白虎-VTouch数据集新版本发布,使用指南&配套脚本加持,轻松上手无门槛!
1月26日,全球首个规模超60,000分钟的跨本体视触觉(Vision-Based Tactile Sensor)多模态操作数据集——白虎·VTouch在OpenLoong 开源社区正式开源。该数据集面向机器人精细作业场景,系统性融合视觉与触觉信息,为多模态感知与操作学习提供了基础支撑。在传统多模态数据集基础上,进一步引入“跨本体”设计理念,覆盖不同机器人结构与形态,有效提升数据的通用性与泛化能力,为多平台迁移与应用奠定基础。
在此基础上,技术团队围绕“多模态数据如何真正服务于机器人决策与操作”这一核心问题,进一步开展了系统性研究工作。一方面,构建了面向视觉、触觉与姿态信息的跨模态检索框架,提升多源信息之间的对齐与理解能力;另一方面,设计了分布内策略验证系统,为模型从离线评估走向真实部署提供可靠依据。在此基础上,完成了从数据驱动到端到端模型训练,再到真实机器人系统部署验证的完整技术闭环。

相关研究成果已以预印本形式发布于arXiv平台,同时,围绕白虎-VTouch数据集的配套处理脚本及使用方法也已同步上线OpenLoong开源社区,旨在降低多模态数据使用门槛,推动相关技术在更广泛场景中的落地应用。值得一提的是,VTouch数据集在正式开源之后备受行业关注,目前下载使用量已突破89万
数据使用说明
我们开源了白虎-VTouch数据使用指南,给出了数据的原始格式以及转换后格式,并说明如何将数据集中的原始机器人数据转换为可训练的格式,同步配套数据转换脚本、可视化脚本。
支持多种机器人本体平台
Qingloong:足式人形机器人
Wheelloong M1:轮式人形机器人
Pika:UMI式无本体数采夹爪
支持两种主流数据格式转换
RoboMimic格式:基于HDF5的数据存储结构,支持灵活的数据索引与高效的轨迹级访问。
LeRobot格式:基于视频的数据存储方式,具有较高的压缩效率,适用于大规模数据的存储与策略学习训练。
视觉-触觉-姿态统一对齐框架
围绕“如何让机器人理解‘看到的’与‘摸到的’之间的内在关联”这一关键问题,提出一种融合视觉、触觉与姿态信息的统一建模方法。通过将三类异构模态(视觉信息、触觉信号以及机器人姿态,即关节位置与夹爪开合状态)映射至同一特征空间,实现多模态信息的协同表达与对齐,从而提升机器人对操作过程的整体理解能力。面向机器人操作过程中的多源信息融合需求,构建视觉、触觉与姿态三类模态的统一表征空间,实现“所见”“所感”与“所动”的协同建模,提升模型对复杂操作语义的整体理解能力。
在技术实现上,采用对比学习范式,构建跨模态表征学习框架,并设计了三类针对性编码器:
视觉模态
基于 DINOv2 预训练模型提取图像特征,增强视觉语义表达能力
触觉模态
构建专用触觉卷积网络(TactileCNN),有效提取触觉信号中的关键特征
姿态模态
引入机器人自身状态信息,包括12维关节位置及2维夹爪开合参数,提供操作过程中的结构性约束
通过上述方法,实现了不同模态之间的有效对齐与协同学习。为进一步验证所提出多模态对齐方法的有效性,我们在双模态与三模态设置下开展了系统性的跨模态检索实验,对模型的跨模态检索能力进行全面评估。双模态检索任务的性能表现,反映了任意两种模态之间的对齐效果:
双模态跨模态检索结果。展示不同模态对之间(如视觉→触觉、触觉→姿态等)的检索性能,所提方法能够有效实现任意两种模态之间的表征对齐。
三模态联合条件下的检索结果,用于评估多模态信息协同建模的能力:
在整体框架层面,基于对比学习构建的跨模态检索模型,相较传统基线方法在性能上实现了显著提升,验证了该范式在多模态对齐任务中的有效性与稳定性。三模态融合(视觉+触觉+姿态)相比双模态组合具有更为明显的性能增益,表明多模态之间的协同建模能够更充分地刻画跨模态语义关系。
在具体指标上:
-
在基线方法中,引入触觉信息后的跨模态检索成功率提升约14%;
-
在基于对比学习的跨模态检索模型中,触觉信息带来约8%的性能提升,验证了触觉模态的稳定增益作用。
四层渐进式分布内策略验证
为了在模仿学习策略部署前确保可靠性,我们提出四层渐进式验证框架,从动作质量、物理合理性、时序一致性、输出稳定性四个维度进行评估,每一层分别针对策略行为的不同方面进行测试,有效降低模型从实验环境迁移至真实场景过程中的不确定性。
-
第1层(动作重建):通过平均绝对误差、均方误差以及专家相似度等指标,验证策略是否能够从训练数据中准确复现专家动作。
-
第2层(单步闭环):评估策略输出在物理上的合理性与平滑性,包括动作统计分析、加加速度分析以及物理有效性检查。
-
第3层(短时域滚动预测):通过多步预测测试策略的时间一致性,用于检测误差随时间累积的情况。
-
第4层(一致性评估):针对随机策略,测量其输出方差,以评估策略行为的可复现性与稳定性。
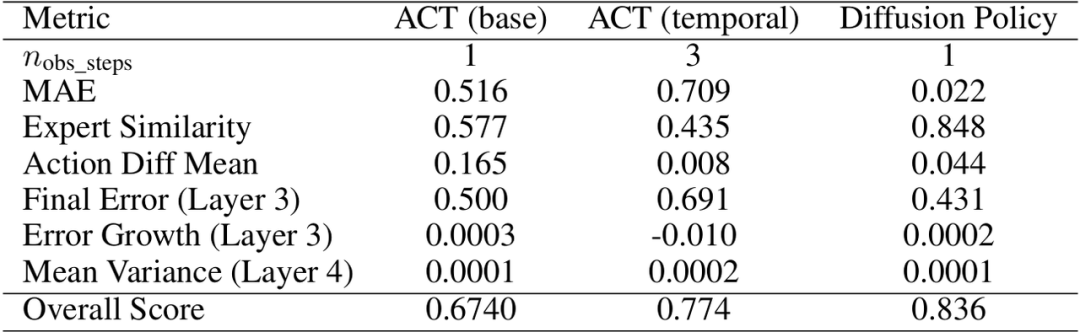
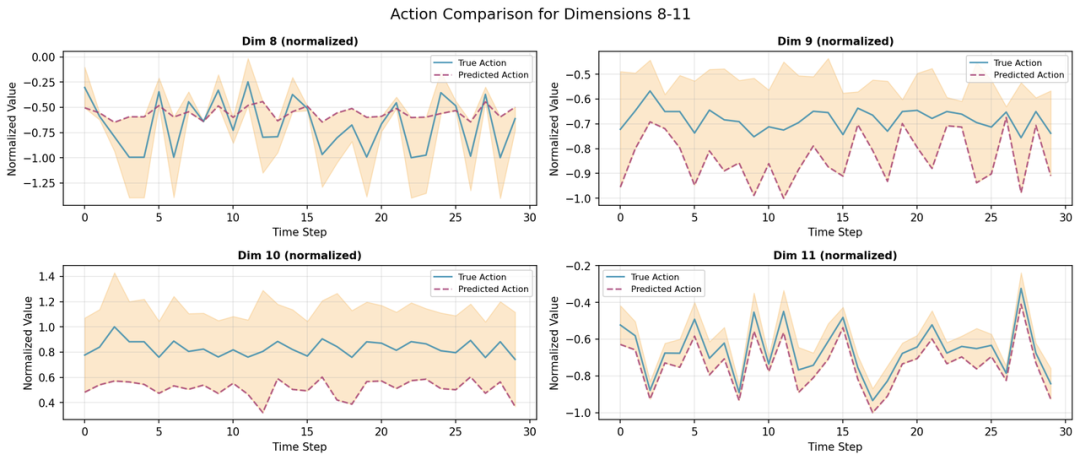
我们选择ACT(base)、ACT(temporal)、Diffusion Policy策略在 白虎-VTouch 数据集上进行验证,得到结论:
时序一致性优异:负误差增长表明策略在短时域内能够保持稳定的行为模式
输出高度稳定:极低的方差表明策略具有可靠的确定性输出
重建质量可提升:Expert Similarity 为主要优化方向
真机闭环应用框架(训练-推理一体化)

为了推进从离线训练到在线部署的快速推进,针对真实机器人场景的多种应用基础和需求,我们提出一种通用性的的产业级机器人应用框架,打通了从数据驱动建模到真实机器人执行的完整链路。它具备广泛的感知数据兼容性,内置统一封装的规划策略库,支持多种运控方式灵活切换,便于快速部署与扩展。
-
感知数据:支持常见的感知器件,统一格式至大尺度的视觉反馈(多视角协同融合的RGB-D图像)和小尺度的触觉反馈(操作级的接触图像)。
-
规划策略:支持与控制频率相同的实时推理,包括多种主流的模仿学习策略并统一封装接口,ACT (Action Chunking Transformer),DP (Diffusion Policy)和pi0.5等
-
控制方式:支持多种控制频率,基于离散控制方式的多种连续轨迹控制,嵌入安全限制与约束以实现稳定安全平滑的关节位置/速度/力矩控制
此外,基于该框架在实机平台完成模型训练与推理验证,形成可复现、可推广的技术闭环,验证方法在真实应用场景中的可行性与稳定性。实验结果证明了框架在不同构型机器人上的通用性,也表明跨本体多模态白虎-VTouch数据集和通用性框架结合的范式有助于机器人学习到实际可用的具身能力。
值得一提的是,白虎-VTouch数据集采用了与智能体无关的自动标注标注,包括任务描述和详细的元数据。对于相同的操作任务,即使真实产业场景的机器人与白虎-VTouch数据集涉及到的硬件基础不尽相同,我们的通用性闭环应用框架将最大程度助力数据集和算法快速适应与落地。
为新一代具身智能实训场建设与模型进化提供基础支撑
围绕视触觉融合的策略学习与验证,我们构建一条从算法设计到真实部署的完整路径,主要贡献体现在四方面:
-
端到端验证闭环:基于 ACT 与 DP 框架,打通了从模型训练到真机部署的全流程,验证了方法在实际场景中的可行性与稳定性。
-
跨模态对齐能力提升:在 12 个检索任务中实现对基线方法的全面超越,充分证明了模型在视觉与触觉信息融合上的表达优势。
-
可靠的验证体系:提出四层渐进式验证框架,从离线评估到在线部署逐级推进,为策略效果提供了系统化、可量化的评估依据。
-
标准化应用范式:构建面向视触觉多模态数据集的完整下游任务流程,为相关研究与应用提供了可复用的实践路径。

点击直达白虎-VTouch数据集开源仓库,下载数据、获取配套脚本,快速开启你的多模态操作学习之旅吧!
未来,OpenLoong开源社区将持续聚焦具身智能领域的开源共创,围绕视觉、触觉、力觉等多模态感知数据的空间对齐与语义关联,推动构建开放、可扩展的统一数据表示框架。我们将联合社区成员,共同提升跨模态表征的鲁棒性与泛化能力,打通从数据采集、模型训练到真实场景落地的全链条路径,助力数据集实现“能有-能用-好用”的跨越。
同时,社区也将进一步推动机器人数据集与核心技术的开源开放,我们真诚邀请各高校院所、企业及个人开发者加入OpenLoong开源社区,共同合作、贡献代码与数据,一起推动具身智能技术与数据的开放共享,让更多机器人真正“看懂、摸清、操作好”真实世界吧!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)