向量数据库全面对比分析
·
向量数据库全面对比分析:从国产到开源,如何选择最适合的方案
随着AI应用的快速发展,向量数据库作为处理高维数据的关键技术,已经成为现代AI架构中不可或缺的组成部分。本文将对主流向量数据库进行全面对比分析。
📊 向量数据库概览
向量数据库专门用于存储、索引和检索高维向量数据,广泛应用于相似性搜索、推荐系统、图像检索、自然语言处理等AI场景。
核心价值
- 高效相似性搜索:快速找到最相似的向量
- 大规模数据处理:支持亿级向量的存储和检索
- 实时性能:毫秒级的查询响应时间
- 多模态支持:处理文本、图像、音频等多种数据类型
🔍 主流向量数据库深度对比
1. Milvus - 国产分布式向量数据库
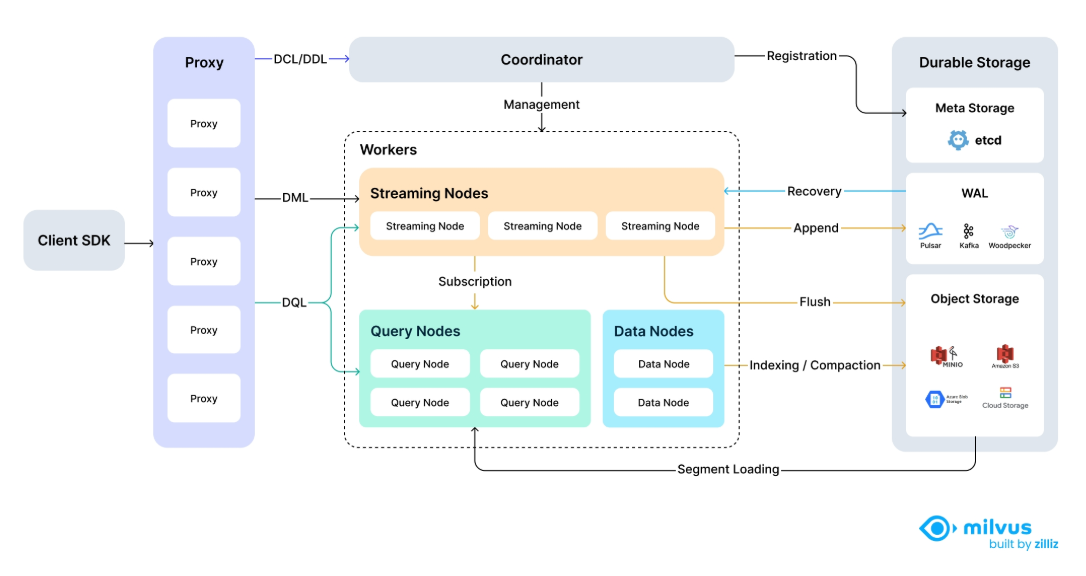
核心特点
- 国产化:中国自主开发的向量数据库
- 分布式架构:支持水平扩展,适合大规模部署
- 企业级特性:生产环境验证,稳定性高
技术优势
✅ 支持多种索引算法(HNSW、IVF、ANNOY等)
✅ 分布式架构,支持水平扩展
✅ 完善的监控和管理工具
✅ 丰富的SDK支持(Python、Java、Go等)
✅ 支持GPU加速
适用场景
- 企业级生产环境:需要高可用性和稳定性的场景
- 大规模数据:亿级向量存储和检索
- 国产化要求:有国产软件替代需求的场景
部署建议
- 生产环境推荐使用Kubernetes部署
- 建议配置:至少3节点集群,SSD存储
2. Qdrant - 轻量高性能向量数据库

核心特点
- 轻量级:资源占用少,部署简单
- 高性能:低延迟,高吞吐量
- Rust开发:内存安全,性能优异
技术优势
✅ 基于Rust开发,内存安全性能高
✅ 支持HNSW索引,查询性能优秀
✅ 丰富的过滤功能
✅ 支持多种距离度量方式
✅ 轻量级部署,资源占用少
适用场景
- 中小型项目:资源有限但需要高性能的场景
- 实时应用:对延迟要求严格的场景
- 原型开发:快速搭建和验证想法
部署建议
- 单机部署即可满足大部分需求
- 内存建议:数据量 × 向量维度 × 4字节
3. Chroma - 轻量化本地开发工具
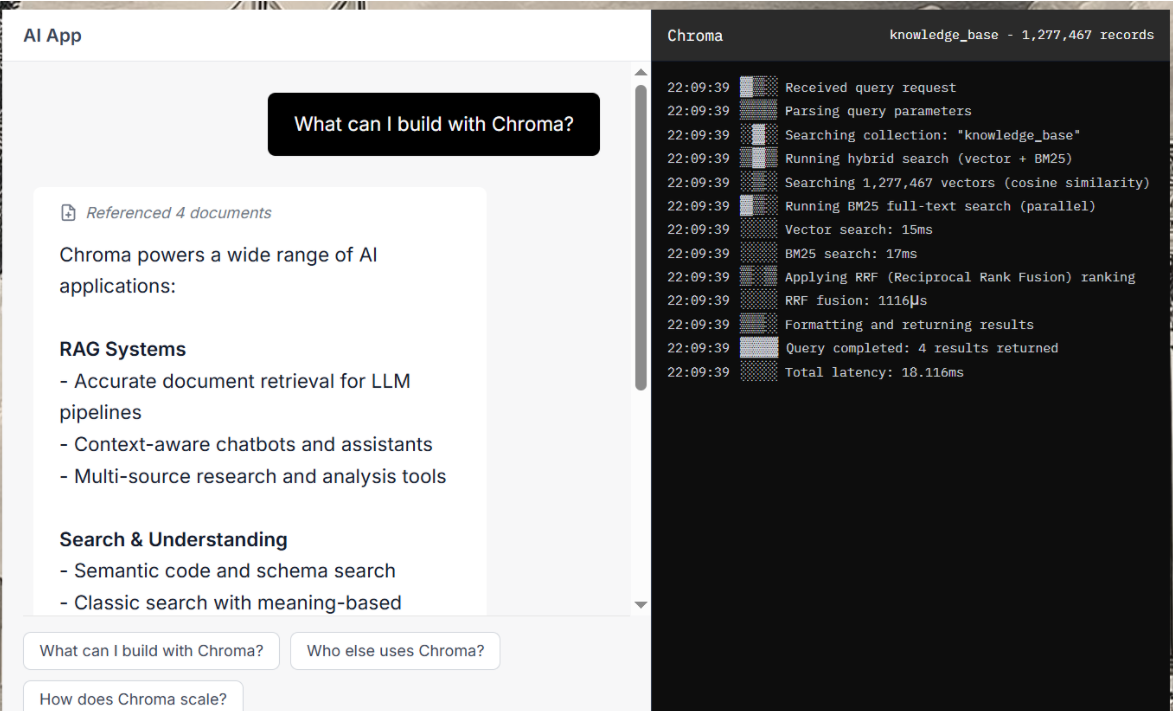
链接:https://www.trychroma.com/
github:https://github.com/chroma-core/chroma
核心特点
- 轻量化:专注于本地开发和调试
- 简单易用:API设计简洁,学习成本低
- 快速原型:适合快速验证想法
技术优势
✅ 极简API设计,上手快速
✅ 支持内存和持久化存储
✅ 内置向量化功能
✅ 与LangChain等框架深度集成
✅ 开发调试友好
适用场景
- 本地开发:个人开发者和研究团队
- 原型验证:快速验证AI应用想法
- 教学演示:向量数据库入门学习
部署建议
- 主要用于开发环境
- 生产环境建议使用其他方案
4. Weaviate - 向量+全文混合检索
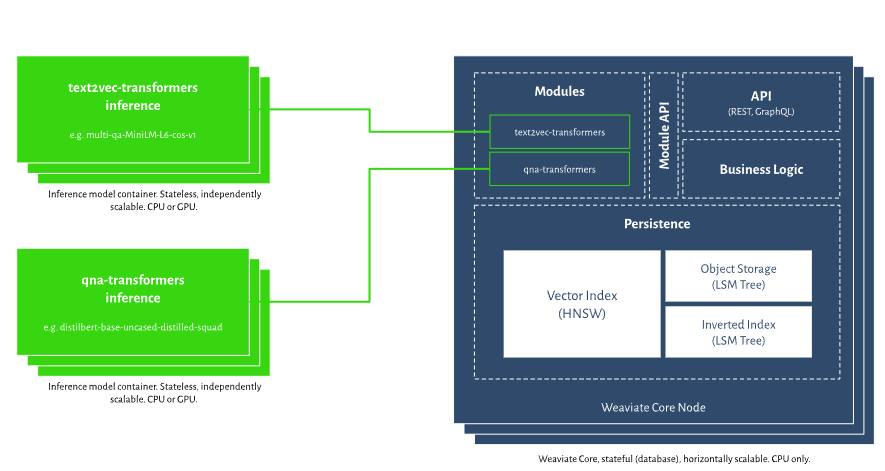
核心特点
- 混合检索:向量搜索 + 全文搜索
- 多模态友好:支持文本、图像等多种数据类型
- GraphQL接口:灵活的查询语言
技术优势
✅ 向量搜索与全文搜索结合
✅ 支持多模态数据(文本、图像等)
✅ GraphQL查询接口
✅ 模块化架构,可扩展性强
✅ 内置机器学习模块
适用场景
- 多模态应用:需要处理多种数据类型的场景
- 复杂查询:需要结合语义和关键词搜索
- 知识图谱:构建智能知识库系统
部署建议
- 支持Docker和Kubernetes部署
- 建议配置:SSD存储,充足内存
5. FAISS - Meta开源向量检索库
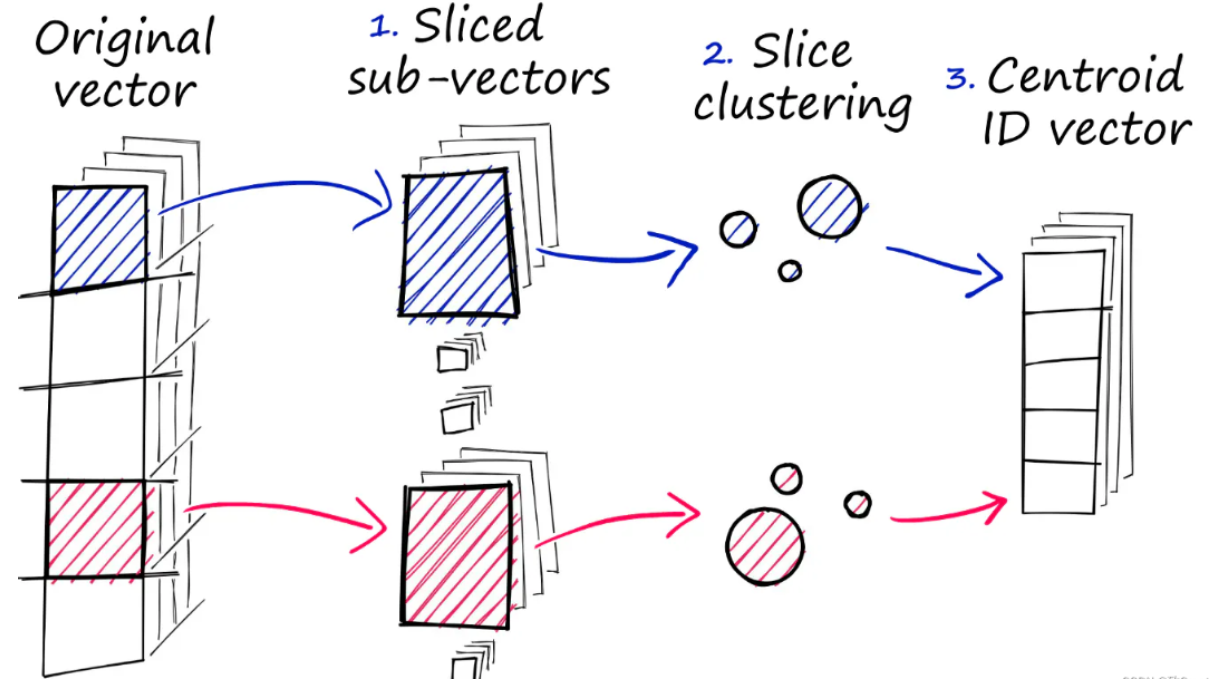
核心特点
- 算法强大:Meta AI团队开发,算法先进
- 离线检索:专注于离线批量处理
- 二次开发:需要集成到现有系统中
技术优势
✅ 算法先进,检索性能优秀
✅ 支持GPU加速
✅ 丰富的索引类型
✅ 成熟的社区和文档
✅ 可嵌入到现有系统中
适用场景
- 离线处理:批量数据处理和分析
- 算法研究:需要定制化算法的场景
- 系统集成:嵌入到现有数据处理流水线
部署建议
- 主要作为库使用,需要二次开发
- 建议配合其他存储系统使用
📈 性能对比分析
查询性能对比
| 数据库 | 查询延迟 | 吞吐量 | 内存占用 | 扩展性 |
|---|---|---|---|---|
| Milvus | 中等 | 高 | 高 | 优秀 |
| Qdrant | 低 | 高 | 中等 | 良好 |
| Chroma | 低 | 中等 | 低 | 有限 |
| Weaviate | 中等 | 中等 | 高 | 良好 |
| FAISS | 低 | 高 | 中等 | 需定制 |
功能特性对比
| 特性 | Milvus | Qdrant | Chroma | Weaviate | FAISS |
|---|---|---|---|---|---|
| 分布式 | ✅ | ❌ | ❌ | ✅ | ❌ |
| 多模态 | ✅ | ✅ | ✅ | ✅ | ✅ |
| GPU支持 | ✅ | ❌ | ❌ | ❌ | ✅ |
| 全文搜索 | ❌ | ✅ | ❌ | ✅ | ❌ |
| 生产就绪 | ✅ | ✅ | ❌ | ✅ | ❌ |
🎯 选择指南
根据项目规模选择
大型企业项目
推荐:Milvus
- 需要高可用性和稳定性
- 数据量达到亿级别
- 有国产化要求
中小型项目
推荐:Qdrant
- 资源有限但需要高性能
- 对延迟要求严格
- 快速部署和上线
开发原型
推荐:Chroma
- 快速验证想法
- 个人开发和学习
- 简单的演示项目
多模态应用
推荐:Weaviate
- 需要处理多种数据类型
- 复杂的查询需求
- 知识图谱类应用
算法研究
推荐:FAISS
- 需要定制化算法
- 离线批量处理
- 集成到现有系统
技术选型考虑因素
-
数据规模
- 小规模(<100万):Chroma/Qdrant
- 中规模(100万-1亿):Qdrant/Weaviate
- 大规模(>1亿):Milvus
-
性能要求
- 低延迟:Qdrant/FAISS
- 高吞吐:Milvus/FAISS
- 实时性:Qdrant
-
部署复杂度
- 简单部署:Chroma/Qdrant
- 企业级部署:Milvus/Weaviate
-
开发成本
- 快速上手:Chroma
- 中等复杂度:Qdrant/Weaviate
- 高复杂度:Milvus/FAISS
🚀 最佳实践建议
部署架构建议
生产环境架构
负载均衡器
↓
应用服务器集群
↓
向量数据库集群(Milvus/Qdrant)
↓
存储层(对象存储/分布式文件系统)
开发环境架构
本地应用
↓
Chroma/Qdrant单机版
↓
本地文件系统
性能优化建议
-
索引策略
- 根据数据分布选择合适的索引算法
- 平衡构建时间和查询性能
- 定期重建索引优化性能
-
内存管理
- 合理配置内存大小
- 使用SSD提升IO性能
- 监控内存使用情况
-
查询优化
- 使用合适的距离度量方式
- 合理设置查询参数
- 批量查询提升效率
🔮 未来发展趋势
技术发展方向
- 多模态融合:更好的支持文本、图像、音频等多种数据类型
- 云原生:更好的Kubernetes支持和云服务集成
- 智能化:自动化的索引优化和查询优化
- 边缘计算:轻量级版本支持边缘设备部署
市场趋势
- 国产化替代:国产向量数据库市场份额持续增长
- SaaS化服务:更多的云托管服务出现
- 行业定制:针对特定行业的优化版本
💡 总结
向量数据库的选择需要综合考虑项目需求、技术团队能力和长期发展规划。没有绝对的最佳选择,只有最适合的选择。
关键建议:
- 从实际需求出发,避免过度设计
- 考虑团队技术栈和运维能力
- 预留扩展空间,为未来发展考虑
- 重视国产化趋势,关注国产方案
通过本文的分析,希望能够帮助您在选择向量数据库时做出更明智的决策,为AI应用的成功落地奠定坚实基础。
本文基于最新的向量数据库技术发展情况编写,技术细节可能随时间变化,建议在实际选型时参考官方文档和最新测试数据。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)