多模态大模型架构(CLIP, Flamingo)(分层式精讲)
多模态大模型架构分层式精讲:CLIP 与 Flamingo

核心结论:CLIP 解决“图像和文本如何对齐”,Flamingo 解决“如何把视觉信息接入语言模型并生成答案”。前者更像检索和分类底座,后者更像生成式视觉语言模型。两者都重要,但能力边界不同,不能简单归为“会看图聊天”。

第 0 层:30 秒理解
本文聚焦视觉-语言模型。更广义的多模态还包括音频、视频、3D、传感器等,但 CLIP 和 Flamingo 的核心代表的是图像-文本路线。
| 模型 | 一句话理解 | 输入 | 输出 | 典型用途 |
|---|---|---|---|---|
| CLIP | 双塔模型,把图片和文字映射到同一语义空间 | 图像、候选文本 | 相似度分数 | 图文检索、零样本分类、数据过滤 |
| Flamingo | 把视觉特征通过交叉注意力接入语言模型 | 图像/视频 + 文本提示 | 自回归文本 | 视觉问答、图文交错 few-shot 推理 |
关键区别:
CLIP: image_encoder(image) · text_encoder(text) → matching score
Flamingo: language_model(text, visual_context) → generated text
需要先纠正几件事:
| 原说法 | 更准确的说法 |
|---|---|
| CLIP 看到图就能描述图片 | CLIP 本身不是 caption 模型;它会给图文匹配打分 |
| Flamingo 是通用聊天模型 | 原始 Flamingo 是 few-shot 视觉语言模型,不是现代意义的指令对话助手 |
| CLIP 训练数据是 LAION | OpenAI CLIP 使用私有 400M 图文对;LAION 常见于 OpenCLIP 等开放复现 |
| 原始 CLIP 文本上下文是 512 token | OpenAI CLIP 的文本上下文长度是 77 token,嵌入维度和上下文长度不是一回事 |
第 1 层:基础概念
1. 为什么需要多模态模型
现实任务很少只有纯文本或纯图像:
| 场景 | 需要的跨模态能力 |
|---|---|
| 商品搜索 | 用文字找到图片,或用图片找到相似商品 |
| 医学/工业图像 | 把视觉异常和专业描述对应起来 |
| 视觉问答 | 根据图像内容回答自然语言问题 |
| 文档理解 | 结合版面、图表、OCR 和文本语义 |
| 数据治理 | 过滤图文不匹配、低质量或违规样本 |
多模态模型的难点不是把两个输入拼在一起,而是要解决三件事:
表示:每种模态如何编码成 token 或 embedding
对齐:不同模态的语义如何进入同一空间或互相访问
生成:模型如何基于多模态上下文输出可靠答案
2. 三类常见架构
| 架构 | 代表 | 机制 | 优点 | 局限 |
|---|---|---|---|---|
| 双塔对齐 | CLIP、ALIGN、SigLIP | 图像塔和文本塔分别编码,再计算相似度 | 检索快,可离线建库 | 跨模态细粒度推理弱 |
| 融合编码 | BLIP、ViLT 等 | 图文 token 在 Transformer 中交互 | 细粒度理解更强 | 推理成本较高 |
| 视觉接入 LLM | Flamingo、BLIP-2、LLaVA | 用连接器/交叉注意力把视觉特征送入语言模型 | 能生成自然语言答案 | 容易幻觉,评估复杂 |
CLIP 属于双塔对齐;Flamingo 属于视觉接入语言模型。
第 2 层:CLIP
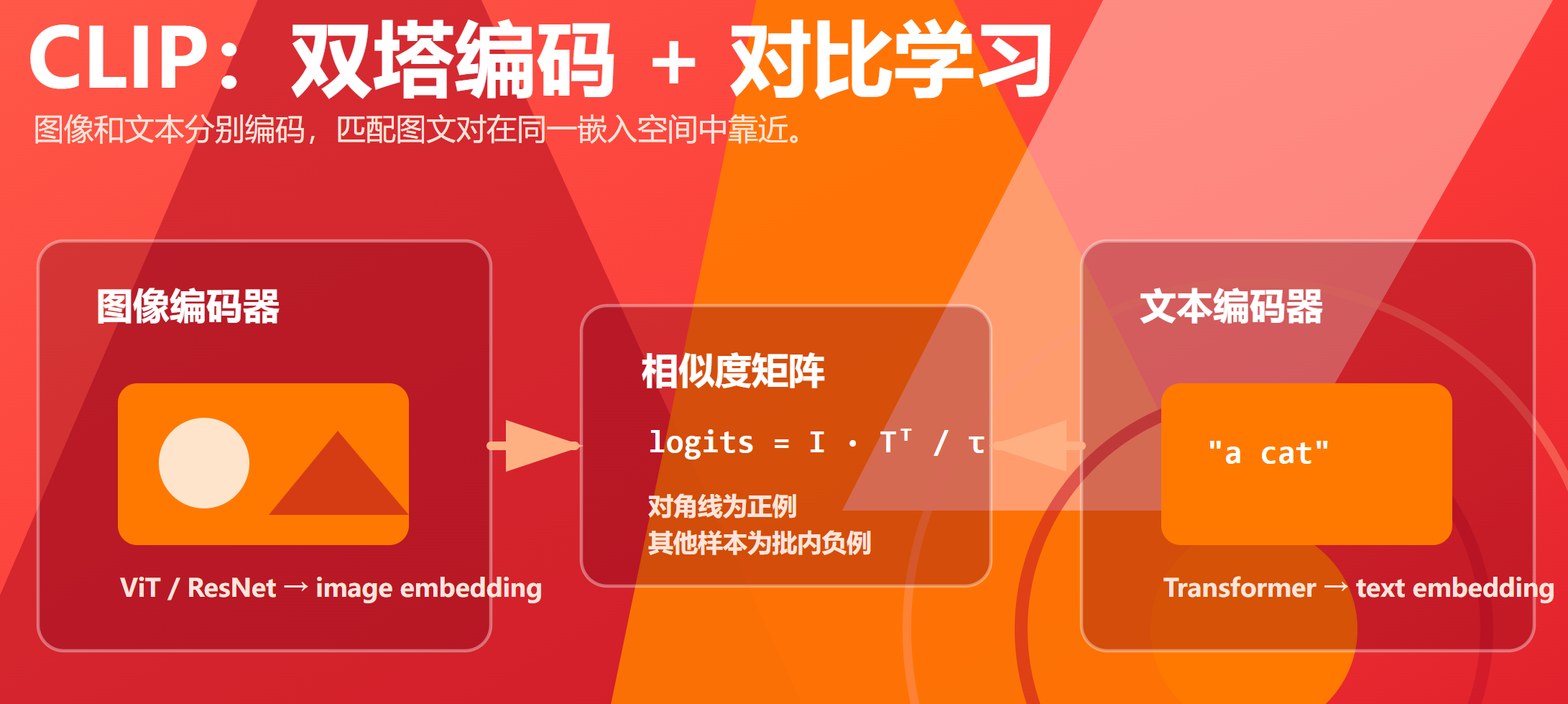
1. 架构
CLIP 训练两个编码器:
image_features = image_encoder(images)
text_features = text_encoder(texts)
similarity = image_features @ text_features.T
图像编码器可以是 ResNet 或 ViT;文本编码器是 Transformer。训练时把图像特征和文本特征 L2 normalize,然后使用批内对比学习。
2. 对比学习损失
下面是一个接近 CLIP 训练目标的简化实现:
import torch
import torch.nn.functional as F
def clip_contrastive_loss(image_features, text_features, logit_scale):
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
logits_per_image = logit_scale.exp() * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
labels = torch.arange(image_features.size(0), device=image_features.device)
loss_i = F.cross_entropy(logits_per_image, labels)
loss_t = F.cross_entropy(logits_per_text, labels)
return (loss_i + loss_t) / 2
CLIP 的正例是同一 batch 中的真实图文对,负例是同一 batch 里的其他图像或文本。因此 batch size、数据质量和图文匹配质量会显著影响效果。
3. 零样本分类怎么来的
CLIP 做零样本分类时,不是直接输出类别,而是把类别变成文本 prompt:
"a photo of a dog"
"a photo of a cat"
"a photo of a car"
然后计算图像 embedding 和每个 prompt embedding 的相似度,最高者作为预测类别。
实用建议:
| 技巧 | 作用 |
|---|---|
| 使用多个 prompt 模板并平均 | 降低 prompt 敏感性 |
| 类别名要贴近数据语境 | 医学、遥感、工业场景尤其重要 |
| 先测 zero-shot,再决定是否微调 | CLIP 零样本不是所有领域都稳 |
| 微调时小心过拟合 | 小数据集上 prompt learning / linear probe 更稳 |
4. CLIP 的局限
| 局限 | 表现 |
|---|---|
| 不是生成模型 | 不能直接生成详细 caption 或回答复杂问题 |
| 细粒度关系弱 | 数数、左右关系、复杂空间推理容易错 |
| 依赖 prompt | 类别文本写法会影响分类结果 |
| 数据偏差 | 网络图文对带有偏见、噪声和版权/安全问题 |
| 分辨率限制 | 小目标、OCR、细节识别常常不足 |
第 3 层:Flamingo
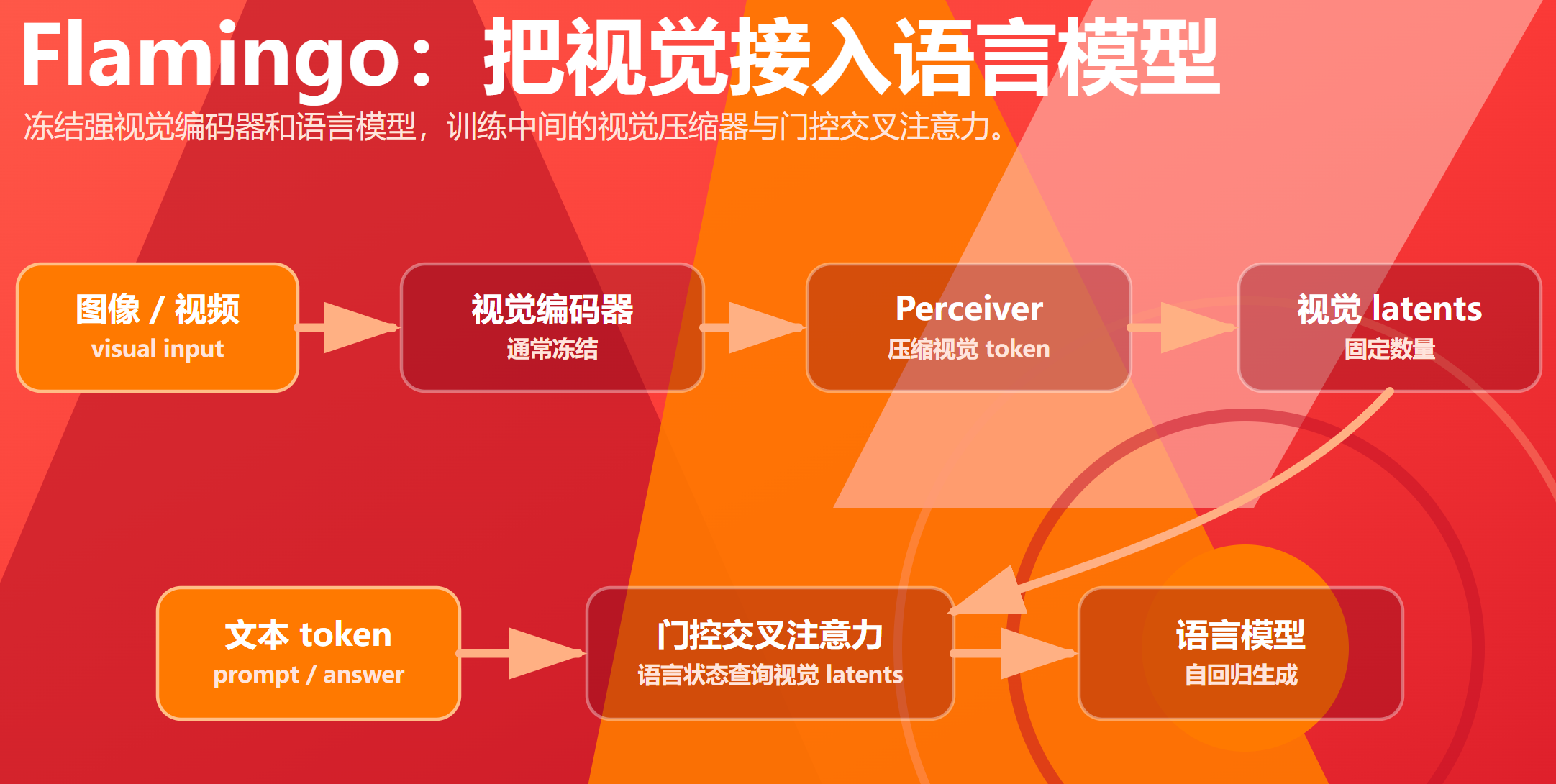
1. 架构
Flamingo 的核心不是重新训练一个从零开始的多模态 Transformer,而是把强视觉模型和强语言模型连接起来:
视觉输入 → 冻结视觉编码器 → Perceiver Resampler → 视觉 latents
文本输入 → 冻结语言模型
视觉 latents 通过 gated cross-attention 注入语言模型
关键组件:
| 组件 | 作用 |
|---|---|
| 视觉编码器 | 提取图像/视频特征,通常冻结 |
| Perceiver Resampler | 把可变数量视觉 token 压缩成固定数量 latent |
| Gated Cross-Attention | 让语言模型隐藏状态查询视觉 latent |
| 语言模型 | 自回归生成答案,通常使用预训练 LM |
原始 Flamingo 的重要设计是“冻结已有大模型,只训练新增的跨模态连接层”。这样可以保留语言模型能力,并降低多模态训练成本。
2. Gated Cross-Attention 示例
下面是简化版,展示思想而不是完整 Flamingo 复现:
import torch
import torch.nn as nn
class GatedCrossAttentionBlock(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
self.norm = nn.LayerNorm(d_model)
self.cross_attn = nn.MultiheadAttention(d_model, n_heads, batch_first=True)
self.attn_gate = nn.Parameter(torch.zeros(1))
def forward(self, hidden_states, vision_latents, vision_mask=None):
# hidden_states: [batch, text_len, d_model]
# vision_latents: [batch, num_latents, d_model]
x = self.norm(hidden_states)
attn_out, _ = self.cross_attn(
query=x,
key=vision_latents,
value=vision_latents,
key_padding_mask=vision_mask,
need_weights=False,
)
return hidden_states + torch.tanh(self.attn_gate) * attn_out
门控参数通常从接近 0 的状态开始,使新增视觉通道在训练初期不会破坏原语言模型行为。
3. Flamingo 训练方式
原稿中“Flamingo 两阶段指令微调”的说法不准确。更准确的是:
| 阶段/对象 | 原始 Flamingo 的做法 |
|---|---|
| 视觉编码器 | 使用预训练视觉模型,冻结 |
| 语言模型 | 使用预训练语言模型,冻结 |
| 新增模块 | 训练 Perceiver Resampler 和 gated cross-attention |
| 数据 | 使用大规模图文/视频文本和交错网页数据 |
| 目标 | 自回归语言建模,基于视觉上下文预测后续文本 |
现代 LLaVA、InstructBLIP、MiniGPT-4 等模型更强调视觉指令调优;它们和 Flamingo 有继承关系,但不是同一个训练配方。
4. Flamingo 的能力边界
| 能力 | 说明 |
|---|---|
| Few-shot 视觉问答 | 可以在 prompt 中放多个图文示例,再回答新图 |
| 图文交错上下文 | 支持多张图与文本交错输入 |
| 开放式文本生成 | 比 CLIP 更适合回答“为什么/怎么做” |
| 视觉细节 | 受视觉编码器分辨率和 latent 压缩限制 |
| 幻觉风险 | 语言模型可能编造图中不存在的内容 |
第 4 层:选型与实践
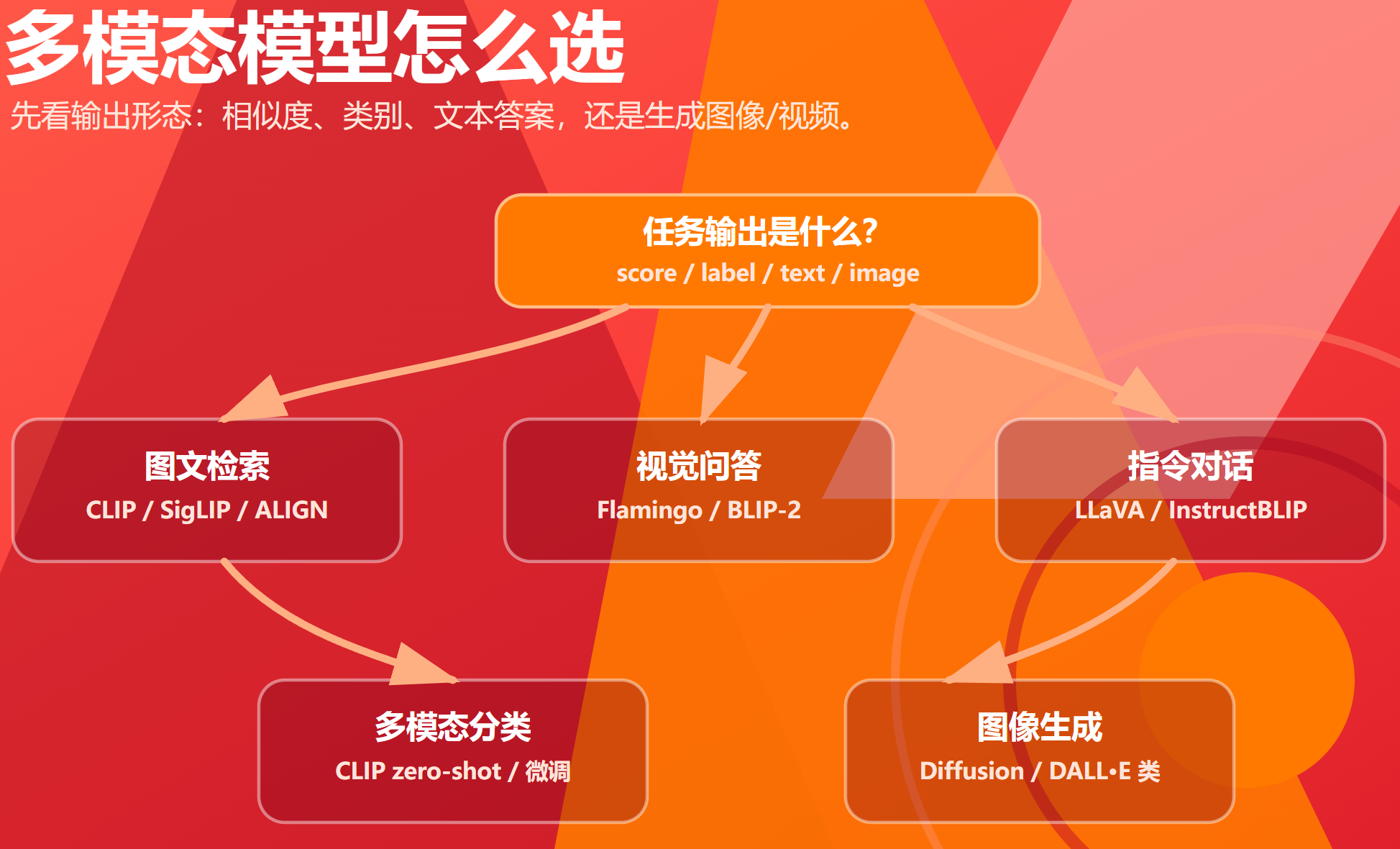
1. 任务选型
| 任务 | 优先考虑 | 原因 |
|---|---|---|
| 图文检索 | CLIP / OpenCLIP / SigLIP | 双塔 embedding 可离线建索引,推理便宜 |
| 零样本图像分类 | CLIP | prompt 类别即可试验 |
| 数据过滤 | CLIP 类模型 | 图文相似度可作为质量信号 |
| 视觉问答 | Flamingo / BLIP-2 / LLaVA 类 | 需要生成式回答 |
| 图文交错 few-shot | Flamingo 类 | 原生支持 interleaved examples |
| 视觉指令助手 | LLaVA / InstructBLIP 类 | 指令数据对齐更强 |
| 图像生成 | Diffusion / DALL·E 类 | CLIP/Flamingo 不是图像生成模型 |
2. 训练和微调建议
| 场景 | 建议 |
|---|---|
| 小数据图像分类 | 先用 CLIP zero-shot,再试 linear probe 或 prompt learning |
| 垂直领域检索 | 用领域图文对微调双塔,注意 hard negatives |
| 视觉问答 | 使用视觉指令数据 SFT,评估幻觉和拒答 |
| 文档/图表理解 | 增加 OCR、版面信息和高分辨率 crop |
| 多图推理 | 需要明确图像顺序、图像引用和跨图关系监督 |
3. 评估指标
| 模型类型 | 关键指标 |
|---|---|
| CLIP 类 | zero-shot accuracy、Recall@K、mAP、linear probe |
| 检索系统 | latency、index size、Recall@K、误召回分析 |
| VLM 生成模型 | VQA accuracy、MMBench/MME、POPE 幻觉评估、人类偏好 |
| 指令模型 | 指令遵循、视觉 grounding、事实准确性、拒答安全性 |
自动评估只能作为筛查。关键业务场景必须做人类评估,尤其是医学、工业质检、安全审核等高风险任务。
关键纠错总结
| 原稿表述 | 修正后 |
|---|---|
| CLIP 像看到画作就能说描述 | CLIP 是匹配/检索模型,不是原生 caption 生成器 |
| Flamingo 是会对话的视觉专家 | 原始 Flamingo 是 few-shot 生成式 VLM,不等同于指令聊天助手 |
| CLIP/Flamingo 都是中间融合 | CLIP 是双塔对齐;Flamingo 是语言模型中的交叉注意力视觉接入 |
| CLIP 文本上下文 512 | OpenAI CLIP 原始文本上下文长度是 77 token |
| CLIP 训练数据是 LAION | OpenAI CLIP 用私有 400M 图文对;LAION 主要用于开放复现 |
| Flamingo 两阶段指令微调 | 原始 Flamingo 训练新增跨模态模块,指令微调是后续 VLM 路线常见做法 |
| LLaVA 是图文生成模型 | LLaVA 是视觉指令/问答模型,不是图像生成模型 |
最后记住三句话
- CLIP 学的是“图文是否匹配”,适合检索、分类和数据过滤。
- Flamingo 学的是“语言模型如何利用视觉上下文生成文本”,适合视觉问答和图文交错 few-shot。
- 多模态不是简单拼接输入,真正难点是对齐、视觉细节保留、幻觉控制和可靠评估。
参考资料
- CLIP 论文 Learning Transferable Visual Models From Natural Language Supervision:https://arxiv.org/abs/2103.00020
- Flamingo 论文 A Visual Language Model for Few-Shot Learning:https://arxiv.org/abs/2204.14198
- BLIP-2 论文:https://arxiv.org/abs/2301.12597
- LLaVA 论文 Visual Instruction Tuning:https://arxiv.org/abs/2304.08485
- OpenCLIP / LAION 相关论文:https://arxiv.org/abs/2212.07143

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)