2026年山东大学软件学院创新项目实训博客(三)
一、工作进展
前两篇博客中,我主要做了 MetalCat 项目 AI 层的基础工作:第一篇先把 LangChain 的调用链路跑通,第二篇继续围绕营养场景测试结构化输出、缺失字段追问和相对记录修改。经过这两轮之后,模型已经不是单纯回答一句话,而是开始尝试把用户输入整理成后端能继续处理的数据。
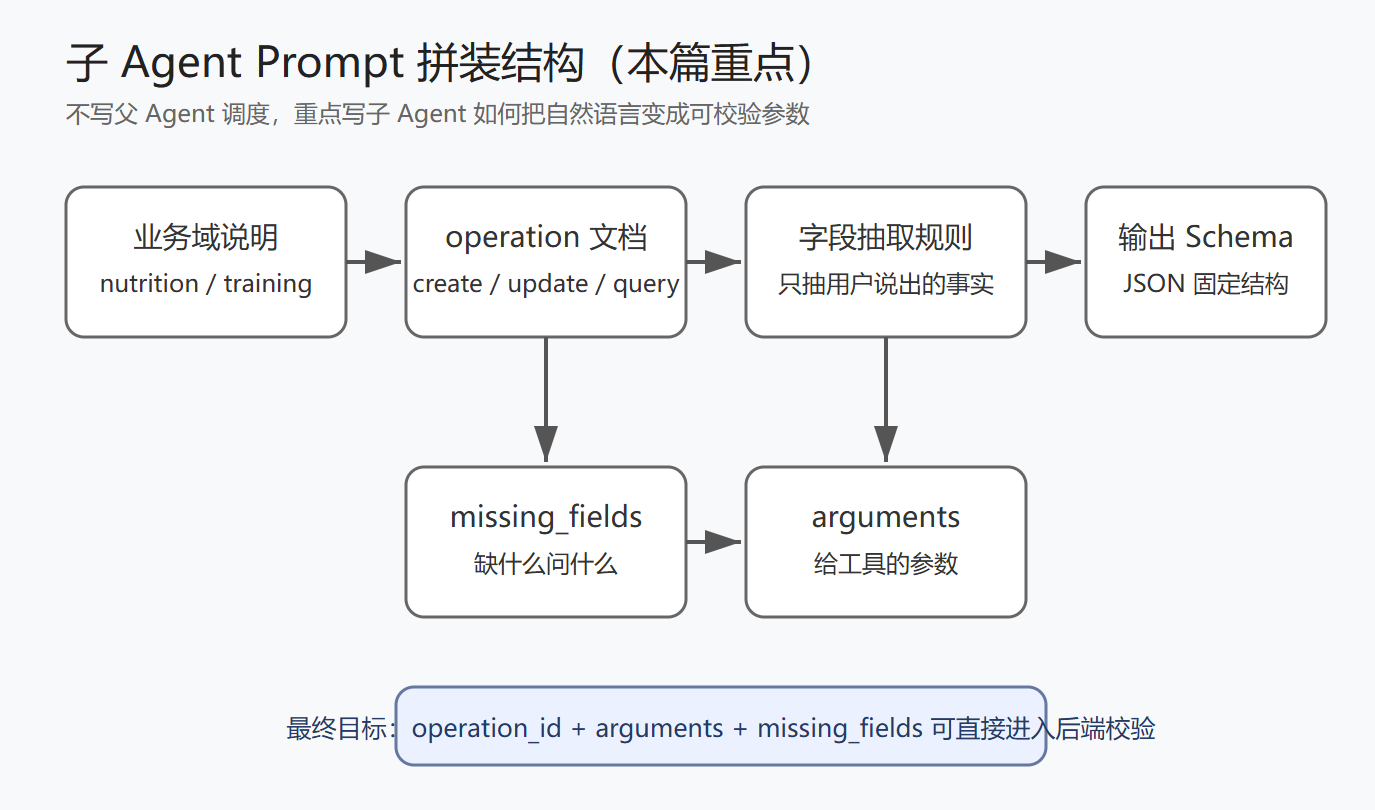
本阶段我没有继续写父 Agent 的意图识别和调度逻辑,因为这部分更多属于 Agent 架构和调度中心的工作。为了避免和队友的分工重复,我这次把重点放在 Prompt 工程更靠后的部分:子 Agent 收到任务后,如何选择具体 operation,并把用户自然语言转换成可校验的工具参数。
简单来说,父 Agent 判断“这句话属于营养还是训练”,而我这一阶段重点处理的是:如果已经进入 nutrition 或 training 子 Agent,模型接下来应该选哪个操作、抽哪些字段、缺什么字段、什么时候追问,以及展示给用户的文字能不能和实际参数保持一致。
本阶段主要完成了以下几项工作:
- 整理 nutrition 子 Agent 的 operation 选择规则。
- 整理 training 子 Agent 的 operation 选择规则。
- 设计统一的子 Agent 输出结构,包含
operation_id、arguments、missing_fields、needs_follow_up等字段。 - 增加字段缺失时的追问规则,避免模型在用户没说清楚时自己补数据。
- 重点修正
display_text和arguments不一致的问题,防止出现“文字说已记录,参数却不完整”的情况。
这一阶段的成果不体现在页面上新增了多少按钮,而体现在 AI 层输出的稳定性上。因为后面真正调用工具、写数据库之前,必须先保证模型传出来的参数是清楚的、可校验的、不会凭空编造的。
二、详细内容
1. 本阶段为什么不再写父 Agent 调度
项目做到这里之后,很容易出现一个问题:每个人都在写 Agent,最后博客内容看起来都像是在讲“用户输入 → 意图识别 → 分发给子 Agent”。但从团队分工看,我负责的是 Prompt 工程,更应该关注模型在具体业务场景中的输出约束,而不是调度中心本身。
所以这一篇我有意避开父 Agent 的路由细节,只把它当成上游已经完成的一步。也就是说,本文默认已经知道当前请求进入了某个子 Agent,比如 nutrition 或 training。我的工作从这里开始:子 Agent 需要把用户的话变成后端工具可以消费的结构。
举个例子,用户说:
中午吃了鸡胸肉和米饭,帮我记一下。
如果只看父 Agent,这句话被分到 nutrition 就够了。但进入 nutrition 子 Agent 后,问题才真正开始:
- 这是新增记录,还是查询营养?
- 餐次是不是 lunch?
- 食物有哪些?
- 分量有没有说?
- 没有分量能不能直接写入?
- 给用户的回复应该说“已记录”,还是应该先追问?
这些问题不是父 Agent 应该处理的,而是子 Agent Prompt 必须处理的。
2. 子 Agent Prompt 的拆分方式
一开始我也尝试过给 nutrition 和 training 各写一大段 system prompt,把身份、规则、输出格式全部放进去。测试几轮后发现,这样虽然能跑,但很难维护。
比如 nutrition 子 Agent 里面同时有新增饮食、修改饮食、删除饮食、查询汇总、估算热量几种操作。如果全写在一段 Prompt 里,后面只要改其中一个操作的字段说明,就容易影响其他操作。
所以我把子 Agent Prompt 拆成了几个部分:
1. 当前业务域说明
2. 可选 operation 列表
3. operation 选择规则
4. 字段抽取规则
5. missing_fields 处理规则
6. 输出 JSON 结构约束
7. 当前用户输入
这样拆完之后,Prompt 不再是一整块长文本,而是像一个运行时拼装的模板。业务域说明负责告诉模型“你现在只处理营养/训练”;operation 列表告诉模型“你可以选择哪些动作”;字段抽取规则告诉模型“哪些字段能填,哪些不能猜”;输出结构则保证后端拿到的数据格式稳定。
我目前使用的简化拼装方式如下:
def build_sub_agent_prompt(scene, operation_docs, output_schema, user_input):
return f"""
你是 MetalCat 项目的 {scene} 子 Agent。
你只处理当前业务域内的请求,不处理其他模块任务。
当前可选 operation:
{operation_docs}
你需要完成:
1. 判断用户输入对应哪个 operation_id。
2. 从用户输入中抽取 arguments。
3. 不确定的字段不要猜,放入 missing_fields。
4. 如果缺失字段影响执行,needs_follow_up 设为 true。
5. display_text 只能复述 arguments 中已经确定的信息。
6. 输出必须符合指定 JSON 结构。
输出结构:
{output_schema}
用户输入:
{user_input}
"""
这段代码本身不复杂,但它解决了一个比较实际的问题:Prompt 可以随着业务域和 operation 文档变化而变化,不用每次都重写完整 system prompt。
3. nutrition 子 Agent 的 operation 规则
营养模块是我前两篇已经重点测试过的方向,所以这次我先把它整理成更明确的 operation 选择表。
当前 nutrition 子 Agent 先保留五类操作:
{
"create_nutrition_record": "新增饮食记录",
"update_nutrition_record": "修改已有饮食记录",
"delete_nutrition_record": "删除已有饮食记录",
"query_nutrition_summary": "查询某段时间的营养摄入汇总",
"estimate_food_nutrition": "估算食物热量和营养素,不直接落库"
}
这里最关键的是区分“记录型请求”和“咨询型请求”。之前测试时模型容易把“一份牛肉盖饭多少热量”也识别成新增饮食记录,直接准备写入。实际上这句话只是估算,不应该落库。
我现在给 Prompt 加了一条规则:
如果用户只是询问某种食物的热量、蛋白质、脂肪或碳水,不要选择 create_nutrition_record,应该选择 estimate_food_nutrition。
只有用户明确表达“记录、记一下、加入今天摄入、算到今天”时,才选择 create_nutrition_record。
几组测试如下。
用户输入:
中午吃了鸡胸肉和米饭,帮我记一下。
期望输出:
{
"scene": "nutrition",
"operation_id": "create_nutrition_record",
"confidence": 0.92,
"arguments": {
"meal_type": "lunch",
"foods": [
{"name": "鸡胸肉", "amount": null, "unit": null},
{"name": "米饭", "amount": null, "unit": null}
],
"date": "today"
},
"missing_fields": ["foods[0].amount", "foods[1].amount"],
"needs_follow_up": true,
"follow_up_question": "鸡胸肉和米饭大概分别吃了多少?",
"display_text": "我识别到你中午吃了鸡胸肉和米饭,但还缺少大致分量。"
}
用户输入:
一份牛肉盖饭大概多少热量?
期望输出:
{
"scene": "nutrition",
"operation_id": "estimate_food_nutrition",
"confidence": 0.88,
"arguments": {
"food_name": "牛肉盖饭",
"amount": "一份"
},
"missing_fields": [],
"needs_follow_up": false,
"follow_up_question": "",
"display_text": "这是一次热量估算请求,不会直接写入今日饮食记录。"
}
这两组的区别很重要。前者是记录,后者是估算。如果 Prompt 不做区分,后端很可能收到错误的写入意图。
4. update 请求中的 record_anchor
除了新增记录,修改记录也是营养模块里比较常见的场景。比如用户说:
把刚才那条鸡胸肉改成牛肉。
这句话不能简单理解成新增牛肉,也不能直接删除鸡胸肉。它的真实意思是:找到刚才那条饮食记录,把其中的食物字段改掉。
所以我给 update 类请求增加了 record_anchor 字段,用来描述用户想修改哪一条记录。
{
"scene": "nutrition",
"operation_id": "update_nutrition_record",
"confidence": 0.86,
"record_anchor": {
"relative_time": "previous",
"food_name": "鸡胸肉"
},
"arguments": {
"update_fields": {
"food_name": "牛肉"
}
},
"missing_fields": [],
"needs_follow_up": false,
"follow_up_question": "",
"display_text": "识别到你想把上一条鸡胸肉记录改成牛肉。"
}
这里我没有让模型直接填 record_id。因为用户没有给 ID,模型也不可能知道数据库中的真实记录编号。它只能提供一个相对锚点,例如“刚才那条”“今天午饭那条”“鸡胸肉那条”。真正匹配数据库记录,应该交给后端工具处理。
这个设计避免了一个常见错误:模型为了让 JSON 看起来完整,随便编一个 record_id。这种字段一旦进入后端,会比空字段更危险。
5. training 子 Agent 的 operation 规则
训练模块目前也先整理成五类 operation:
{
"create_training_record": "新增训练记录",
"update_training_record": "修改已有训练记录",
"query_today_training": "查询今日训练安排或完成情况",
"update_training_plan": "调整训练计划",
"query_exercise_library": "查询动作或器械信息"
}
训练模块和营养模块类似,但字段更偏动作和训练量。比如:
今天练了胸,卧推50kg做了4组,每组8次。
期望输出:
{
"scene": "training",
"operation_id": "create_training_record",
"confidence": 0.95,
"arguments": {
"date": "today",
"muscle_group": "chest",
"exercises": [
{
"name": "卧推",
"weight": 50,
"weight_unit": "kg",
"sets": 4,
"reps": 8
}
]
},
"missing_fields": [],
"needs_follow_up": false,
"follow_up_question": "",
"display_text": "已识别到今天的胸部训练:卧推50kg,4组,每组8次。"
}
如果用户只说:
今天练了胸。
则不能直接写成完整训练记录,应该输出:
{
"scene": "training",
"operation_id": "create_training_record",
"confidence": 0.72,
"arguments": {
"date": "today",
"muscle_group": "chest",
"exercises": []
},
"missing_fields": ["exercises"],
"needs_follow_up": true,
"follow_up_question": "你今天胸部训练具体做了哪些动作?每个动作做了几组、多少重量?",
"display_text": "我先识别到你今天练了胸,但还缺少具体动作和训练量。"
}
这个例子和营养模块是一致的:用户没说的信息,不让模型自己补。
6. display_text 和 arguments 不一致的问题
本阶段最值得记录的一个坑,是 display_text 和 arguments 不一致。
测试时我发现模型有时会出现这种情况:
{
"arguments": {
"food_name": "鸡胸肉",
"amount": null
},
"missing_fields": ["amount"],
"display_text": "已为你记录鸡胸肉150g。"
}
这就是典型的“参数里没填,嘴上却说填了”。从用户角度看,他会以为系统已经记录了鸡胸肉 150g;但从后端角度看,amount 还是空。更严重的是,如果后续系统为了补齐字段采用默认值,就会造成错误数据写入。
所以我在 Prompt 中加入了一个硬约束:
所有 display_text 中出现的事实,必须能在 arguments 或工具返回结果中找到来源。
如果 arguments 中某字段为 null,不允许在 display_text 中补全该字段。
如果字段缺失,display_text 只能说明“已识别到部分信息,还缺少某字段”。

这个约束看起来很细,但对项目很重要。因为 MetalCat 最终不是聊天机器人,而是要记录用户的饮食、训练和身体数据。模型不能为了让回答听起来完整,就把不确定的信息说成确定信息。
7. missing_fields 的处理原则
这一阶段我还把缺失字段分成了两类。
第一类是影响执行的关键字段。例如新增饮食记录时没有食物名称,新增训练记录时没有动作名称。这种情况下必须追问,不能调用写入工具。
第二类是不影响初步执行但会影响精度的字段。例如用户说“吃了一碗米饭”,虽然没有精确克数,但“一碗”可以作为粗略单位进入估算流程;用户说“做了几组卧推”,但没说重量,可以记录无重量训练,或者追问重量,具体取决于后端规则。
因此我在 Prompt 里没有简单写“缺字段就追问”,而是要求模型判断缺失字段是否影响当前 operation 执行。
示例:
{
"missing_fields": [
{
"field": "foods[0].amount",
"level": "important",
"reason": "没有分量会影响热量和营养素估算"
}
],
"needs_follow_up": true
}
后续如果需要更严格,也可以把 missing_fields 从字符串数组升级成对象数组,保留字段名、重要程度和追问原因。当前阶段为了方便调试,先保留了字符串数组,必要时再扩展。
8. 本阶段和后端工具的边界
Prompt 工程不能替代后端校验。模型可以帮我们把自然语言整理成结构化参数,但它不能保证这些参数一定合法。
比如训练动作“卧推”是否存在于动作库,饮食记录是否能找到“刚才那条”,用户有没有权限修改某条记录,这些都不是 Prompt 层应该最终决定的事情。
所以我给子 Agent 输出设置了一个原则:
Prompt 层负责表达“用户想做什么”和“从话里能抽出什么”。
工具层负责判断“这些参数能不能执行”。
数据库层负责保证“实际写入的数据合法”。
这样分工以后,Prompt 不需要假装自己知道所有数据库状态。它只需要把 operation_id、arguments、record_anchor、missing_fields 输出清楚,后续再由工具层继续校验。
9. 本阶段形成的子 Agent 输出模板
综合 nutrition 和 training 两个方向,我目前整理出一个通用输出模板:
{
"scene": "nutrition | training",
"operation_id": "具体操作名称",
"confidence": 0.0,
"arguments": {},
"record_anchor": {},
"missing_fields": [],
"needs_follow_up": false,
"follow_up_question": "",
"display_text": ""
}
这里每个字段都有明确作用:
scene:当前子 Agent 所属业务域。operation_id:子 Agent 判断出的具体操作。confidence:当前操作选择的置信度。arguments:准备传给工具的参数。record_anchor:用于修改、删除时定位目标记录。missing_fields:当前缺失的字段。needs_follow_up:是否需要先追问用户。follow_up_question:需要追问时给用户的问题。display_text:给用户看的解释文本,但必须和参数保持一致。
这个模板后续可以继续和 JSON Schema 对齐。当前阶段先解决 Prompt 输出稳定问题,下一步再让它通过工具参数校验。
三、总结
本阶段我没有继续写父 Agent 的意图识别和调度,而是把工作重点放在子 Agent Prompt 的具体执行规则上,主要解决“进入某个业务域之后,模型如何选择 operation、抽取 arguments、处理缺失字段”的问题。
本阶段形成的主要成果有:
- 整理了 nutrition 子 Agent 的五类 operation:新增、修改、删除、查询汇总、食物估算。
- 整理了 training 子 Agent 的五类 operation:新增训练记录、修改训练记录、查询今日训练、调整训练计划、查询动作库。
- 初步设计了通用子 Agent 输出模板,包含
operation_id、arguments、record_anchor、missing_fields等字段。 - 加入了缺失字段追问逻辑,避免模型在用户没说清楚时直接补全数据。
- 修正了
display_text和arguments不一致的问题,要求展示文本不能出现参数中没有的事实。 - 明确 Prompt 层和后端工具层的边界:Prompt 负责结构化表达意图,工具和数据库负责最终校验与执行。
这一阶段的工作虽然没有直接表现为一个新的页面功能,但它对后续“对话即执行”很关键。因为只要模型输出的 operation 或 arguments 不稳定,后端工具再完整也很难安全调用。
下一阶段我准备继续把这套子 Agent 输出结构和后端 MCP 工具对齐,重点测试 operation_id 是否能稳定映射到真实接口,arguments 是否能通过 JSON Schema 校验。如果这一步跑通,MetalCat 的 AI 层就能从“理解用户输入”继续推进到“生成可执行工具参数”。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)