打开分类抽屉,按分类筛选论文 |
| 📋 | Toggle View | 切换视图 | 切换论文卡片的显示模式(简约视图/详细视图) |
| </> | Code Filter | 代码过滤 | 筛选包含代码仓库链接的论文,激活时高亮显示 |
| 🔄 | Refresh | 刷新列表 | 重新加载当前 listings 数据 |
5.3 Bookmarks
收藏页面管理所有已收藏的论文。
功能特性:
- 按收藏时间排序
- 支持关键词搜索
- 直接下载,显示下载状态
- 可以直接取消收藏
批量操作
- 批量下载:选中多篇论文批量下载
- 批量删除:取消收藏选中的论文
5.4 Downloads
下载页面展示所有下载任务的状态。
任务状态:
- ⏳ 等待中:任务排队等待
- 🔄 下载中:正在下载,显示进度
- ✅ 已完成:下载成功
- ❌ 失败:下载失败,显示错误信息
任务操作
| 操作 | 说明 |
|---|---|
| 打开文件 | 打开已下载的 PDF |
| 重试 | 重新下载失败的任务 |
| 取消 | 取消正在进行的任务 |
| 删除 | 删除任务记录 |
5.5 Followed
该页面可以查看关注的论文作者,单击该作者可以查询其发布过的历史论文、合作者列表等。在Home、Listings页面的论文列表中,单击某一篇论文的某个作者进入一个新页面,在它的右上角有一个关注按钮,单击该按钮即可关注该作者。
5.6 Assistant
AI 助手提供智能问答、语义搜索和技能执行功能。
5.6.1 模式切换
AI 助手支持两种模式:
搜索模式:
- 在论文库中进行语义搜索
- 输入自然语言查询,返回相关论文
问答模式:
- 基于论文内容回答问题
- 支持多轮对话
5.6.2 搜索模式

使用方法:
- 选择"搜索"模式
- 输入搜索关键词或问题
- 系统返回语义相关的论文列表
- 在返回结果的底部有复制按钮、重新生成按钮
示例查询:
- “transformer attention mechanism”
- “图像分割最新进展”
- “reinforcement learning for robotics”
5.6.3 问答模式

使用方法:
- 选择"问答"模式
- 输入问题
- 系统基于论文库内容生成回答
示例问题:
- “这篇论文的主要贡献是什么?”
- “总结一下这篇论文的方法论”
- “这篇论文与之前工作的区别是什么?”
5.7 Skills
技能系统允许用户创建和执行自定义任务。
5.7.1 技能管理页面

功能:
- 查看所有可用技能
- 执行技能任务
- 创建自定义技能
5.7.2 内置技能
| 技能 | 功能 | 输入 |
|---|---|---|
| 论文摘要 | 生成论文摘要 | 论文 ID |
| 论文翻译 | 翻译论文内容 | 论文 ID、目标语言 |
| 引用生成 | 生成引用格式 | 论文 ID、引用格式 |
| 相关论文 | 查找相似论文 | 论文 ID |
5.7.3 创建自定义技能
在 backend/skills/ 目录下创建 SKILL.md 文件:
---
name: my-custom-skill
description: 我的自定义技能
icon: file-text
category: analysis
requires_paper: true
---
# 我的自定义技能
请分析以下论文的 {paper.title}:
{paper.abstract}
请从以下几个方面进行分析:
1. 研究背景
2. 主要贡献
3. 方法论
4. 实验结果
5.8 SubAgents
SubAgents 是 AI 代理系统,可以执行复杂的研究任务。
5.8.1 SubAgents 页面

5.8.2 内置代理
研究助手 (Research Assistant):
- 文献搜索和分析
- 获取论文详情
- 执行技能分析
分析助手 (Analysis Assistant):
- 深度论文分析
- 方法论评估
- 趋势发现
写作助手 (Writing Assistant):
- 文献综述写作
- 摘要生成
- 翻译润色
5.8.3 执行任务
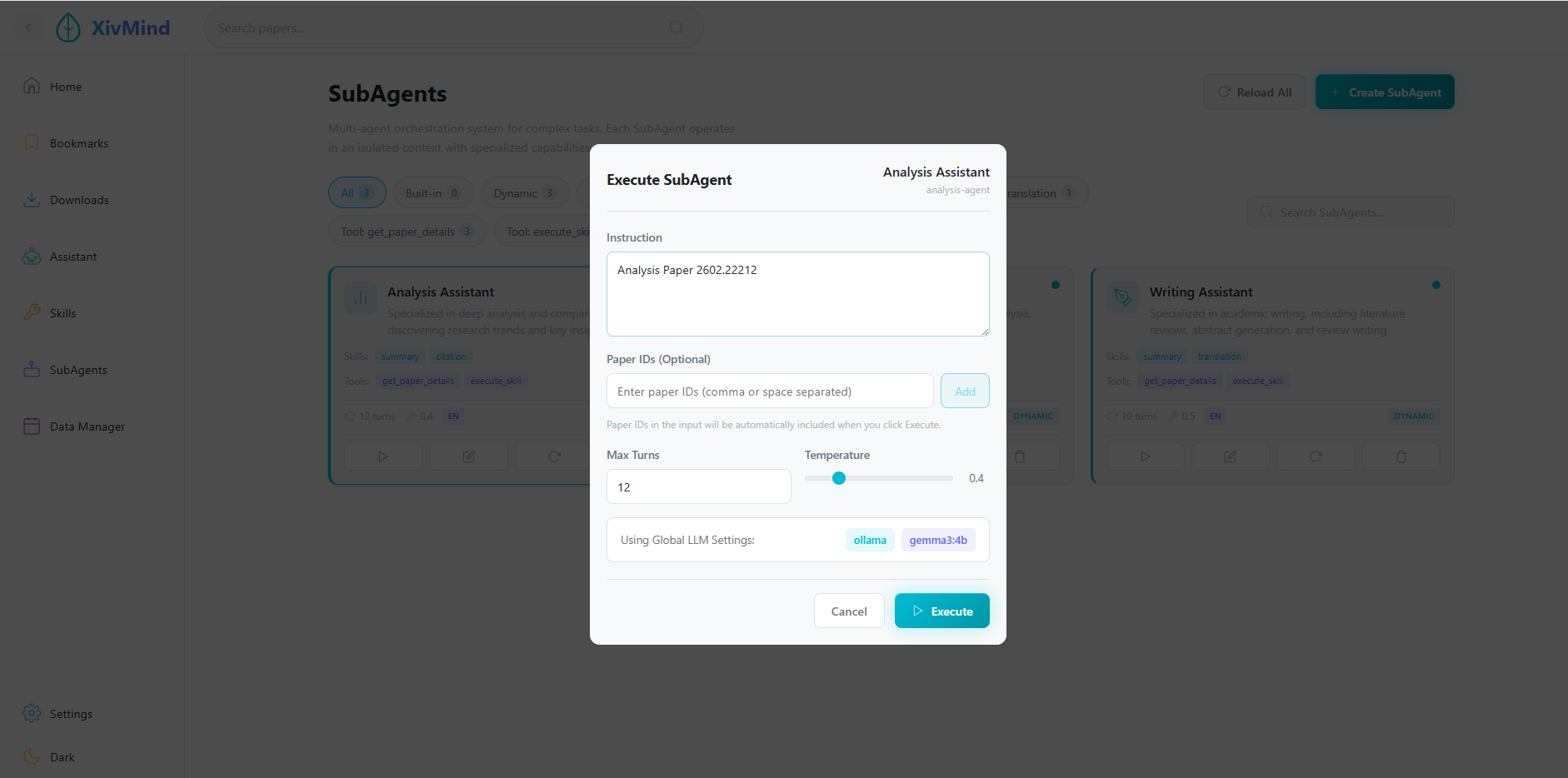
操作步骤:
- 选择一个代理
- 输入任务指令
- 可选:添加论文 ID
- 点击"执行"
示例指令:
- “搜索关于 transformer 的最新论文”
- “分析这篇论文的方法论”
- “写一篇关于机器学习的文献综述”
5.8.4 查看结果

结果展示:
- 任务状态
- 执行轮次
- 输出内容
- 消息历史
5.8.5 创建自定义代理
在 backend/subagents/ 目录下创建 AGENT.md 文件:
---
id: my-agent
name: 我的代理
description: 自定义代理描述
icon: search
skills:
- summary
tools:
- search_papers
- get_paper_details
max_turns: 15
temperature: 0.3
---
# 我的代理
你是一个专业的助手,专门...
## 工具调用格式
[TOOL: tool_name({"arg1": "value1"})]
## 可用工具
- search_papers: 搜索论文
- get_paper_details: 获取论文详情
5.9 Ranking
查看基于 PageRank 算法的作者影响力排名。首次使用需要有历史的论文数据摘要,它会根据PageRank算法分析所有论文的作者并得到最终的作者排名。
5.10 Data Manager
数据管理页面用于管理论文数据存储。
5.10.1 年度视图

功能:
- 查看全年数据存储情况
- 按月统计论文数量
- 快速导航到特定月份
- 可以选择从1991年-2026年期间的任何一年
5.10.2 月度视图

功能:
- 查看每日论文数量
- 获取特定日期的论文
- 对特定日期的论文生成嵌入向量(应用于智能检索与知识图谱)
- 清除缓存数据
- 绿色勾勾表示该天论文已经存储
- 紫色波浪线表示该天论文已经生成嵌入向量
5.10.3 数据操作
| 操作 | 说明 |
|---|---|
| 获取论文 | 从 arXiv 获取指定日期的论文 |
| 嵌入向量 | 对指定日期的论文生成嵌入向量 |
| 清除缓存 | 删除指定日期的缓存数据 |
| 查看论文 | 跳转到该日期的论文列表 |
5.11 Settings
设置页面用于配置系统参数。
5.11.1 主题设置

- 浅色模式:适合白天使用
- 深色模式:适合夜间使用
5.11.2 LLM 配置

支持的 LLM 提供商:
| 提供商 | 模型示例 | 说明 |
|---|---|---|
| OpenAI | gpt-4o-mini | 需要 API Key |
| Anthropic | claude-4.6 | 需要 API Key |
| GLM (智谱) | glm-5 | 需要API Key |
| Ollama | llama3 | 本地运行 |
配置步骤:
- 选择 LLM 提供商
- 选择模型
- 输入 API Key(如需要)
- 点击"测试连接"验证配置
5.11.3 Ollama 本地配置
安装 Ollama:
# macOS/Linux
curl -fsSL https://ollama.ai/install.sh | sh
# Windows
# 从 https://ollama.ai 下载安装包
下载模型:
ollama pull llama3
ollama pull mistral
ollama pull qwen2
启动 Ollama:
ollama serve
6. 高级配置
6.1 环境变量
完整的 .env 配置:
# 数据库SQLite配置(开发模式)
DATABASE_TYPE=sqlite
SQLITE_DB_PATH=./data/xivmind.db
DOWNLOAD_DIR=./downloads
# Milvus 配置(生产模式)
MILVUS_HOST=localhost
MILVUS_PORT=19530
DATABASE_NAME=xivmind
# LLM 配置
LLM_PROVIDER=openai
LLM_MODEL=gpt-4o-mini
OPENAI_API_KEY=sk-xxx
# Anthropic 配置
# LLM_PROVIDER=anthropic
# LLM_MODEL=claude-4.6
# ANTHROPIC_API_KEY=sk-xxx
# GLM 配置
# LLM_PROVIDER=glm
# LLM_MODEL=glm-5
# GLM_API_KEY=xxx
# GLM_BASE_URL=https://open.bigmodel.cn/api/paas/v4
# Ollama 配置
# LLM_PROVIDER=ollama
# OLLAMA_BASE_URL=http://localhost:11434
# OLLAMA_MODEL=llama3
6.2 Milvus 生产部署
启动 Milvus:
cd backend
# 标准模式(推荐生产)
./milvus.sh start
# 精简模式(开发测试)
./milvus.sh start lite
服务端口:
- Milvus: 19530
- Attu (GUI): 3000
- MinIO: 9000/9001
- etcd: 2379
6.3 Docker 部署
# 构建镜像
docker build -t xivmind-backend ./backend
docker build -t xivmind-frontend ./frontend
# 运行容器
docker run -d -p 8000:8000 xivmind-backend
docker run -d -p 5173:5173 xivmind-frontend
7. 常见问题
7.1 安装问题
Q: npm install 失败?
A: 尝试清除缓存后重新安装:
npm cache clean --force
rm -rf node_modules
npm install
Q: Python 依赖安装失败?
A: 确保使用 Python 3.10+,并安装构建工具:
pip install --upgrade pip
pip install -r requirements.txt
7.2 运行问题
Q: 后端启动失败?
A: 检查以下项目:
1. 端口 8000 是否被占用
2. .env 文件是否正确配置
3. 数据库目录是否有写入权限
Q: 前端无法连接后端?
A: 确认:
1. 后端服务正在运行
2. 后端端口配置正确(默认 8000)
3. 没有防火墙阻止连接
7.3 AI 功能问题
Q: AI 助手无响应?
A: 检查 LLM 配置:
1. API Key 是否正确
2. 模型名称是否正确
3. 网络是否可以访问 API
Q: Ollama 连接失败?
A: 确认:
1. Ollama 服务正在运行 (ollama serve)
2. 模型已下载 (ollama list)
3. 端口 11434 可访问
7.4 下载问题
Q: 论文下载失败?
A: 可能原因:
1. 网络连接问题
2. arXiv 服务暂时不可用
3. 下载目录没有写入权限
解决方法:
1. 检查网络连接
2. 稍后重试
3. 检查 DOWNLOAD_DIR 配置
7.5 数据问题
Q: 论文数据为空?
A: 尝试:
1. 点击"刷新"按钮重新获取
2. 检查日期是否有论文发布
3. 在数据管理页面获取指定日期数据
附录
A. API 端点
完整 API 文档请访问:
- Swagger UI: http://localhost:8000/docs
- ReDoc: http://localhost:8000/redoc
B. 技术支持
- GitHub Issues: https://github.com/uwjia/XivMind
- Document: https://github.com/uwjia/XivMind
文档版本:0.7.0
最后更新:2026-04-28

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)