CVPR‘26 Highlight|PixDLM:无人机推理分割首个万级基准+统一模型

「无人机视觉的“推理分割”时代来了」
目录
03 核心架构:PixDLM,双路径平衡全局语义与细粒度结构
2. 多路径对齐(MultiPath Alignment):跨尺度融合的关键
近三年,多模态大模型与视觉分割的融合,彻底改写了通用场景的像素级理解范式。从LISA、PixelLM将语言推理嵌入分割任务,到GeoPix、RemoteSAM面向遥感影像的空间建模,再到各类高分辨率适配方案,推理分割已从地面视角逐步走向高空、斜拍、大尺度变化的复杂场景。
但无人机(UAV)视觉始终是一块难啃的硬骨头。斜拍视角带来的几何畸变、超高清分辨率与极小目标共存、密集小物体极易在token压缩中丢失、全局语义与局部细节需同时建模——这些特性让现有推理分割模型直接迁移时性能断崖式下跌。行业与学界长期缺少一个专门面向无人机的推理分割基准,更缺少一套能同时hold住全局语义与细粒度结构的统一模型。
厦门大学纪荣嵘团队最新提出的PixDLM,正是瞄准这一空白给出的系统性答案。它没有跟风堆叠更大的多模态架构,也没有简单复用遥感模型的设计,而是从无人机视觉的本质痛点出发,定义了全新的UAV Reasoning Segmentation任务,配套构建了万级规模DRSeg基准,并以双路径视觉编码+分层推理解码的极简架构,拿下了三项推理维度的最优性能。

图 | UAV ReasonSeg 任务总览
这不是一次简单的模型迭代,而是无人机细粒度视觉感知从“检测识别”向“语言指令驱动的推理分割”跨越的关键一步。
值得一提的是,该项工作被评选为CVPR2026 Highlight。
01 行业空白:无人机推理分割,为何一直是缺位状态?
在低空安防、搜救巡检、自主导航等真实场景中,无人机需要完成的早已不是“识别车/人/桥”这类基础任务,而是理解语言指令并定位满足条件的目标。
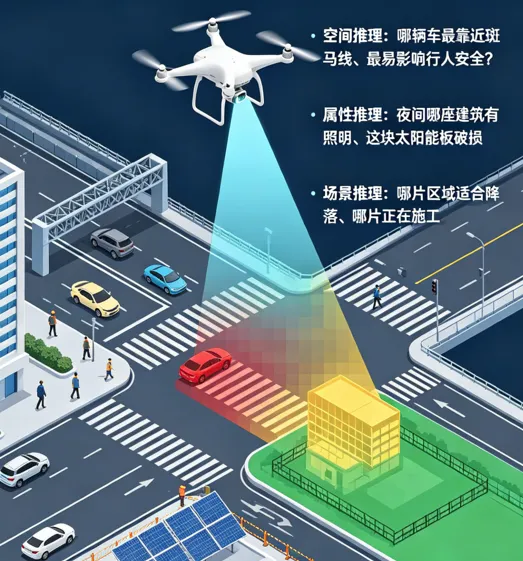
- 空间推理:哪辆车最靠近斑马线、最易影响行人安全?
- 属性推理:夜间哪座建筑有照明、哪块太阳能板存在破损?
- 场景推理:哪片区域适合降落、哪块区域正在施工?
这类需求不依赖显式类别命名,而是基于位置关系、视觉状态、场景意图的隐式推理,同时必须输出像素级掩码——这正是推理分割的核心定义。
但现有体系存在三重致命缺口:
- 数据集缺失:VisDrone、DroneVehicle等无人机数据集只提供检测框或简单分割,无链式推理(CoT)文本标注,无法支撑指令驱动的学习。
- 模型能力不匹配:地面/遥感模型依赖低分辨率视觉token,会直接丢失无人机画面中占比仅数十像素的关键小目标;纯大模型缺少像素级预测头,无法输出掩码。
- 视角与尺度难题:斜拍视角几何畸变、30/60/100米不同高度带来的极端尺度变化,让通用视觉假设全部失效。
学界并非没有尝试,但要么局限于定向目标检测,要么停留在普通指代表达分割,始终没有形成“指令理解+链式推理+像素分割”的闭环。PixDLM的首要贡献,就是把这个模糊需求,变成了可定义、可评测、可迭代的标准任务。
02 任务与基准:DRSeg,首个无人机推理分割万级数据集
为了让任务可落地,团队首先正式定义UAV Reasoning Segmentation:输入一张无人机图+自由形式自然语言指令,输出满足语义条件的像素级二值掩码。
与传统指代表达分割不同,它不依赖显式目标名称,完全依靠关系、状态、意图推理,更贴近真实人机交互。
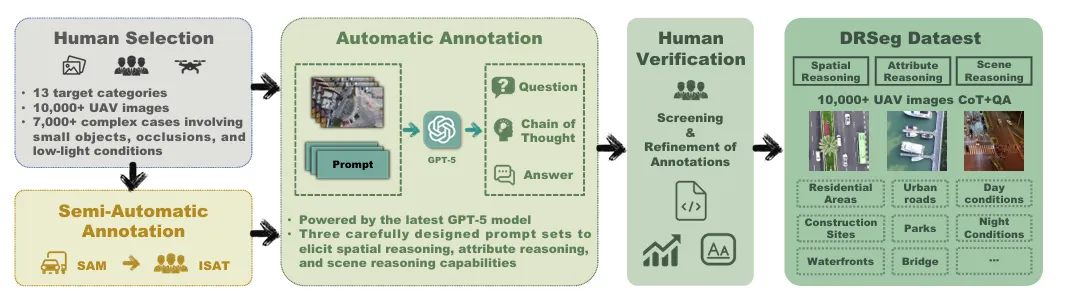
图 | DRSeg 数据集构建流程
团队进一步将推理切为三类均衡维度:
- 空间推理:几何/位置关系(最靠近路口的车辆、河道旁的区域)
- 属性推理:视觉属性/状态(破损结构、夜间照明目标)
- 场景推理:全局上下文/任务意图(安全降落区、施工区域)
在此基础上,团队构建了DRSeg——目前规模最大、标注最精细的无人机推理分割基准:
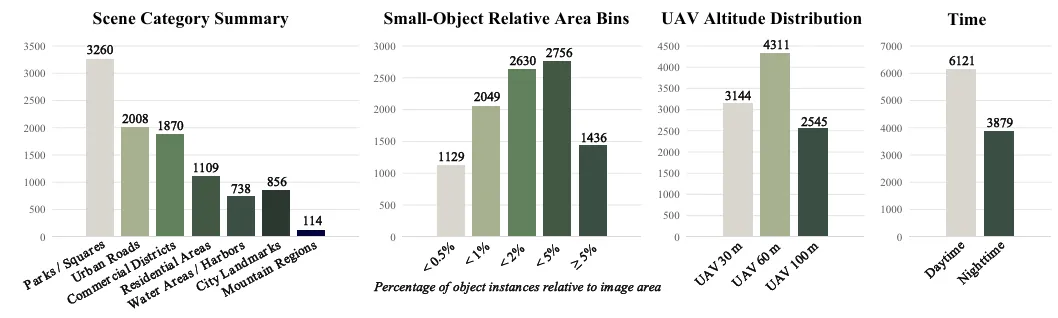
图 | DRSeg 数据集统计分布图
- 规模:超10000张超高清无人机图像,10000个实例掩码
- 场景:城市道路、公园、住宅区、工业区、滨水区
- 条件:30/60/100米三高度、白天/夜间混合光照
- 标注:GPT-5自动生成+人工校验的链式问答(CoT-QA),三类推理各占1/3
- 小目标占比:58.08%实例面积<图像2%,高度还原真实挑战
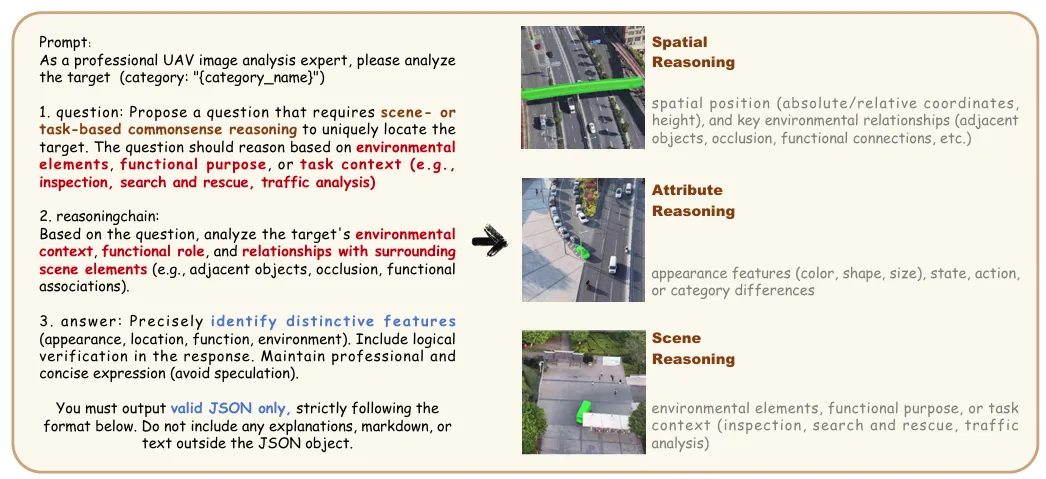
图 | 推理标注指令模板
标注流程经过四步严格质控:人工精选→SAM半自动掩码→GPT-5推理标注→专家校验,确保问题唯一可定位、推理链一致、掩码对齐率达97%。这套基准直接填补了无人机领域的空白,成为后续研究的标准测试床。
03 核心架构:PixDLM,双路径平衡全局语义与细粒度结构
解决任务与数据后,模型设计成为关键。团队没有走“堆参数、扩分辨率”的老路,而是抓住核心矛盾:
无人机场景既要全局语义做推理,又要超高分辨率保小目标边界,二者在传统单路径编码器中不可兼得。
为此,PixDLM采用双路径视觉编码器+多路径对齐+分层推理解码器的紧凑架构,仅训练约4.19M参数(占总参0.0574%),就能实现强性能。
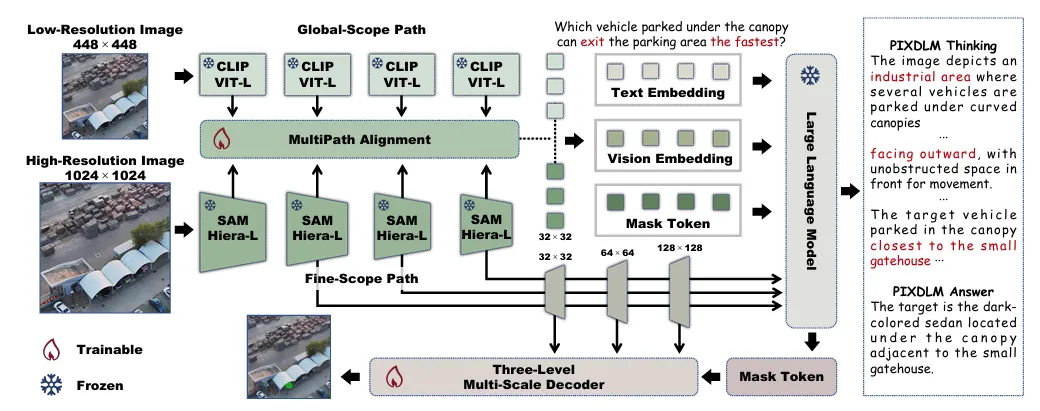
图 | PixDLM 模型总览
1. 双路径视觉编码:各司其职,互不干扰
架构拆为两条独立通路,分别处理不同尺度需求:
- 全局语义通路(Global-Scope Path):输入448×448低分辨率图,以CLIP ViT-L为编码器,负责捕获长距离上下文,支撑语言推理。
- 细粒度结构通路(Fine-Scope Path):输入1024×1024高分辨率图,以SAM Hiera-L为编码器,保留小物体、边缘、纹理等高频细节。
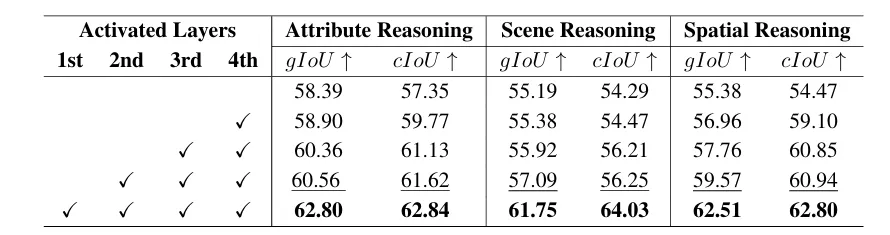
图 | 双路径视觉编码器不同对齐层的性能消融
这一设计直接规避了低分辨率压缩丢细节、全分辨率推理耗显存的两难问题。
2. 多路径对齐(MultiPath Alignment):跨尺度融合的关键
两条路径分辨率、维度不同,无法直接相加。团队提出三阶段隐式融合+输出层显式融合:
1. 把细粒度通路特征逐阶段对齐到全局通路的隐空间
2. 用门控残差融合,自适应注入结构信息
3. 最终再做一次全量融合,形成兼顾语义与结构的视觉表征
消融实验证明:完整启用四层对齐,相比无对齐,属性推理gIoU提升4.41%,场景推理提升6.56%,空间推理提升7.13%——对齐机制是性能跃升的核心。
3. 分层推理解码器:从粗到精恢复像素掩码
大模型输出的掩码token缺少空间粒度,团队设计三级多尺度解码器:
- 每一层接收高层掩码与当前尺度视觉特征
- 用掩码调制特征权重,聚焦高置信区域
- 逐层加权融合,逐步细化边界

图 | 分层推理解码器 2 层 / 3 层性能对比
相比两层解码器,三层结构整体gIoU从56.43%升至62.35%,小目标边界精度显著改善,完美适配无人机密集小目标场景。
4. 训练机制:链式推理(CoT)监督的增益
团队采用文本交叉熵+掩码二值交叉熵+Dice损失的组合权重,同时引入链式推理(CoT)监督。
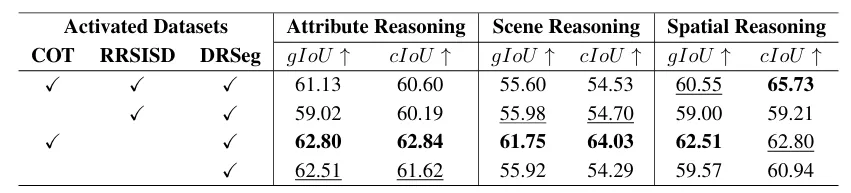
图 | 数据集与 CoT 监督消融实验
实验显示:仅用DRSeg训练已很强,加入CoT后,属性/场景推理进一步上涨,推理逻辑更贴合人类思考路径,输出掩码与指令语义更一致。
04 实验结果:全面超越SOTA,三类推理全维度领先
团队在DRSeg上与LISA、PixelLM、SegEarth、GeoPix等主流推理分割模型对比,结果极具说服力:

图 | PixDLM 在属性推理、场景推理、空间推理子集上的结果可视化
1. 零样本场景:现有模型完全不适应无人机
零样本下,所有基线模型gIoU普遍低于50%,尤其场景推理与空间推理下滑明显,证明通用推理分割模型无法直接迁移。
2. 微调后:PixDLM全面领跑
在有监督微调(SFT)设置下:
- 属性推理:gIoU 62.80%,cIoU 62.84%
- 场景推理:gIoU 61.75%,cIoU 64.03%
- 空间推理:gIoU 62.51%,cIoU 62.80%
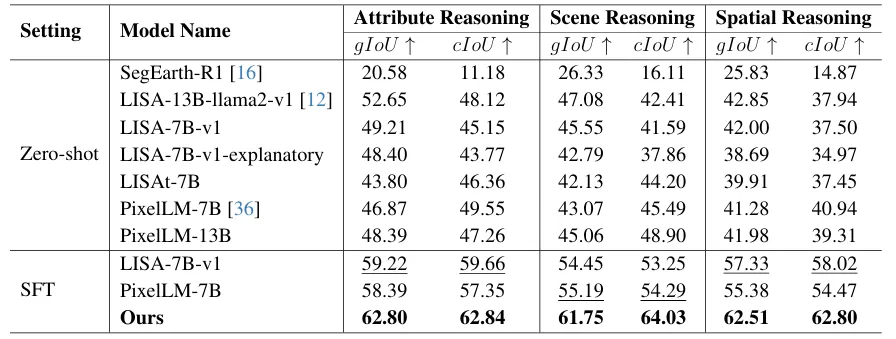
图 | 不同模型在 DRSeg 基准上的三类推理性能对比(零样本 & 微调)
全面超越LISA、PixelLM等模型,在三类推理维度均取得最优成绩。可视化结果更直观:PixDLM能精准定位小目标、复杂关系目标,边界更干净,错检更少。
3. 泛化能力:通用指代表达分割同样强势

图 | LISA、GeoPix、微调 LISA 与 PixDLM 的分割结果可视化对比
团队在RefCOCO/RefCOCO+/RefCOCOg标准数据集测试,PixDLM同样达到领先水平,证明双路径架构不局限于无人机,具备通用价值。
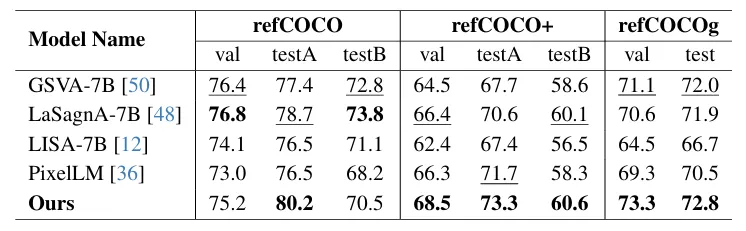
图 | PixDLM 在标准指代表达分割数据集上的泛化性能对比
05 中立审视:优势、局限与行业价值
核心优势(不可替代的三点)

- 任务定义的开创性:首次把无人机推理分割标准化,为低空视觉语言交互建立了研究范式。
- 架构的高效性:双路径+轻量对齐,用极小训练参数实现精度跃升,适合无人机端侧部署。
- 数据的标杆性:DRSeg万级规模+CoT标注,成为该领域未来绕不开的基准。
现存局限(客观存在的挑战)
- 单目标限制:当前每张图只标注一个目标,暂不支持多目标同时推理分割。
- 动态场景不足:数据以静态帧为主,对运动模糊、高速飞行场景覆盖有限。
- 极端夜间依赖光照:极低光条件下,小目标检测与推理仍存在波动。
- 无显式物理先验:纯数据驱动,未融入无人机飞行、空间投影等物理约束。
这些局限并非设计缺陷,而是任务初代阶段必然的取舍,也为后续研究指明了方向。
真实行业价值
PixDLM的落地意义远大于实验精度:
- 低空巡检:用自然语言指令定位破损、隐患、违规区域,无需手动框选
- 搜救救援:快速定位“最靠近伤者的障碍物”“可降落空地”等推理目标
- 交通监控:回答“哪辆车影响行人安全”“哪条车道拥堵”等复杂问题
- 自主导航:基于语言指令做环境理解,辅助无人机避障与路径规划
它把无人机从“被动拍摄设备”变成“能听懂指令、能推理场景、能像素级定位的智能体”。
06 总结:无人机视觉推理,进入指令驱动的细粒度时代
回顾整个工作,PixDLM的价值可以浓缩为三句话:
- 它定义了问题:把模糊的无人机语言指令需求,变成严谨的UAV Reasoning Segmentation任务。
- 它提供了工具:DRSeg基准让后续研究有了统一评测标尺,不再各自为战。
- 它给出了方案:双路径架构证明,全局语义与细粒度结构可以高效融合,为轻量、高精度、可部署的无人机多模态模型树立了范本。
在无人机低空经济快速扩张、自主飞行需求爆发的今天,PixDLM没有追逐大模型热潮,而是回归视觉本质,解决最朴素的问题:
如何让无人机在斜拍、超高分辨率、极端尺度变化下,听懂语言、推理场景、精准分割。
这种回归底层的思路,往往比堆叠技术更具长期价值。随着数据扩大、多目标支持、动态场景融入、物理先验加入,无人机指令推理分割将真正走向产业落地。
未来,当我们说出“找到那辆可能影响行人的车”“圈出最安全的降落区域”,无人机就能瞬间给出像素级答案——PixDLM已经为这一天铺好了第一块基石。
Ref
论文标题:PixDLM: A Dual-Path Multimodal Language Model for UAV Reasoning Segmentation
论文链接:https://arxiv.org/abs/2604.15670
开源地址:https://github.com/XIEFOX/PixDLM

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献77条内容
已为社区贡献77条内容

所有评论(0)