(论文速读)YOLOv5s-GhostNet :轻量高效的PCB工业表面缺陷检测
论文题目:An Efficient Deep Neural Network for Surface Defect Detection in Industrial Edge Sensing(一种用于工业边缘传感表面缺陷检测的高效深度神经网络)
期刊:IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS
摘要:本文为基于深度学习的表面缺陷检测提供了一种高效的边缘端实现方案,以提高在资源有限的边缘设备上应用的准确性和效率。提出了一种高效的YOLO (you only look once)网络YOLOv5sGhostNet,它突出了轻量级的骨干/颈部网络、高效的特征提取模块和基于知识蒸馏的快速学习方案。从理论上分析了参数压缩比可以降低计算复杂度。节理损耗的设计是为了提高对新缺陷的泛化能力。以树莓派为边缘,开发了具有实时边缘终端云检测系统的工业测试平台。实验结果表明,该方法具有复杂度(每秒浮点运算8.2G, pt 7.9M)、检测精度(精度97.91%,平均精度(mAP) 96.66%)、效率(单个缺陷每秒帧数(FPS) 294)和快速学习收敛(50 epoch)等特点。与现有方法相比,该方法在overage上减小了50%的模型尺寸,检测效率提高了4倍,并保持了较高的精度。
轻量高效的工业表面缺陷检测:YOLOv5s-GhostNet 论文详解
一、研究背景与问题
工业表面缺陷检测是智能制造中的关键环节,涵盖电路板(PCB)、芯片、电池、钢材等多类工业产品。近年来,深度学习方法在该任务上取得了显著进展,YOLO系列因其端到端的检测能力成为最主流的方案之一。
然而,现有方法面临以下几个核心挑战,本文正是针对这些问题提出解决方案:
1.1 边缘部署困难
以提升精度为目标的改进方法(引入注意力模块、Transformer等)虽然在服务器端表现出色,但模型体积庞大、计算量高,几乎无法直接部署在 Raspberry Pi 等算力受限的工业边缘设备上。大量研究只在配备高端 GPU 的服务器上完成验证,缺乏真实边缘端的落地实验。
1.2 精度与效率难以兼顾
- 以精度为目标的改进:引入注意力机制、Transformer,显著增大模型复杂度;
- 以效率为目标的改进:引入轻量化模块,往往以牺牲检测精度为代价。
两类优化目标本质上相互矛盾,如何在二者之间取得平衡,仍是开放性问题。
1.3 无法动态应对新兴缺陷
实际生产中会不断出现新型缺陷,而现有方法缺乏有效机制来快速适应新类别。重新训练整个模型不仅耗时耗力,还容易导致"灾难性遗忘",即对旧类别的检测性能下降。
1.4 缺乏完整的工业落地系统
现有研究大多停留在算法层面,缺少从边缘端感知到云端管理的完整工业检测系统设计,无法满足工业物联网(IoT)的实时性与可扩展性需求。
二、核心创新点
本文从轻量化网络结构、快速学习机制和系统架构设计三个维度出发,提出了完整的解决方案。
2.1 轻量化主干网络:YOLOv5s-GhostNet
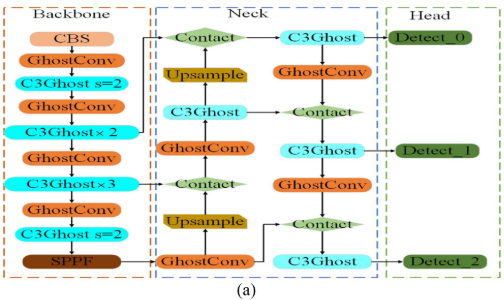
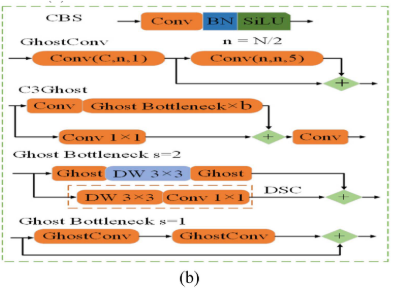
📌 【此处配图:图1(a) 网络整体结构图 + 图1(b) 基础模块示意图】
整体网络由四部分组成:输入端、backbone(主干网络)、neck(颈部网络)和检测头。区别于传统 YOLOv5s,本文引入了三个高效模块:
2.1.1 GhostConv(GC)模块
GhostConv 的核心思想是:标准卷积产生的特征图存在大量冗余(高度相似),因此不必全部通过代价昂贵的卷积来生成。
具体做法:
- 先用一个规模较小的主卷积生成 M 个本征特征图(M ≤ N);
- 再对每个本征特征图施加一系列廉价线性变换(如 1×1 逐点卷积、DW 深度可分离卷积),生成 S 个"ghost"特征图;
- 最终拼接得到所需的 N = M × S 个特征图。
理论上,GhostConv 的加速比和参数压缩比均约为 S(默认 S=2),即在保留特征提取能力的同时,将参数量和计算量降低约一半。
2.1.2 深度可分离卷积(DSC)模块
DSC 将标准卷积拆解为:
- 逐深度卷积(DW):沿通道维度进行空间卷积;
- 逐点卷积(PW):沿空间维度进行通道混合。
其压缩比为 1/N + 1/K²,计算量的节省与输出通道数 N 和卷积核尺寸 K 成反比,在大通道数场景下效果显著。
2.1.3 C3Ghost 模块
C3Ghost 由多个堆叠的 Ghost Bottleneck 构成,专为高效 backbone 和 neck 网络设计。GhostConv 与 DSC 的 shortcut 连接在优化计算效率、增强梯度流动的同时,保留了丰富的特征提取能力,在不牺牲性能的前提下显著降低资源消耗。
2.2 联合损失函数设计
本文设计了一个同时负责缺陷识别、定位与分类的联合损失函数:
三个子损失分别为:
- 分类损失
:二元交叉熵(BCE),衡量类别预测准确性;
- 回归损失
:采用 CIoU Loss,综合考虑预测框与真实框的重叠面积、中心点距离及长宽比;
- 目标置信度损失
:BCE,衡量预测框内是否存在目标的置信度。
2.3 基于知识蒸馏(KD)的快速学习方案
针对新兴缺陷的适应性问题,本文引入了知识蒸馏机制:
- 教师模型:已收敛的 YOLOv5s(6类缺陷,训练300 epoch);
- 学生模型:Y-GhostNet(初始训练4类,经蒸馏后扩展至6类检测);
- 蒸馏温度:T = 20,用于平滑教师模型的输出概率分布(软标签)。
蒸馏损失由三部分组成:
| 子损失 | 计算方式 | 作用 |
|---|---|---|
| MSE | 对齐预测框坐标 | |
| KL 散度 | 对齐类别概率分布 | |
| MSE | 对齐目标置信度 |
软标签相比传统硬标签包含更丰富的类间关系信息,使学生模型能更快速、更稳定地收敛,同时避免灾难性遗忘。
2.4 端-边-云三层工业检测系统
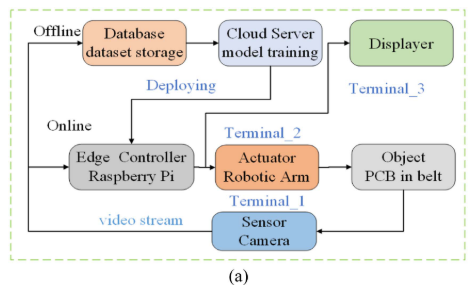
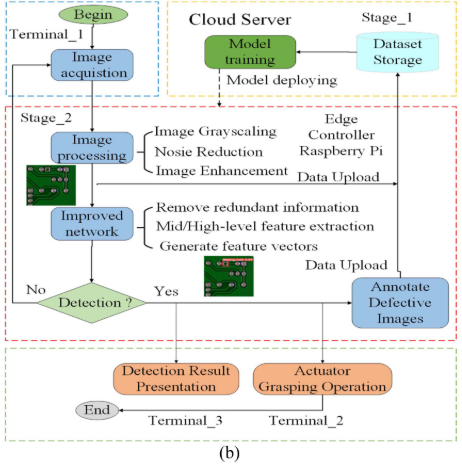
📌 【此处配图:图2(a) 端-边-云系统架构图 + 图2(b) 检测流程图】
本文设计了完整的工业实时检测系统,分为三层:
- 终端层(Terminal):摄像头采集传送带上PCB的实时视频流,机械臂执行抓取动作;
- 边缘层(Raspberry Pi):接收视频流并预处理为图像,运行轻量化检测模型进行实时推理,将结果上传至云端数据库并指令机械臂动作;
- 云端层(Cloud Server):负责数据集存储、模型离线训练与更新,通过 TCP-IP 协议与边缘节点通信。
这一架构充分利用边缘计算的低延迟、实时性优势,以及云计算的可扩展性、强算力优势,实现工业 IoT 场景下的高效缺陷检测闭环。
三、实验设置
3.1 实验平台

📌 【此处配图:图3 实验平台实物图】
本文搭建了以 Raspberry Pi 为边缘计算设备的物理实验平台。
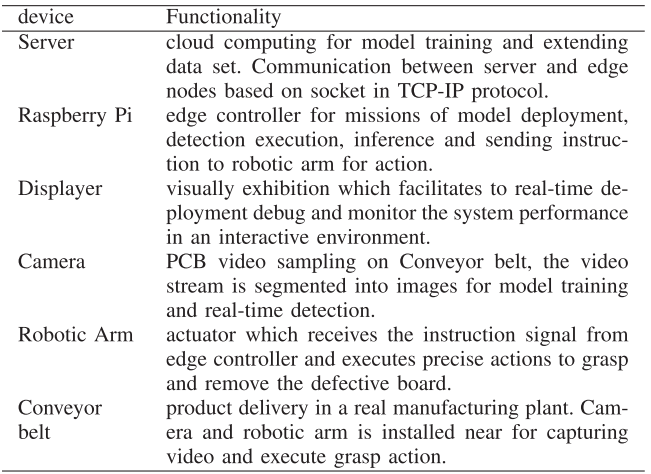
📌 【此处配表:表I 平台主要组件及功能说明】
各组件包括:云服务器(模型训练)、Raspberry Pi(边缘推理)、显示器、摄像头、机械臂和传送带,共同模拟真实工业生产线环境。
3.2 数据集
PCB样本来源于公开数据集 Ku-MarketPCB,原始数量为1386张图像,包含6类常见PCB缺陷,经图像翻转、对比度调整、亮度增强等数据增强后,最终共 6237 张图像,按 8:1:1 划分训练/测试/验证集。
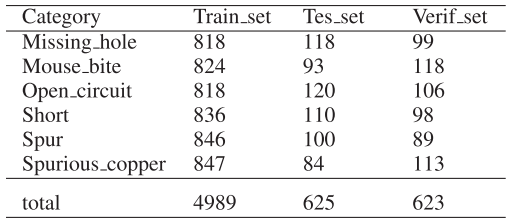
📌 【此处配表:表II 数据集分布详情(即上表)】
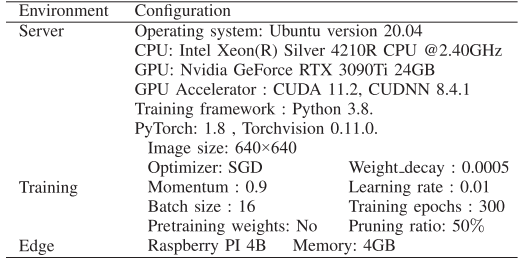
📌 【此处配表:表III 实验环境与训练参数】
3.3 评估指标
📌 【此处配表:表IV 评估指标定义与说明】
本文采用10项指标,分为三类:
- 模型复杂度:PARM(参数量)、FLOPS(浮点运算量)、.pt(权重文件大小)、Layer(网络层数);
- 检测效率:TrainT(训练时间)、FPS(每秒帧数)、RasPiInfT(Raspberry Pi 推理时间);
- 检测精度:Precision(精确率)、Recall(召回率)、mAP(平均精度均值)。
四、实验结果与分析
4.1 服务器端性能对比
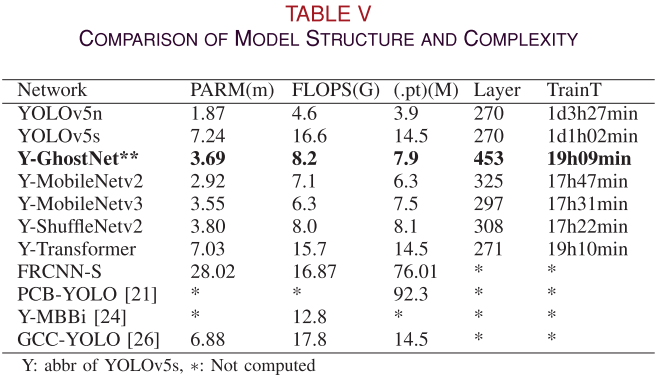
📌 【此处配表:表V 各网络模型结构与复杂度对比】
📌 【此处配表:表VI 测试集检测性能对比】
模型复杂度
与基线 YOLOv5s 相比,Y-GhostNet 将模型参数量从 7.24M 降至 3.69M,FLOPS 从 16.6G 降至 8.2G,权重文件从 14.5M 降至 7.9M,平均压缩约50%。
与其他对比方法相比,Y-GhostNet 在轻量化程度上同样领先:
- FRCNN-S:PARM 28.02M,FLOPS 16.87G,.pt 76.01M;
- PCB-YOLO:.pt 高达 92.3M;
- GCC-YOLO:PARM 6.88M,FLOPS 17.8G。
以上方法均无法部署在真实边缘设备上,而 Y-GhostNet 的 7.9M 权重文件完全适配 Raspberry Pi。
检测精度
Y-GhostNet 在测试集上达到:
- Precision:97.91%
- Recall:94.53%
- mAP@0.5:96.66%
- FPS:294(单缺陷),77(多缺陷),远超工业实时需求(30 FPS)
虽然 YOLOv5s 和 Y-Transformer 在精度上与 Y-GhostNet 相近(Precision/Recall/mAP 均超 96%),但其推理速度远低于 Y-GhostNet,难以满足工业实时检测需求。
结论:Y-GhostNet 在模型轻量化、推理速度与检测精度三者之间实现了最佳平衡,训练时间平均减少约6小时。
4.2 知识蒸馏加速训练效果
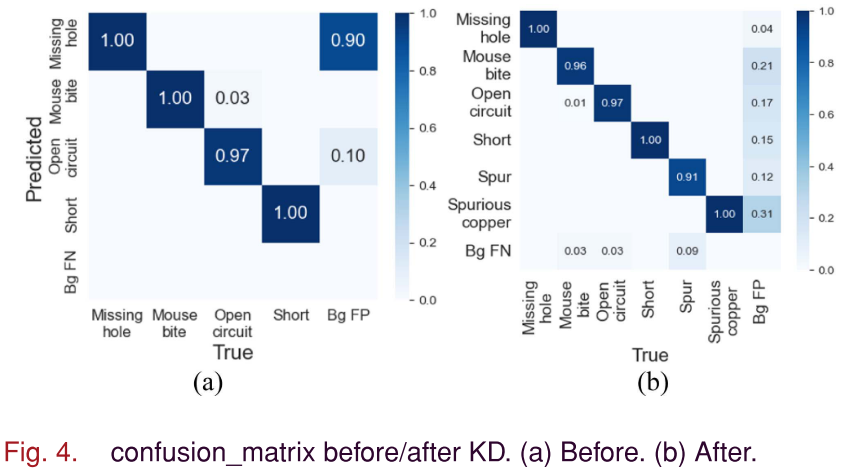
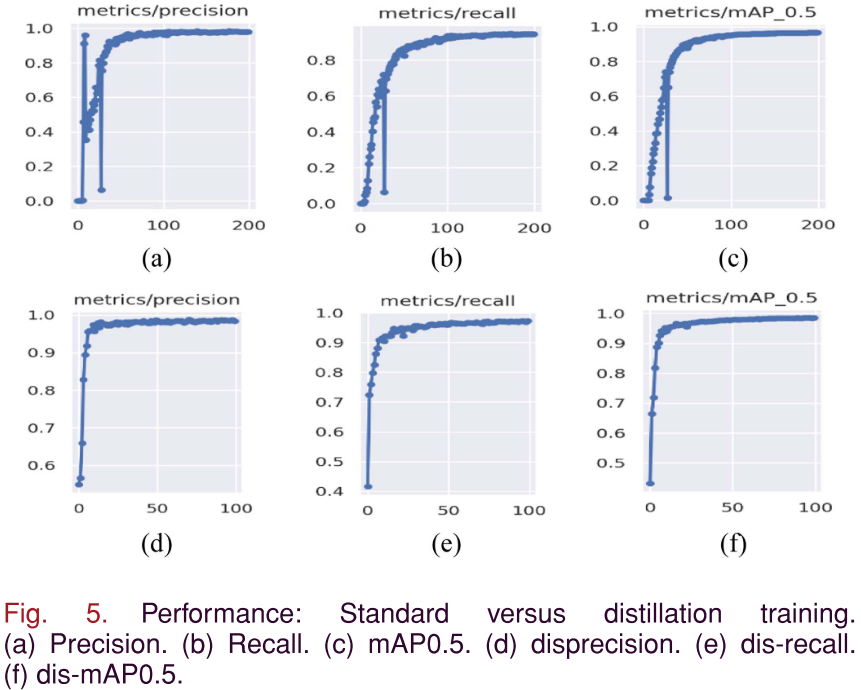
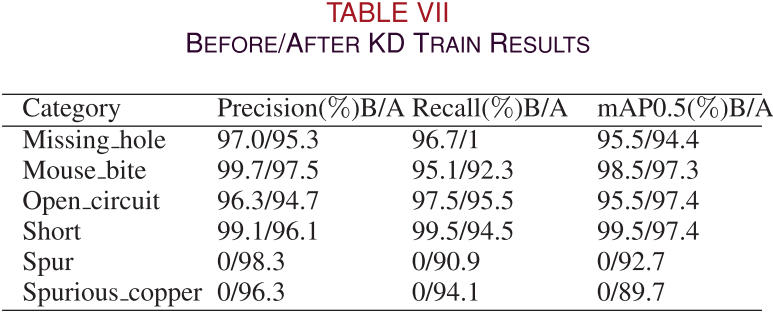
📌 【此处配图:图4 KD前后混淆矩阵对比图】 📌 【此处配图:图5 标准训练 vs 蒸馏训练的Precision/Recall/mAP曲线】 📌 【此处配表:表VII KD前后各类别检测精度对比】
实验设置:
- 教师模型:YOLOv5s,6类,训练至收敛(300 epoch);
- 初始学生模型:Y-GhostNet(nc4),4类,训练100 epoch;
- 蒸馏后学生模型:Y-GhostNet(dis),6类。
关键发现:
-
收敛速度:标准训练在约100 epoch后才开始稳定收敛(最终在200 epoch停止),存在明显早期波动;蒸馏训练曲线更平滑,仅需50 epoch即可收敛。
-
新类别适应性:蒸馏后模型对新增类别 Spurious_copper 的识别能力显著提升(精度从0提升至96.3%,召回率从0提升至94.1%)。
-
旧类别保持:蒸馏不仅未损害旧类别性能,反而优化了部分类别(如 Mouse_bite 与背景 FP 的混淆明显减少)。
4.3 Raspberry Pi 边缘部署效果
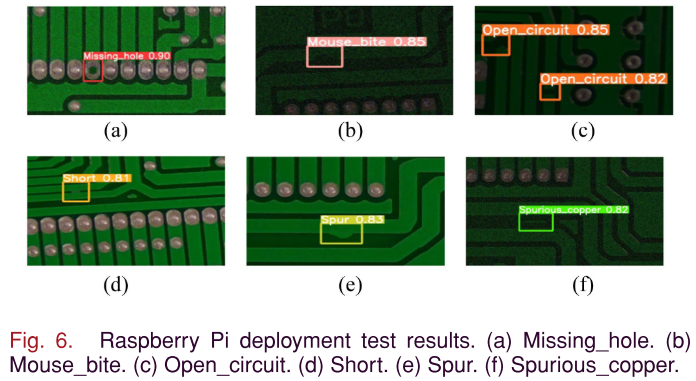
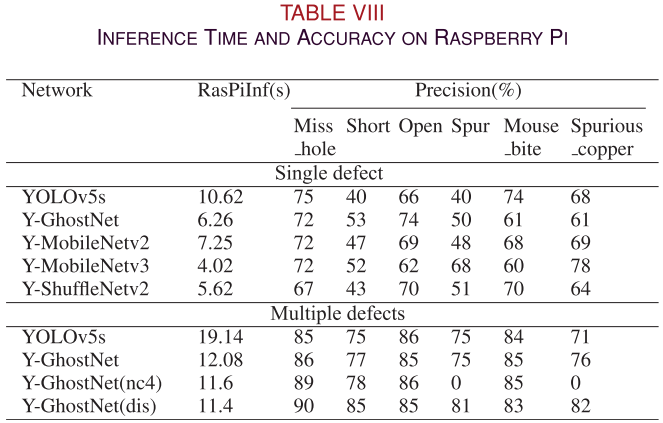
📌 【此处配图:图6 Raspberry Pi上六类缺陷的检测结果可视化图】 📌 【此处配表:表VIII Raspberry Pi推理时间与各类别精度】
将 Y-GhostNet 部署在 Raspberry Pi(Python 3.8 + PyTorch 1.8)上进行测试:
| 场景 | YOLOv5s 推理时间 | Y-GhostNet 推理时间 | Y-GhostNet(dis) 推理时间 |
|---|---|---|---|
| 单缺陷 | 10.62s | 6.26s | — |
| 多缺陷 | 19.14s | 12.08s | 11.4s |
精度方面:从服务器到 Raspberry Pi,整体精度平均从97%下降至约85%,主要原因有两点:
- 边缘设备硬件性能本身对实时推理影响较大;
- 深度卷积过多使用导致小目标细节特征提取不足(如 Spur 类精度仅约75%)。
蒸馏效果:Y-GhostNet(dis) 在多缺陷场景下精度显著优于蒸馏前版本,充分体现了蒸馏学习方案的价值。
⚠️ 局限性说明:Raspberry Pi 在单缺陷场景下推理约需 6 秒(0.2 FPS),多缺陷约 11 秒(0.09 FPS),远低于30 FPS的实时要求。作者建议未来可选用 NVIDIA Jetson Nano、Google Coral 等更强算力的边缘设备,或通过 TensorRT、Intel Neural Compute Stick 2 等硬件加速方案进行优化。
4.4 非理想环境下的鲁棒性测试
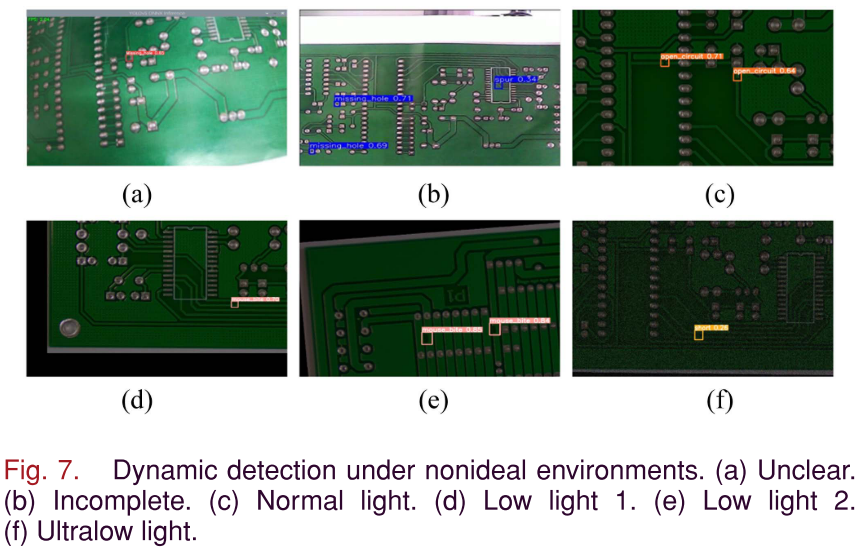
📌 【此处配图:图7 非理想环境下的动态检测结果图(含模糊/不完整/正常/低光照/极低光照六种场景)】
本文在真实工业生产线上进行了多种非理想光照和不完整图像的鲁棒性测试:
| 测试条件 | 检测表现 |
|---|---|
| 正常光照 | 检测稳定,精度有保障 |
| 低光照+图像不完整 | 可准确检测(图像清晰度尚可) |
| 低光照(图像较清晰) | 图像清晰度高于超低光照时,检测仍较准确 |
| 极低光照 | 大量误检,推理时间增至 77.5ms,出现类别错判(mouse_bite → short) |
结论:模型对图像清晰度较为敏感,适当的工业照明是保障检测精度的必要条件;检测能力受限时,边-云协同框架可通过云端进一步分析兜底。
五、总结与展望
本文提出的 YOLOv5s-GhostNet 方法,通过轻量化主干网络设计与知识蒸馏快速学习机制,实现了在资源受限边缘设备上高精度、高效率的工业表面缺陷检测,主要成就如下:
| 指标 | 提升效果 |
|---|---|
| 模型大小 | 较现有方法平均减少 50% |
| 检测效率(服务器) | 提升约 4倍(294 FPS vs ~70 FPS) |
| 检测精度 | Precision 97.91%,mAP 96.66% |
| 训练收敛速度(KD) | 从 200 epoch 加速至 50 epoch |
未来研究方向:
- 同时设计面向精度与复杂度双目标的联合损失函数;
- 探索模型剪枝、量化等技术进一步压缩模型,弥合服务器与边缘端的性能差距;
- 选用更强算力的边缘硬件或引入专用推理加速器以满足真实实时需求;
- 在工业 IoT 数据传输过程中加强数据安全保障机制。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)