【学习笔记】SimpleVLA-RL:通过强化学习扩展 VLA 训练
摘要
视觉-语言-动作(VLA)模型已成为机器人操作的一个强大范式。尽管大规模预训练和监督微调(SFT)取得了实质性进展,但这些模型仍面临两个根本性挑战:(1)SFT 扩展所需的大规模人工操作机器人轨迹的稀缺和高成本;(2)对涉及分布漂移的任务泛化能力有限。
最近在大型推理模型(LRM)方面的突破表明,强化学习(RL)可以显著增强逐步推理能力。这自然引发了一个问题:RL 能否类似地增强 VLA 的长时程逐步动作规划能力?
本文提出 SimpleVLA-RL,一个为 VLA 模型定制的高效 RL 框架。基于 veRL 框架,引入了 VLA 特定的轨迹采样、可扩展并行化、多环境渲染和优化的损失计算。应用到 OpenVLA-OFT 上时,SimpleVLA-RL 在 LIBERO 上达到 SoTA 性能,甚至在 RoboTwin 1.0 & 2.0 上超越 π0。此外,论文还发现了一个称为 “pushcut” 的新现象,即 RL 训练过程中策略发现了超越先前训练数据的新模式。
1. 研究背景与动机
1.1 VLA 模型的现状与挑战
当前 VLA 模型通常采用两阶段训练策略:
| 阶段 | 内容 | 问题 |
|---|---|---|
| 预训练 | 多模态数据(人类视频、图文对、机器人数据集) | 数据相对丰富 |
| SFT | 高质量机器人轨迹 | 数据稀缺且昂贵 |
两个关键挑战:
| 挑战 | 说明 |
|---|---|
| 数据稀缺 | 机器人轨迹采集需要精心设计的场景、多样化的物体和熟练的操作者 |
| 泛化能力差 | SFT 依赖有限的场景和任务特定数据,遇到未见任务/环境/物体时性能下降 |
1.2 LRM 的启示
DeepSeek-R1 等大型推理模型证明:仅依靠结果奖励的 RL 就能驱动显著进步,增强模型的逐步推理能力。
核心研究问题:
RL 能否类似地增强 VLA 模型生成准确动作的能力,同时帮助克服 SFT 的上述两个挑战?
1.3 VLA RL 的独特挑战
| 挑战 | 说明 |
|---|---|
| 传统 RL 依赖手工过程奖励 | 严重限制可扩展性 |
| VLA rollout 需要多轮环境交互 | 比 LLM 更慢、成本更高 |
| 动作解码策略多样 | 扩散、tokenization、回归,只有 token 方法天然兼容 PPO |
2. 预备知识
2.1 LLM 的 RL 形式化
| 要素 | 定义 |
|---|---|
| 状态 sts_tst | 输入提示 + 已生成 token |
| 动作 ata_tat | 从词汇表选择下一个 token |
| 环境 | 序列完成后提供奖励信号 |
| Rollout | 自回归生成直到终止,无中间环境反馈 |
2.2 VLA 的 RL 形式化
| 要素 | 定义 |
|---|---|
| 状态 sts_tst | 视觉输入 + 本体感知 + 语言指令 |
| 动作 ata_tat | 末端执行器控制命令(6-DoF 位姿 + 夹爪) |
| 环境 | 物理世界或仿真,提供状态转移和奖励 |
| Rollout | 迭代交互:动作执行 → 环境更新 → 新观测 |
奖励函数:
R(ai,t∣si,t)={1任务成功0否则R(a_{i,t} \mid s_{i,t}) = \begin{cases} 1 & \text{任务成功} \\ 0 & \text{否则} \end{cases}R(ai,t∣si,t)={10任务成功否则
其中 α\alphaα 平衡结果奖励和过程奖励(本文采用纯结果奖励,α=1\alpha=1α=1)。
2.3 GRPO(Group Relative Policy Optimization)
GRPO 是 DeepSeek 提出的 RL 算法,消除价值函数,通过组内相对归一化计算优势:
| 符号 | 含义 |
|---|---|
| GGG | 每组轨迹数量 |
| RiR_iRi | 第 iii 条轨迹的总奖励 |
| A^i\hat{A}_iA^i | 归一化优势 = (Ri−mean)/std(R_i - \text{mean}) / \text{std}(Ri−mean)/std |
| ri,t(θ)r_{i,t}(\theta)ri,t(θ) | 重要性采样比率 = πθ/πθold\pi_\theta / \pi_{\theta_{\text{old}}}πθ/πθold |
| ϵ\epsilonϵ | PPO 裁剪参数 |
| β\betaβ | KL 正则化系数 |
3. SimpleVLA-RL 方法
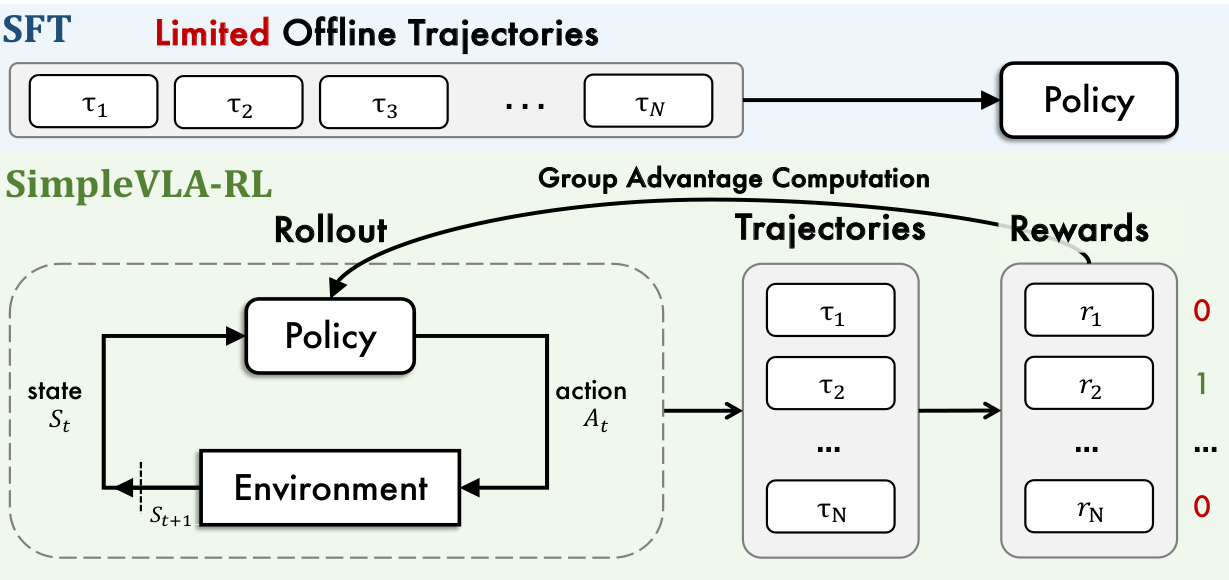
3.1 交互式 VLA Rollout
LLM vs VLA Rollout 对比:
| 维度 | LLM | VLA |
|---|---|---|
| 生成方式 | 自回归生成 token | 动作执行 → 环境更新 → 新观测 |
| 多样性来源 | 温度采样 | 温度采样 + 环境随机性 |
| 反馈 | 无中间反馈 | 每步执行后有新状态 |
VLA 动作解码策略兼容性:
| 策略 | 与 PPO/GRPO 兼容性 |
|---|---|
| Token 生成(如 OpenVLA) | ✅ 天然兼容 |
| 扩散去噪(如 RDT) | ⚠️ 需要适配 |
| 确定性 MLP 回归 | ❌ 不兼容 |
本文选择:采用 token 生成方法,输出动作 token 概率分布,使用随机采样生成多样化轨迹。
3.2 结果奖励建模
核心设计:使用简单的二元结果奖励(成功=1,失败=0)
| 特点 | 说明 |
|---|---|
| 可扩展 | 无需手工设计过程奖励 |
| 通用 | 适用于各种环境 |
| 简单 | 避免任务特定奖励的非迁移性 |
奖励分配:轨迹级奖励均匀传播到每个动作 token。
3.3 探索增强策略
问题:VLA 模型倾向于收敛到狭窄的解决方案模式,限制 RL 效率。
三种增强策略:
| 策略 | 说明 | 效果 |
|---|---|---|
| 动态采样 | 排除全成功或全失败的组,只保留混合结果组 | 确保非零梯度 |
| 提高裁剪上限 | 将 GRPO 裁剪范围从 [0.8, 1.2] 扩大到 [0.8, 1.28] | 允许低概率 token 增加概率 |
| 提高采样温度 | 温度从 1.0 提高到 1.6 | 生成更多样化轨迹 |
3.4 训练目标
最终损失函数:
J(θ)=Es0∼D,{ai}i=1G∼πθold[1G∑i=1G1∣ai∣∑t=1∣ai∣min(ri,t(θ)A^i,clip(ri,t(θ),1−ϵlow,1+ϵhigh)A^i)]\mathcal{J}(\theta) = \mathbb{E}_{s_0 \sim \mathcal{D}, \{a_i\}_{i=1}^G \sim \pi_{\theta_{\text{old}}}} \left[ \frac{1}{G} \sum_{i=1}^G \frac{1}{|a_i|} \sum_{t=1}^{|a_i|} \min \left( r_{i,t}(\theta) \hat{A}_i, \text{clip}(r_{i,t}(\theta), 1-\epsilon_{\text{low}}, 1+\epsilon_{\text{high}}) \hat{A}_i \right) \right]J(θ)=Es0∼D,{ai}i=1G∼πθold
G1i=1∑G∣ai∣1t=1∑∣ai∣min(ri,t(θ)A^i,clip(ri,t(θ),1−ϵlow,1+ϵhigh)A^i)
关键修改:
- 移除 KL 散度正则化(参考 DAPO)
- 动态采样约束:0<∣{成功轨迹}∣<G0 < |\{\text{成功轨迹}\}| < G0<∣{成功轨迹}∣<G
4. 实验
4.1 实验设置
基准测试:
| 基准 | 特点 | 任务数 |
|---|---|---|
| LIBERO | 终身学习,语言引导操作 | 5 个任务套件 |
| RoboTwin1.0 | 双臂操作,场景/物体多样性有限 | 17 任务 |
| RoboTwin2.0 | 双臂操作,731 物体实例,域随机化 | 50 任务 |
RoboTwin2.0 任务分类(按步数/规划长度):
| 级别 | 步数范围 | 任务数 |
|---|---|---|
| Short | 112-130 | 4 |
| Medium | 151-223 | 4 |
| Long | 283-313 | 2 |
| Extra-Long | 466-637 | 2 |
主干网络:OpenVLA-OFT(LLaMA2-7B + 动作 tokenization + 并行解码)
训练配置:
| 参数 | 值 |
|---|---|
| GPU | 8 × A800 80GB |
| 学习率 | 5e-6 |
| 批大小 | 64 |
| 采样数 G | 8 |
| 裁剪范围 | [0.2, 0.28] |
| 温度 T | 1.6 |
4.2 主要结果
LIBERO 结果:
| 模型 | Spatial | Object | Goal | Long | 平均 |
|---|---|---|---|---|---|
| OpenVLA | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| π0 | 96.8 | 98.8 | 95.8 | 85.2 | 94.2 |
| UniVLA | 96.5 | 96.8 | 95.6 | 92.0 | 95.2 |
| OpenVLA-OFT + Ours | 91.6 | 95.3 | 90.6 | 86.5 | 91.0 |
RoboTwin1.0 结果(平均成功率):
| 模型 | 平均 |
|---|---|
| DP | 5.9 |
| DP3 | 58.1 |
| OpenVLA-OFT | 39.8 |
| + Ours | 70.4 (+30.6) |
RoboTwin2.0 结果(按任务长度):
| 模型 | Short | Medium | Long+Extra | 平均 |
|---|---|---|---|---|
| RDT | 24.5 | 47.8 | 27.8 | 33.3 |
| π0 | 45.5 | 58.8 | 43.3 | 49.2 |
| OpenVLA-OFT | 21.3 | 47.1 | 46.5 | 38.3 |
| + Ours | 64.9 | 72.5 | 68.8 | 68.8 (+30.5) |
5. 分析
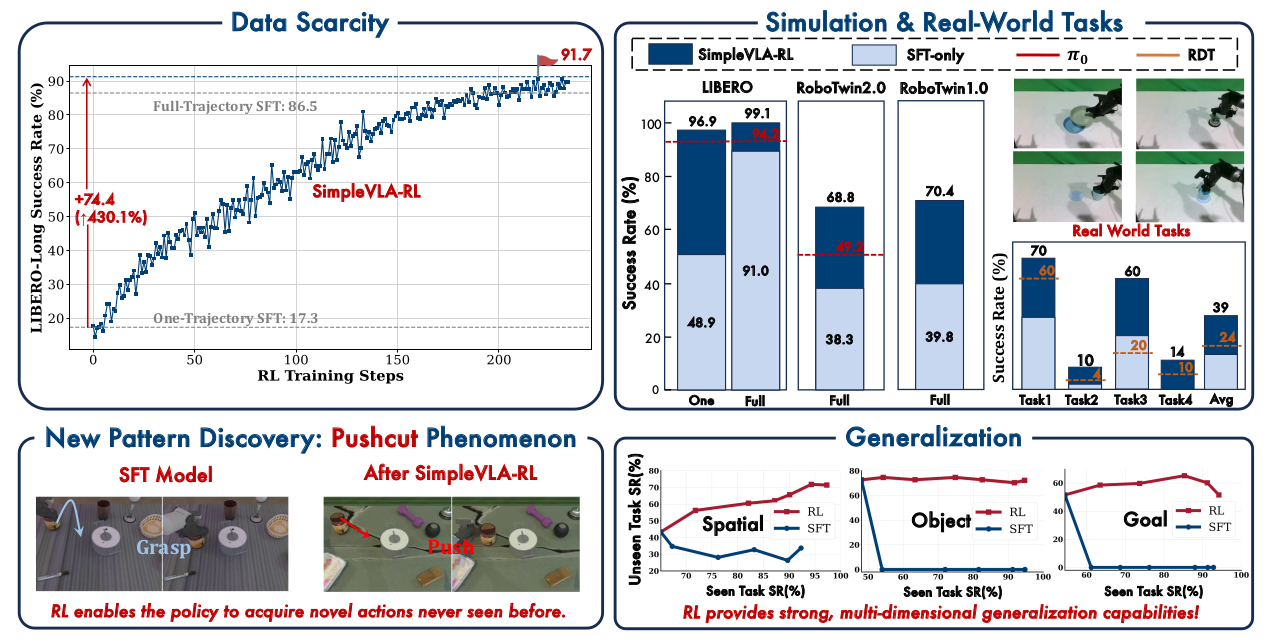
5.1 克服数据稀缺
设置:仅用每条任务 1 条演示进行 SFT(One-Trajectory SFT)
LIBERO-Long 结果:
| 模型 | 成功率 |
|---|---|
| One-Trajectory SFT | 17.3% |
| + RL | 91.7% |
| Full-Trajectory SFT | 86.5% |
| + RL | 98.5% |
关键发现:
- One-Trajectory SFT + RL 甚至超过 Full-Trajectory SFT
- 性能差距仅 2.2%(96.9% vs 99.1%)
- RL 可显著缓解 VLA 训练的数据稀缺瓶颈
5.2 泛化能力分析
设置:9 个 seen 任务训练,1 个 unseen 任务评估
主要发现:
| 维度 | SFT | RL |
|---|---|---|
| 训练任务性能 | >90% | >90% |
| 未见任务性能 | 严重过拟合,常降至 0% | 持续提升,+5-15% |
| 灾难性遗忘 | 严重 | 几乎无 |
结论:RL 使 VLA 模型能够保留已有能力,同时学习可泛化的技能。
5.3 真实世界实验(Sim2Real)
任务:Stack Bowls, Place Empty Cup, Pick Bottle, Click Bell
| 模型 | 平均成功率 |
|---|---|
| RDT | 23.5% |
| OpenVLA-OFT (SFT) | 17.5% |
| + RL | 38.5% (+21.0) |
结论:大规模仿真 RL 训练显著提升真实世界性能,展示了低成本扩展真实世界策略的可行路径。
6. 讨论
6.1 “Pushcut”:RL 中的新模式涌现
观察现象:在 RoboTwin2.0 的 “move can pot” 任务中:
| 数据来源 | 策略 |
|---|---|
| 演示数据 | grasp → move → place(抓取-移动-放置) |
| RL 训练后 | push 直接推送到目标位置 |
类似现象:“place a2b right” 任务中,RL 模型学会直接推动而非抓取放置。
意义:
- 类似 DeepSeek-R1 中的 “Aha Moment”
- 结果奖励设计避免了过程约束,赋予智能体更大的探索空间
- 成功行为通过正向奖励被强化,低效行为被淘汰
6.2 SimpleVLA-RL 的失败模式
关键发现:模型先验是决定 RL 有效性的关键因素
| 初始能力(SFT 轨迹数) | SFT 成功率 | +RL 后 | 提升 |
|---|---|---|---|
| 0 | 0% | 0% | 0 |
| 100 | 7.3% | 25.4% | +18.1 |
| 1000 | 28.2% | 50.4% | +22.2 |
结论:
- RL 完全失败:当基础模型无任务能力时(0% 成功率)
- 强初始能力 → 更大 RL 收益
- 存在性能阈值:初始能力太低时,RL 改进微乎其微
7. 核心创新总结
| 创新点 | 说明 |
|---|---|
| 首个 VLA 在线 RL 系统框架 | 基于 veRL 扩展,支持 VLA 特定交互采样 |
| 探索增强三件套 | 动态采样 + 裁剪上限提高 + 高温度采样 |
| 结果奖励设计 | 简单二元奖励,避免过程奖励复杂性 |
| 数据效率突破 | 每条任务仅 1 条演示 + RL → 91.7% 成功率 |
| 泛化能力提升 | RL 显著优于 SFT,避免灾难性遗忘 |
| Sim2Real 成功 | 仿真 RL → 真实世界性能大幅提升 |
| Pushcut 现象发现 | RL 发现超越演示数据的新策略 |
8. 局限性与未来方向
| 局限性 | 未来方向 |
|---|---|
| 需要基础模型有非零初始能力 | 结合更好的预训练或探索策略 |
| 仅支持 token 化动作的 VLA | 扩展到扩散/回归动作空间 |
| 仿真-真实仍有差距 | 更逼真的仿真或域适应 |
| 计算成本较高 | 更高效的 RL 算法或蒸馏 |
9. 结论
本文提出的 SimpleVLA-RL 是一个为 VLA 模型定制的高效在线 RL 框架。通过将 GRPO 算法适配到 VLA 的交互式 rollout 场景,并引入探索增强策略,在多个基准测试上达到 SoTA 性能。
三大核心贡献:
- 数据效率:每条任务仅需 1 条演示,RL 可将 LIBERO-Long 成功率从 17.3% 提升到 91.7%
- 泛化能力:RL 训练避免 SFT 的过拟合问题,在未见任务上持续提升
- Sim2Real:仿真 RL 训练显著提升真实世界性能(+21%)
Pushcut 现象展示了 RL 发现超越演示数据的新策略的潜力,为 VLA 的自主进化提供了新思路。
10. 资源
- 📄 论文标题:SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
- 👨🔬 作者:Haozhan Li, Yuxin Zuo, Jiale Yu 等(清华 + 上海 AI Lab + 上交 + 北大 + 港大)
- 🔗 代码开源:PRIME-RL/SimpleVLA-RL

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)